Python基础入门自学——16--常用内建模块2
Posted kaoa000
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Python基础入门自学——16--常用内建模块2相关的知识,希望对你有一定的参考价值。
urllib
urllib提供了一系列用于操作URL的功能。
Get
urllib的request模块可以非常方便地抓取URL内容,也就是发送一个GET请求到指定的页面,然后返回HTTP的响应:
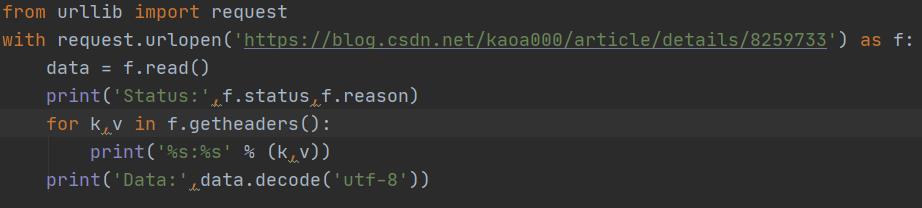
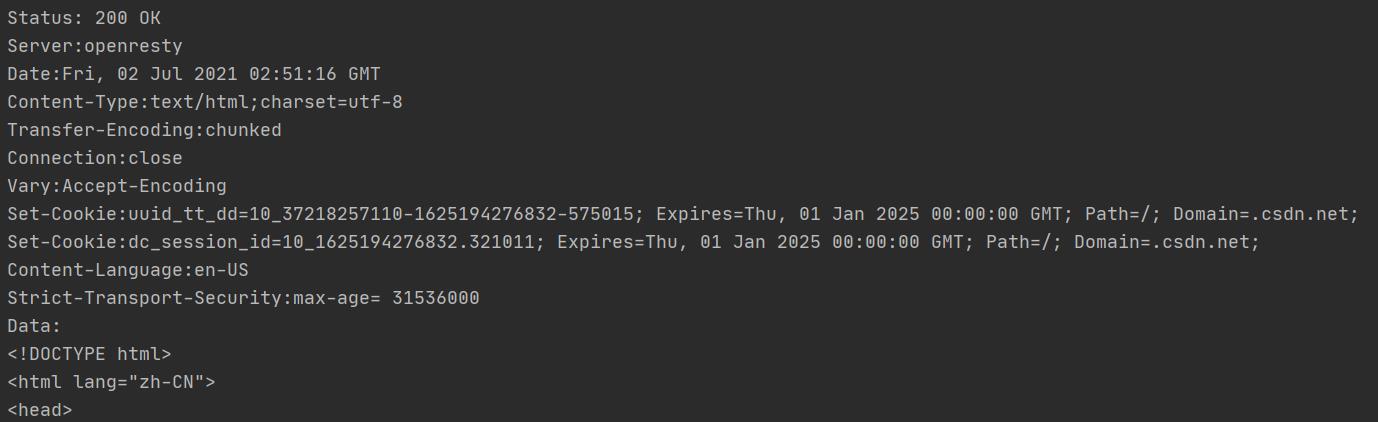
可以看到HTTP响应的头和JSON数据:
如果要想模拟浏览器发送GET请求,就需要使用Request对象,通过往Request对象添加HTTP头,就可以把请求伪装成浏览器。例如,模拟iPhone 6去请求豆瓣首页:

会返回适合iPhone的移动版网页。
Post
如果要以POST发送一个请求,只需要把参数data以bytes形式传入。
模拟一个微博登录,先读取登录的邮箱和口令,然后按照weibo.cn的登录页的格式以username=xxx&password=xxx的编码传入:

Handler
如果还需要更复杂的控制,比如通过一个Proxy去访问网站,我们需要利用ProxyHandler来处理:
proxy_handler = urllib.request.ProxyHandler({'http': 'http://www.example.com:3128/'})
proxy_auth_handler = urllib.request.ProxyBasicAuthHandler()
proxy_auth_handler.add_password('realm', 'host', 'username', 'password')
opener = urllib.request.build_opener(proxy_handler, proxy_auth_handler)
with opener.open('http://www.example.com/login.html') as f:
