高速流水线,Jenkins Shared Pipeline
Posted 日拱一兵
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了高速流水线,Jenkins Shared Pipeline相关的知识,希望对你有一定的参考价值。
前言
不知道你的 team 当中是否采用敏捷开发,总之我们的 team 贯彻敏捷方法很彻底
随着敏捷方法的步伐加快,如何加快软件的交付速度变得极为重要,快速交付离不开 DevOps,而 DevOps 技术栈中,Jenkins 绝对是 CI 过程的核心角色。要充分高效的使用 Jenkins,自然离不开 Jenkinsfile
什么是 Jenkinsfile?
其实在前两篇文章中大家已经和 Jenkinsfile 照过面,只不过他们不是当时的主角:
终于不用跑龙套了,在 Jenkins 的世界中,pipeline(流水线)是我们可以和 Jenkins 互动的最小单元,而 Jenkins pipeline 既可以使用 Jenkinsfile 来定义,也可以通过 GUI 来定义。
通过 GUI 来简单认识或了解 Jenkins 是没问题的,真要用起来 Jenkins,还得用 Jenkinsfile,一句话解释:
Jenkinsfile 就是用来定义 Jenkins pipeline 的文本文件,最终按照我们的要求的步骤和 Jenkins 互动起来
两个最简单的要领就能区分出写 Jenkinsfile 的两种玩法:
-
Declarative Pipeline(声明式):Jenkinsfile 以
pipeline开始 -
Scripted Pipeline(脚本式):Jenkinsfile 以
node开始

推荐使用 Declarative Pipeline,因为它提供了很多高级/便利的特性, Jenkinsfile 虽好,写多了也是非常头疼的,如何减少写 code 是关键
为什么要用 Jenkins Shared Library?
当今微服务的世界,大个头的单体应用都被拆分成了多个小的应用,每个应用基本都会有相同的 Pipeline 步骤:Build,Test,Deploy。Declarative Pipeline 虽好,但每个小的应用都要写那么多重复的内容,作为懒惰的程序猿是忍不了的,因为他们可能仅仅可能是 Git Repo 等参数不同罢了
所以我们要做的就是把这些共同的内容提取出来,写在一个文件里,形成一个 shared library 让其他 Jenkinsfile 引用,这就避免了大量重复代码
这个shared library 也没什么神秘的,本质上还是一个 Jenkinsfile,只不过表现形式变成了一个 Groovy scripts
如何创建 Jenkins Shared Library?
创建 Jenkins Shared Library 很简单,只需要三步:
-
在 shared library Repo 的根目录创建一个名为 vars 的文件夹
-
在文件夹中创建你自己定义名称的 groovy 文件
.
├── Jenkinsfile
├── README.md
└── vars
├── javaProjectCommonLibrary.groovy
├── javaProjectMultiBranchAndParamsCommonLibrary.groovy
├── javaProjectMultiParamsCommonLibrary.groovy
├── nodeProjectCommonLibrary.groovy
└── pythonProjectCommonLibrary.groovy
1 directory, 7 files -
在groovy 文件中定义一个名为 call 的方法
//javaProjectCommonLibrary.groovy
def call(String name = 'rgyb') {
// 定义自己的通用步骤
echo "Hello, ${name}."
}
这就可以 push 你的 shared library 到 remote 了,在 Jenkins 中再配置一下这个 library 就好了
如何配置 Shared Library?
