Java并发多线程编程——线程池的原理与使用
Posted 小志的博客
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Java并发多线程编程——线程池的原理与使用相关的知识,希望对你有一定的参考价值。
目录
一、线程池概述
1、线程池的理解
- 线程池是一种多线程处理形式,处理过程中将任务添加到队列,然后在创建线程后自动启动这些任务。
- 线程池线程都是后台线程。每个线程都使用默认的堆栈大小,以默认的优先级运行,并处于多线程单元中。
- 线程池维护着多个线程,等待着监督管理者分配可并发执行的任务。
2、为什么使用线程池
- 提高程序的执行效率。避免了在处理短时间任务时创建与销毁线程的代价。
- 控制线程的数量,防止程序崩溃。高并发情况下,如果有100万个线程,JVM就需要有保存100万个线程的空间,容易出现内存溢出。
3、线程池的优势
- 降低资源消耗。通过重复利用已创建的线程降低线程创建和销毁造成的消耗。
- 提高响应速度。当任务到达时,任务可以不需要的等到线程创建就能立即执行。
- 提高线程的可管理性。线程是稀缺资源,如果无限制的创建,不仅会消耗系统资源,还会降低系统的稳定性,使用线程池可以进行统一的分配,调优和监控。但是要做到合理的利用线程池,必须对其原理了如指掌。
二、ThreadPoolExecutor 类中参数认识
1、ThreadPoolExecutor 类中构造参数如下图:
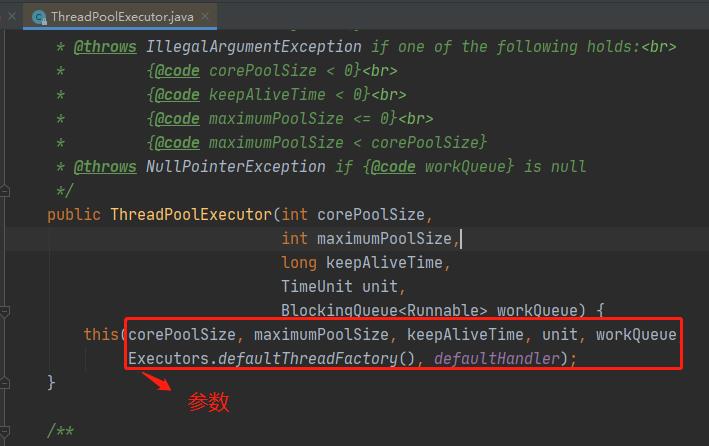
2、ThreadPoolExecutor 类中构造参数认识
-
corePoolSize :线程池的基本大小,当提交一个任务到线程池时,线程池会创建一个线程来执行任务,即使其他空闲的基本线程能够执行新任务也会创建线程,等到需要执行的任务数大于线程池基本大小时就不再创建。如果调用了线程池prestartAllCoreThreads方法,线程池会提前创建并启动所有基本线程。
-
maximumPoolSize :线程池最大大小,线程池允许创建的最大线程数。如果队列满了,并且已创建的线程数小于最大线程数,则线程池会再创建新的线程执行任务。值得注意的是如果使用了无界的任务队列这个参数就没什么效果。
-
keepAliveTime :线程活动保持时间,线程池的工作线程空闲后,保持存活的时间。所以如果任务很多,并且每个任务执行的时间比较短,可以调大这个时间,提高线程的利用率。
-
TimeUnit :线程活动保持时间的单位,可选的单位有天(DAYS),小时(HOURS),分钟(MINUTES),毫秒(MILLISECONDS),微秒(MICROSECONDS, 千分之一毫秒)和毫微秒(NANOSECONDS, 千分之一微秒)。
-
workQueue :任务对列,用于保存等待执行的任务的阻塞队列。可以选择以下几个阻塞队列。
(1)、ArrayBlockingQueue 是一个基于数组结构的有界阻塞队列,此队列按 FIFO(先进先出)原则对元素进行排序。
(2)、LinkedBlockingQueue 是一个基于链表结构的阻塞队列,此队列按FIFO (先进先出) 排序元素,吞吐量通常要高于ArrayBlockingQueue。静态工厂方法Executors.newFixedThreadPool()使用了这个队列。
(3)、SynchronousQueue 是一个不存储元素的阻塞队列。每个插入操作必须等到另一个线程调用移除操作,否则插入操作一直处于阻塞状态,吞吐量通常要高于LinkedBlockingQueue,静态工厂方法Executors.newCachedThreadPool使用了这个队列。
(4)、PriorityBlockingQueue是一个具有优先级得无限阻塞队列。 -
ThreadFactory :用于设置创建线程的工厂,可以通过线程工厂给每个创建出来的线程设置更有意义的名字,Debug和定位问题时非常又帮助。
-
handler(饱和策略):当队列和线程池都满了,说明线程池处于饱和状态,那么必须采取一种策略处理提交的新任务。这个策略默认情况下是AbortPolicy,表示无法处理新任务时抛出异常。可以选择以下几个策略。
(1)、CallerRunsPolicy :只用调用者所在线程来运行任务。
(2)、DiscardOldestPolicy:丢弃队列里最近的一个任务,并执行当前任务。
(3)、DiscardPolicy:不处理,丢弃掉。
