数据准备的能力,决定企业AI研发的边界
Posted 百度大脑
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了数据准备的能力,决定企业AI研发的边界相关的知识,希望对你有一定的参考价值。
在人工智能三要素 “数据、算力、算法” 中,数据相当于人工智能算法的 “燃料”。无论是企业的 AI 业务应用开发,还是高校师生团队的 AI 科研项目,想要获取高精度模型,必须要考虑的是具备充足的训练数据。
简单理解,数据标注相当于为 “投喂” AI 准备 “食物”。机器学习中的监督学习和半监督学习都需要人工标注好的数据进行学习,其训练集、验证集和测试集都是标注过的数据。
比如,如果要教 AI 认识苹果,可以用1000张标注 “苹果” 的图片以及更多的不包括 “苹果” 的图片作为训练集,机器会从中学习得到一个模型,以后再遇到相关图片时就能认出是不是苹果。
但是,在真正的业务和科研场景,动辄上千甚至上万条的数据,标注就成了令人头秃的问题。别小看标注只是画框和点选操作,如果仅依赖一人进行标注,这样的效率足以让整个 AI 项目陷入进展停滞的境地。

观察到这一需求,百度 BML 全功能 AI 开发平台推出特色功能「多人标注」,化整为零、分块并行,倍速级完成数据标注,AI 开发效率提升不是梦!
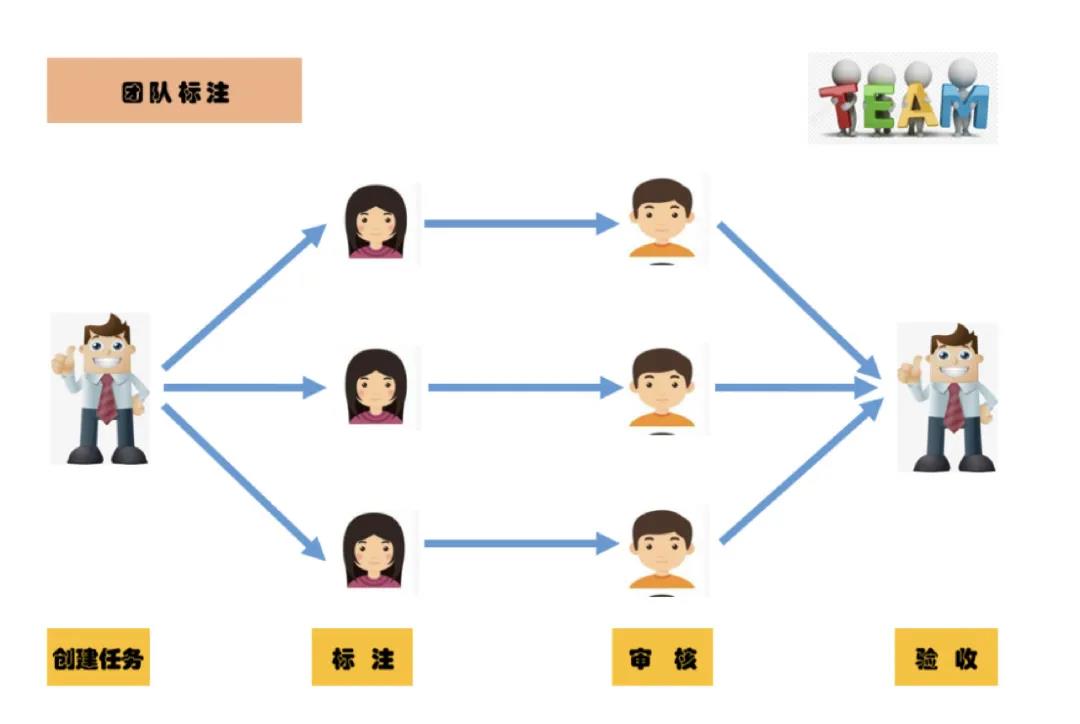
在多人标注中,共有三种角色:管理员、标注员、审核员。管理员创建多人标注任务,分配给指定的标注团队,标注员完成标注后,引入审核团队对标注员的工作进行审核,进一步提高了标注的准确率,保证了后续模型训练的标注准确性。审核员审核全部完成后,管理员对整体的标注效果进行验收,验收完成后标注工作正式结束。
想要启动「多人标注」任务,只要创建好数据集,就可以直接启动使用啦。目前全面支持 BML 平台上的图像和文本任务。用过的都说好!


