《PWC-Net:CNNs for Optical Flow Using Pyramid,Warping,and Cost Volume》论文笔记
Posted m_buddy
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了《PWC-Net:CNNs for Optical Flow Using Pyramid,Warping,and Cost Volume》论文笔记相关的知识,希望对你有一定的参考价值。
参考代码(official):PWC-Net
参考代码(pytorch convert):pytorch-pwc
1. 概述
导读:这篇文章给出了一种使用CNN网络实现光流估计的方法,在该方法中采用了经典的特征金字塔结构作为特征提取网络。之后在金字塔的某个层级上使用上一级的光流作为warp引导,第二幅图像的特征将被warp。进而使用第二幅图像warp之后的特征和第一幅图像的特征构建一个cost volume。在此基础之上,添加一个估计网络从而实现当前金字塔层的光流估计。文章的方法简单明了,在模型的体积上和infer时间上分别比FlowNet2小了17倍和2倍,并且相比FlowNet2繁琐的训练过程文章的方法训练起来更加容易。
将文章的方法与之前的一些光流估计网络进行infer时间与参数量上的比较:
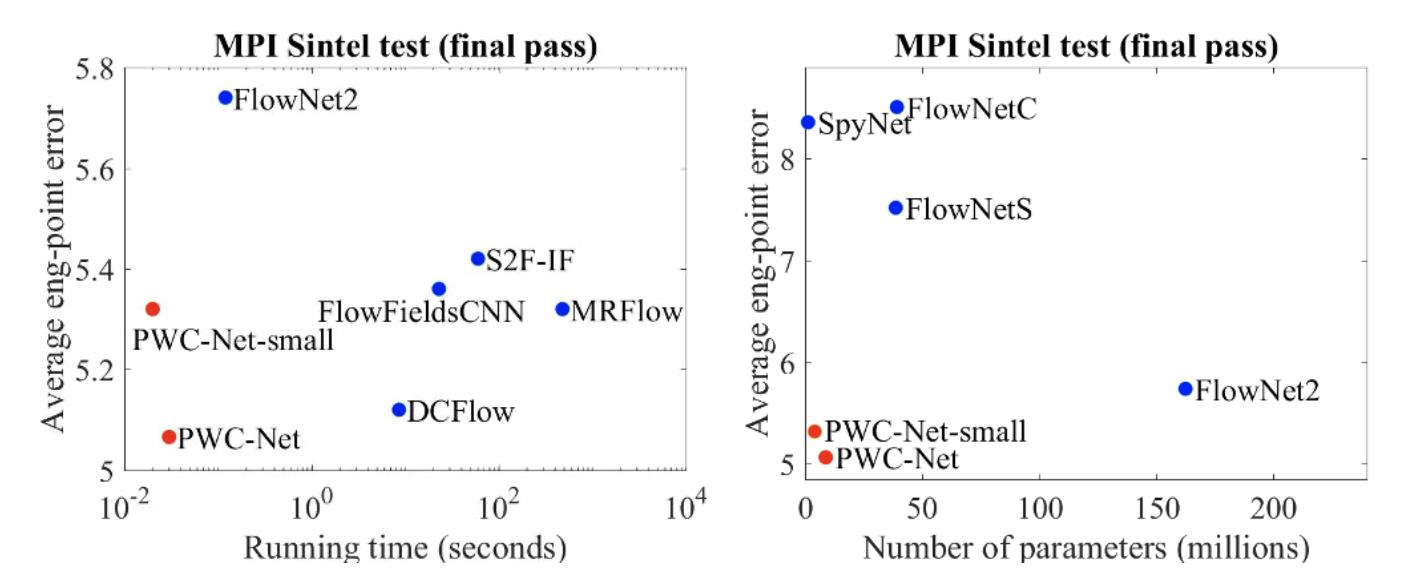
2. 方法设计
2.1 网络结构
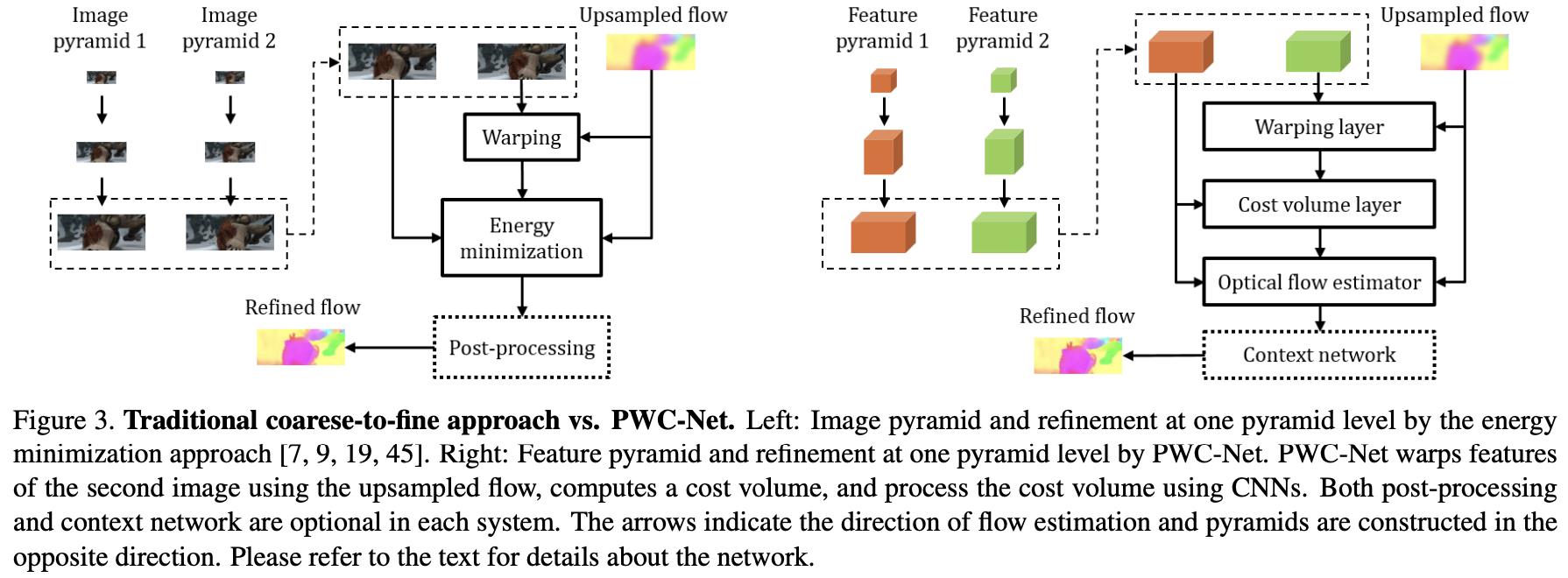
文章方法的网络结构见上图的右图所示,其输入的图像表示为
I
1
,
I
2
I_1,I_2
I1,I2,经过共享权重的CNN网络进行特征抽取(生成的特征描述为
f
e
a
t
=
[
c
t
1
,
c
t
2
,
c
t
3
,
c
t
4
,
c
t
5
,
c
t
6
]
feat=[c_t^1,c_t^2,c_t^3,c_t^4,c_t^5,c_t^6]
feat=[ct1,ct2,ct3,ct4,ct5,ct6],其中
t
t
t为图像的索引值),之后在
s
t
r
