Kafka的集群部署实践及运维相关
Posted 分布式实验室
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Kafka的集群部署实践及运维相关相关的知识,希望对你有一定的参考价值。
上一篇 Kafka 的文章《 》中我们应该已经了解了一些关于基础角色和集群架构相关的问题,这时候我们应该很想了解一下如何构建生产中的Kafka集群或者一些相关的运维工具,所以就应运而生了下文。

假设每天集群需要承载10亿数据。一天24小时,晚上12点到凌晨8点几乎没多少数据。
使用二八法则估计,也就是80%的数据(8亿)会在16个小时涌入,而且8亿的80%的数据(6.4亿)会在这16个小时的20%时间(3小时)涌入。
QPS计算公式:640000000 ÷ (3x60x60) = 60000,也就是说高峰期的时候Kafka集群要扛住每秒6万的并发。
磁盘空间计算,每天10亿数据,每条50kb,也就是46T的数据。保存2个副本(在上一篇中也提到过其实两个副本会比较好,因为follower需要去leader那里同步数据,同步数据的过程需要耗费网络,而且需要磁盘空间,但是这个需要根据实际情况考虑),46 * 2 = 92T,保留最近3天的数据。故需要 92 * 3 = 276T。
部署Kafka,Hadoop,mysql……等核心分布式系统,一般建议直接采用物理机,抛弃使用一些低配置的虚拟机的想法。高并发这个东西,不可能是说,你需要支撑6万QPS,你的集群就刚好把这6万并发卡的死死的。加入某一天出一些活动让数据量疯狂上涨,那整个集群就会垮掉。
但是,假如说你只要支撑6w QPS,单台物理机本身就能扛住4~5万的并发。所以这时2台物理机绝对绝对够了。但是这里有一个问题,我们通常是建议,公司预算充足,尽量是让高峰QPS控制在集群能承载的总QPS的30%左右(也就是集群的处理能力是高峰期的3~4倍这个样子),所以我们搭建的kafka集群能承载的总QPS为20万~30万才是安全的。所以大体上来说,需要5~7台物理机来部署,基本上就很安全了,每台物理机要求吞吐量在每秒4~5万条数据就可以了,物理机的配置和性能也不需要特别高。
需要5台物理机的情况,需要存储276T的数据,平均下来差不多一台56T的数据。这个具体看磁盘数和盘的大小。
现在我们需要考虑一个问题:是需要SSD固态硬盘,还是普通机械硬盘?
SSD就是固态硬盘,比机械硬盘要快,那么到底是快在哪里呢?其实SSD的快主要是快在磁盘随机读写,就要对磁盘上的随机位置来读写的时候,SSD比机械硬盘要快。比如说MySQL这种就应该使用SSD了(MySQL需要随机读写)。比如说我们在规划和部署线上系统的MySQL集群的时候,一般来说必须用SSD,性能可以提高很多,这样MySQL可以承载的并发请求量也会高很多,而且SQL语句执行的性能也会提高很多。
因为写磁盘的时候Kafka是顺序写的。机械硬盘顺序写的性能机会跟内存读写的性能是差不多的,所以对于Kafka集群来说其实使用机械硬盘就可以了。如果是需要自己创业或者是在公司成本不足的情况下,经费是能够缩减就尽量缩减的。
JVM非常怕出现full gc的情况。Kafka自身的JVM是用不了过多堆内存的,因为Kafka设计就是规避掉用JVM对象来保存数据,避免频繁full gc导致的问题,所以一般Kafka自身的JVM堆内存,分配个10G左右就够了,剩下的内存全部留给OS cache。
那服务器需要多少内存呢。我们估算一下,大概有100个topic,所以要保证有100个topic的leader partition的数据在操作系统的内存里。100个topic,一个topic有5个partition。那么总共会有500个partition。每个partition的大小是1G(在上一篇中的日志分段存储中规定了.log文件不能超过1个G),我们有2个副本,也就是说要把100个topic的leader partition数据都驻留在内存里需要1000G的内存。
