Hbase原理深入解析及集成Hadoop
Posted 大数据Java张勇Linux数据库LTL
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Hbase原理深入解析及集成Hadoop相关的知识,希望对你有一定的参考价值。
1.Hadoop生态系统
Zookeeper分布式监控中心:
HDFS的NameNode和MapReduce高可用。
zookeeper内部维护一个内存数据库。
存储Hbase一些数据
MapReduce:分布式计算框架
Hive:数据仓库
HBase:非关系型数据库
HDFS:分布式文件系统
Flume:日志收集工具(离线分析,离线数据处理)
Sqoop:关系数据ETL工具(非关系型数据与关系型数据转换工具)
Mahout:数据挖掘(将机器学习算法通过MapReduce做开源实现,可以通过MapReduce(进行分析,提高效率)
Pig(淘汰):数据流处理语言,通过编写sql脚本分析HDFS数据。
Shark(淘汰):类似于Pig。
2.HBase简介
Hbase-Hadoop Database是一个高可用、高性能、面向列、可伸缩、实时读写的分布式数据库 。
可伸缩:可根据负载增减节点。
面向列:相对于行式数据库,空间利用率高。
利用HadoopHDFS作为其文件存储系统,利用Hadoop MapReduce来处理HBase中的海量数据,利用Zookeeper作为分布式协同服务。
主要用来存储非结构化和半结构化数据。
3.HBase优点
HBase是一种构建在HDFS之上的分布式、面向列的存储系统。在需要实时读写、随机访问超大规模数据集时,可以使用HBase。
尽管已经有许多数据存储和访问的策略和实现方法,但事实上大多数解决方案,特别是一些关系类型的,在构建时并没有考虑超大规模和分布式的特点。许多商家通过复制和分区的方法来扩充数据库使其突破单个节点的界限,但这些功能通常都是事后增加的,安装和维护都和复杂。同时,也会影响RDBMS的特定功能,例如联接、复杂的查询、触发器、视图和外键约束这些操作在大型的RDBMS上的代价相当高,甚至根本无法实现。
HBase从另一个角度处理伸缩性问题。它通过线性方式从下到上增加节点来进行扩展。HBase不是关系型数据库,也不支持SQL,但是它有自己的特长,这是RDBMS不能处理的,HBase巧妙地将大而稀疏的表放在商用的服务器集群上。
HBase 是Google Bigtable 的开源实现,与Google Bigtable 利用GFS作为其文件存储系统类似, HBase 利用Hadoop HDFS 作为其文件存储系统;Google 运行MapReduce 来处理Bigtable中的海量数据, HBase 同样利用Hadoop MapReduce来处理HBase中的海量数据;Google Bigtable 利用Chubby作为协同服务, HBase 利用Zookeeper作为对应。
大:一个表可以有上亿行,上百万列。
面向列:面向列表(簇)的存储和权限控制,列(簇)独立检索。
稀疏:对于为空(NULL)的列,并不占用存储空间,因此,表可以设计的非常稀疏。
无模式:每一行都有一个可以排序的主键和任意多的列,列可以根据需要动态增加,同一张表中不同的行可以有截然不同的列。
数据多版本:每个单元中的数据可以有多个版本,默认情况下,版本号自动分配,版本号就是单元格插入时的时间戳。
数据类型单一:HBase中的数据都是字符串,没有类型。
4、逻辑存储模型
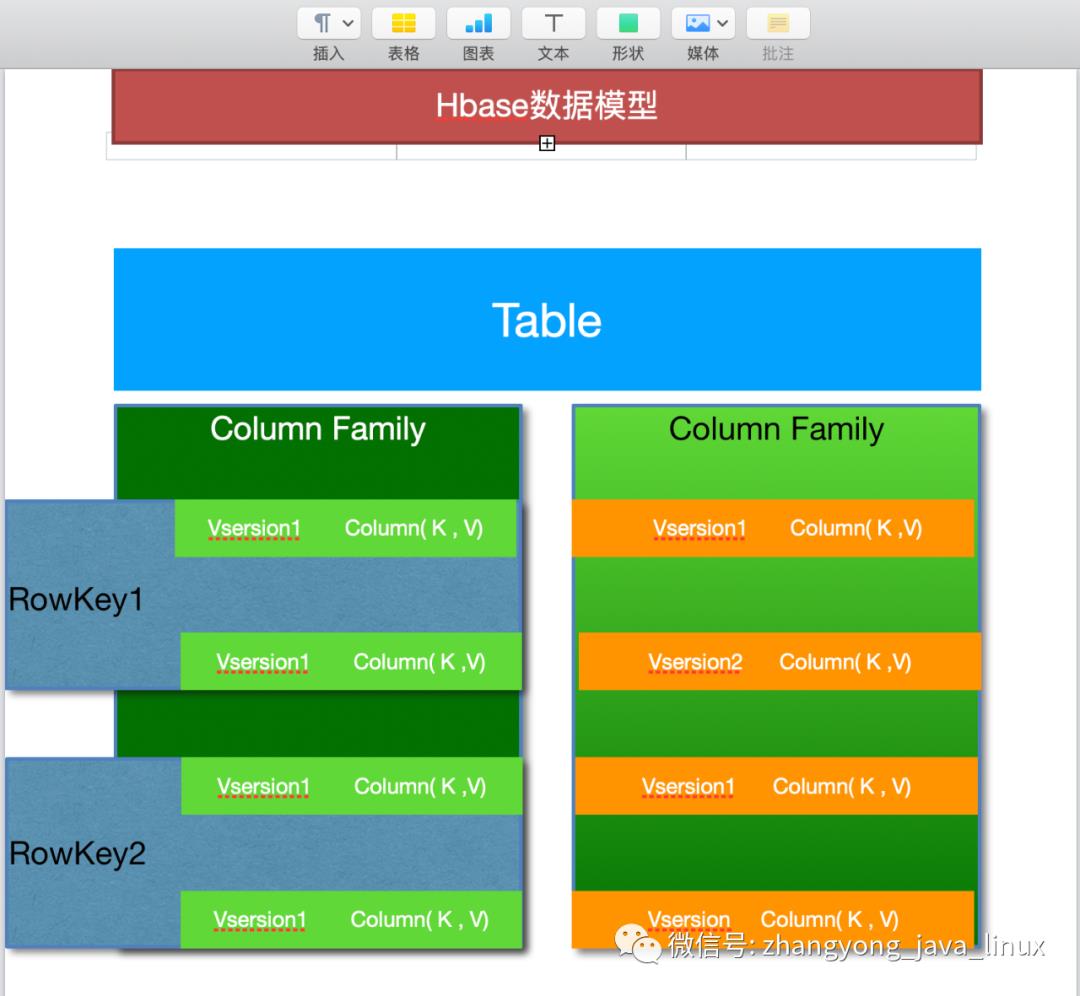
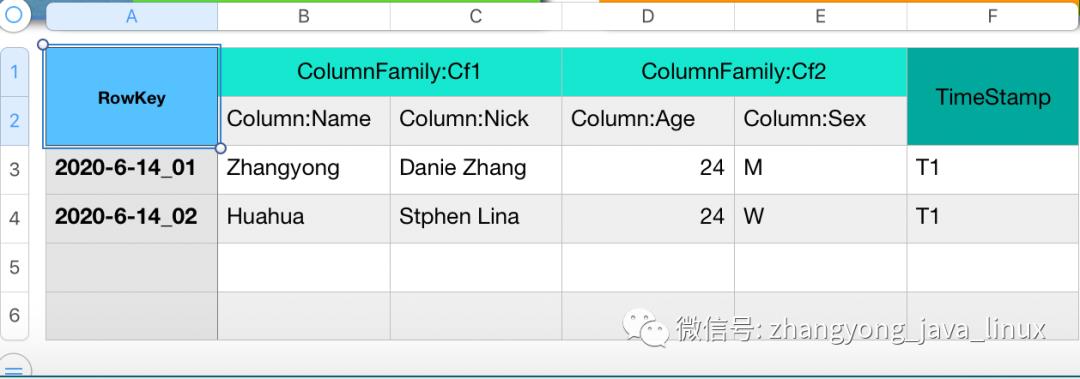
RowKey:Hbase使用Rowkey来唯一的区分某一行的数据。如图中"2020-6-14_01"
列族:Hbase通过列族划分数据的存储,列族下面可以包含任意多的列,实现灵活的数据存取。Hbase的列族不是越多越好,官方推荐的是列族最好小于或者等于3。我们使用的场景一般是1个列族。如图中的“CF1”列族,下面包含两个列:"Name"和"Nick"。