(4)、当然也可以根据应用场景需要来实现RejectedExecutionHandler接口自定义策略。如记录日志或持久化不能处理的任务。
3、ThreadPoolExecutor 类其他属性
// 线程池的控制状态:用来表示线程池的运行状态(整型的高3位)和
//运行的worker数量(低29位)
private final AtomicInteger ctl = new AtomicInteger(ctlOf(RUNNING, 0));
// 29位的偏移量
private static final int COUNT_BITS = Integer.SIZE - 3;
// 最大容量(2^29 - 1)
private static final int CAPACITY = (1 << COUNT_BITS) - 1;
// runState is stored in the high-order bits
//线程运行状态,总共有5个状态,需要3位来表示(所以偏移量的29 = 32 - 3)
/**
* RUNNING :接受新任务并且处理已经进入阻塞队列的任务
* SHUTDOWN:不接受新任务,但是处理已经进入阻塞队列的任务
* STOP: 不接受新任务,不处理已经进入阻塞队列的任务并且中断正在运行的任务
* TIDYING: 所有的任务都已经终止,workerCount为0, 线程转化为TIDYING状态并且调用terminated钩子函数
* TERMINATED:terminated钩子函数已经运行完成
**/
private static final int RUNNING = -1 << COUNT_BITS;
private static final int SHUTDOWN = 0 << COUNT_BITS;
private static final int STOP = 1 << COUNT_BITS;
private static final int TIDYING = 2 << COUNT_BITS;
private static final int TERMINATED = 3 << COUNT_BITS;
// 阻塞队列
private final BlockingQueue<Runnable> workQueue;
// 可重入锁
private final ReentrantLock mainLock = new ReentrantLock();
// 存放工作线程集合
private final HashSet<Worker> workers = new HashSet<Worker>();
// 终止条件
private final Condition termination = mainLock.newCondition();
// 最大线程池容量
private int largestPoolSize;
// 已完成任务数量
private long completedTaskCount;
// 线程工厂
private volatile ThreadFactory threadFactory;
// 拒绝执行处理器
private volatile RejectedExecutionHandler handler;
// 线程等待运行时间
private volatile long keepAliveTime;
// 是否运行核心线程超时
private volatile boolean allowCoreThreadTimeOut;
// 核心池的大小
private volatile int corePoolSize;
// 最大线程池大小
private volatile int maximumPoolSize;
// 默认拒绝执行处理器
private static final RejectedExecutionHandler defaultHandler =new AbortPolicy();
三、ThreadPoolExecutor 类中构造方法详解
1、ThreadPoolExecutor 类构造方法源码截图
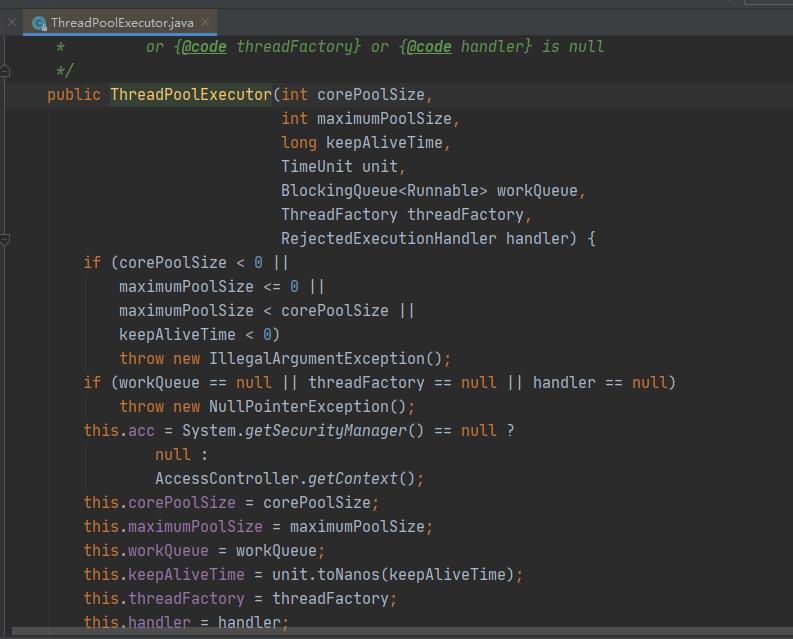
2、ThreadPoolExecutor 类构造方法源码解析
public ThreadPoolExecutor(int corePoolSize,
