单线程照样飞起 | redis字典快速映射+hash釜底抽薪+渐进式rehash
Posted 烟花散尽13141
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了单线程照样飞起 | redis字典快速映射+hash釜底抽薪+渐进式rehash相关的知识,希望对你有一定的参考价值。
前言
-
相信你一定使用过新华字典吧!小时候不会读的字都是通过字典去查找的。在
Redis中也存在相同功能叫做字典又称为符号表!是一种保存键值对的抽象数据结构 -
本篇仍然定位在【redis前传】系列中,因为本篇仍然是在解析redis数据结构!当你尝试去了解redis时才能明白其中原理!才能明白为什么redis被大家吹捧速度快,而不是被告知redis很快!
应用场景
- 在Redis中有很多场景都是用了字典作为底层数据结构!我们使用最多的应该是redis的库的设置和五种基本数据类型的Hash结构数据!
- 在上一篇【redis前传】中我们学习了list数据结构。今天我们继续学习主流数据结构Hash。
- 在redis内部有字典结构、hash结构但是这里的hash和我们平时熟知的redis基础数据的hash并不是一个意思!我们简单的将字典结构、hash结构理解成redis更加底层的一种抽象结构。平时我们使用的hash基础数据结构理解成hash工具
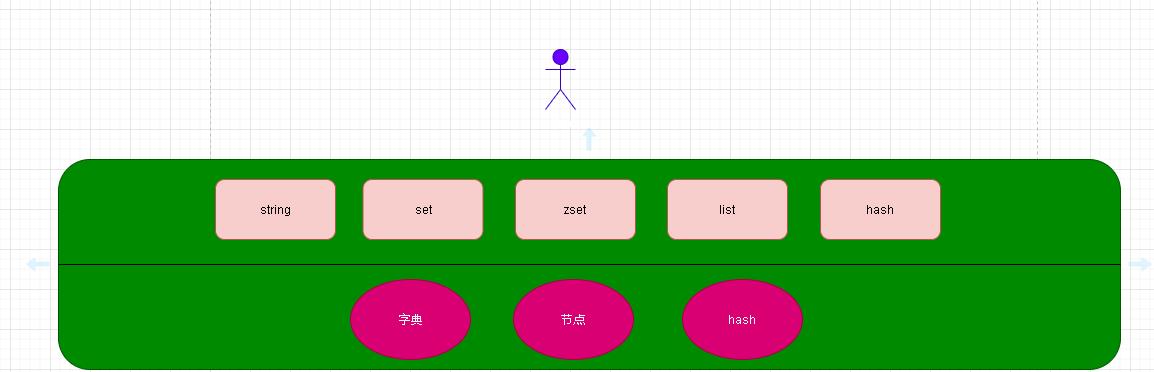
- 而今天我们的主角就是五种数据结构的Hash分析。他的底层使用了字典这个结构。字典结构内部使用的是底层的hash结构。有点绕!好好理解你行的
哈希表
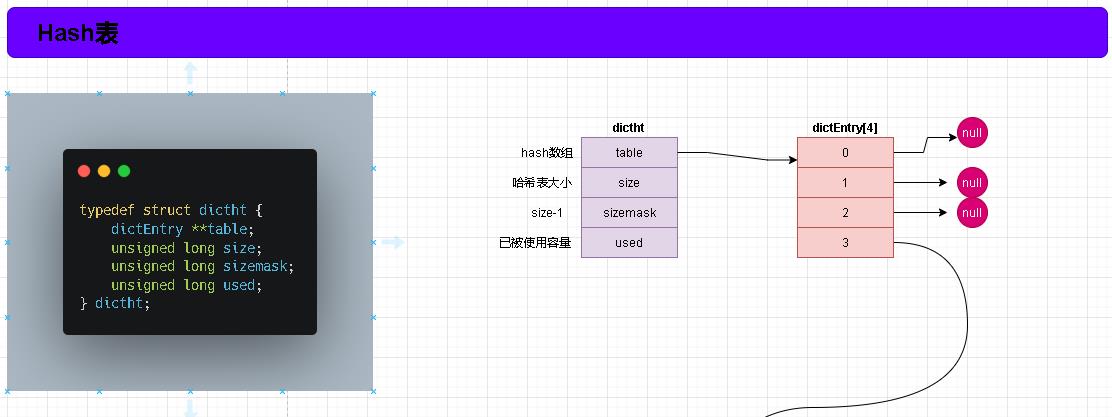
