RNN实战进阶手把手教你如何预测当天股票的最高点
Posted AI浩
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了RNN实战进阶手把手教你如何预测当天股票的最高点相关的知识,希望对你有一定的参考价值。
摘要
在头条上有很多人做股市的分析,分析每天大盘的涨跌,我观察了几位,预测的都不理想,我一直想着用AI去预测大盘的涨跌。股市数据是个时间序列数据,用RNN再合适不过了,今天我用GRU手把手教大家实现这一算法。
免责声明
算法的结果不能作为投资的依据!!!如果你根据算法的结果去投资,赔钱别找我啊!

获取原始数据
网站的地址:http://quotes.money.163.com/trade/lsjysj_zhishu_000001.html
在这上面能找到大盘额历史数据,我们选择所有的数据下载下来即可。
下载方法如下图:
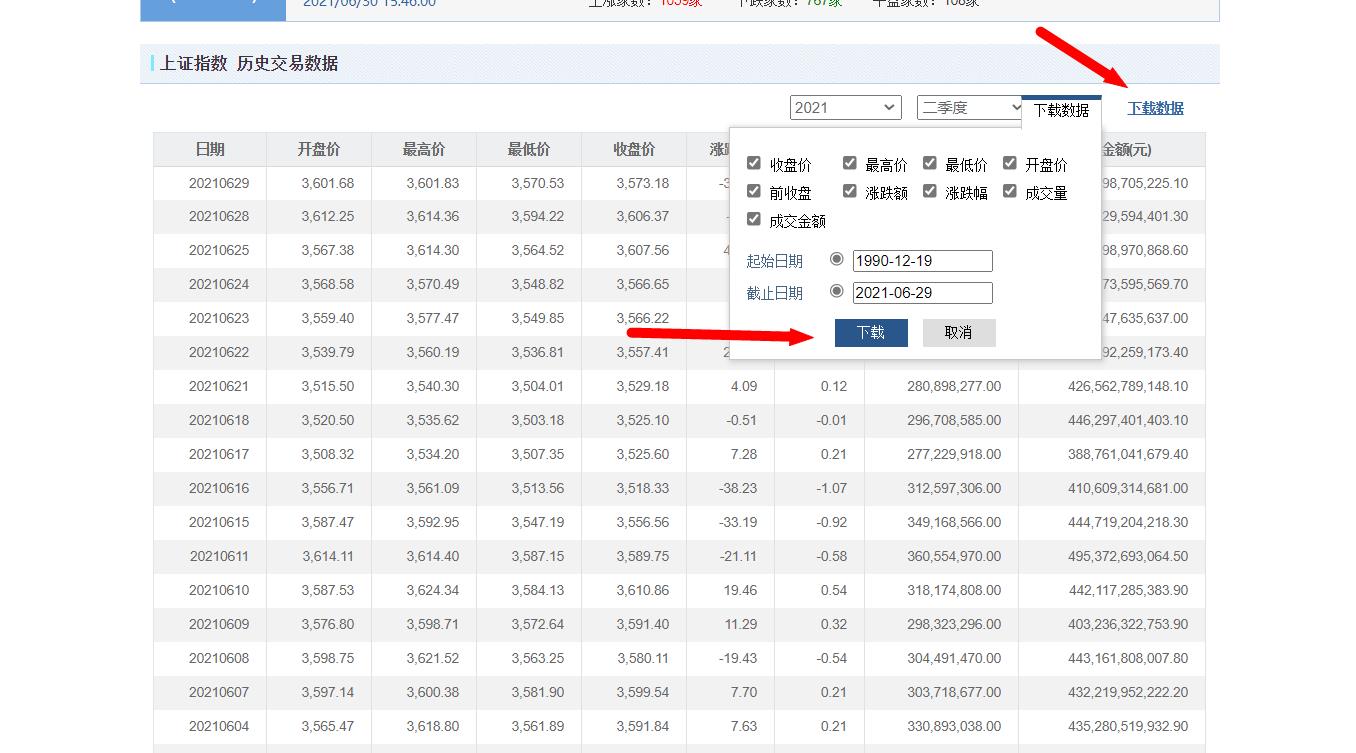
点击下载数据,默认选择全部数据,然后下载即可。
制作训练用的数据
原始的数据不能直接拿来使用,我们需要构建时序数据。我的想法是用前n-1天的数据来预测n天的最高点或者收盘价。所以前n-1天的数据组成x,当天的最高点就是y。
制作数据的具体思路:
第一步 读入数据,把几个“None”替换为0,格式化日期,由于下载的数据默认是按照日期的倒序,所以对日期做升序排列。
第二步 删除“股票代码”、“名称”和日期列。
第三步 定义时序的长度n,n代表用多少天的数据。定义列名cols,类型是list,定义data,存放时序数据。
第四步 循坏df,读取数据,构建时序数据然后存放到data中,这个过程比较慢,不知道有没有快捷的方式,如果有,还请指教。
第五步 保存data数据到sssh.csv 文件中

得到的最终结果是sssh.csv文件,然后就可以训练了。
注:文件的最后一行是test数据,所以没有标签,我设置为0。
完整的代码如下:
import pandas as pd
df = pd.read_csv("000001.csv", encoding='gbk')
df=df.replace("None", '0')
df["日期"] = pd.to_datetime(df["日期"], format="%Y-%m-%d")
df.sort_values(by=["日期"], ascending=True)
del df["股票代码"]
del df["名称"]
df = df.sort_values(by=["日期"], ascending=True)
df.to_csv("sh.csv", index=False, sep=',')
del df['日期']
n = 60
cols = []
for col in df.columns:
for i in range(n):
cols.append(col + str(i))
cols.append('y')
data = []
for k in range(n, len(df) + 1):
onedata = []
for ii in range(n, 0, -1):
for colindex in range(len(df.columns)):
onedata.append(df.values[k - ii][colindex])
if k < len(df):
onedata.append(df.values[k][1])
else:
onedata.append(0)
print(onedata)
data.append(onedata)
df_train = pd.DataFrame(data, columns=cols)
df_train.to_csv("sssh.csv", index=False, sep=',')
构建模型
模型选用GRU,隐藏层设置为64,平台用的pytorch,模型的代码如下:
RNN是模型,TrainSet是数据读取逻辑。
class RNN(nn.Module):
def __init__(self, input_size):
super(RNN, self).__init__()
self.rnn = nn.GRU(
input_size=input_size,
hidden_size=64,
num_layers=1,
batch_first=True
)
self.out = nn.Sequential(
nn.Linear(64, 1),
)
self.hidden = None
def forward(self, x):
r_out, self.hidden = self.rnn(x) # None 表示 hidden state 会用全0的 state
out = self.out(r_out)
return out
class TrainSet(Dataset):
def __init__(self, data, lables):
# 定义好 image 的路径
self.data, self.label = data.float(), lables.float()
def __getitem__(self, index):
return self.data[index], self.label[index]
def __len__(self):