进入 Jenkins,依次点击 Manage Jenkins -> Configure System -> 找到 Global Pipeline Libraries, 添加 library 就好,然后 Save 就好了
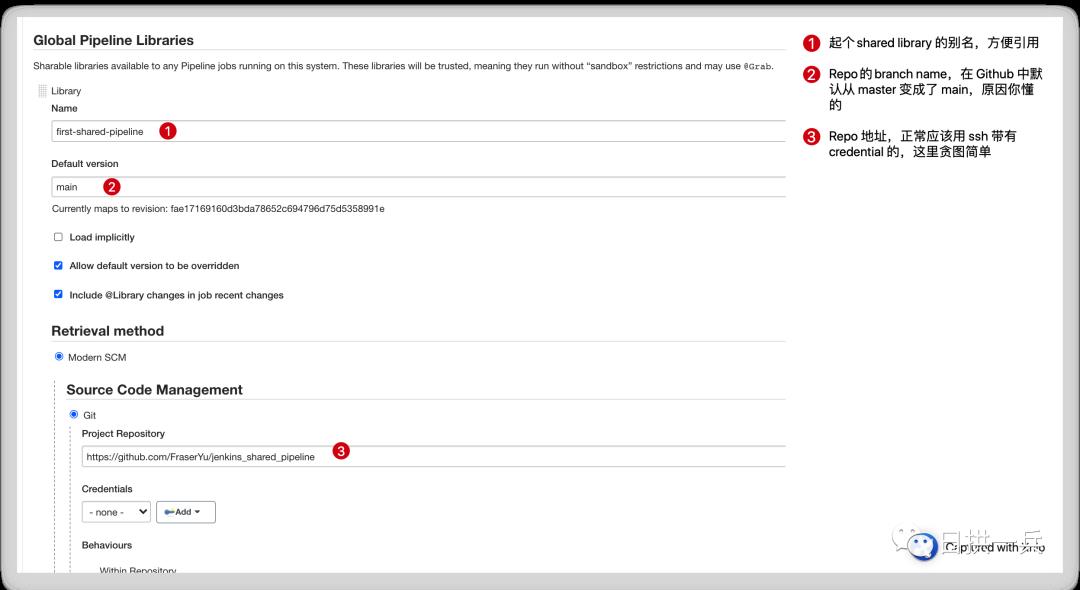
接下来就创建一个 Pipeline job 来引用这个 library
引用 Jenkins Shared Library
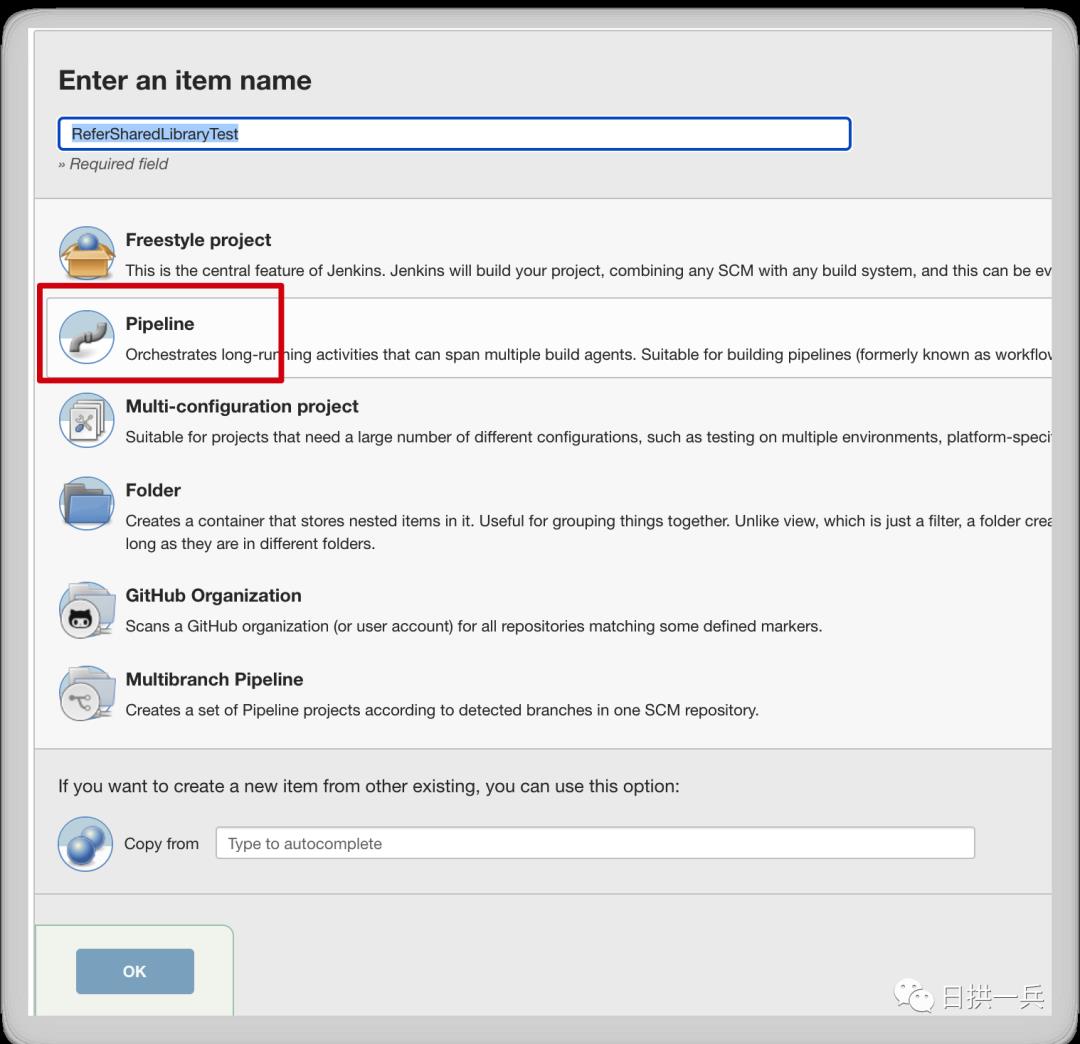
如下图,创建一个 pipeline 类型的 job
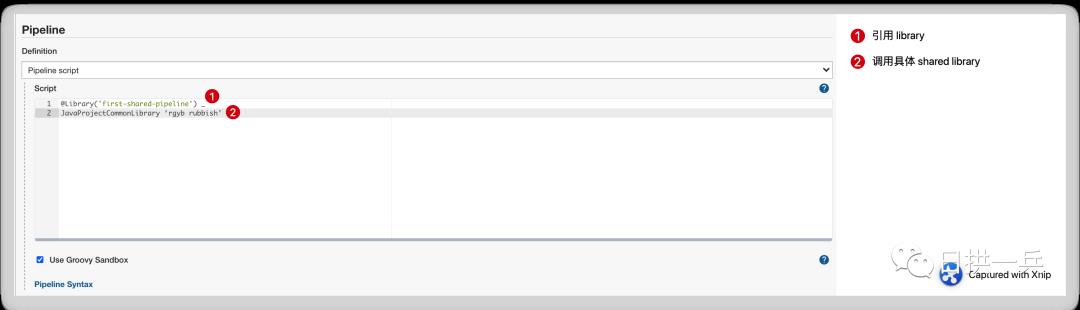
在 Pipeline 位置添加如下内容:
@Library('first-shared-pipeline') _
javaProjectCommonLibrary 'rgyb rubbish'
具体如下图
