技术选型:为什么批处理我们却选择了Flink
Posted 深度操作系统
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了技术选型:为什么批处理我们却选择了Flink相关的知识,希望对你有一定的参考价值。
最近接手了一个改造多平台日志服务的需求,经过梳理,我认为之前服务在设计上存在缺陷。经过一段时间的技术方案调研,最终我们决定选择使用 Flink 重构该服务。
目前重构后的服务已成功经受了国庆节流量洪峰的考验,今日特来总结回顾,和大家分享一下经验。
业务需求及背景
在了解改造服务的需求前,我们首先要明确,要解决什么问题以及目前的服务是如何解决的。
当前的业务逻辑还是比较清晰的:
采集同一时段不同数据源的日志;
对采集的数据进行处理;
将处理后的数据上传到指定位置,供客户下载。
我们面临的痛点和难点:
日志的数据量比较大:每小时未压缩的日志数据量有 50 多个 G,节假日等特殊时间节点,日志量会翻倍。
目前服务使用单机进行处理,速度比较慢,扩容不方便。
目前服务处理数据时需要清洗字段,按时间排序,统计某字段的频率等步骤。这些步骤都属于 ETL 中的常规操作,但是目前是以代码的形式实现的,我们想以配置形式减少重复编码,尽量更加简单、通用。
方案1:我们需要一个数据库吗?
针对以上业务需求,有同学提出:“我们可以把所有原始数据放到数据库中,后续的 ETL 可以通过 SQL 实现。”
如果你一听到"数据库"想到的就是 Pg、mysql、Oracle 等,觉得这个方案不具有可行性,那你就错了。数据库的类型和维度是非常丰富的,如下图所示:
△数据库行业全景图
按业务负载特征,关系型数据库可分为 OLTP 数据库(交易型)和 OLAP 数据库(分析型) :
OLTP,Online Transaction Processing。OLTP 数据库最大的特点是支持事务,增删查改等功能强大,适合需要被频繁修改的"热数据"。我们耳熟能详的 Mysql、Pg 等都属于这一类。缺点就是由于支持事务,插入时比较慢。拿来实现我们的需求显然是不合适的。
OLAP,Online Analytical Processing,数据分析为主。不支持事务,或者说是对事务的支持有限。OLAP 的场景是:大多数是读请求,数据总是以相当大的批(> 1000 rows)进行写入,不修改已添加的数据。
方案 1 小结
OLAP 的使用场景符合我们的需求,为此我们还专门去调研了一下 ClickHouse。但是有一个因素让我们最终放弃了使用 OLAP。请注意,数据库存储的数据都是二维的,有行和列两个维度。但是日志只有行一个维度。如果说为了把日志存入数据库把每行日志都切分,那统计字段的需求也就顺手实现了,又何必存到数据呢?
所以,OLAP 使用场景隐含的一个特点是:存入的数据需要被多维度反复分析的。这样才有把数据存入数据库的动力,像我们当前的需求对日志进行简单的变形后仍旧以文本日志的形式输出,使用 OLAP 是不合适的。
方案2:Hive 为什么不行?
看到这,熟悉大数据的同学可能会觉得我们水平很 Low,因为业务需求归根到底就是三个字:批处理。
那我们为什么第一时间没有考虑上大数据呢?
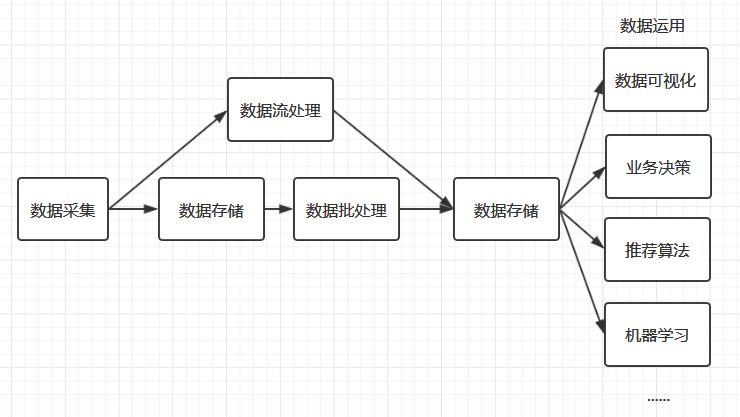
△ 大数据处理流程
大数据确实如雷贯耳,但现在我们的日志处理这块大部分都是用 Golang 实现的,团队内的其他业务用了 Python、Lua、C,就是没有用过到 Java。而目前大数据都是基于 JVM 开发的。Golang 调用这些服务没有一个好用的客户端。
所以基于团队目前的技术储备,大数据才没有成为我们的首选。但是从目前的状况来看大数据是最优解了。那么我们该选用大数据的什么组件实现需求呢?