时间戳:TimeStamp对Hbase来说至关重要,因为它是实现Hbase多版本的关键。在Hbase中使用不同的timestame来标识相同rowkey行对应的不通版本的数据。
Cell:HBase 中通过 rowkey 和 columns 确定的为一个存储单元称为 cell。每个 cell 都保存着同一份 数据的多个版本。版本通过时间戳来索引。
5、Hbase总体架构
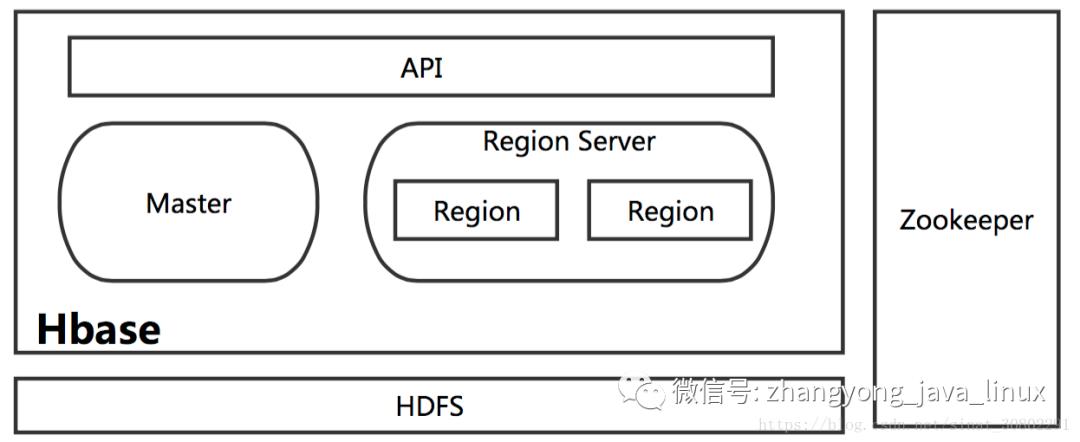
包括了HMaster、HRegionSever、HRegion、HLog、Store、MemStore、StoreFile、HFile等。接下来我先用自己的理解把这个结构描述一下,然后再分别介绍每个部分,建议再开一个屏幕对照着架构图看。HBase底层依赖HDFS,通过DFS Cilent进行HDFS操作。HMaster负责把HRegion分配给HRegionServer,每一个HRegionServer可以包含多个HRegion,多个HRegion共享HLog,HLog用来做灾难恢复。每一个HRegion由一个或多个Store组成,一个Store对应表的一个列族,每个Store中包含与其对应的MemStore以及一个或多个StoreFile(是实际数据存储文件HFile的轻量级封装),MemStore是在内存中的,保存了修改的数据,MemStore中的数据写到文件中就是StoreFile。
5.1 HMaster
HMaster的主要功能有:
①把HRegion分配到某一个RegionServer。
②有RegionServer宕机了,HMaster可以把这台机器上的Region迁移到active的RegionServer上。
③对HRegionServer进行负载均衡。
④通过HDFS的dfs client接口回收垃圾文件(无效日志等)
注:HMaster没有单点问题,HBase中可以启动多个HMaster,通过Zookeeper的Master Election机制保证总有一个Master运行。
5.2 HRegionServer
①维护HMaster分配给它的HRegion,处理对这些HRegion的IO请求,也就是说客户端直接和HRegionServer打交道。(从图中也能看出来)
②负责切分正在运行过程中变得过大的HRegion
5.3 HRegion
下面我们看看HRegion的结构:
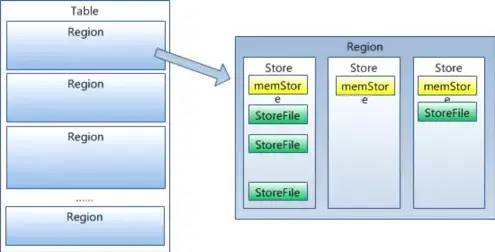
每个HRegion由多个Store构成,每个Store保存一个列族(Columns Family),表有几个列族,则有几个Store,每个Store由一个MemStore和多个StoreFile组成,MemStore是Store在内存中的内容,写到文件后就是StoreFile。StoreFile底层是以HFile的格式保存。
5.4 HLog
HLog(WAL log):WAL意为write ahead log(预写日志),用来做灾难恢复使用,HLog记录数据的变更,包括序列号和实际数据,所以一旦region server 宕机,就可以从log中回滚还没有持久化的数据。
5.5 HFile
HBase的数据最终是以HFile的形式存储在HDFS中的,HBase中HFile有着自己的格式。
6、Hbase集成Hadoop
hadoop
core-site.xml 配置文件添加以下内容
<configuration><property><name>hadoop.tmp.dir</name><value>file:/usr/local/hadoop/tmp</value><description>Abase for other temporary directories.</description></property><property><name>fs.defaultFS</name><value>hdfs://192.168.176.128:9000</value></property></configuration>
hadoop
hadoop-env.sh 配置文件添加详细的jdk安装路径
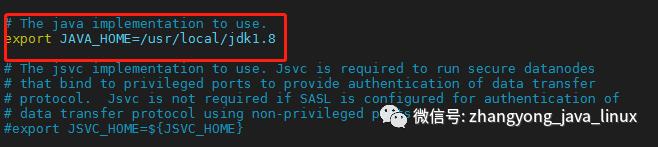