我们现在有5台服务器,所以平均下来每天服务器需要200G的内存,但是其实partition的数据我们没必要所有的都要驻留在内存里面,只需要25%的数据在内存就行,200G * 0.25 = 50G就可以了(因为在集群中的生产者和消费者几乎也算是实时的,基本不会出现消息积压太多的情况)。所以一共需要60G(附带上刚刚的10G Kafka服务)的内存,故我们可以挑选64G内存的服务器也行,大不了partition的数据再少一点在内存,当然如果能够提供128G内存那就更好。
CPU规划,主要是看你的这个进程里会有多少个线程,线程主要是依托多核CPU来执行的,如果你的线程特别多,但是CPU核很少,就会导致你的CPU负载很高,会导致整体工作线程执行的效率不太高,上一篇的Kafka的网络设计中讲过Kafka的Broker的模型。acceptor线程负责去接入客户端的连接请求,但是他接入了之后其实就会把连接分配给多个processor,默认是3个,但是一般生产环境建议大家还是多加几个,整体可以提升kafka的吞吐量比如说你可以增加到6个,或者是9个。另外就是负责处理请求的线程,是一个线程池,默认是8个线程,在生产集群里,建议大家可以把这块的线程数量稍微多加个2倍~3倍,其实都正常,比如说搞个16个工作线程,24个工作线程。
后台会有很多的其他的一些线程,比如说定期清理7天前数据的线程,Controller负责感知和管控整个集群的线程,副本同步拉取数据的线程,这样算下来每个broker起码会有上百个线程。根据经验4个CPU core,一般来说几十个线程,在高峰期CPU几乎都快打满了。8个CPU core,也就能够比较宽裕的支撑几十个线程繁忙的工作。所以Kafka的服务器一般是建议16核,基本上可以hold住一两百线程的工作。当然如果可以给到32 CPU core那就最好不过了。
现在的网基本就是千兆网卡(1GB / s),还有万兆网卡(10GB / s)。kafka集群之间,broker和broker之间是会做数据同步的,因为leader要同步数据到follower上去,他们是在不同的broker机器上的,broker机器之间会进行频繁的数据同步,传输大量的数据。那每秒两台broker机器之间大概会传输多大的数据量?
高峰期每秒大概会涌入6万条数据,约每天处理10000个请求,每个请求50kb,故每秒约进来488M数据,我们还有副本同步数据,故高峰期的时候需要488M * 2 = 976M/s的网络带宽,所以在高峰期的时候,使用千兆带宽,网络还是非常有压力的。
10亿数据,6w/s的吞吐量,276T的数据,5台物理机
硬盘:11(SAS) * 7T,7200转
内存:64GB/128GB,JVM分配10G,剩余的给os cache
CPU:16核/32核
网络:千兆网卡,万兆更好
进到Kafka的config文件夹下,会发现有很多很多的配置文件,可是都不需要你来修改,你仅仅需要点开一个叫作server.properties的文件就够了。
【broker.id】
每个broker都必须自己设置的一个唯一id,可以在0~255之间
【log.dirs】
这个极为重要,Kafka的所有数据就是写入这个目录下的磁盘文件中的,如果说机器上有多块物理硬盘,那么可以把多个目录挂载到不同的物理硬盘上,然后这里可以设置多个目录,这样Kafka可以数据分散到多块物理硬盘,多个硬盘的磁头可以并行写,这样可以提升吞吐量。ps:多个目录用英文逗号分隔
【zookeeper.connect】
连接Kafka底层的ZooKeeper集群的
【Listeners】
broker监听客户端发起请求的端口号,默认是9092
【num.network.threads】默认值为3
【num.io.threads】默认值为8