放弃使用数据库直接使用 HDFS 存储日志文件,应该是毋庸置疑的。
我们需求是离线批处理数据,对时效性没有要求,MapReduce 和 Hive 都能满足需求。但是 MapReduce 与 Hive 相比,Hive 在 MapReduce 上做了一层封装并且支持 SQL。看起来 Hive 是非常合适的。
那为什么最终放弃了 Hive 呢?
机器资源问题。公司其他团队已经有一套 HDFS 的设施,只用来做存储,Hadoop 的 MapReduce 这个组件根本没跑起来。那套 HDFS 部署的机器资源比较紧张,他们担心我们使用 MapReduce 和 Hive 跑计算,会影响现在 HDFS 的性能; 我们想审批一批新的机器,重新使用 Ambari 搭建一套 Hadoop,却被告知没那么多闲置的机器资源。而且我们即便申请下来了机器,只跑目前服务也跑不满,机器资源大部分也会被闲置,也有浪费资源的嫌疑。
存储分离是趋势。在调研中我们发现,像 Hadoop 这样把存储和计算放到一起的已经比较"落伍"了。Hadoop 存储分离,需要修改源码,目前没有开源实现,只是云厂商和各个大数据公司有相关商业产品。从这个角度讲,即便我们自己搞定了机器资源搭一套 Hadoop,也只不过是拾人牙慧罢了。
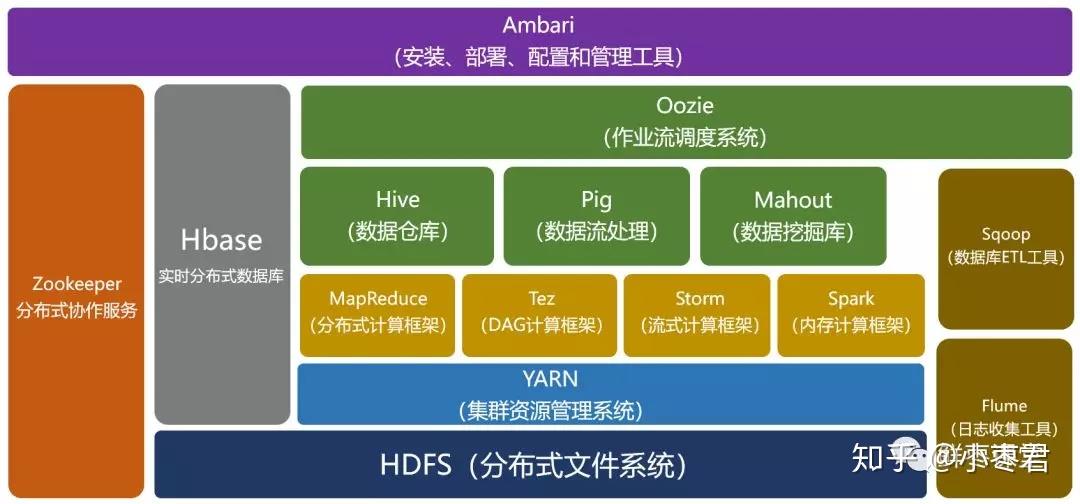
△大数据生态图
方案 2 小结
再合适的技术方案不能落地也是空谈。但是技术方案想要落地时,已经不是一个单纯的技术问题了,资源限制,团队限制等都需要考虑在内。
一个优秀的技术方案立足于解决当下的问题,并且能放眼未来勾画蓝图,这样大家觉得 "有利可图",才愿意跟你一起折腾。
方案3:为什么我们放弃了 Spark?