hadoop
hdfs-site.xml 配置文件添加以下内容
<configuration><property><name>dfs.replication</name><value>1</value></property><property><name>dfs.namenode.name.dir</name><value>file:/usr/local/hadoop/tmp/dfs/name</value></property><property><name>dfs.datanode.data.dir</name><value>file:/usr/local/hadoop/tmp/dfs/data</value></property></configuration>
hadoop
mapred-site.xml 配置文件添加以下内容
<configuration><property><name>mapred.job.tracker</name><value>localhost:9001</value></property></configuration>
zookeeper
zoo.cfg 配置文件添加以下内容
# The number of milliseconds of each ticktickTime=2000# The number of ticks that the initial# synchronization phase can takeinitLimit=10# The number of ticks that can pass between# sending a request and getting an acknowledgementsyncLimit=5# the directory where the snapshot is stored.# do not use /tmp for storage, /tmp here is just# example sakes.dataDir=/usr/local/zookeeper/logs# the port at which the clients will connectclientPort=2181
hbase
hbase-env.sh 配置文件添加以下内容
注意2个地方jdk全路径


hbase
hbase-site.xml 配置文件添加以下内容
<configuration><property><name>hbase.cluster.distributed</name><value>true</value></property><property><name>hbase:rootdir</name><value>hdfs://localhost:9000/hbase</value></property><!-- 新增的配置 页面web地址--><property><name>hbase.master.info.port</name><value>60010</value></property><!-- 新增的配置 --><property><name>hbase.zookeeper.quorum</name><value>192.168.176.128</value></property><property><name>hbase.zookeeper.property.dataDir</name><value>/usr/local/hbase/zy_zkdata</value></property><property><name>hbase.tmp.dir</name><value>/usr/local/hbase/zy_tmp</value></property></configuration>
需要启动的步骤:
第一步启动hadoop相关的
/sbin# ./start-dfs.sh
jps
63927 SecondaryNameNode
63575 NameNode
63736 DataNode
64042 Jps 自带的
sbin# ./start-yarn.sh
jps