i
d
e
=
[
2
,
4
,
8
,
16
,
32
,
64
]
stride=[2,4,8,16,32,64]
stride=[2,4,8,16,32,64]的特征上进行迭代优化(这里的
c
h
a
n
n
e
l
=
[
16
,
32
,
64
,
96
,
128
,
192
]
channel=[16,32,64,96,128,192]
channel=[16,32,64,96,128,192])生成最后的光流估计,最后会使用传统的中值滤波或是双边滤波作后处理得到最后的光流结果。
2.2 网络模块
特征warp操作:
这里使用上一层特征生成的光流估计对当前图像2特征进行warp操作,从而对几何形变进行补偿以及使得图像块在正确的尺度上,其warp的过程可以描述为:
c
w
l
(
x
)
=
c
2
l
(
x
+
u
p
2
(
w
l
+
1
)
(
x
)
)
c_w^l(x)=c_2^l(x+up_2(w^{l+1})(x))
cwl(x)=c2l(x+up2(wl+1)(x))
其中,
x
x
x是像素的索引,
u
p
2
(
w
l
+
1
)
up_2(w^{l+1})
up2(wl+1)是上采样之后的光流估计结果,
w
l
+
1
w^{l+1}
wl+1是上一个层的光流估计结果。
cost volume构建:
文章的cost volume采用的是在窗口内向量乘积的形式,这里的窗口大小指的是输入的两个图像相对移动的范围,表示为
∣
x
1
−
x
2
∣
∞
≤
d
|x_1-x_2|_{\\infty}\\le d
∣x1−x2∣∞≤d。则cost volume的计算描述为:
c
v
l
(
x
1
,
x
2
)
=
1
N
(
c
1
l
(
x
1
)
)
T
c
w
l
(
x
2
)
cv^l(x_1,x_2)=\\frac{1}{N}(c_1^l(x_1))^Tc_w^l(x_2)
cvl(x1,x2)=N1(c1l(x1))Tcwl(x2)
其中,
N
N
N是列向量
c
1
l
(
x
1
)
c_1^l(x_1)
c1l(x1)的数量。生成的cost volume的维度为
d
2
