小白Spark工程师需要了解的Hadoop和YARN小知识
Posted 知了小巷
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了小白Spark工程师需要了解的Hadoop和YARN小知识相关的知识,希望对你有一定的参考价值。
点击关注上方“知了小巷”,
设为“置顶或星标”,第一时间送达干货。
Apache Spark
Apache Spark是一个用于批处理和流处理的开源分布式计算引擎,它是为快速内存数据处理而设计的。
Apache Spark是一个分布式编程框架,运用Spark API编写程序代码并打包,打包好的Spark应用(jar)可以运行在EC2、Hadoop YARN、Mesos或Kubernetes上,也可以运行在Spark Standalone上面。
Hadoop VS 操作系统
传统操作系统基本上都少不了这两部分:文件系统和资源管理组件。
不同机器上安装的操作系统,其文件系统可能是不一样的,比如:FAT32 HPFS、ext2、NFS、ZFS等。操作系统也可以是不一样的,比如Windows、Unix、Linux等,Linux还会有不同的发行版。但是,操作系统本身就是一个软件,有相应的启动入口,操作系统(Operating System,简称OS)是管理计算机硬件与软件资源的计算机程序。
操作系统有资源管理组件:包括内核、调度程序和一些线程以及允许程序基于数据运行的进程。
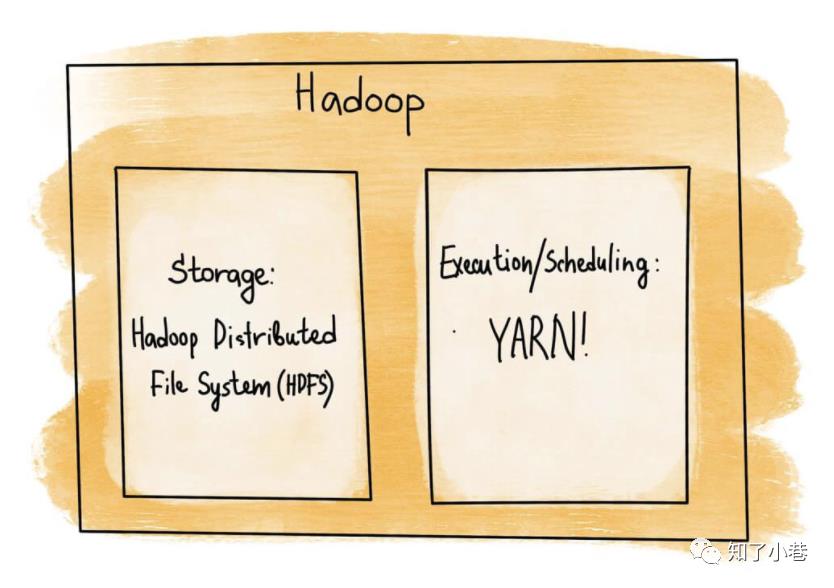
当我们将数据存储和资源管理概念拿到集群上来看,并将其 “置于” Hadoop中时,我们得到了和单个操作系统基本相同的分离开的两个组件。存储层将取代单节点文件系统,新的存储是HDFS——Hadoop分布式文件系统。YARN(Yet Another Resource Negotiator)承担了资源管理的角色:执行、调度、决定可以做什么以及在哪里能够分配足够的资源(CPU+内存) 去执行数据处理任务。
操作系统资源管理的基本单位是进程(一个进程单位),OS资源调度的基本单位是线程。
YARN资源管理的基本单位是分布式Application,即分布式应用(分布在多个节点机器上的多个进程),YARN资源调度的基本单位是进程,对于计算任务本身,要看具体任务的执行粒度:比如MapReduce默认多进程,MapTask和ReduceTask都是进程,当然进程内部仍然是线程;而Spark或Flink分别在Executor和TaskManager进程启动后驻守在OS后台,具体执行Task的是进程内部的线程。执行粒度的区别在于,进程切换和线程切换(常驻线程不需要切换,比如实时消费Kafka的线程)对分布式计算整体效率的影响是有明显差异的。