64112 ResourceManager
64418 NodeManager
63927 SecondaryNameNode
63575 NameNode
63736 DataNode
64478 Jps
第二步启动zookeeper相关的
zookeeper# bin/zkServer.sh start
jps
64112 ResourceManager
64418 NodeManager
64597 QuorumPeerMain
63927 SecondaryNameNode
63575 NameNode
64631 Jps
63736 DataNode
第三部启动hbase相关的
hbase/bin# ./start-hbase.sh
jps
64112 ResourceManager
64418 NodeManager
64964 HMaster
64597 QuorumPeerMain
63927 SecondaryNameNode
63575 NameNode
63736 DataNode
65100 HRegionServer
65199 Jps
启动hbase命令:
hbase shell
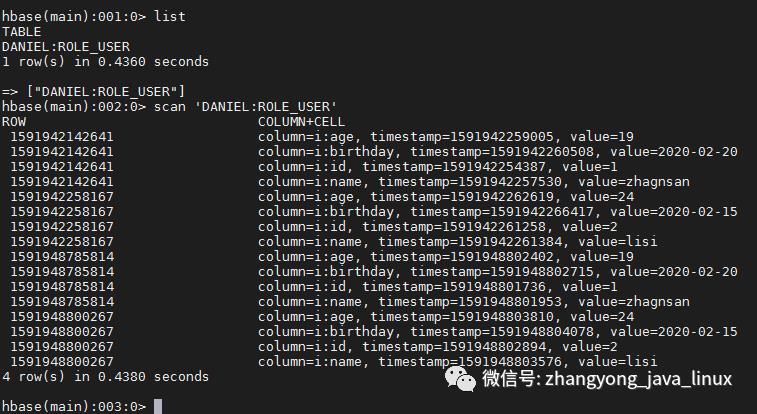
7.解析Hbase底层源码 Scala、Java操作Hbase
7.1 Scala解析Hbase底层源码
/**
* hbase查询结果转换JSONArray
*
* @param rs 源码结果集
* @param writeColumns 要查询的列名
* @return JSONArray
*/
def resultSet2JSONArrayColName(rs: Result, writeColumns: Array[String]): JSONArray = {
if (rs != null) try {
val recordArray: JSONArray = new JSONArray
val recordOne: JSONObject = new JSONObject
for (cel: Cell <- rs.rawCells()) {
val colName: String = Bytes.toString(cel.getQualifierArray, cel.getFamilyOffset, cel.getQualifierLength)
val colValue: String = Bytes.toString(cel.getValueArray, cel.getValueOffset, cel.getValueLength)
if (colValue != null) recordOne.put(colName, colValue)
else recordOne.put(colName, "")
}
if (writeColumns != null) {
val one: JSONObject = new JSONObject
for (col <- writeColumns) {
one.put(col, recordOne.get(col))
}
recordArray.add(one)
} else {
recordArray.add(recordOne)
}
return recordArray
} catch {
case e: SQLException =>
throw new DanielException(ErrorEnum.I_00002, e.toString)
}
null}
/**def resultSet2JSONObjectColName(rs: Result, writeColumns: Array[String]): JSONObject = {
* hbase查询结果转换JSONObject
*
* @param rs 源码结果集
* @param writeColumns 要查询的列名
* @return JSONObject
*/
if (rs != null) try {
val recordOne: JSONObject = new JSONObject