pass
urllib提供的功能就是利用程序去执行各种HTTP请求。如果要模拟浏览器完成特定功能,需要把请求伪装成浏览器。伪装的方法是先监控浏览器发出的请求,再根据浏览器的请求头来伪装,User-Agent头就是用来标识浏览器的。
XML
DOM vs SAX
操作XML有两种方法:DOM和SAX。DOM会把整个XML读入内存,解析为树,因此占用内存大,解析慢,优点是可以任意遍历树的节点。SAX是流模式,边读边解析,占用内存小,解析快,缺点是需要自己处理事件。正常情况下,优先考虑SAX。
在Python中使用SAX解析XML非常简洁,通常关心的事件是start_element,end_element和char_data,准备好这3个函数,然后就可以解析xml了。
当SAX解析器读到一个节点时:
<a href="/">python</a>
会产生3个事件:
start_element事件,在读取<a href="/">时;
char_data事件,在读取python时;
end_element事件,在读取</a>时。
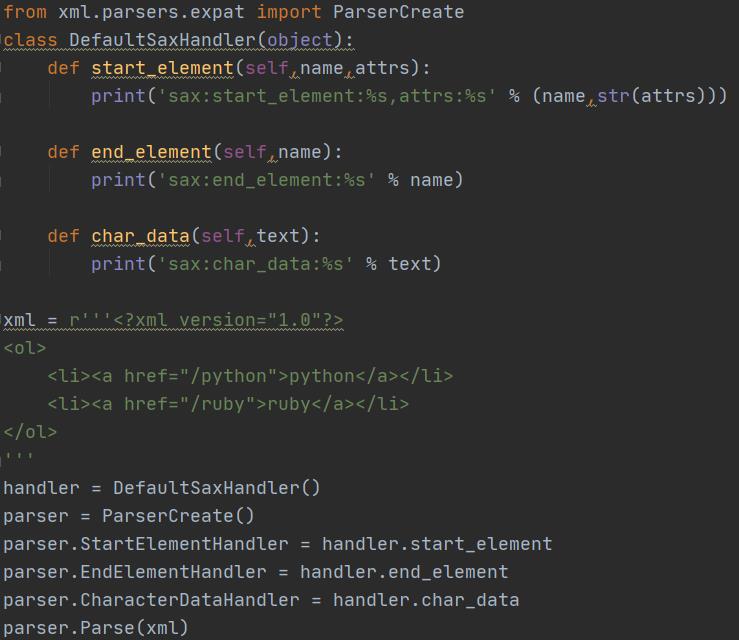
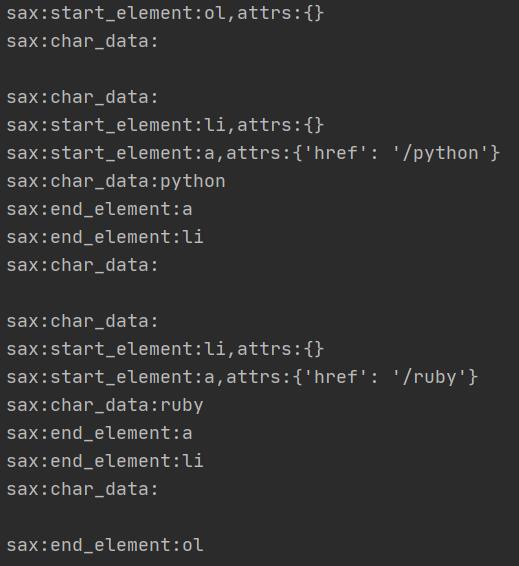
需要注意的是读取一大段字符串时,CharacterDataHandler可能被多次调用,所以需要自己保存起来,在EndElementHandler里面再合并。
HTMLParser
如果要编写一个搜索引擎,第一步是用爬虫把目标网站的页面抓下来,第二步就是解析该HTML页面,看看里面的内容到底是新闻、图片还是视频。假设第一步已经完成了,第二步应该如何解析HTML呢?HTML本质上是XML的子集,但是HTML的语法没有XML那么严格,所以不能用标准的DOM或SAX来解析HTML。Python提供了HTMLParser来非常方便地解析HTML,只需简单几行代码:
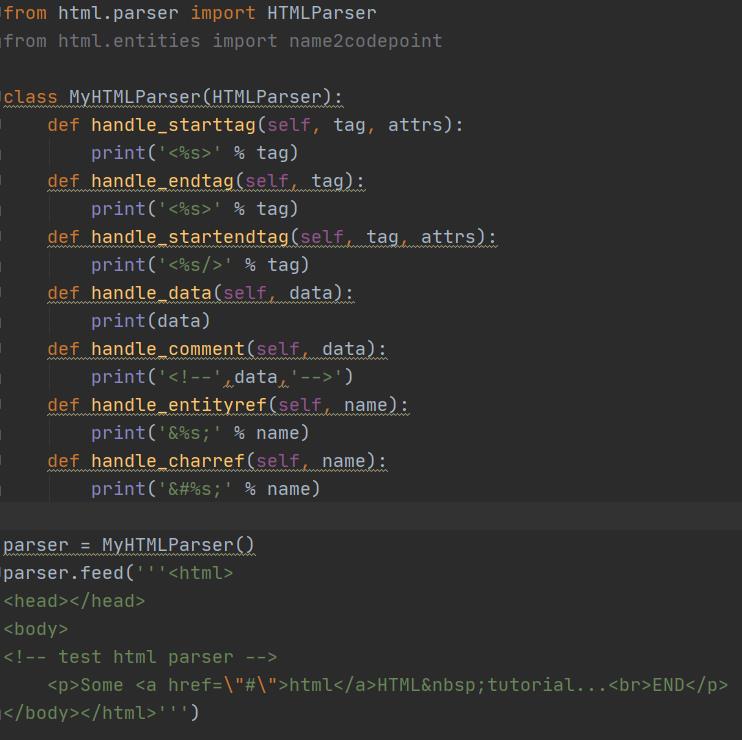
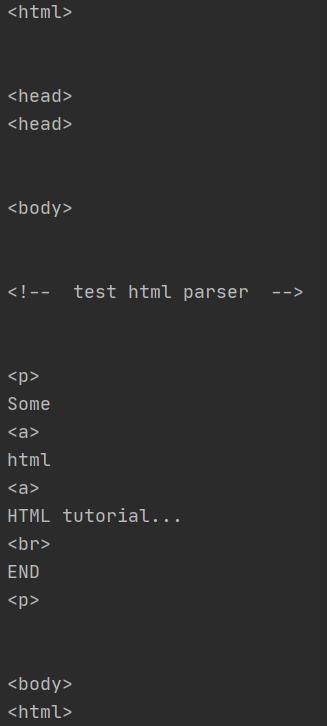
feed()方法可以多次调用,也就是不一定一次把整个HTML字符串都塞进去,可以一部分一部分塞进去。特殊字符有两种,一种是英文表示的 ,一种是数字表示的Ӓ,这两种字符都可以通过Parser解析出来。
