HDFS集群优化实践(hadoop2.7.2)
Posted 风筝Lee聊大数据
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了HDFS集群优化实践(hadoop2.7.2)相关的知识,希望对你有一定的参考价值。
问题整理:
namenode rpc延迟问题;
namenode状态切换延迟问题;
Namenode占用堆外内存过高问题;
Namenode应用G1 Scan Rset时间过长问题;
HDFS客户端写数据报错问题;
standby namenode rpc抖动问题;
hdfs balance 执行效率低问题;
Datanode磁盘不均衡问题;
一. namenode rpc延迟问题
背景:由于扩容了大量的datanode节点,导致相应的IBR数量线性增大,对namenode节点产生了大量的rpc请求(9002端口),由于来自多个IPC处理程序线程的过多写锁争用,负载下的大量DN节点的ibr将降低NN性能。
优化方案:
A. Namenode端新增线程异步去处理所有IBR请求,通过将多个IBR合并到一个写锁事务中(IBR处理速度很快),可以减少锁争用。因此对于其他操作,处理程序也可以更快地释放出来。
HDFS-9198 异步聚合处理IBR降排队负载,减少抢锁次数
https://issues.apache.org/jira/browse/HDFS-9198https://issues.apache.org/jira/secure/attachment/12785139/HDFS-9198-branch-2.7.patch
具体实现:
增量块报告被后台线程转储到一个队列中进行异步处理。这个线程获取写锁并处理ibr,直到队列耗尽或满足最大锁持有。最大持有时间是4ms,这可能看起来有点高,但如果NN有那么多的积压,最好是抓住这个机会,以避免客户端问题。
完全BR处理也以同步方式使用队列。这有助于保持来自节点的IBRs和完整BRs之间的顺序。同步完整BR处理的另一个原因是它可能会发出finalize命令。
ibr不发送命令,所以它们可以异步。但是,在IBR不太可能失败的情况下,DN当前会重新对IBR进行排队,但是现在DN总是会看到成功。实际上,如果DN已死或未注册,IBR将失败。在IBR因为另一个原因而失败的可能性很小的情况下,我添加了最小限度的支持来强制DN重新注册,从而得到一个完整的BR以进行重新同步。
B. 调整datanode端IBR汇报机制,改为批量ibr, 由于现有机制,一旦有block修改操作就会产生一次ibr,namenode 端处理ibr rpc请求会随着datanode的数量线性增长,增加写锁的抢占,同时影响到客户端的读写请求;
https://issues.apache.org/jira/browse/HDFS-9917https://issues.apache.org/jira/secure/attachment/12796709/HDFS-9917-branch-2.7-002.patchhttps://issues.apache.org/jira/browse/HDFS-9726https://issues.apache.org/jira/secure/attachment/12868855/HDFS-9726-branch-2.7.01.patchhttps://issues.apache.org/jira/browse/HDFS-9710https://issues.apache.org/jira/secure/attachment/12869711/HDFS-9710-branch-2.7.01.patch
具体实现:
增加批量ipr机制,通过配置时间间隔来批量发送ibr请求;
以后考虑的优化点:
1. 将Balancer⾼负载请求打到SBN
Balancer不需要保证数据⼀致性,getDatanodeStorageReport+getBlocks
HDFS-13183;
2. 全局公平读写锁调整到⾮公平读写锁(有可能会导致写饥饿问题)
只需要调整配置:dfs.namenode.fslock.fair 为false,重启namenode;
3.
