HDFS集群应用与优化实践(hadoop2.7.2)
Posted 风筝Lee聊大数据
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了HDFS集群应用与优化实践(hadoop2.7.2)相关的知识,希望对你有一定的参考价值。
目录:
Namenode RPC性能优化实践
Namenode状态切换延迟问题
HDFS安全机制之白名单实现
Namenode应用G1 GC不稳定问题
HDFS集群存储过高导致客户端写入异常;
HDFS Balancer优化;
Datanode磁盘不均衡问题;
Standby Namenode RPC抖动问题;
本文说明:
此篇文章是本人在负责维护公司hadoop2.7.2集群过程中总结的一部分实践优化经验以及遇到的一些问题的解决方法,如有异议的地方欢迎一起讨论。
一. namenode rpc性能优化实践
背景:由于扩容了大量的datanode节点,导致相应的IBR数量线性增大,对namenode节点产生了大量的rpc请求,由于来自多个IPC处理程序线程的过多写锁争用,大量DN节点的IBR请求将降低NN性能,影响客户端请求。
优化方案(hadoop社区):
A. Namenode端新增线程异步去处理所有IBR请求,通过将多个IBR合并到一个写锁事务中(IBR请求处理速度很快),可以减少锁争用。因此对于其他操作,处理程序也可以更快地释放出来。
HDFS-9198 异步聚合处理IBR降排队负载,减少抢锁次数
https://issues.apache.org/jira/browse/HDFS-9198https://issues.apache.org/jira/secure/attachment/12785139/HDFS-9198-branch-2.7.patch
具体实现:
增量块报告被后台线程转储到一个队列中进行异步处理。这个线程获取写锁并处理IBR请求,直到队列耗尽或满足最大锁持有时间。最大持有时间是4ms,这可能看起来有点高,但如果NN有那么多的积压,最好是抓住这个机会,以避免客户端问题。
B. 调整datanode端IBR汇报机制,改为批量ibr, 由于现有机制,一旦有block修改操作就会产生一次ibr,namenode 端处理ibr rpc请求会随着datanode的数量线性增长,增加写锁的抢占,同时影响到客户端的读写请求;(具体实现:增加批量ipr机制,通过配置时间间隔来批量发送ibr请求)