简单四步,团队协作搞定海量数据标注
(文末有福利)
1. 管理员创建团队与任务
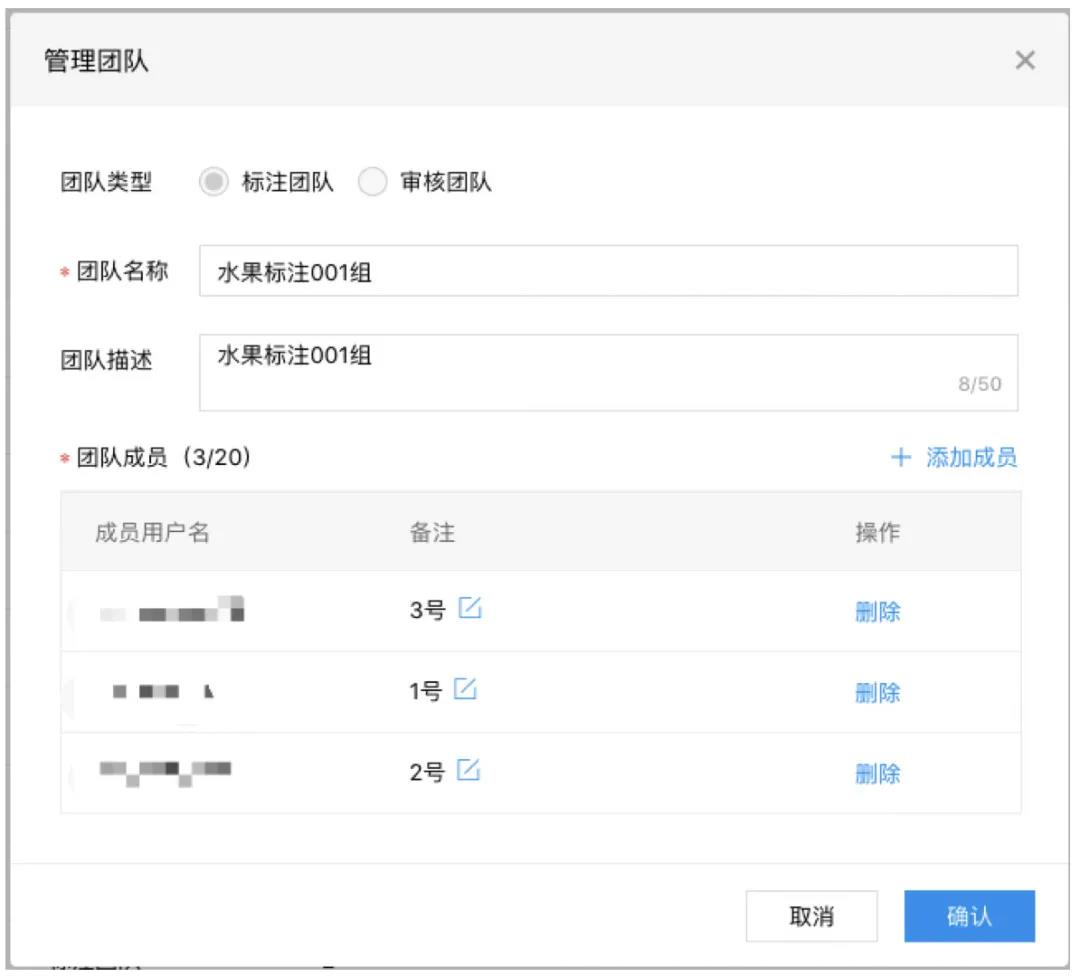
首先,管理员创建好标注团队和审核团队,并在团队里添加相关的成员并完善信息。
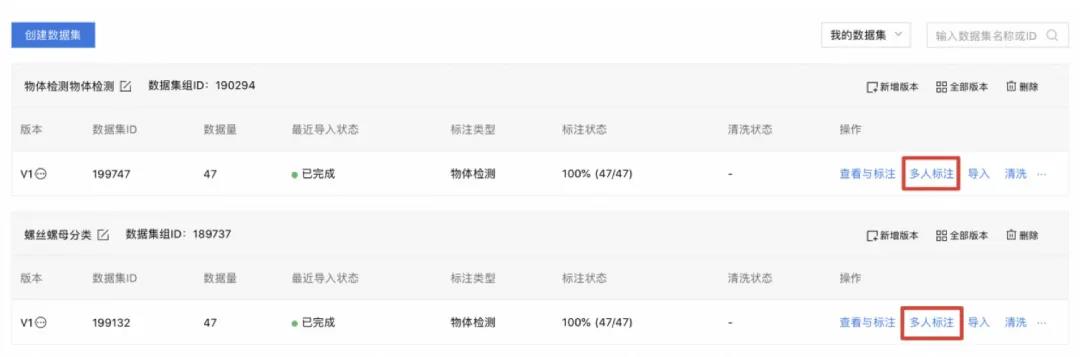
团队创建好后,就可以对已有数据集的未标注图片发起多人标注任务了。如下图:
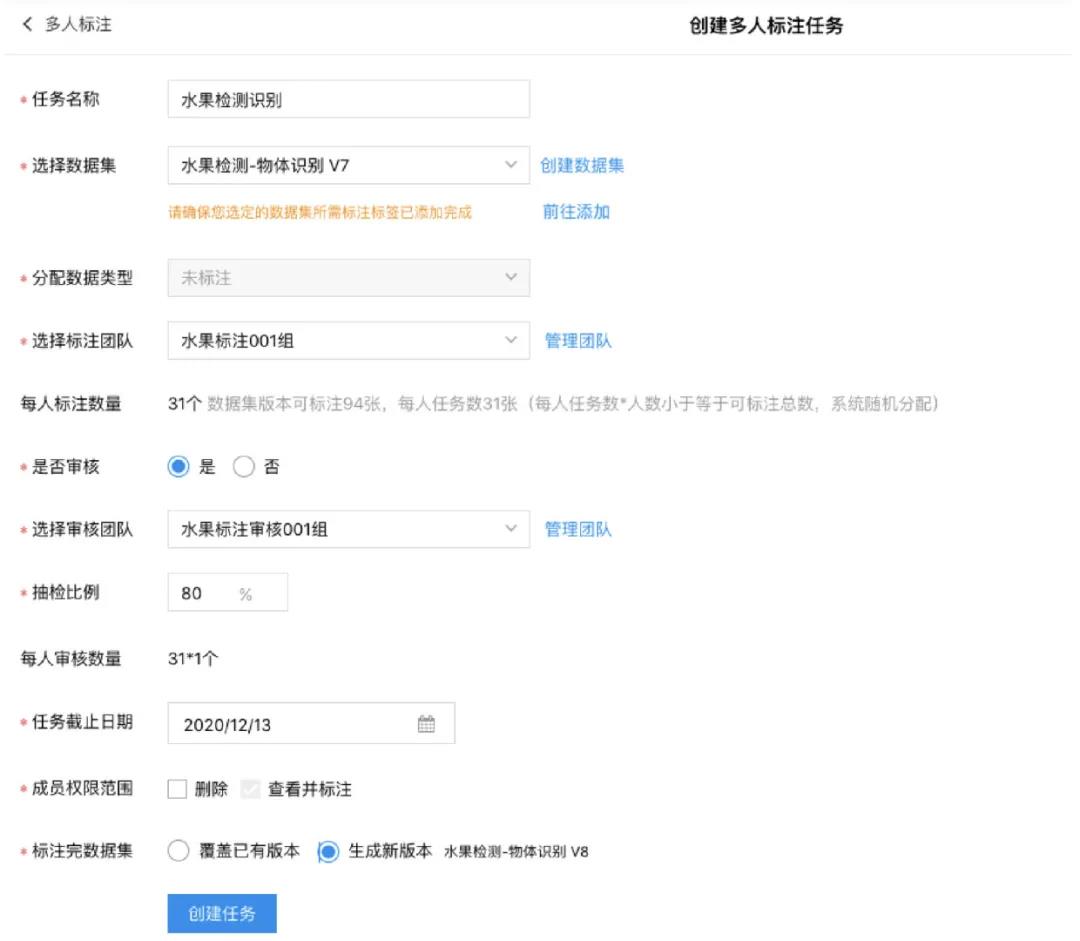
目前对数据集里面未标注的数据进行任务平均分配,在任务创建时,管理员可以灵活选择是否需要标注审核、任务截止时间、成员权限和数据保存方式。
完成任务创建并提交后,后台会自动进行任务的平均分配,并将标注任务的链接发放到标注团队成员的邮箱中。
2. 标注员进行标注
标注员点击邮箱收到的任务链接开始标注,在管理员设置的结束时间之前完成即可,标注完成后进行任务提交,根据管理员设置决定是否进行任务审核。
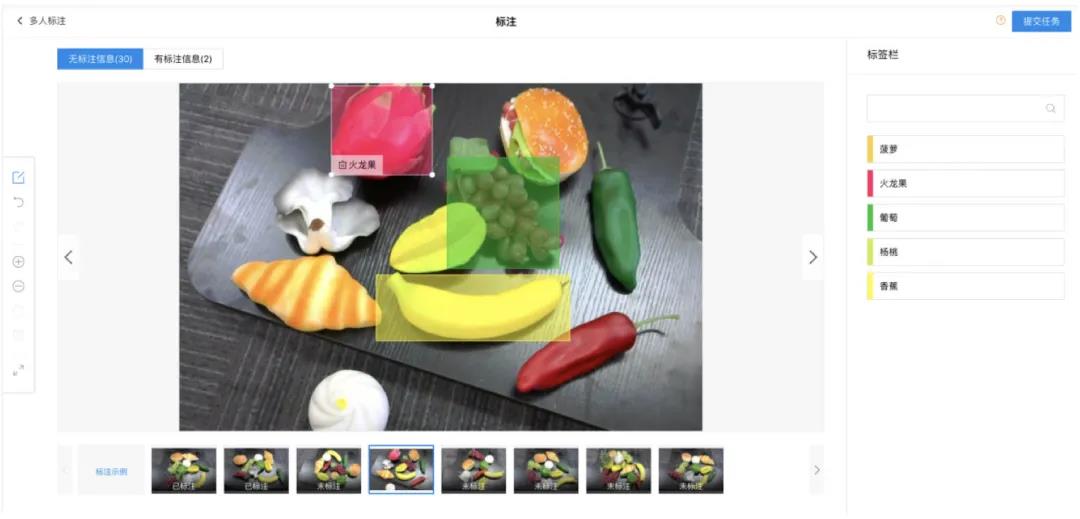
上图为标注员的标注页面,管理员可以为每个标签设置对应的颜色,标注框的颜色也会随之变化,以方案标注员进行标注和检查。同时,EasyData 也支持标签置顶和锁定功能,便于标注员快速选择常用标签,提升标注效率和准确率。