通用的计算引擎
虽然使用 HDFS 的团队不赞成在他们的机器上跑 Hive,但是我们把日志数据存到他们的 HDFS 上还是没问题的。在已知 "存储和分离是趋势" 是前提的基础下,"我们到底需要什么" 这个问题已经有答案了。
我们需要的是一个通用的计算引擎。存储已经剥离给 HDFS 了,所以我们只需要找一个工具,帮我们处理 ETL 就可以了。Spark 和 Flink 正是这样的场景。
Spark 与 Flink 初次交锋
Spark 和 Flink 之间,我们毫不犹豫地选择了 Spark。原因非常简单:
Spark 适合批处理。Spark 当初的设计目标就是用来替换 MapReduce。而 Spark 流处理的能力是后来加上去的。所以用 Spark 进行批处理,可谓得心应手。
Spark 成熟度高。Spark 目前已经发布到 3.0,而 Flink 尚在 Flink 1.x 阶段。Flink 向来以流处理闻名,虽然被国内某云收购后开始鼓吹 "流批一体",但是线上效果还是有待检验的。
Scala 的加持。Spark 大部分是用 Scala 实现的。Scala 是一门多范式的编程语言,并且与 Haskell 有很深的渊源。Haskell 是一门大名鼎鼎的函数式编程语言。对于函数式编程语言,想必大多数程序猿都有一种 "虽不能至,然心向往之" 的情结。现在使用 Spark 能捎带着耍一耍函数式编程语言 Scala,岂不妙哉?

△ Scala
挥泪斩 Spark
前文已经交代过了,我们否决掉 Hive 的一个重要因素是没有足够的机器资源。所以我们把 Spark 直接部署到云平台上。
对于我司的云平台要补充一些细节。
我们的云平台是基于 K8S 二次开发的,目前还在迭代当中,因此"Spark on K8S" 的运行模式我们暂时用不了。在这样的情况下,我们采用了 "Spark Standalone" 的模式。Standalone 模式,也就是Master Slaver 模式,类似于 nginx 那样的架构,Master 节点负责接收分发任务,Slaver 节点负责"干活"。
等到我们在云平台上以 "Spark Standalone" 模式部署好了,跑了几个测试 Case 发现了新问题。我们的云平台与办公网络是隔离的,如果办公网络想访问云平台的某个 Docker 容器,需要配置域名。而 Spark 的管理页面上很多 URL 的 domain 是所在机器的 IP,容器的 IP 是虚拟 IP,容器重启后IP 就会改变。具体如图:
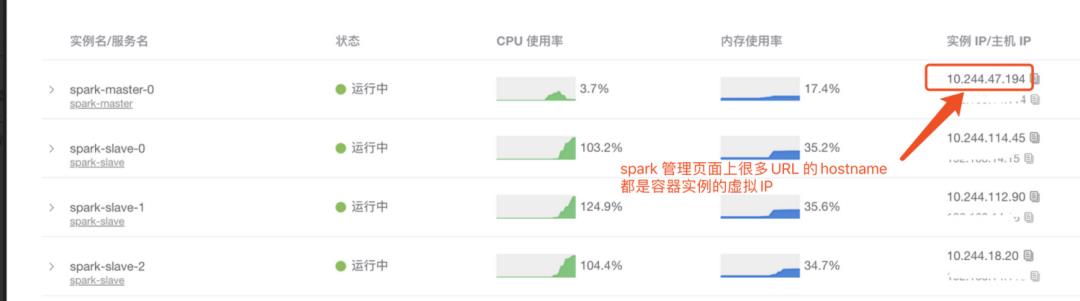
△ 部署在云平台的 spark
Spark 的管理平台非常重要,因为能从这上面看到当前各个节点运行情况,任务的异常信息等,现在很多链接不能访问,不利于我们对 Spark 任务进行问题排查和调优。基于这个原因,我们最终放弃了 Spark。
方案 3 小结
Spark 你真的很优秀,擅长批处理,如此成熟,还有函数式的基因 。。。这些优点早让我倾心不已。
Spark 你真的是个好人,如果不是云平台的限制,我一定选择你。
Spark,对不起。
方案4:Flink,真香!