for (cel: Cell <- rs.rawCells()) {
val colName: String = Bytes.toString(cel.getQualifierArray, cel.getFamilyOffset, cel.getQualifierLength)
val colValue: String = Bytes.toString(cel.getValueArray, cel.getValueOffset, cel.getValueLength)
if (colValue != null) recordOne.put(colName, colValue)
else recordOne.put(colName, "")
}
val one: JSONObject = new JSONObject
for (col <- writeColumns) {
one.put(col, recordOne.get(col))
}
return one
} catch {
case e: SQLException =>
throw new DanielException(ErrorEnum.I_00002, e.toString)
}
null
}
7.2、java操作Hbase数据入库
package main.scala.com.web.zhangyong168.cn.spark.java;
import com.alibaba.fastjson.JSONObject;
import org.apache.hadoop.hbase.HBaseConfiguration;
import org.apache.hadoop.hbase.TableName;
import org.apache.hadoop.hbase.client.*;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.hbase.util.Bytes;
import java.io.IOException;
import java.util.ArrayList;
import java.util.LinkedHashMap;
import java.util.List;
import java.util.Map;
/**
* @author zhangyong
* @version 1.0.0
* @description : json数据写入hbase
* @date 2020/05/28 10:55
*/
public class WriteHbase {
/**
* 获取hbase hadoop 的相关配置文件
*
* @return
* @throws IOException
*/
public static Connection initHbase() throws IOException {
Configuration configuration = HBaseConfiguration.create();
// configuration.addResource("hadoop/mapred-site.xml");
// configuration.addResource("hadoop/hive-site.xml");
// configuration.addResource("hadoop/ssl-client.xml");
// configuration.addResource("hadoop/yarn-site.xml");
configuration.addResource("hadoop/hdfs-site.xml");
configuration.addResource("hadoop/hbase-site.xml");
configuration.addResource("hadoop/core-site.xml");
Connection connection = ConnectionFactory.createConnection(configuration);
return connection;
}
/**
* @param connection hbase连接