二. namenode 状态切换延迟问题;
问题现象:namenode切换为active状态时出现延迟和超时现象;
Step1: 通过当时打印的namenode 进程的火焰图和jstack log分析
查看当时备份的m3节点的namenode进程火焰图(火焰图通过async-profiler工具生成):
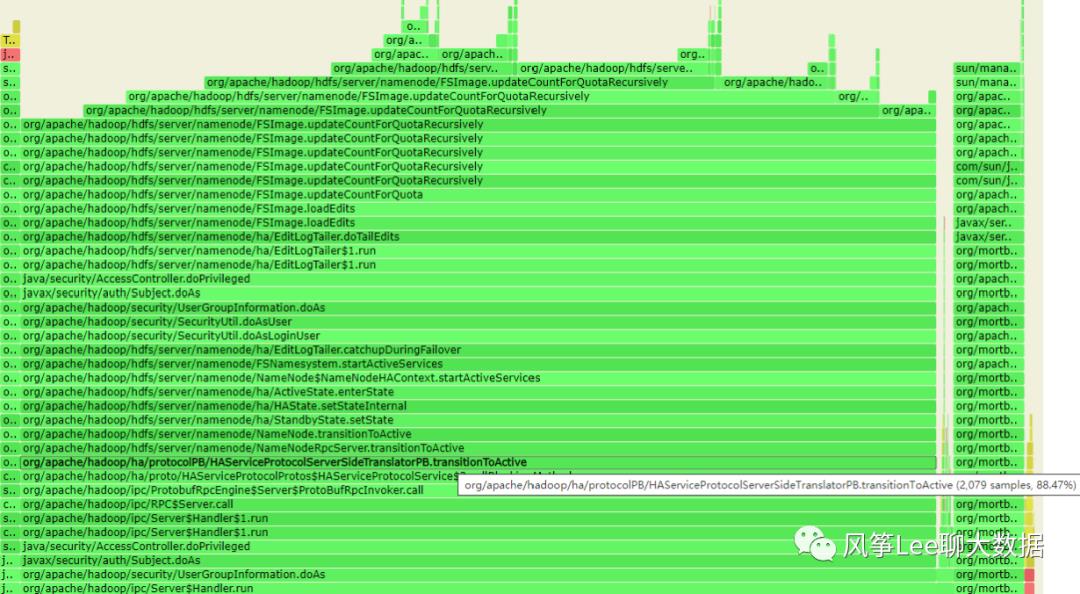
可见namenode端处理transitionToActive请求的调用过程和主要耗时情况,几乎全部耗时都花费在了FsImage.updateCountForQuotaRecursively方法上;
查看当时打印的jstack log也发现当时线程一直是runnable状态:
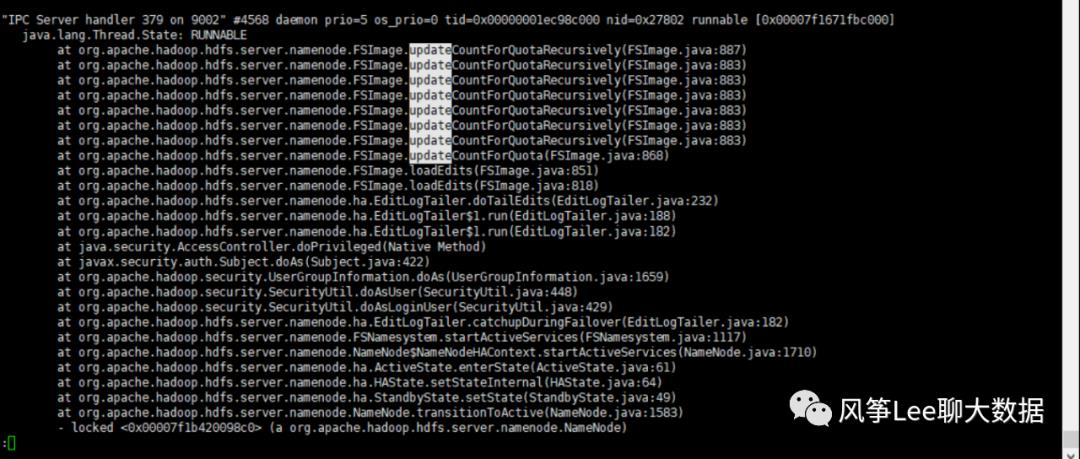
梳理具体的代码逻辑: namenode端处理zkfc transitionToActive 切换状态请求,需要保证所有的editlog已加载完成,并调用递归方法updateCountForQuotaRecursively更新整个fsimage下的配额和使用量信息,因为现在逻辑是单线程递归更新,在fsimage 比较大情况下处理会比较慢。
问题原因:
namenode切换为active状态时更新整个fsimage配额和使用量方法耗时过高,导致整个rpc切换方法执行时间过长。
问题解决:
参考hadoop jira,hadoop2.8.0版本上更新配额和使用量逻辑已更改为fork-join并发处理模式,相关patch上的测试对比结果:
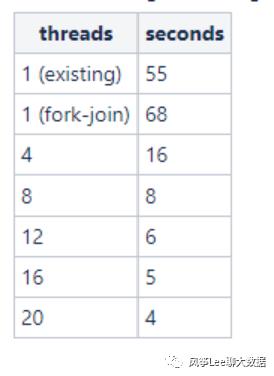
相关patch: https://issues.apache.org/jira/browse/HDFS-8865
三.HDFS客户端写数据报错问题
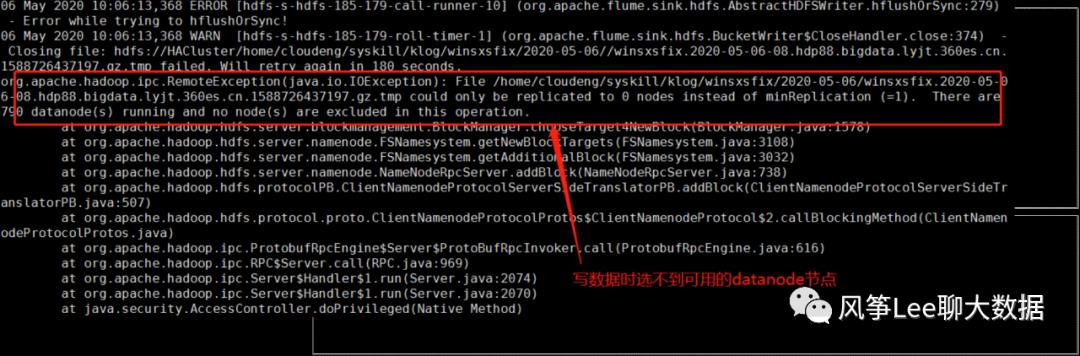
问题分析:
step1:通过namenode log进行分析:
通过hdfs客户端配置和后台代码分析可知,namenode端使用的是默认的副本放置策略(BlockPlacementPolicyDefault), 利用hadoop支持动态配置log4j级别的特性,动态设置BlockPlacementPolicyDefault类的log级别为debug(注意debug log量特别大,会影响服务性能,生产环境谨慎使用或者短暂调整下使用):
