5 个流行的自然语言处理库及入门用法
Posted AI前线
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了5 个流行的自然语言处理库及入门用法相关的知识,希望对你有一定的参考价值。
本文并不是要从这些解决方案中指定一个最优集合,而是给出一篇概述,介绍精选的 5 个流行库,希望能帮助解决你的问题。
Hugging Face 的 Datasets 库本质上是一个对公开可用的 NLP 数据集的打包集合,带有一组通用的 API 和数据格式,以及一些辅助功能。以下是关于它的介绍:
收集了最多的用于 ML 模型的即开即用 NLP 数据集,具有快速、易用且高效的数据操作工具。
你可以通过以下方式轻松安装 Datasets 库:
pip install datasets
根据介绍,Datasets 提供了两大特性:用于许多公共数据集的单行数据加载器,以及高效的数据预处理。但它的介绍没有提到这个库的另一大特性:与 NLP 任务相关的许多内置评估指标。这个库还有其他一些特性,例如数据集的后端内存管理以及与流行的 Python 工具(如 NumPy、Pandas)和主流机器学习平台(TensorFlow 和 PyTorch)的互操作性。
我们先来看看如何加载一个数据集:
from datasets import load_dataset, list_datasets
print(f"The Hugging Face datasets library contains {len(list_datasets())} datasets")
squad_dataset = load_dataset('squad')
print(squad_dataset['train'][0])
print(squad_dataset)
The Hugging Face datasets library contains 635 datasets
Reusing dataset squad (/home/matt/.cache/huggingface/datasets/squad/plain_text/1.0.0/4c81550d83a2ac7c7ce23783bd8ff36642800e6633c1f18417fb58c3ff50cdd7)
{'answers': {'answer_start': [515], 'text': ['Saint Bernadette Soubirous']}, 'context': 'Architecturally, the school has a Catholic character. Atop the Main Building\'s gold dome is a golden statue of the Virgin Mary. Immediately in front of the Main Building and facing it, is a copper statue of Christ with arms upraised with the legend "Venite Ad Me Omnes". Next to the Main Building is the Basilica of the Sacred Heart. Immediately behind the basilica is the Grotto, a Marian place of prayer and reflection. It is a replica of the grotto at Lourdes, France where the Virgin Mary reputedly appeared to Saint Bernadette Soubirous in 1858. At the end of the main drive (and in a direct line that connects through 3 statues and the Gold Dome), is a simple, modern stone statue of Mary.', 'id': '5733be284776f41900661182', 'question': 'To whom did the Virgin Mary allegedly appear in 1858 in Lourdes France?', 'title': 'University_of_Notre_Dame'}
DatasetDict({
train: Dataset({
features: ['id', 'title', 'context', 'question', 'answers'],
num_rows: 87599
})
validation: Dataset({
features: ['id', 'title', 'context', 'question', 'answers'],
num_rows: 10570
})
})
加载指标也很简单:
from datasets import load_metric, list_metrics
print(f"The Hugging Face datasets library contains {len(list_metrics())} metrics")
print(f"Available metrics are: {list_metrics()}")
# Load a metric
squad_metric = load_metric('squad')
The Hugging Face datasets library contains 19 metrics