- 上面这张图诠释了作为redis底层结构的Hash。在内部redis称之为dictht 。 后面我们为什么和之前的hash结构冲突我们都已类名为准叫做dictht类。
- 在hictht类中有四个属性分别是table 、 size 、 sizemask 、 used ; 其中table就是一个数组;数组中元素是另外一个类叫做dictEntry类。
- dictEntry就是真正存储数据的。内部是key、value存储结构。一个简单的哈希表就如图所示。数据最终会存储在table中的dictEntry对象中。
- 至于为什么sizemask = size -1 ; 这个是为了在计算hash索引时需要用到的。那为什么不直接使用size-1而是通过一个变量来承接呢?这个吧!!!我也不知道。容我去百度百度。
数组节点
- 上面的哈希表是不是很熟悉,这不和我们Java中的Map数据结构如出一辙吗。可以说是也可以说不是,两者很相似但也有区别的。
- 在上面中我们提到数据最终是存储在哈希表里table数组里的元素。该元素叫dictEntry 。 下面我们看看dictEntry结构如何吧!
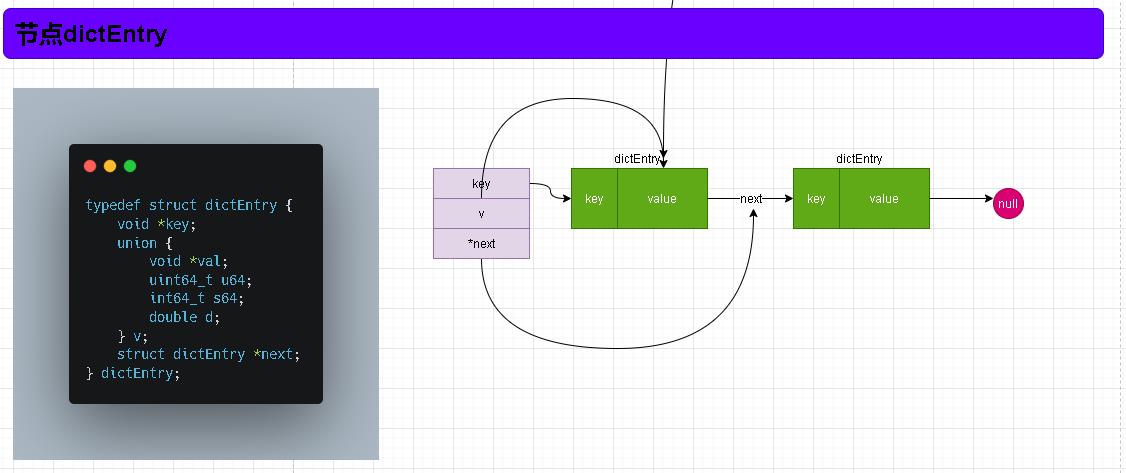
- 通过左侧对dictEntry的定义我们可以看出。dictEntry存储的值可以是指针、正数、浮点数各种数据类型!类似于Java中的Object属性。 对于上述的key没有啥真意的就是一个键。
- 既然是数组那么索引就是固定长度的,那么在有限的长度中肯定会出现经典问题就是【hash冲突】。在Java中我们是通过链表和红黑树来解决冲突的问题!在redis中是通过链表解决的。在dictEntry中通过next指针将冲突元素连接。
- 这里我们就可以和Java中的Map结构进行理解。他们内部很是相似!!!