return len(self.data)
特征工程
我做的特征工程有:
1、对标签做缩放,把标签缩放到0到1之间。
2、使用多项式对特征做扩展。
3、对x数据做缩放,缩放到0到1之间。
代码如下:
LR = 0.0001
EPOCH = 300
# 数据集建立
df = pd.read_csv("sssh.csv", encoding='utf-8')
scaler_y = MinMaxScaler(feature_range=(0, 1))
df['y'] = scaler_y.fit_transform(df['y'].values.reshape(-1, 1))
target = df['y']
del df['y']
polyCoder = PolynomialFeatures(degree=2, include_bias=True, interaction_only=False)
df = polyCoder.fit_transform(df)
df = pd.DataFrame(df, columns=polyCoder.get_feature_names())
cols = df.columns
scaler = MinMaxScaler(feature_range=(0, 1))
for clo in cols:
df[clo] = scaler.fit_transform(df[clo].values.reshape(-1, 1))
数据集切分
先把测试集切出来,测试集是最后一行。然后再按照一定比例切分测试集和验证集,切分方法采用train_test_split,切分比例一般是7:3。代码如下:
data = df[:df.shape[0] - 1]
y=target[:df.shape[0] - 1]
test = df[df.shape[0] - 1:]
X_train, X_val, y_train, y_val = train_test_split(data, y, test_size=0.1, random_state=6)
训练验证
第一步 使用DataLoader加载训练集和测试集。
第二步 设置模型的,n是输入的size,优化器采用Adam,loss采用mse。
第三步 测试。
第四部 验证。
整个过程比较简单。
代码如下:
# 第一步
trainloader = DataLoader(trainset, batch_size=64, shuffle=True)
valloader = DataLoader(valset, batch_size=64, shuffle=True)
#第二步
rnn = RNN(n)
optimizer = torch.optim.Adam(rnn.parameters(), lr=LR) # optimize all cnn parameters
loss_func = nn.MSELoss()
#第三步
for step in range(EPOCH):
rnn.train()
for tx, ty in trainloader:
output = rnn(torch.unsqueeze(tx, dim=1))
loss = loss_func(torch.squeeze(output), ty)
optimizer.zero_grad() # clear gradients for this training step
loss.backward() # back propagation, compute gradients
optimizer.step()
print(step, loss)
if step % 10:
torch.save(rnn, 'rnn.pkl')
#第四步
rnn.eval()
for vx, vy in valloader:
output = rnn(torch.unsqueeze(vx, dim=1))
loss = loss_func(torch.squeeze(output), vy)
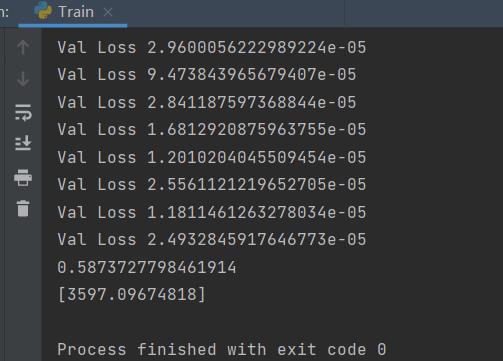
print("Val Loss {}".format(loss))
测试
这个过程就比较简单。
测试test数据,输出结果,然后执行inverse_transform,将结果还原。
rnn.eval()
test = np.array(test)
test = torch.Tensor(test)
test=torch.unsqueeze(test, dim=1)
output=rnn(test)
print(output.data.item())
output=np.array(output.data.item())
inv_y = scaler_y.inverse_transform(output.reshape(-1,1))
inv_y = inv_y[0]
print(inv_y)
预测今天的最高点是3597,实际最高点是3594,差了三个点。
完整代码:https://download.csdn.net/download/hhhhhhhhhhwwwwwwwwww/19934980
以上是关于RNN实战进阶手把手教你如何预测当天股票的最高点的主要内容,如果未能解决你的问题,请参考以下文章
实测 《Tensorflow实例:利用LSTM预测股票每日最高价》的结果