Available metrics are: ['accuracy', 'bertscore', 'bleu', 'bleurt', 'comet', 'coval', 'f1', 'gleu', 'glue', 'indic_glue', 'meteor', 'precision', 'recall', 'rouge', 'sacrebleu', 'seqeval', 'squad', 'squad_v2', 'xnli']
你想用它们做什么都随意,但有了这个库,你就可以轻松加载可公开访问的数据集,和久经考验的真实评估指标了。
TextHero 在其 GitHub 存储库中的介绍很简单:
文本预处理、表示和可视化,助你从零迈向大师。
这几句话很好地解释了这个库可以解决的问题,下面我们再深入研究一下为什么我们就要用它。从 repo 中我们可以看到更具体的说明:
TextHero 只有一个非常务实的目标:为开发人员腾出空闲时间。文本数据处理起来可能会很痛苦,在大多数情况下有一个默认管道的话上手起来就轻松多了。总有时间回来改进以前的工作。
现在你知道了为什么要使用 TextHero,它的安装方法如下:
pip install texthero
入门指南 (https://texthero.org/docs/getting-started) 介绍了你可以用它做的工作,几行代码就可以搞定。使用 TextHero Github 存储库中的以下示例,我们会加载一个数据集,清理它,并创建一个 TF-IDF 表示,执行主成分分析(PCA)并绘制 PCA 的结果。
def text_texthero():
import texthero as hero
import pandas as pd
df = pd.read_csv("https://github.com/jbesomi/texthero/raw/master/dataset/bbcsport.csv")
df['pca'] = (
df['text']
.pipe(hero.clean)
.pipe(hero.tfidf)
.pipe(hero.pca)
)
hero.scatterplot(df, 'pca', color='topic', title="PCA BBC Sport news")
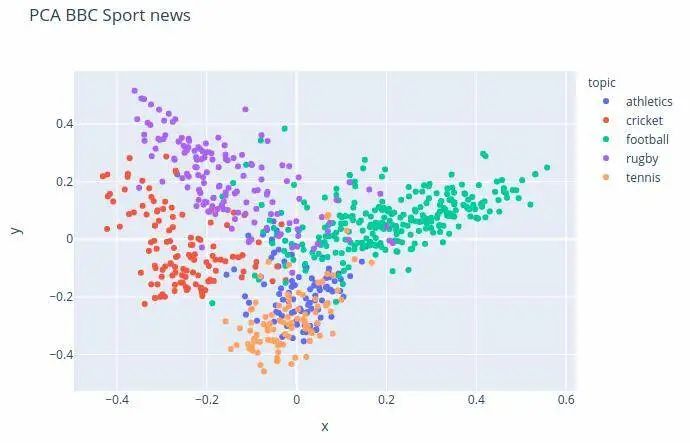
用 TextHero 可以完成的工作还有很多,请继续查阅文档 (https://texthero.org/docs/api-preprocessing),了解数据清理和预处理、可视化、表示、基本 NLP 任务等相关信息。
spaCy 是专门设计的,其宗旨是成为一个用于实现生产就绪系统的有用库。以下是关于它的介绍:
spaCy 旨在帮助你完成真正的工作——构建真正的产品,或收集真正的见解。这个库尊重你的宝贵时间,并尽量避免浪费它。它很容易安装,其 API 简单而高效。我们愿意将 spaCy 视为自然语言处理领域的 Ruby on Rails。
所以当你准备开始做一些真正的工作时,你需要先安装 spaCy 和至少一个语言模型。在下面这个例子中我们将使用它的英语语言模型。库和语言模型只需几行代码即可安装:
pip install spacy
python -m spacy download en
要开始使用 spaCy,我们将使用示例文本的这句话:
sample = u"I can't imagine spending $3000 for a single bedroom apartment in N.Y.C."
现在我们导入 spaCy 和一个英文停用词列表。我们还将英语语言模型作为 Language 对象加载(根据 spaCy 约定,我们将其称为“nlp”),然后在示例文本上调用 nlp 对象,它会返回一个经过处理的 Doc 对象(我们将其称为“doc”)。
import spacy
from spacy.lang.en.stop_words import STOP_WORDS
nlp = spacy.load('en')
doc = nlp(sample)
这样就行了?根据 spaCy文档:
即使一个 Doc 经过了处理——例如拆分为单个单词并注释——它仍 包含原始文本的所有信息,如空格字符。你随时可以将一个符号(token)的偏移量获取到原始字符串中,或者将符号及其尾随空格连接起来来重建原始字符串。这样,在使用 spaCy 处理文本时,你永远不会丢失任何信息。
现在我们来看看处理过的样本:
# Print out tokens
print("Tokens:\n=======)
for token in doc:
print(token)
# Identify stop words
print("Stop words:\n===========")
for word in doc:
if word.is_stop == True:
print(word)
# POS tagging
print("POS tagging:\n============")
for token in doc:
print(token.text, token.lemma_, token.pos_, token.tag_, token.dep_,
token.shape_, token.is_alpha, token.is_stop)
# Print out named entities
print("Named entities:\n===============")
for ent in doc.ents:
print(ent.text, ent.start_char, ent.end_char, ent.label_)
Tokens:
=======
I
ca
n't
imagine
spending
$
3000
for
a
single
bedroom
apartment
in
N.Y.C.