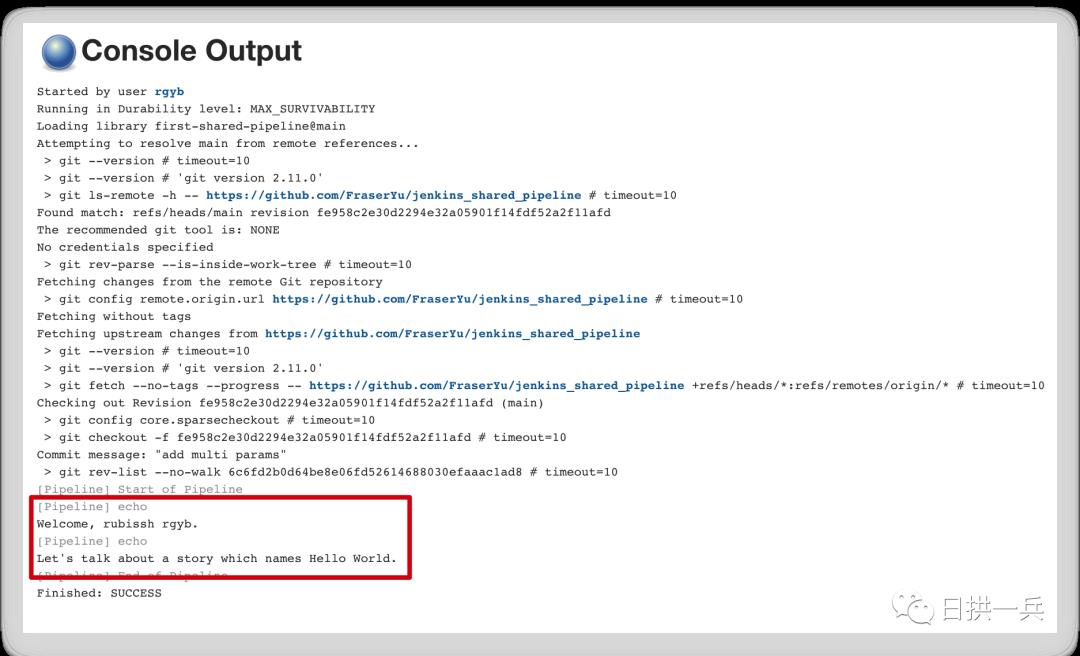
Save 之后就可以 build 了, 打开 log console,可以看到醒目的几个大字,大声的读出来:

到这里,自定义 Jenkins Shared Library 就已经搞定了。可实际项目中怎么可能只有一个参数这么简单的 pipeline,进阶玩法还是要知道的
Jenkins Shared Library 高级定义
接收多个参数很简单,只需要改一下 call 方法的参数类型就可以,比如我们定义了一个名为 javaProjectMultiParamsCommonLibrary.groovy 的 library,参数类型为 Map
//javaProjectMultiParamsCommonLibrary.groovy
def call(Map pipelineParams) {
//自定义code
echo "Welcome, ${pipelineParams.name}."