3. 审核员进行审核
审核员点击邮箱里面的审核任务链接,在管理员设置的结束时间之前,对标注员的标注工作进行审核,审核完成后提交任务。所有审核任务都提交后,管理员进入验收环节。在整体流程中,审核员的加入分担了管理员的审核压力,也提高了对标注员的要求,通过多种方式提升数据的标注质量,提升了验收环节的效率。
4. 管理员验收
管理员可以看到标注任务和审核任务的进展,以及所有的标注详情。在需要审核的情况下,如果某个标注员的标注结果审核通过率较低,可以进行打回与重新标注,审核员与管理员也需要重新审核与验收。在验收完成之后,标注数据会保存到目标数据集中,标志着多人标注工作完成。
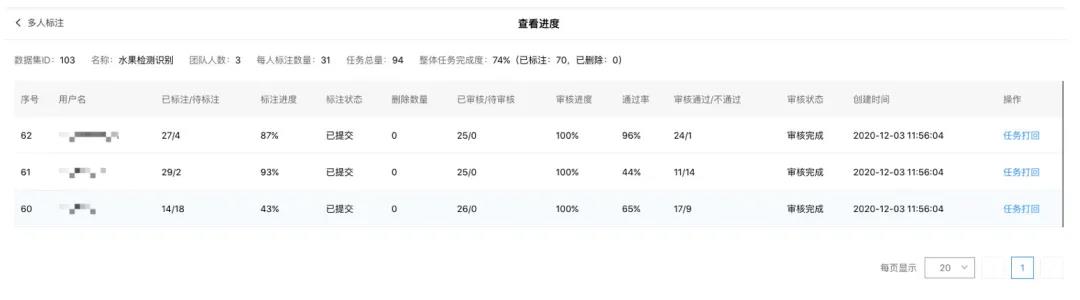
基于 BML「多人标注」功能,原本繁重的数据标注工作可以通过团队协作的方式进行分配,并且,引入管理员、审核员角色,将标注工作进一步细分,在保证数据质量的前提下,最大化提升团队协作效率。

百度 BML 全功能 AI 开发平台