YARN架构
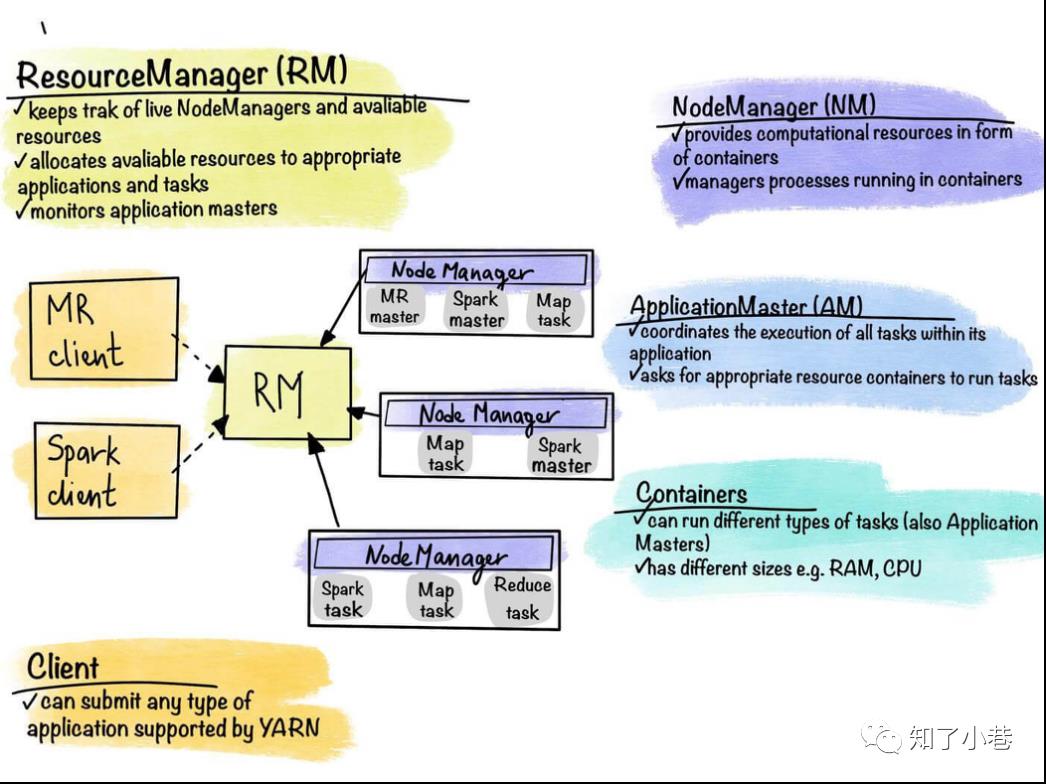
YARN是怎么运行的?
YARN是Hadoop集群资源管理系统,同时也具有通用性,除了MapReduce之外,也可以执行其它分布式计算程序。
基本组件
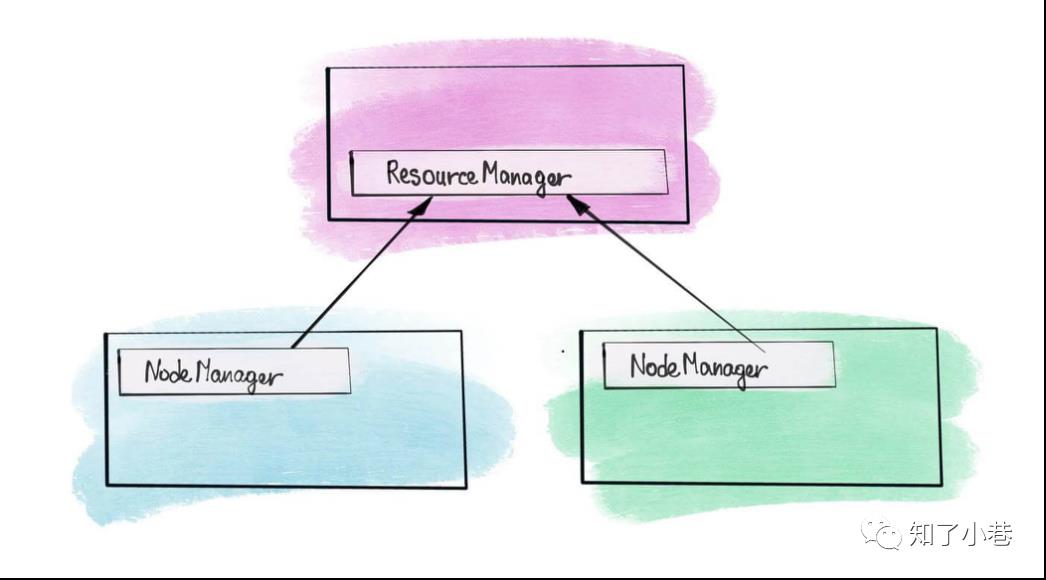
ResourceManager
集群资源的仲裁者,包括两部分:一是插件式的调度器Scheduler,二是ApplicationManager,用于管理集群中的用户作业。
NodeManager
管理该节点上的用户作业和工作流,也会不断发送自己Container使用情况给ResourceManager。
ApplicationMaster
向ResourceManager(全局的)申请计算资源(Containers)并且和NodeManager交互来执行和监控具体的task。ApplicationMaster要根据具体应用的特点进行编写,比如MapReduce的AM是MRAppMaster.java;Spark on YARN cluster的AM是ApplicationMaster.scala;Flink on YARN cluster per-job的AM是YarnJobClusterEntrypoint.java。
集群的所有节点都有一定数量的Container。Container是计算单元,是节点资源执行用户应用程序任务的一种包装器。它们是由YARN管理的主要计算单元。Container有自己的参数,可以按需配置(例如:内存、CPU等)。
每个节点上的Container由NodeManager守护进程控制。当在集群上启动新应用程序时,ResourceManager为应用程序的Master分配一个Container用来运行ApplicationMaster。每个应用程序的ApplicationMaster是一个特定于框架的实体(上面MR、Spark和Flink都是特定编写的),其任务是与ResourceManager协商资源,并与NodeManager合作执行和监视组件任务(比如MapTask、ReduceTask或Executor)。
一旦ApplicationMaster启动以后,ApplicationMaster将负责分布式应用程序的整个生命周期。首先,它将向ResourceManager发送资源请求,以获得执行应用程序任务所需要的Container(列表)。资源请求只是对满足某些资源需求的若干Container的请求,例如:
-
一定数量的资源,比如8GB内存,16核CPU -