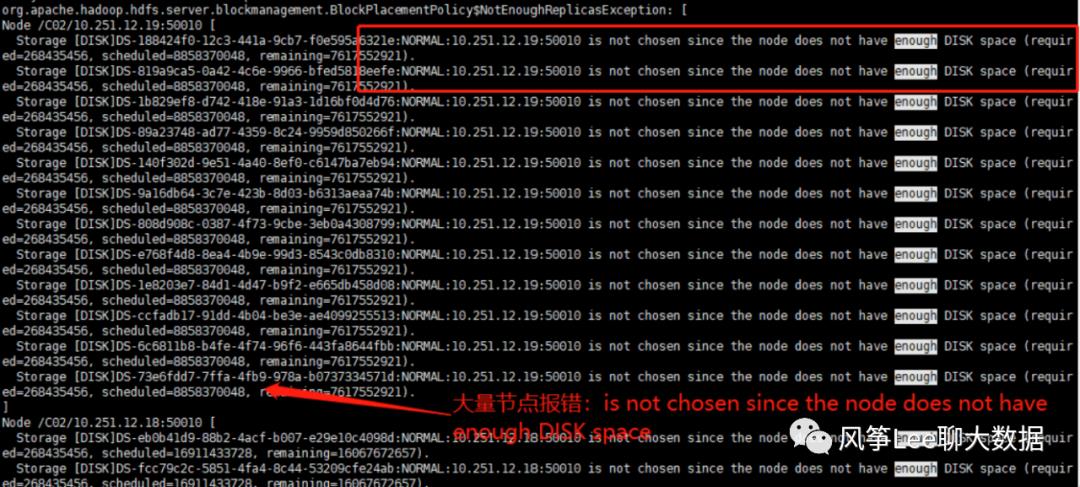
可见,namenode分配datanode节点时,出现了大量的错误,主要有两种:
1. datanodeIP:50010 is not chosen since the node does not have enough DISK space;
2. datanodeIP:50010 is not chosen since the node is too busy;
通过hdfs命令和web页面查看datanode节点存储使用率情况,发现大量节点使用率已超过98%;
step2:分析副本放置策略逻辑代码
看下具体校验节点是否可用逻辑(isGoodTarget):
1. 存储目录不能是read-only
2. 存储目录必须是健康的
3. 存储目录所在节点不能是正在下线中的节点
4. 此节点必须存在空间大于放置副本的存储目录
5. 节点的IO线程数不能超过集群内平均IO线程数量的2倍
6. 该节点需要同时满足机架内最大副本数限制
结合打印的log ,可知namenode已经选择了所有数据节点,未发现可用节点, 结合具体的报错信息分析可知:
1. datanodeIP:50010 is not chosen since the node does not have enough DISK space : 当时大量的节点存储已无可用空间,为不可选节点,所有这些节点上负载几乎为0;
2. datanodeIP:50010 is not chosen since the node is too busy : 验证逻辑的第五条,如果dn节点的active xceiver 数量超过了集群平均值的两倍就认为是不可选节点, 当时acitve xceiver线程数为76,远远没有达到配置值1024,且这些节点磁盘和网络io未发现过高问题,所以认为是逻辑问题导致的误报不可用节点;
问题原因:
整个集群存储使用率过高,大量节点已无可用空间,且这些节点拉低了整个集群的平均负载值,影响到了namenode 判断可用节点逻辑中的第五条(判断负载),导致不可用节点的误报,最终选不出可用的dn节点;
问题解决:
通过配置调整 判断过高负载逻辑中的 集群平均负载的倍数,根据集群情况手动/动态配置;
以上是关于HDFS集群优化实践(hadoop2.7.2)的主要内容,如果未能解决你的问题,请参考以下文章