百度 BML 全功能 AI 开发平台(Baidu Machine Learning) ,基于英特尔 ® 至强 ® 集成 AI 加速,是为企业和个人开发者提供机器学习和深度学习的一站式 AI 开发服务。提供一站式、低代码、高效便捷的 AI 开发体验。包括:
- 数据处理:摄像头数据采集与回流、在线标注、多人标注、智能标注、数据清洗、数据质检;
- 模型训练:低代码的预置模型调参模式、notebook 原生编程模式、多文件上传的自定义作业模式;
- 服务部署:全面的公有云部署和端侧离线部署能力,支持服务自动启停、流量切分、自定义配额、性能评测。
功能有多贴心你已经感受到了吧!
现在,BML 还在进行 “2021万有引力计划”,百度搜索 “百度 BML”( https://ai.baidu.com/bml/ )参与活动,体验平台功能即有可能获得10000元的 AI 特权,能够兑换超级 “豪华大礼包”!

比如:
- 6000+小时的自定义模型训练时长;
- 590+小时的预置模型调参;
- 公有云模型部署服务400+小时配额;
- 或者兑换50个设备端的 SDK。
加上完全免费的「多人标注」,妥妥地满足一个 AI 模型 Demo 的开发调试,不领就错亿!
以上是关于数据准备的能力,决定企业AI研发的边界的主要内容,如果未能解决你的问题,请参考以下文章