利用HTMLParser,可以把网页中的文本、图像等解析出来。
常用第三方模块
基本上,所有的第三方模块都会在PyPI - the Python Package Index上注册,只要找到对应的模块名字,即可用pip安装。
Pillow
PIL:Python Imaging Library,已经是Python平台事实上的图像处理标准库了。由于PIL仅支持到Python 2.7,一群志愿者在PIL的基础上创建了兼容的版本,名字叫Pillow,支持最新Python 3.x,可以直接安装使用Pillow。
安装Pillow
$ pip install pillow
如果遇到Permission denied安装失败,请加上sudo重试。
操作图像:最常见的图像缩放操作,其他功能如切片、旋转、滤镜、输出文字、调色板等,还有模糊效果,PIL的ImageDraw提供了一系列绘图方法,可以直接绘图。比如要生成字母验证码图片,PIL提供了操作图像的强大功能,可以通过简单的代码完成复杂的图像处理。
requests
前面讲解了Python内置的urllib模块,用于访问网络资源。但是,它用起来比较麻烦,而且,缺少很多实用的高级功能。更好的方案是使用requests。它是一个Python第三方库,处理URL资源特别方便。
安装requests
$ pip install requests
chardet
字符串编码一直是令人非常头疼的问题,尤其是在处理一些不规范的第三方网页的时候。虽然Python提供了Unicode表示的str和bytes两种数据类型,并且可以通过encode()和decode()方法转换,但是,在不知道编码的情况下,对bytes做decode()不好做。
对于未知编码的bytes,要把它转换成str,需要先“猜测”编码。猜测的方式是先收集各种编码的特征字符,根据特征字符判断,就能有很大概率“猜对”。chardet第三方库用来检测编码。
安装chardet
$ pip install chardet
使用chardet,当拿到一个bytes时,就可以对其检测编码:
>>> chardet.detect(b'Hello, world!')