int maximumPoolSize,
long keepAliveTime,
TimeUnit unit,
BlockingQueue<Runnable> workQueue,
ThreadFactory threadFactory,
RejectedExecutionHandler handler) {
/**
* corePoolSize < 0 核心大小不能小于0
* maximumPoolSize<= 0 线程池的初始最大容量不能小于0
* maximumPoolSize < corePoolSize 初始最大容量不能小于核心大小
* keepAliveTime < 0 keepAliveTime不能小于0
**/
if (corePoolSize < 0 ||
maximumPoolSize <= 0 ||
maximumPoolSize < corePoolSize ||
keepAliveTime < 0)
throw new IllegalArgumentException();
/**
* workQueue == null 任务对列不能为空
* threadFactory == null 线程工厂不能为空
* handler == null 饱和策略不能为空
**/
if (workQueue == null || threadFactory == null || handler == null)
throw new NullPointerException();
this.acc = System.getSecurityManager() == null ?
null :
AccessController.getContext();
// 初始化相应的域
this.corePoolSize = corePoolSize;
this.maximumPoolSize = maximumPoolSize;
this.workQueue = workQueue;
this.keepAliveTime = unit.toNanos(keepAliveTime);
this.threadFactory = threadFactory;
this.handler = handler;
}
四、ThreadPoolExecutor 类中提交任务方法详解
1、ThreadPoolExecutor 类中提交任务方法源码截图
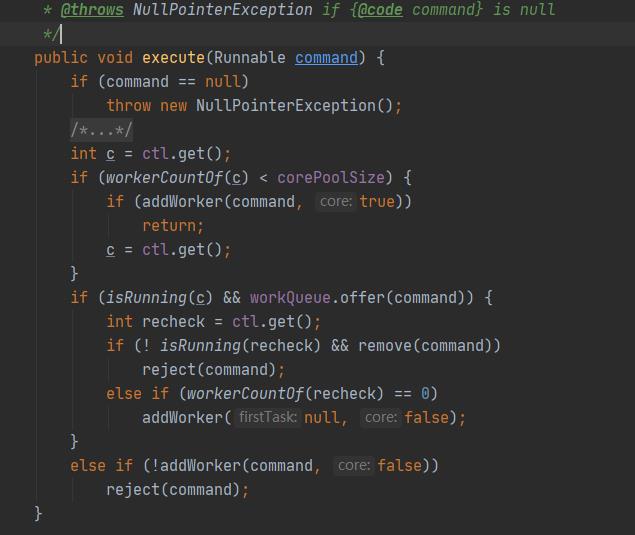
2、ThreadPoolExecutor 类中提交任务方法解析
/*
* 进行下面三步
*
* 1. 如果运行的线程小于corePoolSize,则尝试使用用户定义的Runnalbe对象创建一个新的线程
* 调用addWorker函数会原子性的检查runState和workCount,通过返回false来防止在不应
* 该添加线程时添加了线程
* 2. 如果一个任务能够成功入队列,在添加一个线城时仍需要进行双重检查(因为在前一次检查后
* 该线程死亡了),或者当进入到此方法时,线程池已经shutdown了,所以需要再次检查状态,
* 若有必要,当停止时还需要回滚入队列操作,或者当线程池没有线程时需要创建一个新线程
* 3. 如果无法入队列,那么需要增加一个新线程,如果此操作失败,那么就意味着线程池已经shut
* down或者已经饱和了,所以拒绝任务
*/
public void execute(Runnable command) {
if (command == null)
throw new NullPointerException();
int c = ctl.get();// 获取线程池控制状态
if (workerCountOf(c) < corePoolSize) {// worker数量小于corePoolSize
if (addWorker(command, true))// 添加worker
return; // 成功则返回
c = ctl.get(); // 不成功则再次获取线程池控制状态
}
// 线程池处于RUNNING状态,将用户自定义的Runnable对象添加进workQueue队列
if (isRunning(c) && workQueue.offer(command)) {
int recheck = ctl.get(); // 再次检查,获取线程池控制状态
// 线程池不处于RUNNING状态,将自定义任务从workQueue队列中移除