细心的朋友们应该已经发现了,这就是上一篇我们在网络架构上提到的processor和处理线程池的线程数目。
所以说掌握Kafka网络架构显得尤为重要。
现在你看到这两个参数,就知道这就是Kafka集群性能的关键参数了
【unclean.leader.election.enable】
默认是false,意思就是只能选举ISR列表里的follower成为新的leader,1.0版本后才设为false,之前都是true,允许非ISR列表的follower选举为新的leader
【delete.topic.enable】
默认true,允许删除topic
【log.retention.hours】
可以设置一下,要保留数据多少个小时,这个就是底层的磁盘文件,默认保留7天的数据,根据自己的需求来就行了
【min.insync.replicas】
acks=-1(一条数据必须写入ISR里所有副本才算成功),你写一条数据只要写入leader就算成功了,不需要等待同步到follower才算写成功。但是此时如果一个follower宕机了,你写一条数据到leader之后,leader也宕机,会导致数据的丢失。
因为实际的集群搭建说真的没有太大难度,所以搭建的过程就不详细展开了,网上应该很多相关资料。
在操作Kafka集群的时候,不同的Kafka版本命令的写法是不一样的,所以其实如果需要了解一下,推荐直接到官网去查看。
时也有提到说Kafka在0.8版本以前存在比较大的问题,1.x的算是目前生产环境中使用较多的版本。
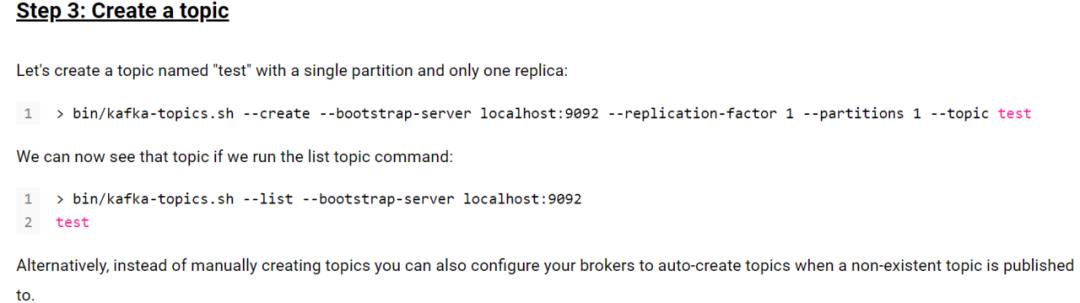
bin/kafka-topics.sh --create --zookeeper localhost:2181 --replication-factor 1 --partitions 1 --topic
test
将该命令修改一下
zookeeper localhost:2181 --replication-factor 2 --partitions 2 --topic tellYourDream
这时候就是zookeeper的地址为localhost:2181
两个分区,两个副本,一共4个副本,topic名称为“tellYourDream”了
还得注意,一般来说设置分区数建议是节点的倍数,这是为了让服务节点分配均衡的举措。
bin/kafka-topics.sh --list --zookeeper localhost:2181
bin/kafka-console-producer.sh --broker-list localhost:9092 --topic test
This is a message
This is another message
bin/kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic test --from-beginning
This is a message
This is another message
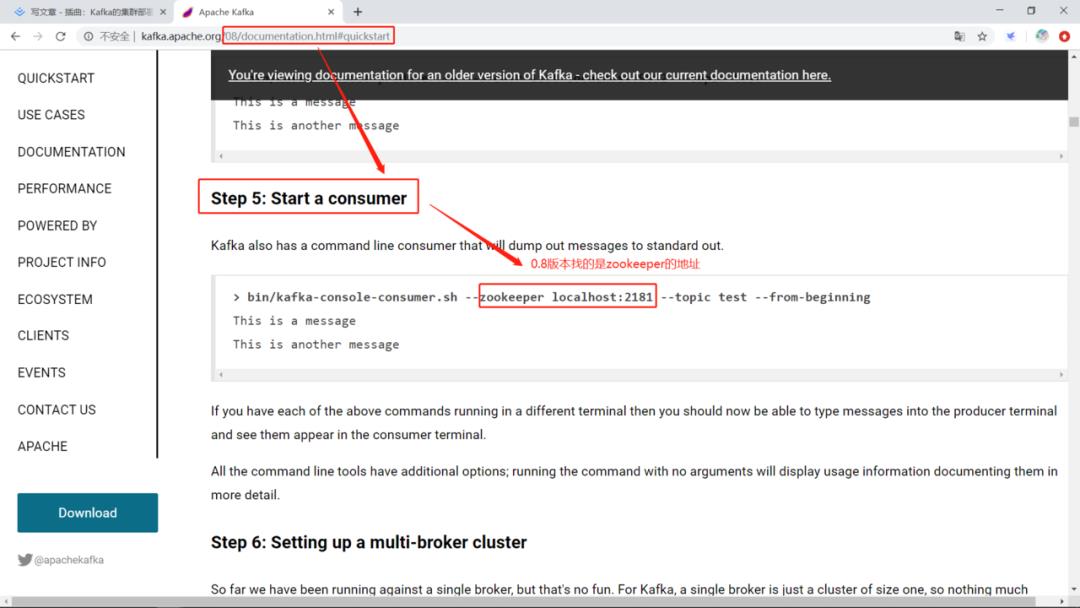
这里有个细节需要提及一下,就是我们0.8版本的Kafka找的是ZooKeeper,ZooKeeper上确实是也存在着元数据信息。
不过这存在着一些问题,ZooKeeper本身有一个过半服务的特性,这是一个限制,过半服务是指任何的请求都需要半数节点同意才能执行。每次有写请求,它都要投票,因为它要保持数据的强一致性,做到节点状态同步,所以高并发写的性能不好。不适合做高并发的事。ZooKeeper是Kafka存储元数据和交换集群信息的工具,主要是处理分布式一致性的问题。
下面的命令就是生产50W条数据,每条数据200字节,这条命令一运行就会产生一条报告,可以很直观的看到集群性能,看不懂的情况搜索引擎也可以很好地帮助你解决问题。