首选Container的位置,主机名+机架名或者没有首选位置 -
应用程序内部的优先级,不是多个程序之间的优先级
ApplicationMaster也是在Container中运行,如果ApplicationMaster崩溃了或者不可用,ResourceManager可以重新创建另一个Container来重新启动ApplicationMaster,所以整个应用是高可用的。ResourceManager会将应用运行的相关信息存储在HDFS上面,重新启动时,ResourceManager会重新创建应用程序的状态,只重新启动尚未完成的任务,当然对于进程内部的具体计算任务需要应用框架本身的Checkpoint机制来恢复具体任务执行情况。
Submit application on YARN
-
客户端程序提交应用,包括特定于框架的ApplicationMaster和包含计算逻辑的用户程序、还有计算引擎本身的类库等。 -
ResourceManager负责为ApplicationMaster分配资源Container并远程通知NodeManager将Container运行起来(启动ApplicationMaster)。 -
ApplicationMaster启动后,将自己注册到ResourceManager。然后向ResourceManager请求指定的资源Container,且让这些Container与ApplicationMaster进行直接交互。正常情况下,ApplicationMaster会请求合适数量的Container。 -
ApplicationMaster成功接收到Container之后,ApplicationMaster会遍历Container列表,通知对应的NodeManager将Container运行起来(比如 启动Executor)。 -
在Container内部,运行用户程序代码,比如ApplicationMaster可能运行Spark的Driver或者Flink的JobManager相关执行计划生成逻辑等;计算节点运行Executor或者TaskManager、等待任务分配以及执行具体计算任务。 -
用户程序运行期间,客户端与ApplicationMaster进行交互获取应用的运行状态,如果是实时常驻应用,会有相应的Web后台可以实时获取应用的运行状态。 -
整个应用结束之后,ApplicationMaster会向ResourceManager注销自己,释放Container资源。
以上是关于小白Spark工程师需要了解的Hadoop和YARN小知识的主要内容,如果未能解决你的问题,请参考以下文章
sh spark-submit-python-wordcount-yarn.sh