∗
H
l
∗
W
l
d^2*H^l*W^l
d2∗Hl∗Wl。
光流估计模块:
这里是用生成的cost volume作为输入,之后接几个卷积从而得到光流估计结果。
context优化模块:
这部分网络是在金字塔网络的最后添加的,主要是添加了几个膨胀卷积用以增大感受野,其膨胀系数设置为
r
a
t
i
o
=
[
1
,
2
,
4
,
8
,
16
,
1
,
1
]
ratio=[1,2,4,8,16,1,1]
ratio=[1,2,4,8,16,1,1]。
2.3 损失函数
训练的时候文章使用L2损失:
L
(
θ
)
=
∑
l
=
l
0
L
α
l
∑
x
∣
w
θ
l
(
x
)
−
w
G
T
l
(
x
)
∣
2
+
γ
∣
θ
∣
2
L(\\theta)=\\sum_{l=l_0}^L\\alpha_l\\sum_x|w_{\\theta}^l(x)-w_{GT}^l(x)|_2+\\gamma|\\theta|_2
L(θ)=l=l0∑Lαlx∑∣wθl(x)−wGTl(x)∣2+γ∣θ∣2
而在finetune训练阶段文章使用的L1损失:
L
(
θ
)
=
∑
l
=
l
0
L
α
l
∑
x
∣
w
θ
l
(
x
)
−
w
G
T
l
(
x
)
+
η
∣
q
+
γ
∣
θ
∣
2
L(\\theta)=\\sum_{l=l_0}^L\\alpha_l\\sum_x|w_{\\theta}^l(x)-w_{GT}^l(x)+\\eta|^q+\\gamma|\\theta|_2
L(θ)=l=l0∑Lαlx∑∣wθl(x)−wGTl(x)+η∣q+γ∣θ∣2
3. 实验结果
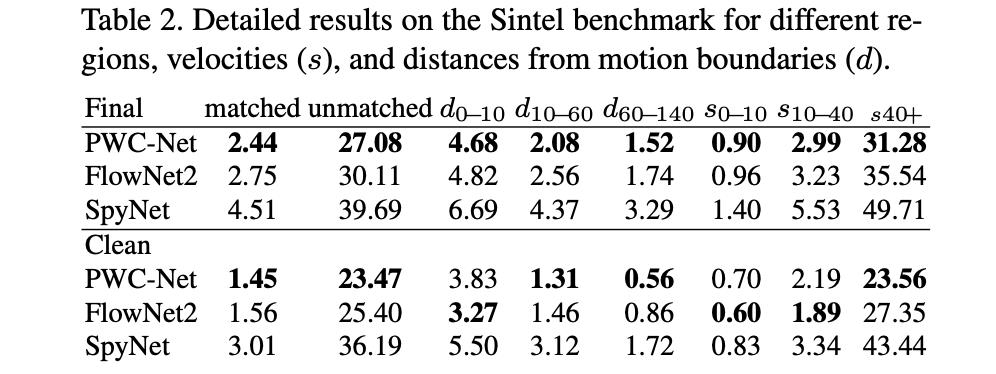
Sintel benchmark:
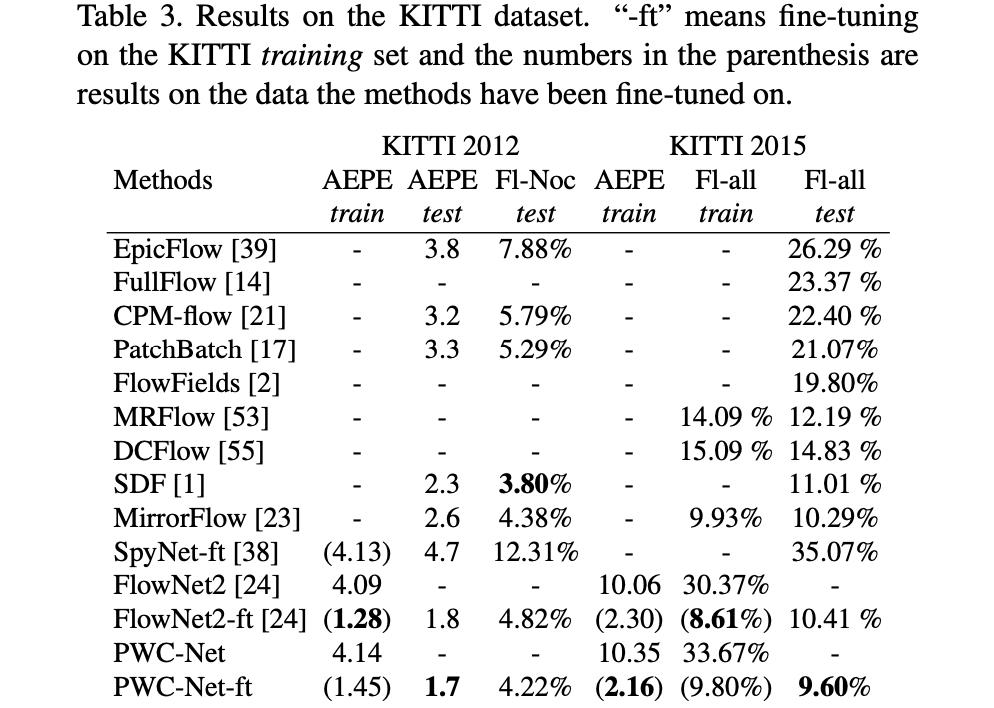
KITTI:
以上是关于《PWC-Net:CNNs for Optical Flow Using Pyramid,Warping,and Cost Volume》论文笔记的主要内容,如果未能解决你的问题,请参考以下文章