技术干货具有HadoopSpark和Kafka的实时大数据管道
Posted 海牛大数据
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了技术干货具有HadoopSpark和Kafka的实时大数据管道相关的知识,希望对你有一定的参考价值。
海牛学院的 | 第 609 期

大数据由3V定义,即速度,数据量和各种数据,大数据与常规数据位于单独的行中。尽管自从过去几年以来,大数据一直是数据分析的流行语,但有关大数据分析的新问题是建立实时大数据管道。简单地说,就是建立一个有效的大数据分析系统,使组织能够即时做出决策。
在实时大数据管道中,你需要考虑各种因素,例如实时欺诈分析、日志分析、预测错误以衡量正确的业务决策。
因此,要实时处理这种高速海量数据,高度可靠的数据处理系统就成为了时代的需求。市场上有许多开源工具和技术可用于执行实时大数据管道操作。在此文中,我们要讨论最受欢迎的几个——Apache Hadoop、Apache Spark和Apache Kafka。
为什么实时大数据管道在当今如此重要?
据估计,到2020年,每秒将创建约1.7兆字节的数据。这导致对实时和流数据分析的需求增加。对于历史数据分析,使用描述性,描述性和预测性分析技术。另一方面,对于实时数据分析,流数据分析是选择。实时分析的主要好处是可以实时分析和可视化报告。
通过实时大数据管道,我们可以执行实时数据分析,从而实现以下功能:
帮助制定运营决策。
根据结果建立的决策将实时应用于业务流程、不同的生产活动和交易。
可以应用于说明性模型或预先存在的模型。
帮助同时生成历史数据和当前数据。
根据预定义的参数生成警报。
持续监控实时更改交易数据集。
实时大数据管道系统有哪些不同功能?
实时大数据管道应具有一些可满足业务需求的基本功能,此外,它不应超出组织的成本和使用限制。
大数据管道系统必须具备的功能:
大容量数据存储:系统必须具有健壮的大数据框架,例如Apache Hadoop。
消息系统:它应该具有发布-订阅消息支持,例如Apache Kafka。
预测分析支持:系统应支持各种机器学习算法。因此,它必须具有必需的库支持,例如Apache Spark MLlib。
灵活的后端,用于存储结果数据:处理后的输出必须存储在某个数据库中。因此,应该有一个灵活的数据库,最好是NoSQL数据。
报告和可视化支持:系统必须具有某些报告和可视化工具,例如Tableau。
警报支持:系统必须能够生成文本或电子邮件警报,并且必须有相关的工具支持。
为什么Apache Hadoop,Apache Spark和Apache Kafka成为了实时大数据管道的选择?
在选择用于构建大数据管道的工具或技术时,需要衡量以下一些关键点:
组件
参量
大数据管道的组件包括:
消息传递系统。
消息分发支持到各个节点以进行进一步的数据处理。
数据分析系统,可从数据中得出决策。
数据存储系统,用于存储结果和相关信息。
数据表示和报告工具以及警报系统。
大数据管道系统必须具有的重要参数:
兼容大数据
低延迟
可扩展性
多样性——意味着它可以处理各种用例
灵活性
经济适用
诸如Apache Hadoop、Apache Spark和Apache Kafka之类的技术选择可以解决上述问题。因此,这些工具是构建实时大数据管道的首选。
Apache Hadoop、Apache Spark和Apache Kafka在大数据管道系统中扮演什么角色?
在大数据管道系统中,两个核心过程是:
消息系统
数据提取过程
消息传递系统是大数据管道中的入口点,Apache Kafka是用作输入系统的发布——订阅消息传递系统。对于消息传递,Apache Kafka提供了两种利用其API的机制:
制片人
用户
使用优先级队列,它将数据写入生产者。然后,数据由侦听器订阅。它可以是Spark侦听器,也可以是任何其他侦听器。Apache Kafka可以处理大量和高频数据。
消息系统中的数据一旦可用,就需要以实时方式进行摄取和处理。Apache Spark通过使用其流API使其成为可能。此外,Hadoop MapReduce在某些架构中处理数据。
Apache Hadoop为Apache Spark和Apache Kafka提供了在其之上运行的生态系统。此外,它通过其HDFS提供持久的数据存储。同样出于安全目的,可以在Hadoop群集上配置Kerberos。由于诸如Apache Spark和Apache Kafka之类的组件在Hadoop集群上运行,因此这些安全功能也涵盖了这些组件,并启用了强大的大数据管道系统。
如何使用Apache Hadoop、Apache Spark和Apache Kafka构建大数据管道?