{'encoding': 'ascii', 'confidence': 1.0, 'language': ''}
检测出的编码是ascii,注意到还有个confidence字段,表示检测的概率是1.0(即100%)。
试试检测GBK编码的中文:
>>> data = '离离原上草,一岁一枯荣'.encode('gbk')
>>> chardet.detect(data)
{'encoding': 'GB2312', 'confidence': 0.7407407407407407, 'language': 'Chinese'}
检测的编码是GB2312,注意到GBK是GB2312的超集,两者是同一种编码,检测正确的概率是74%,language字段指出的语言是'Chinese'。
psutil
用Python来编写脚本简化日常的运维工作是Python的一个重要用途。在Linux下,有许多系统命令可以时刻监控系统运行的状态,如ps,top,free等等。要获取这些系统信息,Python可以通过subprocess模块调用并获取结果。但这样做显得很麻烦,尤其是要写很多解析代码。
在Python中获取系统信息的另一个好办法是使用psutil这个第三方模块。psutil = process and system utilities,它不仅可以通过一两行代码实现系统监控,还可以跨平台使用,支持Linux/UNIX/OSX/Windows等。
安装psutil
$ pip install psutil
获取CPU的信息:
>>> import psutil
>>> psutil.cpu_count() # CPU逻辑数量
4
>>> psutil.cpu_count(logical=False) # CPU物理核心
2
# 2说明是双核超线程, 4则是4核非超线程
统计CPU的用户/系统/空闲时间:
>>> psutil.cpu_times()
scputimes(user=10963.31, nice=0.0, system=5138.67, idle=356102.45)
psutil获取物理内存和交换内存信息:
>>> psutil.virtual_memory()
>>> psutil.swap_memory()
获取磁盘信息:
>>> psutil.disk_partitions() # 磁盘分区信息
>>> psutil.disk_usage('/') # 磁盘使用情况
>>> psutil.disk_io_counters() # 磁盘IO
获取网络信息:
>>> psutil.net_io_counters() # 获取网络读写字节/包的个数
>>> psutil.net_if_addrs() # 获取网络接口信息
>>> psutil.net_if_stats() # 获取网络接口状态
>>> psutil.net_connections()
获取进程信息:
>>> psutil.pids() # 所有进程ID
>>> p = psutil.Process(3776) # 获取指定进程ID=3776
>>> p.name() # 进程名称
>>> p.exe() # 进程exe路径
>>> p.cwd() # 进程工作目录
>>> p.cmdline() # 进程启动的命令行
>>> p.ppid() # 父进程ID
>>> p.parent() # 父进程
>>> p.children() # 子进程列表
>>> p.status() # 进程状态
>>> p.username() # 进程用户名
>>> p.create_time() # 进程创建时间
>>> p.terminal() # 进程终端
>>> p.cpu_times() # 进程使用的CPU时间
>>> p.memory_info() # 进程使用的内存
>>> p.open_files() # 进程打开的文件
>>> p.connections() # 进程相关网络连接
>>> p.num_threads() # 进程的线程数量
>>> p.threads() # 所有线程信息
>>> p.environ() # 进程环境变量
>>> p.terminate() # 结束进程
virtualenv
在开发Python应用程序的时候,系统安装的Python3只有一个版本。所有第三方的包都会被pip安装到Python3的site-packages目录下。
如果要同时开发多个应用程序,如果应用A需要jinja 2.7,而应用B需要jinja 2.6怎么办?
这种情况下,每个应用可能需要各自拥有一套“独立”的Python运行环境。virtualenv就是用来为一个应用创建一套“隔离”的Python运行环境。
安装virtualenv:
$ pip3 install virtualenv
假定要开发一个新的项目,需要一套独立的Python运行环境,可以这么做:
第一步,创建目录:
Mac:~ michael$ mkdir myproject
Mac:~ michael$ cd myproject/
Mac:myproject michael$
第二步,创建一个独立的Python运行环境,命名为venv:
Mac:myproject michael$ virtualenv --no-site-packages venv
Using base prefix '/usr/local/.../Python.framework/Versions/3.4'
New python executable in venv/bin/python3.4
Also creating executable in venv/bin/python
Installing setuptools, pip, wheel...done.
命令virtualenv就可以创建一个独立的Python运行环境,还加上了参数--no-site-packages,这样,已经安装到系统Python环境中的所有第三方包都不会复制过来,这样,就得到了一个不带任何第三方包的“干净”的Python运行环境。
新建的Python环境被放到当前目录下的venv目录。有了venv这个Python环境,可以用source进入该环境:
Mac:myproject michael$ source venv/bin/activate
(venv)Mac:myproject michael$
注意到命令提示符变了,有个(venv)前缀,表示当前环境是一个名为venv的Python环境。
下面正常安装各种第三方包,并运行python命令:
(venv)Mac:myproject michael$ pip install jinja2
...
Successfully installed jinja2-2.7.3 markupsafe-0.23
(venv)Mac:myproject michael$ python myapp.py
...
在venv环境下,用pip安装的包都被安装到venv这个环境下,系统Python环境不受任何影响。也就是说,venv环境是专门针对myproject这个应用创建的。
退出当前的venv环境,使用deactivate命令:
(venv)Mac:myproject michael$ deactivate
Mac:myproject michael$
此时就回到了正常的环境,现在pip或python均是在系统Python环境下执行。
完全可以针对每个应用创建独立的Python运行环境,这样就可以对每个应用的Python环境进行隔离。
virtualenv是如何创建“独立”的Python运行环境的呢?原理很简单,就是把系统Python复制一份到virtualenv的环境,用命令source venv/bin/activate进入一个virtualenv环境时,virtualenv会修改相关环境变量,让命令python和pip均指向当前的virtualenv环境。
以上是关于Python基础入门自学——16--常用内建模块2的主要内容,如果未能解决你的问题,请参考以下文章