https://issues.apache.org/jira/browse/HDFS-9917https://issues.apache.org/jira/secure/attachment/12796709/HDFS-9917-branch-2.7-002.patchhttps://issues.apache.org/jira/browse/HDFS-9726https://issues.apache.org/jira/secure/attachment/12868855/HDFS-9726-branch-2.7.01.patchhttps://issues.apache.org/jira/browse/HDFS-9710https://issues.apache.org/jira/secure/attachment/12869711/HDFS-9710-branch-2.7.01.patch
其他优化点(包括考虑中的):
将Balancer⾼负载请求打到SBN
Balancer不需要保证数据⼀致性,getDatanodeStorageReport+getBlocks请求到stadnby namenode 节点
https://issues.apache.org/jira/browse/HDFS-1318全局公平读写锁调整到⾮公平读写锁
一般情况下集群的读操作比写操作读很多,使用非公平读写锁会提高吞吐量,需要调整配置:dfs.namenode.fslock.fair 为false,重启namenode;
EditLog异步化 rpc性能提升10+%;
https://issues.apache.org/jira/browse/HADOOP-10300https://issues.apache.org/jira/browse/HDFS-7964https://issues.apache.org/jira/browse/HDFS-12603
添加Namenode锁时间监控
为FSNamesystemLock添加监控来查看每个操作持有锁的时间,以便于通过监控指标分析和进行namenode锁优化
https://issues.apache.org/jira/browse/HDFS-10872避免同步方法里打印大量的log影响性能;
通过jstack和火焰图排查发现大量的写log操作占用一些性能且大量刷盘操作占用磁盘io,可以去掉大量无用log或者降低log level;
二. namenode 状态切换延迟问题;
问题现象:namenode切换为active状态时出现延迟和超时现象;