if (! isRunning(recheck) && remove(command))
reject(command); // 拒绝执行命令
else if (workerCountOf(recheck) == 0)// worker数量等于0
addWorker(null, false);// 添加worker
}
else if (!addWorker(command, false))// 添加worker失败
reject(command); // 拒绝执行命令
}
五、创建一个线程池并提交线程任务示例
1、示例(使用默认的AbortPolicy饱和策略)
-
代码
java package com.xz.thread.threadPool; import java.util.concurrent.ArrayBlockingQueue; import java.util.concurrent.ThreadPoolExecutor; import java.util.concurrent.TimeUnit; /** * @description: * @author: xz * @create: 2021-06-21 21:26 */ public class Demo { public static void main(String[] args) { //创建线程池 ThreadPoolExecutor pool = new ThreadPoolExecutor(10,20, 10, TimeUnit.DAYS,new ArrayBlockingQueue<>(10)); //创建100个线程,并放到到线程池中 for(int i=1;i<=100;i++){ pool.execute(new Runnable() { @Override public void run() { System.out.println(Thread.currentThread().getName()); } }); } } } -
输出结果如下
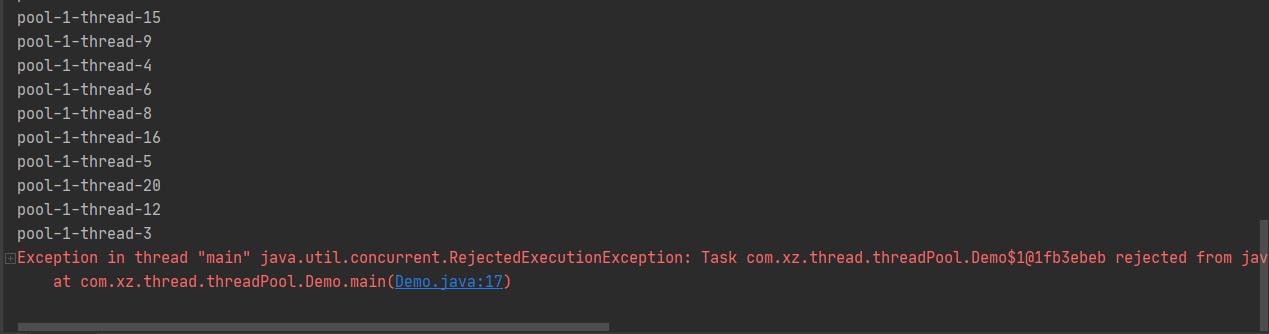
-
报错原因
(1)、如上图报RejectedExecutionException这个异常,是因为涉及到饱和策略;
(2)、RejectedExecutionHandler(饱和策略):当队列和线程池都满了,说明线程池处于饱和状态,那么必须采取一种策略处理提交的新任务。这个策略默认情况下是AbortPolicy,表示无法处理新任务时抛出异常。
2、示例(使用DiscardOldestPolicy饱和策略)
- 代码
package com.xz.thread.threadPool;
import java.util.concurrent.ArrayBlockingQueue;
import java.util.concurrent.ThreadPoolExecutor;
import java.util.concurrent.TimeUnit;
import java.util.concurrent.atomic.AtomicInteger;
/**
* @description:
* @author: xz
* @create: 2021-06-21 21:46
*/
public class Demo {
public static void main(String[] args) {
//创建线程池,并使用DiscardOldestPolicy饱和策略
ThreadPoolExecutor pool = new ThreadPoolExecutor(10,20,
10, TimeUnit.DAYS,new ArrayBlockingQueue<>(10),new ThreadPoolExecutor.DiscardOldestPolicy());
//创建100个线程,并放到到线程池中
for(int i=1;i<=100;i++){
pool.execute(new Runnable() {
@Override
public void run() {
System.out.println(Thread.currentThread().getName());
}
});
}
}
}
- 输出结果如下,报错消失
以上是关于Java并发多线程编程——线程池的原理与使用的主要内容,如果未能解决你的问题,请参考以下文章