* @param tableName 表名(hbase表空间加表名)
* @param rowKey rowKey值主值
* @param colFamliy 列族 默认为i
* @param col 列名
* @param val 列值
*/
public static void insertRow(Connection connection, String tableName, String rowKey, String colFamliy, String col, String val) throws IOException {
Table table = connection.getTable(TableName.valueOf(tableName));
Put put = new Put(Bytes.toBytes(rowKey));
put.addColumn(Bytes.toBytes(colFamliy), Bytes.toBytes(col), Bytes.toBytes(val));
table.put(put);
table.close();
}
/***
* 构造数据结果集
* @param accessArray
* @return
*/
public static List<Map<String, Object>> getResultList(AccessArray accessArray) {
List<Map<String, Object>> list = new ArrayList<>();
int columnNameLengths = accessArray.getColumnNames().length;
for (Object[] tempValue : accessArray.getRecordArrayValue()) {
Map<String, Object> parameters = new LinkedHashMap<>();
if (columnNameLengths == tempValue.length) {
for (int j = 0; j <columnNameLengths; j++) {
parameters.put(accessArray.getColumnName(j), tempValue[j].toString());
}
}
list.add(parameters);
}
return list;
}
public static void main(String[] args) throws IOException {
String json="{"columnNames":["id","name","age","birthday"]," +
""columnsTypes":[0,0,0,0],"valuesSize":2," +
""columnValues":[["1","zhagnsan","19","2020-02-20"]," +
"["2","lisi","24","2020-02-15"]]}";
String tableName="DANIEL:ROLE_USER";
AccessArray accessArray= JSONObject.parseObject(json,AccessArray.class);
List<Map<String,Object>> list=getResultList(accessArray);
for (Map<String,Object> map:list){
//设置一条数据的rowkey值
String rowKey=System.currentTimeMillis()+"";
for (Map.Entry<String,Object> entry:map.entrySet()){
insertRow(initHbase(),tableName,rowKey,"i",entry.getKey(),entry.getValue().toString());
}
}
}
}
7.3查询已经启动的应用程序
以上是关于Hbase原理深入解析及集成Hadoop的主要内容,如果未能解决你的问题,请参考以下文章