Step1: 通过当时打印的namenode 进程的火焰图和jstack log分析
查看当时备份的m3节点的namenode进程火焰图:
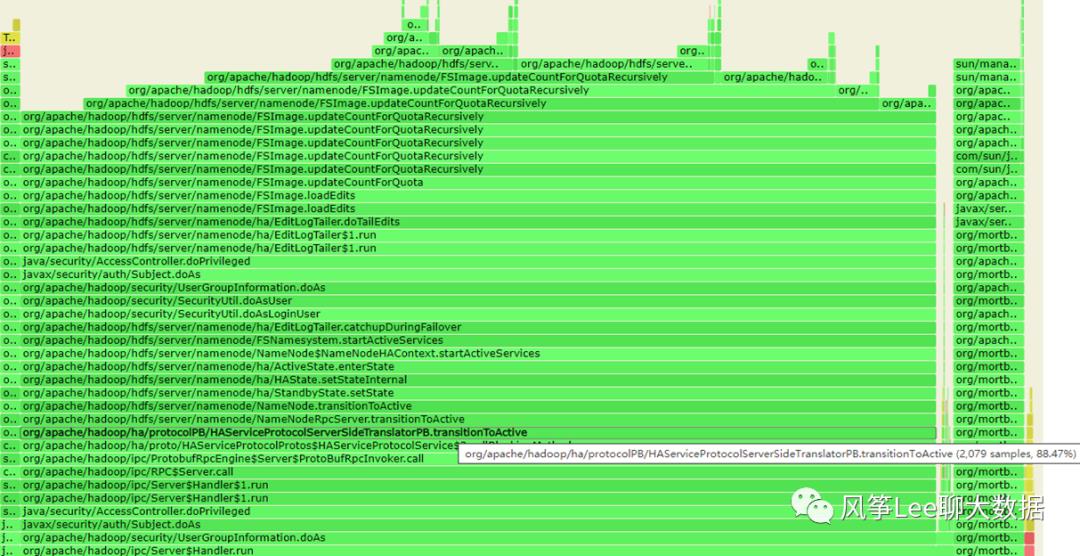
可见namenode端处理transitionToActive请求的调用过程和主要耗时情况,几乎全部耗时都花费在了FsImage.updateCountForQuotaRecursively方法上;
查看当时打印的jstack log也发现当时线程一直是runnable状态:
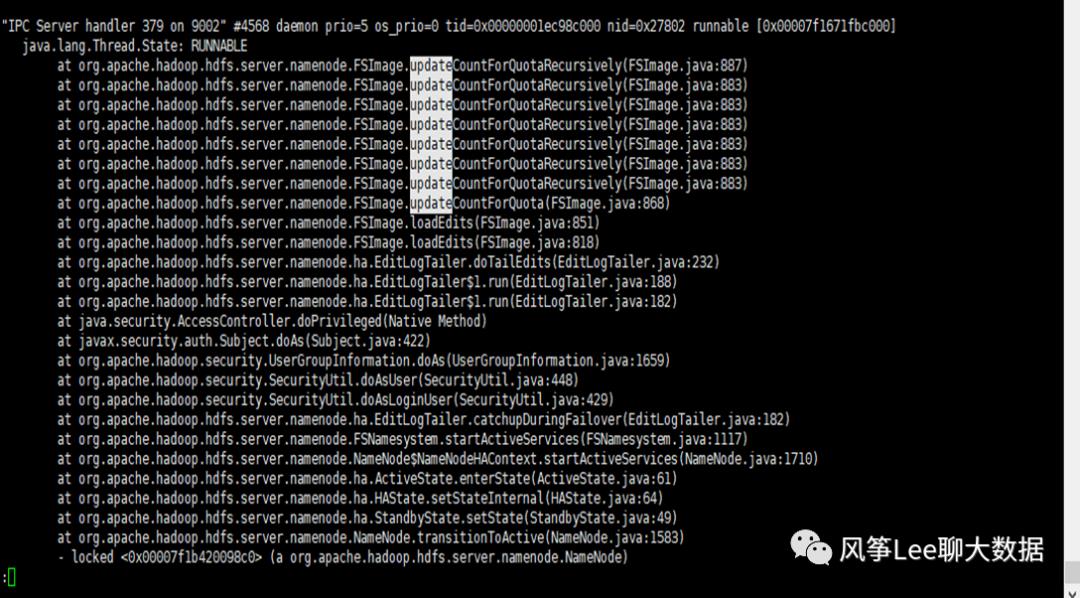
梳理具体的代码逻辑: namenode端处理zkfc transitionToActive切换状态请求,需要保证所有的editlog已加载完成,并调用递归方法updateCountForQuotaRecursively更新整个fsimage下的配额和使用量信息,因为现在逻辑是单线程递归更新,在fsimage 比较大情况下处理会比较慢。
问题原因:
namenode切换为active状态时更新整个fsimage配额和使用量方法耗时过高,导致整个rpc切换方法执行时间过长。
问题解决:
参考hadoop jira,hadoop2.8.0版本上更新配额和使用量逻辑已更改为fork-join并发处理模式,相关patch上的测试对比结果:
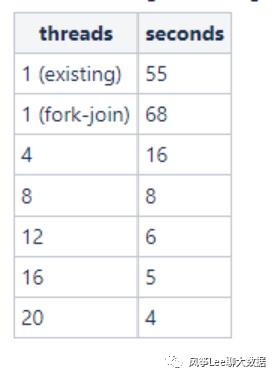
相关patch: https://issues.apache.org/jira/browse/HDFS-8865
三. HDFS安全机制之访问白名单机制
背景
HDFS现有的用户认证机制基于kerberos实现,但是存在一些问题,比如kerberos服务存在KDS服务单点问题、配置维护复杂、且依赖hdfs的服务响应也要配置kerberos增加运维复杂度。HADOOP本身存在IP白名单机制,但是没有实现基于用户的,且会限制hdfs服务本身的一些进程服务访问。
访问白名单机制
基于安全性、简易性我们单独设计了基于IP用户的白名单访问机制;整体设计如下图:
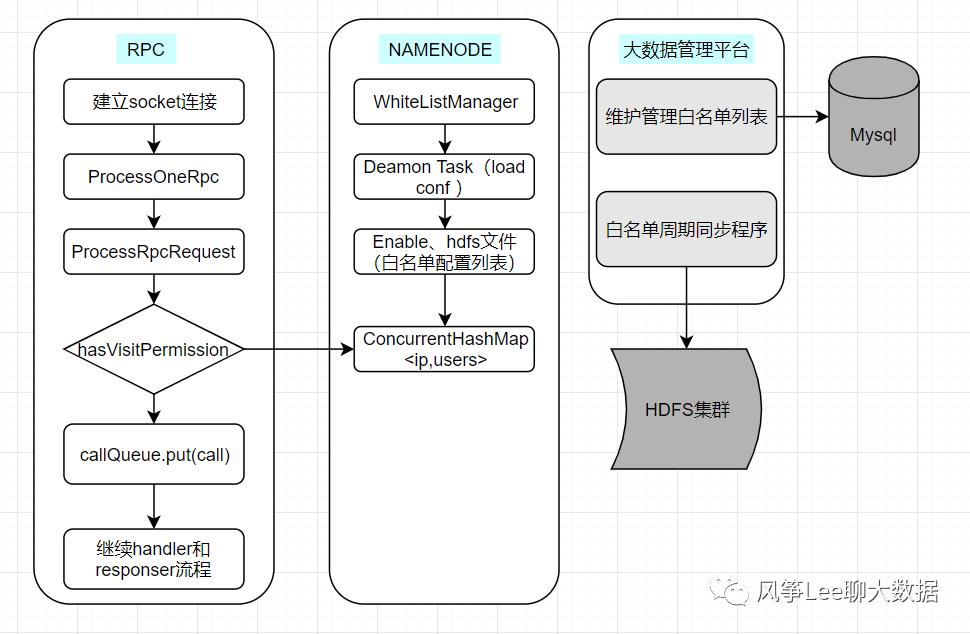
白名单列表在大数据管理平台进行维护,由平台管理人员批量导入和实时更新。为了避免白名单验证逻辑直接访问mysql数据库,后台周期性任务load数据到hdfs集群的具体文件里,namenode守护线程异步load白名单列表到namenode进程内存中,整个流程中为了安全设计了很多容错处理;