Stop words:
===========
ca
for
a
in
POS tagging:
============
I -PRON- PRON PRP nsubj X True False
ca can VERB MD aux xx True True
n't not ADV RB neg x'x False False
imagine imagine VERB VB ROOT xxxx True False
spending spend VERB VBG xcomp xxxx True False
$ $ SYM $ nmod $ False False
3000 3000 NUM CD dobj dddd False False
for for ADP IN prep xxx True True
a a DET DT det x True True
single single ADJ JJ amod xxxx True False
bedroom bedroom NOUN NN compound xxxx True False
apartment apartment NOUN NN pobj xxxx True False
in in ADP IN prep xx True True
N.Y.C. n.y.c. PROPN NNP pobj X.X.X. False False
Named entities:
===============
3000 26 30 MONEY
N.Y.C. 65 71 GPE
spaCy 功能强大、坚持己见(opinionated),可用于从预处理到表示再到建模的各种 NLP 任务。查看 spaCy 文档 (https://spacy.io/usage/spacy-101),看看你可以用它做哪些事情。
Hugging Face 的 Transformers 库已成为 NLP 实践不可或缺的一部分,这一点再怎么强调也不为过。根据 GitHub 存储库的介绍:
用于 PyTorch 和 TensorFlow 2.0 的一流自然语言处理
Transformers 提供了数千个预训练模型,可以对 100 多种语言的文本执行分类、信息提取、问答、摘要、翻译、文本生成等任务。它的目标是让所有人都更容易使用尖端的 NLP 技术。
Transformers 提供了很多 API,可以用来在给定文本上快速下载和使用这些预训练模型,在你自己的数据集上对它们进行微调,然后在我们的模型中心与社区共享。同时,定义架构的 python 模块都可以作为一个独立的模块进行修改,以实现快速的研究实验。
Transformers 由两个最流行的深度学习库 PyTorch 和 TensorFlow 提供支持,它们之间无缝集成,允许你使用一个模型来训练你的模型,然后加载它来推理另一个。
你可以使用 Write With Transformer(https://transformer.huggingface.co/) 在线测试 Transformer 库,这是该库的官方功能演示。
这个很复杂的库安装起来却很简单:
pip install transformers
Transformers 库包罗万象,你可以花很多时间学习它的所有细节。然而,它自带的管道 API 让你可以立即使用模型,几乎不需要配置。以下是使用 Transformers 管道进行分类的一个示例(请注意,应先安装 TensorFlow 或 PyTorch 才能继续):
from transformers import pipeline
# Allocate a pipeline for sentiment-analysis
classifier = pipeline('sentiment-analysis')
# Classify text
print(classifier('I am a fan of KDnuggets, its useful content, and its helpful editors!'))
[{'label': 'POSITIVE', 'score': 0.9954679012298584}]
多简单,很有趣吧。这个管道使用了一个预训练的模型以及用于该模型的预处理,即使没有微调,结果也非常不错。
下面是第二个管道示例,这次是问题回答:
from transformers import pipeline
# Allocate a pipeline for question-answering
question_answerer = pipeline('question-answering')
# Ask a question
answer = question_answerer({
'question': 'Where is KDnuggets headquartered?',
'context': 'KDnuggets was founded in February of 1997 by Gregory Piatetsky in Brookline, Massachusetts.'
})
# Print the answer
print(answer)
{'score': 0.9153624176979065, 'start': 66, 'end': 90, 'answer': 'Brookline, Massachusetts'}
当然上面是一对简单的示例,但这些管道非常强大,绝不止是解决一些与 KDnuggets 相关的琐碎任务那么简单!你可以在此处 (https://huggingface.co/transformers/main_classes/pipelines.html) 阅读有关管道的更多信息。
Transformers 让最先进的模型也能轻松供所有人使用。请访问它的 GitHub 存储库 (https://github.com/huggingface/transformers),探索更多精彩。
Scattertext 用于创建吸引人的可视化图像,来描述语言在不同文档类型之间的差异。根据其 GitHub 仓库的介绍:
这是一种用于在语料库中查找区分术语,并将它们呈现在交互式 HTML 散点图中的工具。与术语对应的点被有选择地标记出来,防止它们与其他标签或点重叠。
还没搞懂的话,我们先来安装它:
pip install scattertext
以下示例来自它的 GitHub 存储库,可视化了 2012 年美国大选中使用的术语。
2,000 个与党派最相关的一元分词(unigram)显示为散点图中的点。它们的 x 轴和 y 轴分别是共和党和民主党发言人使用它们的密集等级。
请注意,运行示例代码会生成一个 HTML 文件,然后可以在浏览器中查看该文件并与之交互。
import scattertext as st
df = st.SampleCorpora.ConventionData2012.get_data().assign(
parse=lambda df: df.text.apply(st.whitespace_nlp_with_sentences)
)
corpus = st.CorpusFromParsedDocuments(
df, category_col='party', parsed_col='parse'
).build().get_unigram_corpus().compact(st.AssociationCompactor(2000))
html = st.produce_scattertext_explorer(
corpus,
category='democrat', category_name='Democratic', not_category_name='Republican',
minimum_term_frequency=0, pmi_threshold_coefficient=0,
width_in_pixels=1000, metadata=corpus.get_df()['speaker'],
transform=st.Scalers.dense_rank
)
open('./demo_compact.html', 'w').write(html)
查看时保存的 HTML 文件的结果(下面显示的是静态图像,因此不是交互式的):
Scattertext 的用途很窄,但效果很好。它的可视化输出绝对很漂亮,而且富含见解。
原文链接:
https://www.kdnuggets.com/2021/02/getting-started-5-essential-nlp-libraries.html
你也「在看」吗? 以上是关于5 个流行的自然语言处理库及入门用法的主要内容,如果未能解决你的问题,请参考以下文章 Android 必须知道2018年流行的框架库及开发语言,看这一篇就够了!