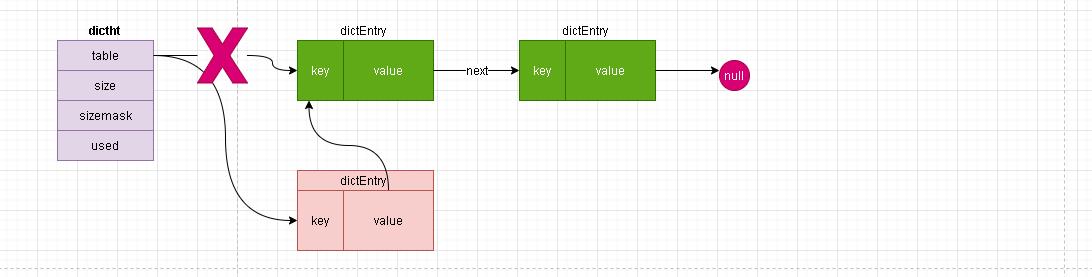
- 这里需要注意下在hash冲突时redis的确是通过链表进行存储的,但是由于哈希表(dictht)中没有记录每个索引未中链表的尾部节点只有头结点信息所以。而且我们也知道链表在查询上效率不佳,所以当发生哈希冲突时redis是将新加入的节点加入在链表的头部!
字典
多态字典
- 字典是本文开头提出的结构!也是redis中大量使用的一种底层数据结构。在redis中名叫做dict类。
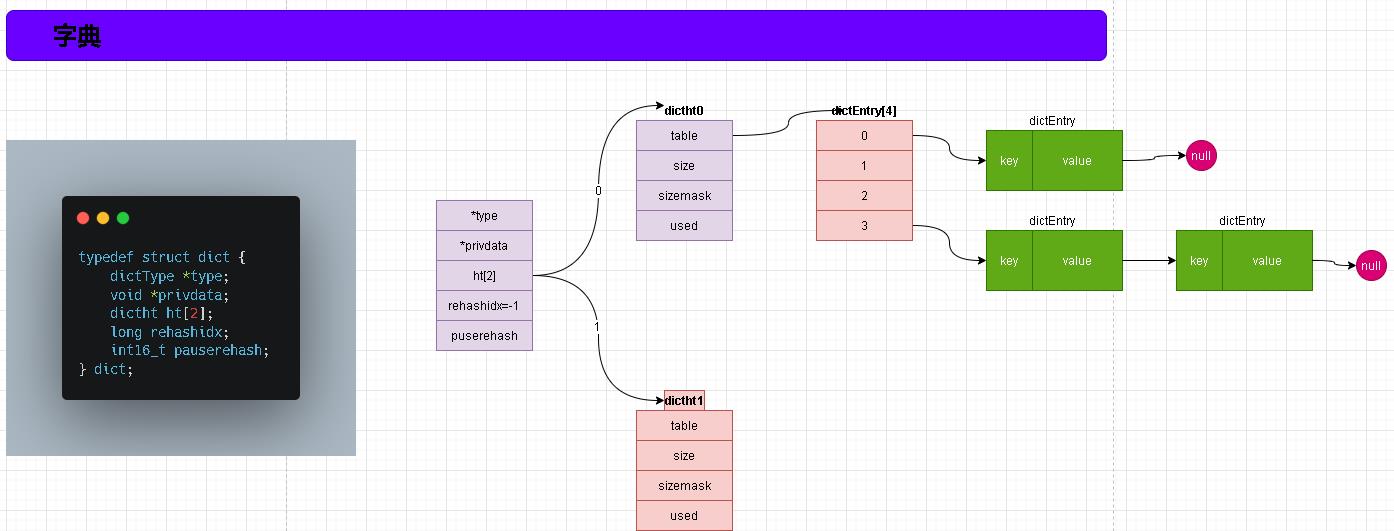
- 通过图示我们明确的看出内部是包含哈希表的。其实从名字上我们也可以看出哈希表为什么叫dictht 。 笔者这里认为是dicthashcodetable 。 意思就是字典表内部的一个hash相关的数组(仅个人理解)
- 之前也提到过redis内部很多地方会使用到字典!就好比我们上学是用到【新华字典】、【成语词典】、【歇后语词典】等等。虽然名字叫法不一样但是内部结构都是一部字典供我们快速定位。而redis中dict内部就是通过type字段进行区分每个字典的。而privdata是每部字典需要的特定参数。通过type和privdata就可以轻松实现各种功能不同的字典,他有个专有名词叫~~多态字典~~
rehash
- 除了type 、 privdata以外剩下的就是ht 、 rehashidx了。其中ht是一个长度为2的数组。数组里元素就是我们之前提到了哈希表(dictht) 。 ht为什么长度为2 这就需要我们了解下redis的rehash过程了。而rehashidx就是记录rehash的进度!在没有发生rehash的时候rehashidx=-1;