echo "Let's talk about a story which names ${pipelineParams.storyName}."
}
修改一下 job 中传入参数的方式:
@Library('first-shared-pipeline') _
javaProjectMultiParamsCommonLibrary(name: 'rubissh rgyb', storyName: 'Hello World')
看一下 build 结果:
貌似完美,但还是有问题:
-
shared library 是供其它 Jenkinsfile 引用的,每个项目都应该有自己可维护的 Jenkinsfile,直接像上面写道 Jenkins Pipeline script 中,显然不是很好的方式,我们也需要将每个项目的 Jenkinsfile 维护在相应的Repo 中 -
大的项目可能有非常多的参数,当参数多的时候,以这种方式调用,不是很优雅,我们希望项目中的 Jenkinsfile 是一种配置文件形式,即 key=value -
一个项目可能有多个 branch,每个 branch 的使用应该互不影响
为了解决上述问题,我们再创建一个名为 javaProjectMultiBranchAndParamsCommonLibrary.groovy 的 shared library,内容如下:
//javaProjectMultiBranchAndParamsCommonLibrary.groovy
def call(body) {
// evaluate the body block, and collect configuration into the object
def pipelineParams= [:]
body.resolveStrategy = Closure.DELEGATE_FIRST
body.delegate = pipelineParams
body()
echo "${pipelineParams.NAME}"
echo "${pipelineParams.STORY_NAME}"
echo "${pipelineParams.VERSION}"
}
body 参数应该是一个闭包,它将闭包中的值设置为对应的配置对象,这样我们只需要在 Jenkinsfile 中按照 key=value 向 Map 中填写参数就可以了
在 Repo 根目录创建 Jenkinsfile,内容如下:
@Library('second-shared-pipeline') _
javaProjectMultiBranchAndParamsCommonLibrary {
NAME = 'rgyb rubbish'
STORY_NAME = 'hello world'
VERSION = '1.1.0'
}创
这里引用 shared library 的名称为:
second-shared-pipeline
