V8 执行 JavaScript 的流程
Posted 跨链技术践行者
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了V8 执行 JavaScript 的流程相关的知识,希望对你有一定的参考价值。
前言
本文意在简单的介绍一下 V8 执行 JS 的过程,通过了解 V8 执行 JS 的过程,知道 JS 代码呈现在浏览器上到底做了什么。当然本人也是在陆续探索 V8 ,文章中如有不当之处,还望不吝指正,理性交流。
众所周知,机器(CPU)只能识别机器码(二进制码),对于 JS 代码,它是识别不了的,所以当代码成为页面出现在屏幕上的时候,必然是做了很多的转译工作。
V8 执行 javascript 过程
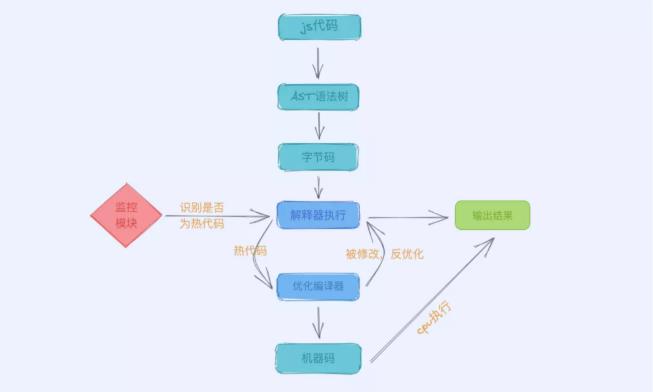
如上图所示,我们将一步步进行拆分分析:
JS TO AST
在 V8 引擎拿到 JS 代码之后,解析器(Parser)会对其进行词法分析和语法分析。
词法分析
将 JS 代码拆分成对应的 Token,Token 是能拆分的最小单位,固定 type 表述类型/属性,value 表示对应的值,如下图 Token。
语法分析
在进行词法分析转为 Token 之后,解析器继续根据生成的 Token 生成对应的 AST,AST 相信前端同学并不陌生,也是热词之一,无论是在 Vue、React 中虚拟 DOM 的表示,或者 Babel 对 JS 转译的表示都是先将其转化为对应的 AST,解析器解析之后的 AST 结构如下图所示:

可以看到,一段极小的代码片段,被解析成 AST 之后复杂了很多,在图中的 AST 还仅仅是简化后的数据,全部的 AST 其实还有很多参数,将会更复杂。
字节码
在解析器(Parser)将 JS 代码解析成 AST 之后,解释器(Ignition)根据 AST 来生成字节码(也称中间码)。前文提到 CPU 只能识别机器码,对字节码是识别不了的,这里就衍生出一个问题,如果 CPU 识别不了字节码,那为什么还要在中间插一步来耗费资源转字节码呢?效率不是很更低吗?
在计算机学科里聊效率,都逃避不了时间和空间这两个概念,绝大部分的优化都是空间换时间和时间换空间,两者的平衡,效率如何达到最高,是一个很值得深入研究的问题。
拿之前版本的 V8 引擎执行 JS 来说,是没有转字节码这一步骤的,直接从 AST 转成机器码,这个过程称为编译过程,所以每次拿到 JS 文件的时候,首先都会编译,而这个过程还是比较浪费时间的,这是一件比较头疼的事情,需要一个解决办法。
一个网页第一次打开,关闭再次去打开,大部分情况下,还是和原来 JS 文件一致的,除非开发者修改了代码,但这个可以暂时不考虑,毕竟哪个网站也不会一天闲的无聊,不停的修改,上传替换。
缓存机器码
按照这个思路,既然绝大多数情况下,文件不会修改,那编译后的机器码可以考虑缓存下来,这样一来,下次再打开或者刷新页面的时候就省去编译的过程了,可以直接执行了,存储机器码被分成了两种情况,一个是浏览器未关闭时候,直接存储到浏览器本地的内存中,一个是浏览器关闭了,直接存储在磁盘上,而早期的 V8 也确实是这么做的,典型的牺牲空间换时间。
缓存带来的问题
思考一个问题,从上面的图中可以看到,一个很小的代码片段,转换成 AST 之后,变大了很多,文件大了导致一个问题就是需要更大的内存来存储,而 JS 文件转成机器码(即二进制文件),会比原来的 JS 文件大几百甚至几千倍,这就意味着一个几十 KB 的 JS 文件将会达到几十 MB,这就很可怕,本来 Chrome 多进程架构就已经很占用内存了,再来这一出,配置再好的电脑,也怕是无福消受 Chrome 了,毕竟使用者体验的好坏,直接决定了一个产品在市场上是否能生存下去,尽管 V8 缓存了编译后的代码,减少了编译的时间,提高了时间上的效率,但代价是内存占用太大了,所以 Chrome 团队是有必要优化这个问题的。
惰性编译
当然,引进其他技术是需要时间去开发和优化的,在一个技术架构产生的同时,必然会有劣势方面的弥补,而早期版本的 V8 为了解决占用内存和启动速度,引进了惰性编译,那么问题来了,惰性编译做了什么去提高效率的呢?