测试生产数据
bin/kafka-producer-perf-test.sh --topic test-topic --num-records 500000 --record-size 200 --throughput -1 --producer-props bootstrap.servers=hadoop03:9092,hadoop04:9092,hadoop05:9092 acks=-1
测试消费数据
bin/kafka-consumer-perf-test.sh --broker-list hadoop03:9092,hadoop04:9092,hadoop53:9092 --fetch-size 2000 --messages 500000 --topic test-topic
KafkaManager使用scala写的项目。安装步骤可以参考:https://www.cnblogs.com/dadonggg/p/8205302.html,非常不错。使用方法可以通过搜索引擎查找。
安装好了之后可以使用jps命令查看一下,会多出一个名字叫做ProdServerStart的服务。
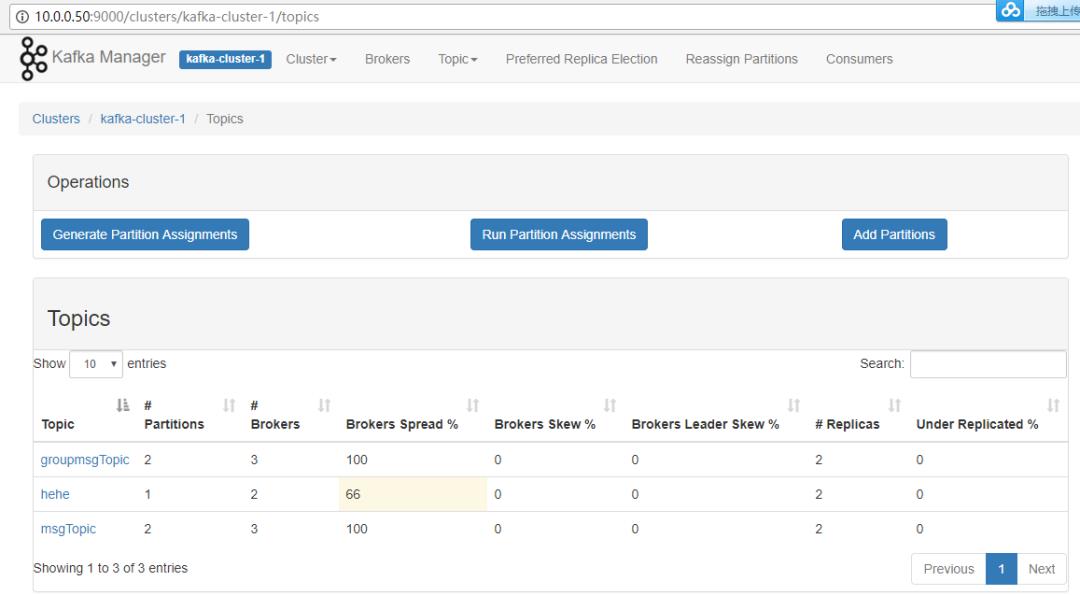
管理多个Kafka集群
便捷的检查Kafka集群状态(topics,brokers,备份分布情况,分区分布情况)
选择你要运行的副本
基于当前分区状况进行
可以选择topic配置并创建topic(0.8.1.1和0.8.2的配置不同)
删除topic(只支持0.8.2以上的版本并且要在broker配置中设置delete.topic.enable=true)
Topic list会指明哪些topic被删除(在0.8.2以上版本适用)
为已存在的topic增加分区
为已存在的topic更新配置
在多个topic上批量重分区
在多个topic上批量重分区(可选partition broker位置)
KafkaOffsetMonitor就是一个jar包而已,是一个针对于消费者的工具。它可以用于监控消费延迟的问题,不过对于重复消费和消息丢失等就无法解决,因为之后如果需要讲解SparkStreaming,flink这些用于消费者的实践的话,会使用到这个工具,所以现在先不展开,了解一下即可。
java -cp KafkaOffsetMonitor-assembly-0.3.0-SNAPSHOT.jar
com.quantifind.kafka.offsetapp.OffsetGetterWeb
--offsetStorage kafka
--zk xx:2181,xx:2181,xx:2181/kafka_cluster
--port 8088
--refresh 60.seconds
--retain 2.days
还有一些跨机房同步数据的像MirrorMaker这些,酌情使用。
文章来源:https://juejin.im/post/6844904001989771278
本次CKA培训将于11月20到22日在
北京开课,培训
基于最新考纲,通过
线下授课、考题解读、模拟演练等方式,帮助学员快速掌握Kubernetes的理论知识和专业技能,并针对考试做特别强化训练,让学员能从容面对CKA认证考试,使学员既能掌握Kubernetes相关知识,又能通过CKA认证考试,
学员可多次参加培训,直到通过认证。点击下方图片或者阅读原文链接查看详情。
以上是关于Kafka的集群部署实践及运维相关的主要内容,如果未能解决你的问题,请参考以下文章
linux运维架构之路-Kafka集群部署
线上交流,欢迎来聊 | 企业自动化运维落地的实践经验及运维工具选型对比分析
结合kafka部署ELK日志收集系统实践
Kafka 负载均衡在 vivo 的落地实践
教你在Kubernetes中快速部署ES集群
教你在Kubernetes中快速部署ES集群