- 在实际使用过程中在字典中我们所有的数据都会存储在ht[0]对应的哈希表中。ht[1]永远都是一个空数组。这些都是为什么rehash做准备,在正式开始之前我们先来了解下redis为什么需要rehash这个动作
- 首先我们在哈希表中是一个定长数组发生冲突时内部是通过链表解决的。理论上一个哈希表可以存储足够的数据,这里的足够就是指空间允许的范围有多少存多少。但是我们知道链表的特点就是新增、删除很快但是查询很慢,尤其是当链表很长的时候就会出现查询效率低下的问题!为了避免链表过长redis就会在一定条件下对哈希表中数组长度的扩展从而解决局部链表过长的问题!
- 每次数组发生长度变化时,那么之前的hash值就需要重新经历一遍hash然后寻址index的过程。这个过程就叫做rehash 。
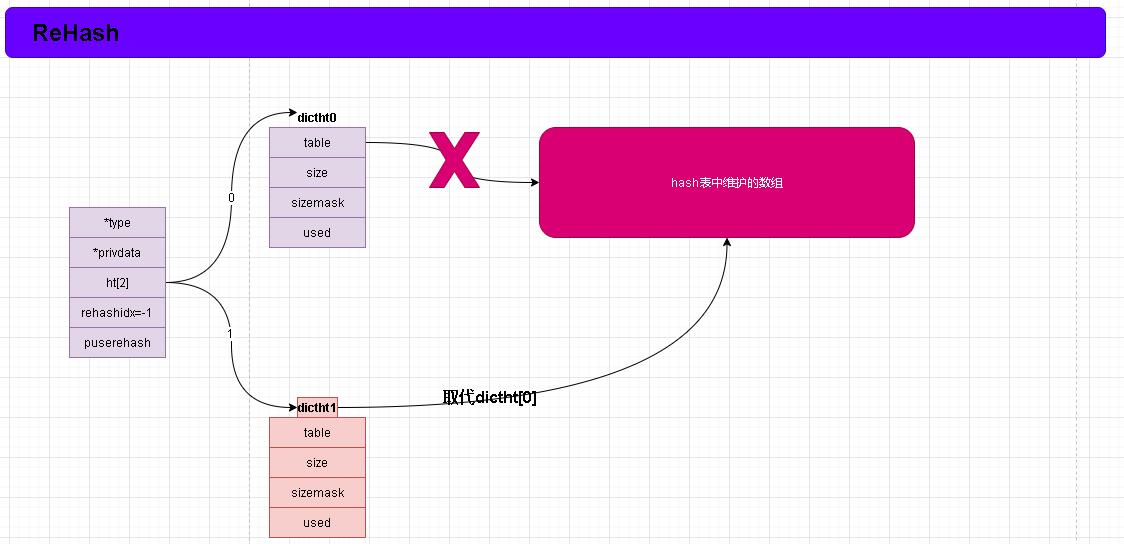
- 关于rehash和Java中Map的resize是一样的功能!Java中resize是直接new 出一片内存进行复制的而且他是每次进行2倍扩展。而redis的rehash稍微不同基本上我们也可以理解成2倍扩展!关于两块内存复制有点类似于JVM中垃圾回收有点类似。有时间我们可以一起研究下JVM章节。
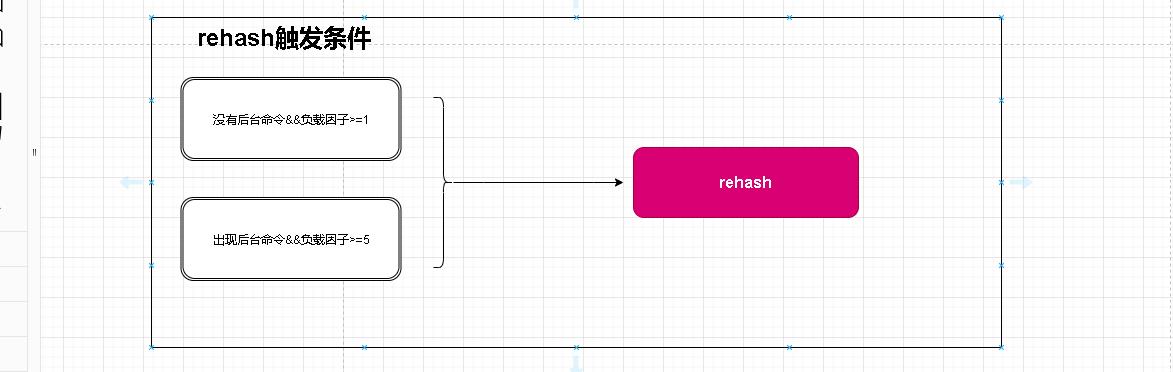
- 那么啥时候需要进行rehash呢?这里和Java的负载因子一样;但是除了负载因子这个空间考核以外redis还考虑一个性能的问题。因为在单线程的前提下我们还要考虑客户端使用的感知性!单线程的意思就是执行命令是顺序执行的。总不能在我们rehash的过程中全部阻塞客户端的使用这对于操作体验上稳定性来说是不友好的。

- 涉及到上述两个命令的我们称之为后台命令结合负载因子产生如下条件


渐进式rehash