接下来创建一个 Multibranch Pipeline 类型的 job
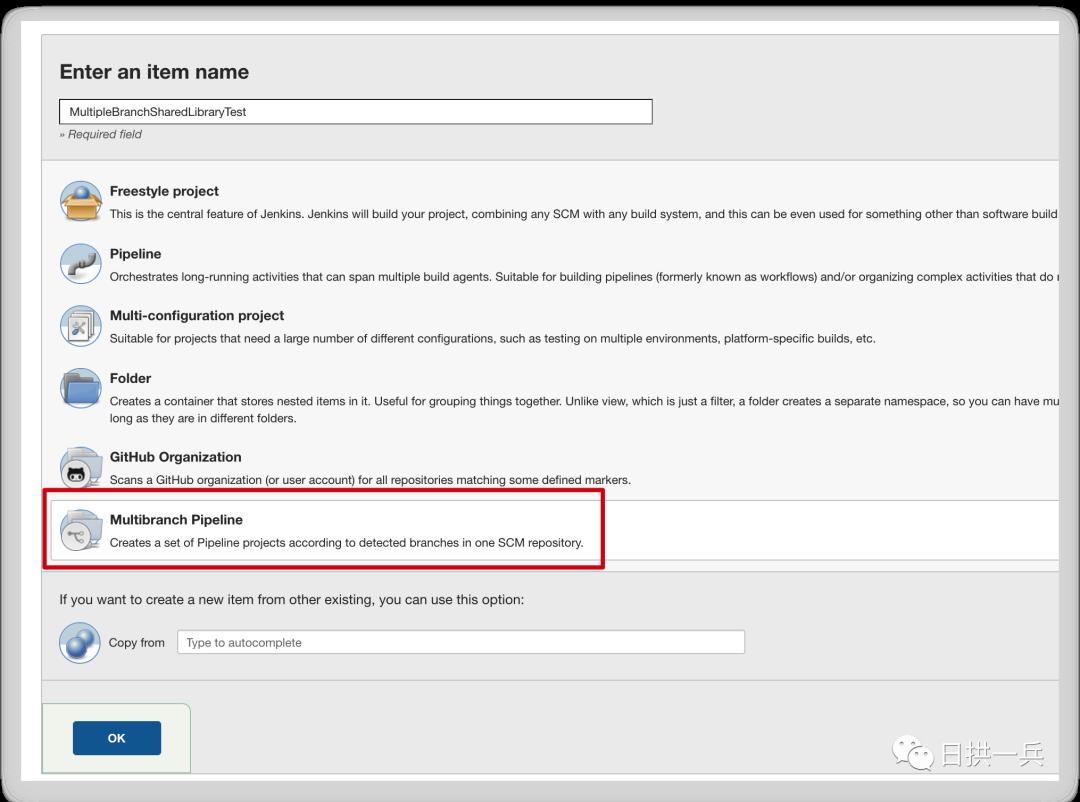
填写 Jenkinsfile 所在 Branch 的信息
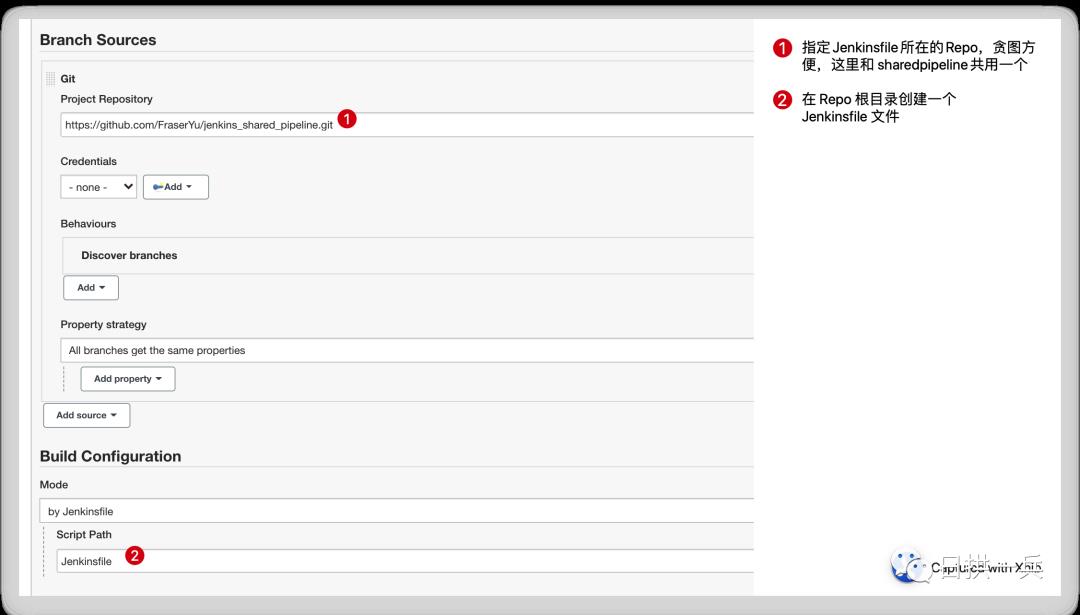
填写 shared library 的信息,这里名称为 second-shared-pipeline
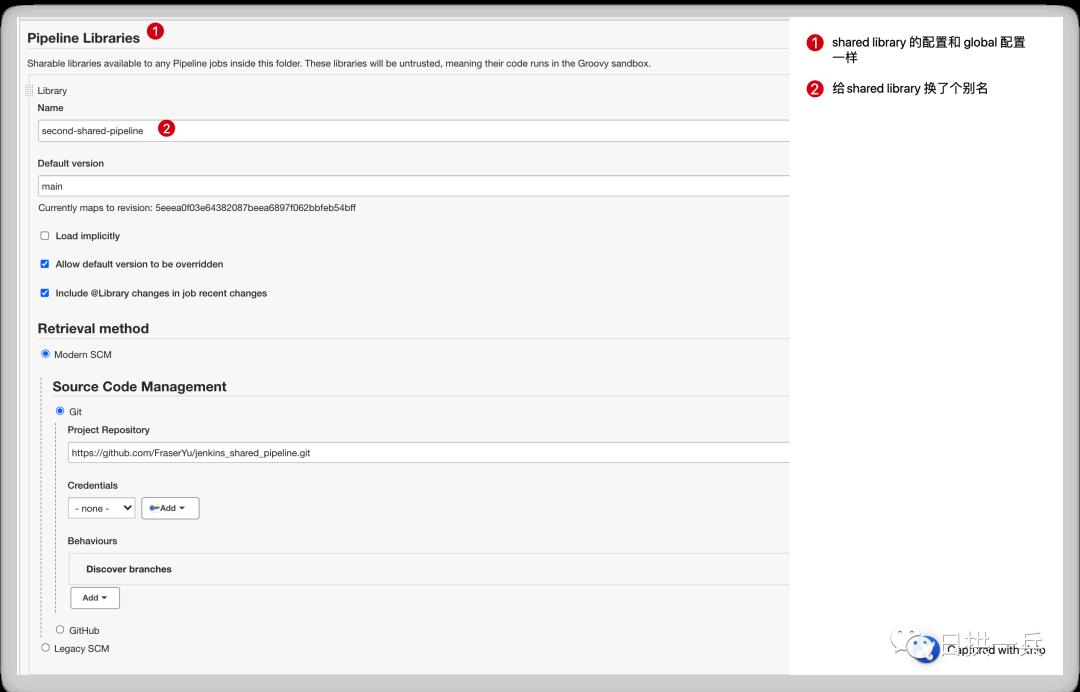
点击 Save 就会扫描当前 Repo 的所有 branch,这里目前只有 main branch
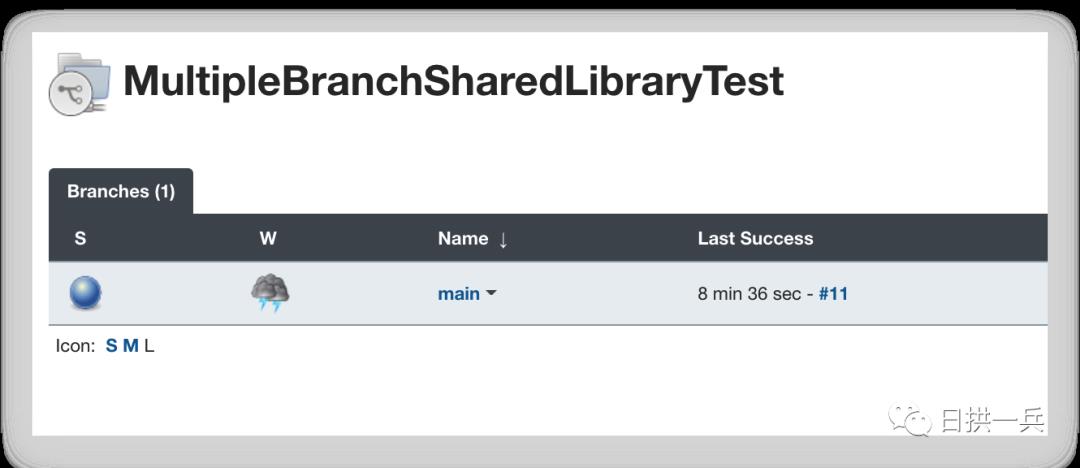
进入 main branch,点击 build,就会正常看到结果了
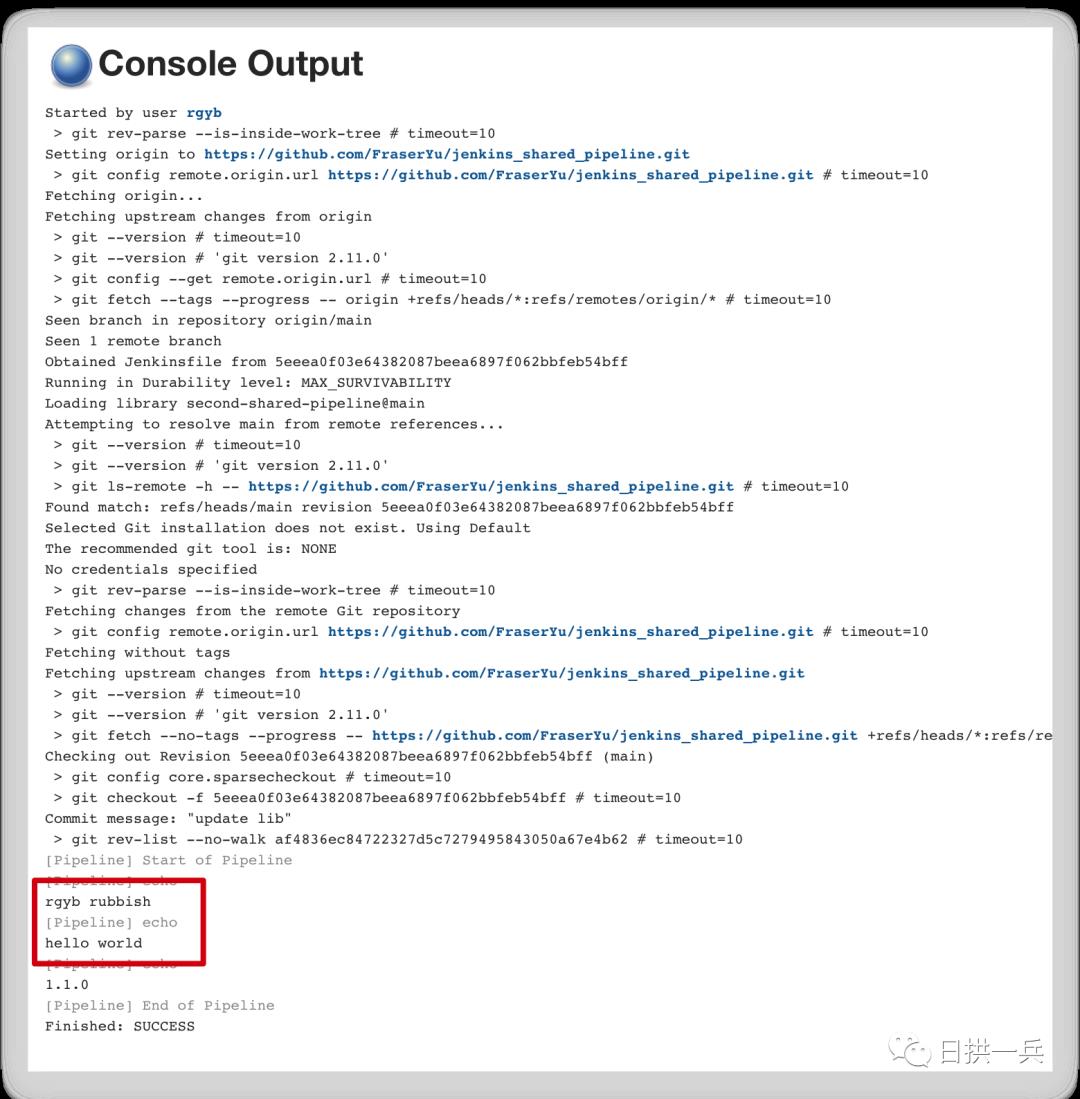
上面在 Jenkinsfile 的变量引用上,我们都要用 "${pipelineParams.XXXXX}" 这种形式,当参数变多时,也在不断重复写pipelineParams , 所以我们要继续优化,将所有的变量放到内置的 env 对象当中去,这样就可以直接使用变量名称了。结合 pipeline 的 Build, Test,Deploy 步骤,我们再修改一下 shared library(注意 Load Variables stage)内容如下:
def call(body) {
// evaluate the body block, and collect configuration into the object
def pipelineParams= [:]
body.resolveStrategy = Closure.DELEGATE_FIRST
body.delegate = pipelineParams
body()
echo "${pipelineParams.NAME}"
echo "${pipelineParams.STORY_NAME}"
echo "${pipelineParams.VERSION}"
pipeline {
agent none
stages {
stage('Load Variables') {
steps {
script {
pipelineParams.each {
k, v -> env."${k}" = "${v}"
}
}
}
}
stage('Build') {
steps {
echo "${BUILD_STAGE}"
}
}
stage('Test') {
steps {
echo "${TEST_STAGE}"
}
}
stage('Deploy') {
steps {
echo "${DEPLOY_STAGE}"
}
}
}
}
}
然后在 Jenkinsfile 中添加几个参数:
@Library('second-shared-pipeline') _
javaProjectMultiBranchAndParamsCommonLibrary {
NAME = 'rgyb rubbish'
STORY_NAME = 'hello world'
VERSION = '1.1.0'
BUILD_STAGE = 'this is build stage'
TEST_STAGE = 'this is test stage'
DEPLOY_STAGE = 'this is deploy stage'
}
再次 build,将会看到如下结果
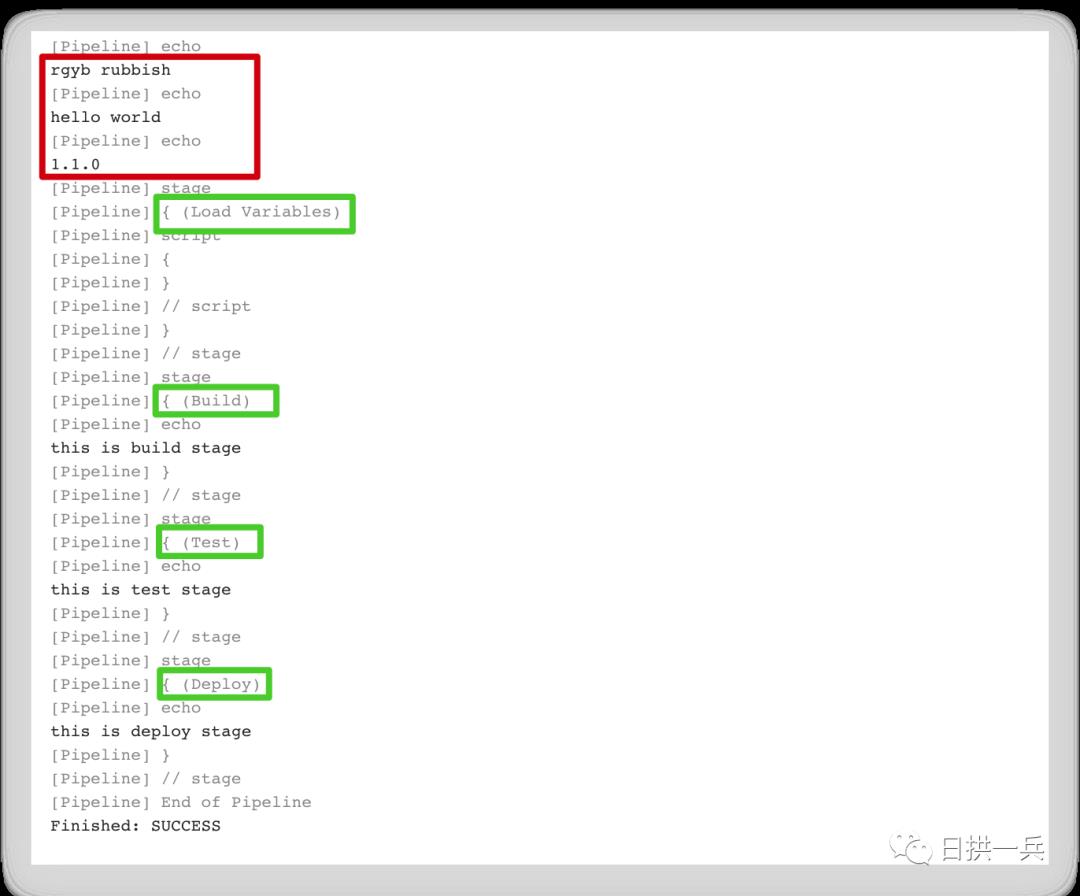
相信到这里你已经掌握如何自定义 shared libray 以及如何在 Jenkinsfile 中引用 shared library 了
总结
我们从当今服务形式出发,发现 DevOps CI 的痛点,结合 Demo,一点点掌握了自定义 shared library,以及实际项目中的规范,过往的 Jenkins 的内容并不多,结合文章开头的两篇文章,玩转 Jenkins Pipeline 就已经不是问题了,如果你项目中有类似需要优化的情况,撸起袖子干吧,做可以帮组内成员省力气的事情,都是加分项哦......
以上是关于高速流水线,Jenkins Shared Pipeline的主要内容,如果未能解决你的问题,请参考以下文章