动态检测开关配置,切换开关不用重启进程,设计两个配置项如下:
hdfs-site.xml<property><name>dfs.whitelist.enabled</name><!--默认为false--><value>false</value></property><property><name>dfs.whitelist.path</name><value>/home/bigmananger/hdfs/namenode/whitelist.properties</value></property>
四. Namenode应用G1 GC不稳定问题
背景
Namenode进程应用G1后经过多次参数调优,稳定运行了很长一段时间,但是随着Namenode进程的
六.HDFS集群存储过高导致客户端写入异常
某日,线上hdfs集群客户端写操作大量报错
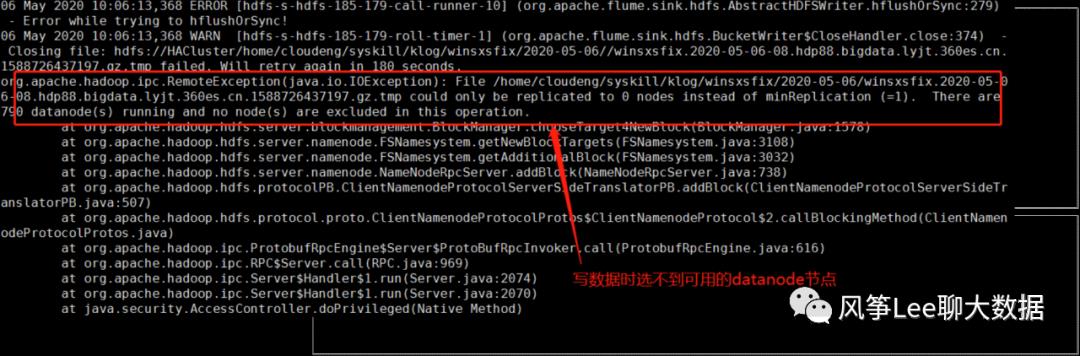
问题分析:
step1:通过namenode log进行分析:
通过hdfs客户端配置和后台代码分析可知,namenode端使用的是默认的副本放置策略(BlockPlacementPolicyDefault),利用hadoop支持动态配置log4j级别的特性,动态设置BlockPlacementPolicyDefault类的log级别为debug(注意debug log量特别大,会影响服务性能,生产环境谨慎使用或者短暂调整下使用):
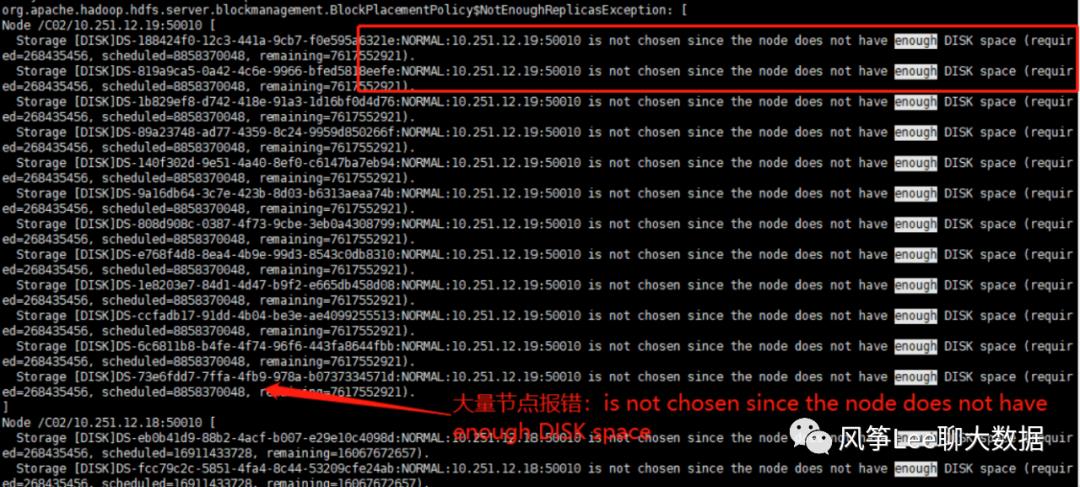
可见,namenode分配datanode节点时,出现了大量的错误,主要有两种:
1. datanodeIP:50010 is not chosen since the node does not have enough DISK space;
2. datanodeIP:50010 is not chosen since the node is too busy;
通过hdfs命令和web页面查看datanode节点存储使用率情况,发现大量节点使用率已超过98%;
step2:分析副本放置策略逻辑代码
看下具体校验节点是否可用逻辑(isGoodTarget):
1. 存储目录不能是read-only
2. 存储目录必须是健康的
3. 存储目录所在节点不能是正在下线中的节点
4. 此节点必须存在空间大于放置副本的存储目录