-
一直强调redis是单线程。那么什么叫单线程模型?就是对于redis服务来说执行命令是线性操作!但是每个客户端的命令是无序的,先到的就先进入队列redis服务从队列一次取出命令进行执行。除了客户端的命令还有一些系统生成的命令比如说我们上面提到的rehash操作!
-
①、首先为了避免阻塞客户端或者说尽量控制阻塞的时间在客户端感知范围内,redis内部的rehash并不是一次性操作而是一个循序渐进的过程。一次仅复制一部分
-
②、还记得之前我们提到dict中rehashidx这个属性吗,他是记录rehash的进度。因为哈希表内部是一个数组而rehashidx就是记录这个数组的索引。从而我们也可以知道每次rehash复制的时候是已一个索引完整链表为单元进行复制的。
-
③、除了新增以外的其他操作都会同时影响到ht[0]、ht[1] 因为在rehash过程中两个数组都是在使用状态的
-
④、新增值的时候就只需要新增到ht[1]中。因为最终的目的就是将所有值同步到ht[1]中。而ht[0]的值会慢慢的变少;没必要新增到ht[0]
-
⑤、在rehash过程中查找元素时会查找两个数组中的并集元素。这也就也是了为什么再rehash过程新增元素只需要新增到ht[1]的原因
总结
①、字典表在redis被广泛使用,基于字典表优秀的设计解决redis单线程问题
②、字典里包含哈希表,哈希表内部使用节点负责存储key、value
③、字典type实现多态字典用于多场景!
④、渐进式rehash解决服务卡顿问题
以上是关于单线程照样飞起 | redis字典快速映射+hash釜底抽薪+渐进式rehash的主要内容,如果未能解决你的问题,请参考以下文章
单线程照样飞起 | redis字典快速映射+hash釜底抽薪+渐进式rehash