建立实时大数据管道遵循两种架构:
Lambda体系结构
Kappa体系结构
Lambda体系结构
Lambda体系结构主要有三个目的–
摄取
处理
查询实时和批量数据
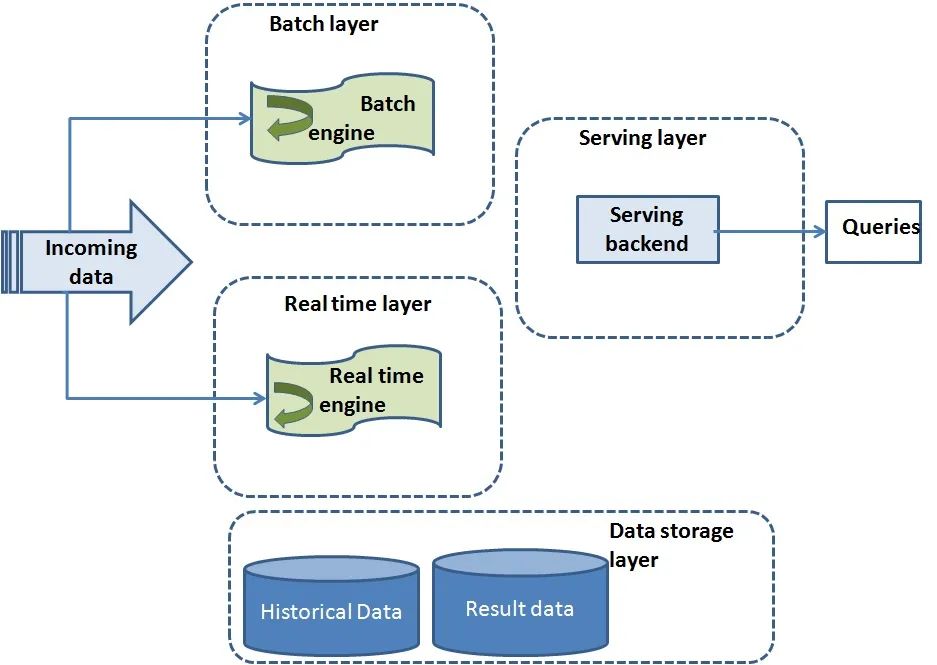
单一数据体系结构用于以上三个目的。此架构由三层Lambda架构组成:
速度层
服务层
批处理层
这些层主要执行实时数据处理,并识别系统中是否发生任何错误。
Lambda体系结构如何工作?
从输入源数据进入系统并路由到批生产层和速度层。输入源可以是诸如Apache Kafka之类的pub-sub消息传递系统。
Apache Hadoop位于批处理层,并且扮演着持久数据存储的角色,执行两个最重要的功能:
管理主数据集。
预先计算批处理视图。
服务层为批处理视图建立索引,从而可以实现低延迟查询。NoSQL数据库用作服务层。
速度层仅处理实时数据。同样,在数据流传输期间出现任何数据错误或数据丢失的情况下,它也会管理高延迟的数据更新。因此,在Hadoop层中运行的批处理作业将通过定期运行MapReduce作业来弥补这一不足。结果,速度层将实时结果提供给服务层。通常,Apache Spark用作速度层。
最后,生成合并结果,该合并结果是实时视图和批处理视图的组合。
Apache Spark用作批处理和速度层的标准平台。这促进了两层之间的代码共享。
Kappa体系结构
Kappa体系结构由两层组成,而不是Lambda体系结构中的三层。这些层是:
实时层/流处理
服务层
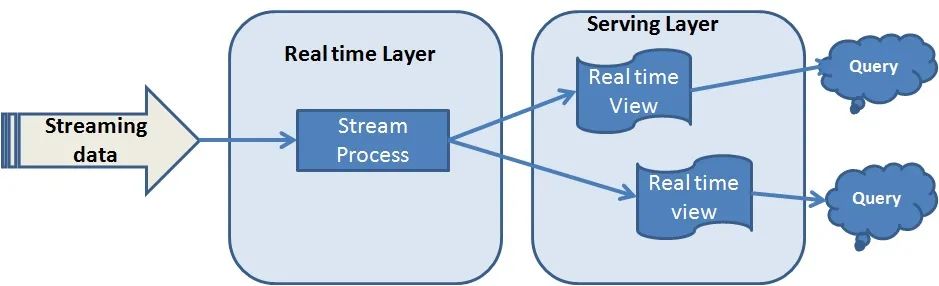
Kappa体系结构工作流程:
在这种情况下,传入的数据将通过Apache Kafka之类的消息传递系统通过实时层提取。
在实时层或流处理中,处理数据。通常,此层使用Apache Spark,因为它支持批处理和流数据处理。
实时层的输出结果被发送到服务层,该服务层是像NoSQL数据库这样的后端系统。
Apache Hadoop为Apache Spark和Apache Kafka提供了生态系统。
Kappa体系结构的主要优点是它可以通过单个流处理引擎处理实时数据和连续数据。
企业如何通过实时大数据管道获得收益?
如果适当地部署了大数据管道,则可以为组织带来很多好处。由于它可以启用实时数据处理并检测实时欺诈,因此可以帮助组织避免收入损失。大数据管道可以应用于任何业务领域,并且对业务优化产生巨大影响。
总之,使用Apache Hadoop、Spark和Kafka构建大数据管道系统是一项复杂的任务。它需要对指定技术和集成的深入了解。但是,如今大数据管道已成为组织的迫切需求,如果你想探索这一领域,则首先必须掌握大数据技术。
备注 “ 进群 ” (广告勿扰)
【海牛大数据交流群】

以上是关于技术干货具有HadoopSpark和Kafka的实时大数据管道的主要内容,如果未能解决你的问题,请参考以下文章
#yyds干货盘点#Alibaba中间件技术系列「RocketMQ技术专题」让我们一同来看看RocketMQ和Kafka索引设计