给 Spark 发完好人卡后,我们看一看新欢 Flink。不客气的说,Flink 初期时很多实现都是抄的 Spark,所以二者的很多概念相似。所以 Flink 同样有 Standalone 模式,我们在部署阶段没遇到任何问题。
在跑了几个 Flink 测试 Case 后,我们由衷的感叹 Flink 真香。
放弃 Spark 时我们的痛点在于 "部署在云平台上的 Spark 服务的管理界面很多功能无法使用",而 Flink 的管理平台完全没有这个问题。除此之外,Flink 管理平台的 "颜值" 和功能都是 Spark 无法比拟的。
管理平台颜值对比
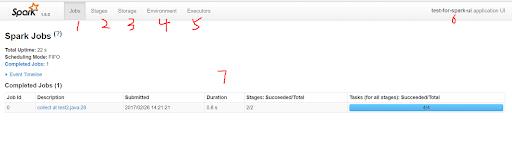
△ Spark管理平台页面
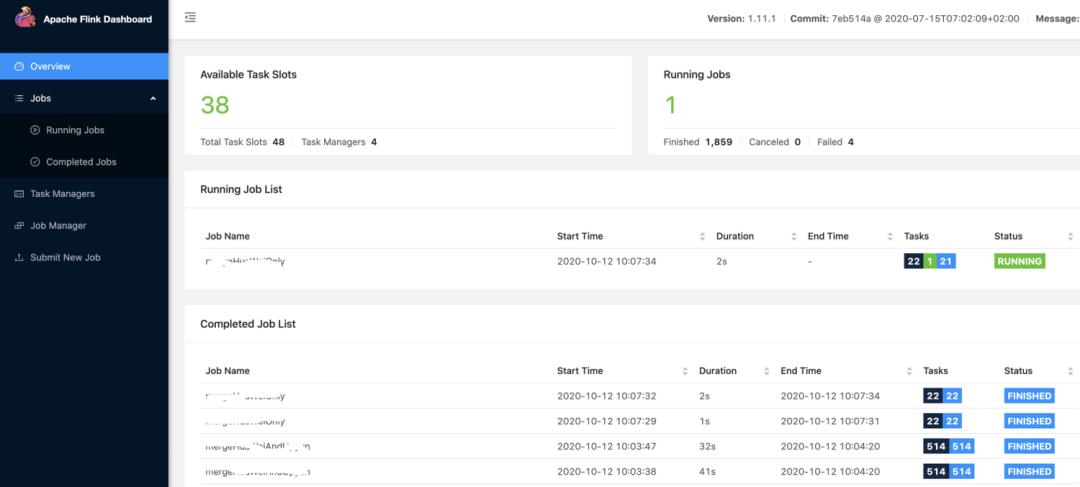
△ Flink管理平台页面
对比之下,Spark 的页面完全是个"黄脸婆"。
Flink 管理平台功能
由于 Spark 的功能很多不能使用,所以就不重点和 Flink 做比较了。这里只说 Flink 几个让人眼前一亮的功能。
完善的 Restful API
部署了 Flink 或 Spark 服务后,该如何下发计算任务呢? 一般是通过 bin 目录下的一个名称中包含 submit 的可执行程序。那如果想把 Flink 或 Spark 做成微服务,通过 http 接口去下发任务呢?
Spark1.0 的时候支持 http,2.0时这个功能基本上废掉了,很多参数不支持了,把 http 这个功能交由 jobService 一个第三方开源组件去实现。这个 jobService 的开源组件对云平台的支持也非常不友好。所以在我们看来,Spark 通过 Http 下发任务的路子基本被堵死了。
反观 Flink,管理平台的接口是 Restful 的,不仅支持 Http 下发计算任务,还可以通过相关接口查看任务状态和获取异常或返回值。
强大的任务分析能力
Flink 的任务分为几个不同的阶段,每个不同的阶段有不同的颜色。这样仅从颜色就可以判断出当前 Flink 任务执行的大致情况。如下图:
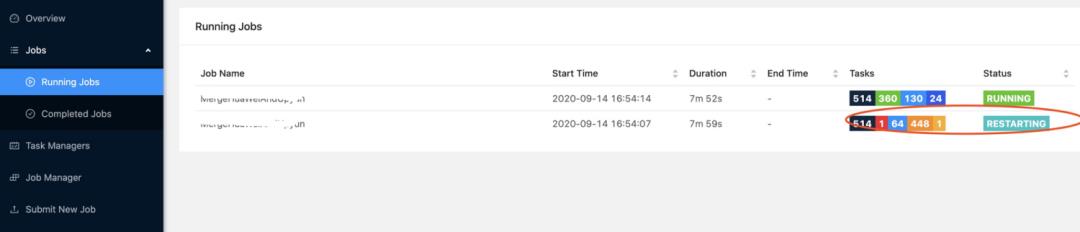
△Flink管理平台页面
在任务详情页面,会有任务分解图和任务执行耗时表格,这两个结合起来能够知道当然 Flink 任务是如何分解的,是否出现数据倾斜的情况,哪个步骤耗时最多,是否有优化的空间。
△管理平台页面
这就是做批处理技术选型时候的心路历程,随笔记了下来,希望对大家有所帮助。
以上是关于技术选型:为什么批处理我们却选择了Flink的主要内容,如果未能解决你的问题,请参考以下文章
数据处理框架选哪个?Spark Streaming与Flink的这些区别你都知道么
SmartNews:基于 Flink 加速 Hive 日表生产的实践