惰性编译还是比较容易理解的,从作用域的角度思考,ES6 之前之只有全局作用域和函数作用域,而惰性编译的思路就是 V8 启动的时候只编译和缓存全局作用域的代码,而函数作用域中的代码,会在调用的时候去编译,同样函数内部编译后的代码一样不会被缓存下来。
惰性编译存在的问题
引入惰性编译之后,在编译速度和缓存上看来,都得到了提升,一切看起来似乎很完美了,对,是看起来,但是设计出来的东西,你永远不知道使用者会怎么使用,在 ES6 和 Vue、React 等这些没有普及之前,绝大部分开发者都使用的是 jQuery,以及 RequireJS 等类似产品,JQ 插件各种引用,各种插件或者开发者自己封装的方法,为了不污染其他使用者的变量,一般都封装成一个函数,这样问题就来了,惰性编译不会保存函数编译后的机器码和理解编译函数,如果一个插件太大那等到使用函数再去编译,编译的时间上就会变得很慢,这相当于是开发者将惰性编译给玩完了,路给封死了。
引入字节码
好吧,玩不过开发者了,那 V8 团队只好换个思路,就引入字节码吧。首先要理解什么是字节码,字节码其实是机器码的抽象,各种字节码的相互构成,可以实现 JS 所需的所有功能,当然首先一点,字节码比机器码占用的内存要小很多很多,基本是机器码所在内存的几十甚至几百分之一,这样一来字节码缓存下来所消耗的内存还是可以接受的。
这里会有一个疑问,既然 CPU 不能识别字节码,那是不是还需要将字节码转成机器码呢?不然怎么执行,答案是肯定。解释在将 AST 转为字节码之后,会在执行的时候将字节码转成机器码,这个执行过程肯定是比直接执行机器码要慢的,所以在执行方面,速度上会比较慢,但是 JS 源码通过解析器转 AST,然后再通过解释器转字节码,这个过程是比编译器直接将 JS 源码转机器码要快很多的,全流程看来,整个时间上是差不了多少的,但是却减小了大量的内存占用,何乐而不为。
编译器
热代码
在代码中,常常会有同一部分代码,被多次调用,同一部分代码如果每次都需要解释器转二进制代码再去执行,效率上来说,会有些浪费,所以在 V8 模块中会有专门的监控模块,来监控同一代码是否多次被调用,如果被多次调用,那么就会被标记为热代码,这有什么作用呢?
优化编译器
TurboFan (优化编译器) 这个词相信关注手机界的同学并不陌生,华为、小米等这些品牌,在近几年产品发布会上都会出现这个词,主要的能力是通过软件计算能力来优化一系列的功能,使得效率更优。
接着热代码继续说,当存在热代码的时候,V8 会借着 TurboFan 将为热代码的字节码转为机器码并缓存下来,这样一来,当再次调用热代码时,就不在需要将字节码转机器码,当然热代码相对来说还是少部分的,所以缓存也并不会占用太大内存,并且提升了执行效率,同样此处也是牺牲空间换时间。
反优化
JS 语言是动态语言,非常之灵活,对象的结构和属性在运行时是可以发生改变的,设想一个问题,如果热代码在某次执行的时候,突然其中的某个属性被修改了,那么编译成机器码的热代码还能继续执行吗?答案是肯定不能。这个时候就要使用到优化编译器的反优化了,他会将热代码退回到 AST 这一步,这个时候解释器会重新解释执行被修改的代码,如果代码再次被标记为热代码,那么会重复执行优化编译器的这个步骤。
总结
从分析的过程来看,V8 对 JS 执行的过程,不仅使用到了解释器,还用到了优化编译器。这种两者结合去处理的方式,业界称为 JIT (Just-In-Time)。使用这种结合的方式来处理 JS,主要是利用了 AST 形成的文件较小,而通过优化编译器编译后的热代码执行效率高,两者结合,各自发挥各自的优势,将效率尽量提升到最大。
V8 所做的事情,远远不止这些,这里也仅仅是简单概况和分析一下主流程上所做的一些事情,如果细化到每个点,还有很多概念,比如内联缓存、隐藏类、快属性、慢属性、创建对象,以及笔者之前写的 V8 引擎垃圾回收与内存分配 等等,所做的事情实在太多,就不一一例举了。
以上是关于V8 执行 JavaScript 的流程的主要内容,如果未能解决你的问题,请参考以下文章