5. 节点的IO线程数不能超过集群内平均IO线程数量的2倍
6. 该节点需要同时满足机架内最大副本数限制
结合打印的log ,可知namenode已经选择了所有数据节点,未发现可用节点, 结合具体的报错信息分析可知:
1. datanodeIP:50010 is not chosen since the node does not have enough DISK space : 当时大量的节点存储已无可用空间,为不可选节点,所有这些节点上负载几乎为0;
2. datanodeIP:50010 is not chosen since the node is too busy : 验证逻辑的第五条,如果dn节点的active xceiver 数量超过了集群平均值的两倍就认为是不可选节点, 当时acitve xceiver线程数为76,远远没有达到配置值1024,且这些节点磁盘和网络io未发现过高问题,所以认为是逻辑问题导致的误报不可用节点;
问题原因:
整个集群存储使用率过高,大量节点已无可用空间,且这些节点拉低了整个集群的平均负载值,影响到了namenode 判断可用节点逻辑中的第五条(判断负载),导致不可用节点的误报,最终选不出可用的dn节点;
问题解决:
新增代码逻辑,增加动态配置:判断过高负载逻辑中的集群平均负载的倍数,根据集群情况手动配置;
七. Hdfs Balancer优化
应用过程中发现hdfs balancer存在很多问题,比如效率很低,对active namenode产生高负载请求(getBlocks)、move线程被慢节点卡住问题等等;
八. Datanode磁盘不均衡问题
背景:
运维hadoop集群的小伙伴都知道,datanode节点经常会出现磁盘不均衡的现象,产生的原因主要有数据盘损坏后进行换新盘操作、删除大量数据的操作等,所以经常遇到磁盘不均衡的问题。
解决方式:
hadoop2.7.2版本中没有单个datanode节点内的磁盘数据balance功能(目前hadoop3版本中已经实现了diskbalancer功能,可以考虑进行功能移植)。我们的做法是调整datanode数据副本存放磁盘的选择策略为可用空间选择策略(AvailableSpaceVolumeChoosingPolicy),让datanode写数据时尽量选择可用空间比较大的磁盘,尽量缓解磁盘不均衡的问题;
九. standby namenode rpc抖动问题;
以上是关于HDFS集群应用与优化实践(hadoop2.7.2)的主要内容,如果未能解决你的问题,请参考以下文章