如何查看csv文件的编码格式,我只能在用 wps的Excel 里打开 ?
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了如何查看csv文件的编码格式,我只能在用 wps的Excel 里打开 ?相关的知识,希望对你有一定的参考价值。
如何查看csv文件的编码格式,我只能在用 wps的Excel 里打开 ?
百度也有人问这个问题,但是都答非所问.
具体方法如下:
1、打开WPS表格,然后新建一个文档。
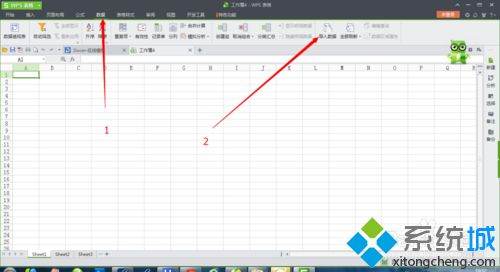
2、依次单击“数据,导入数据”,然后选择需要转换的csv文件后,单击“打开”:
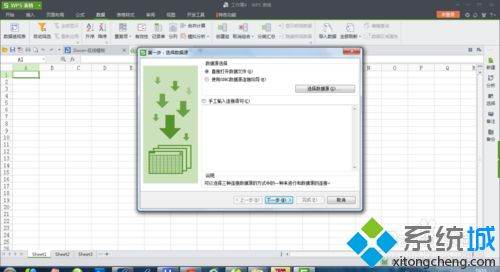
3、点击【直接打开...】 选择【下一步】;
4、打开的csv文件如果有乱码,我们就要选择合适的编码格式,然后下一步。
5、在文本导入向导中,选择“分隔符号”,然后单击“下一步”:
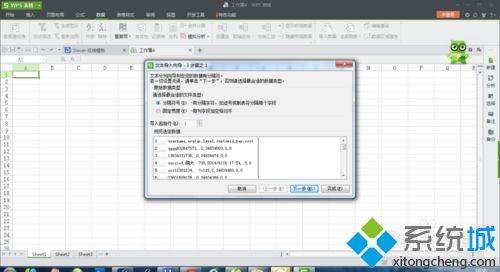
6、勾选“Tab键”和“逗号”,然后单击“下一步”。如果csv文件列分隔符是分号或者其他符号,请勾选相应的选项:
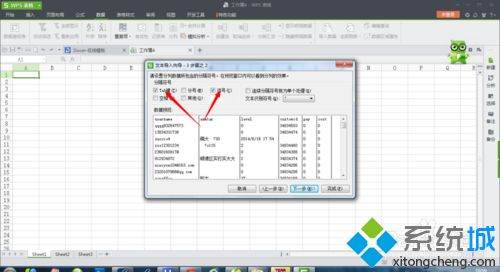
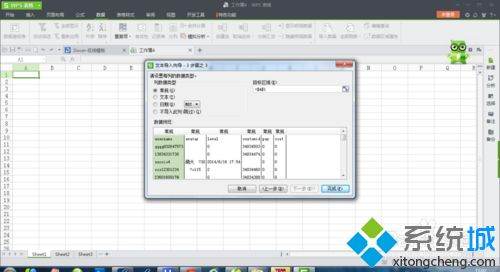
7、在数据预览中,根据数据类型,在文本导入向导的左上角选择相应的数据类型,然后单击“完成”:
Excel 在读取 csv 的时候是通过读取文件头上的 bom 来识别编码的,这导致如果我们生成 csv 文件的平台输出无 bom 头编码的 csv 文件(例如 utf-8 ,在标准中默认是可以没有 bom 头的),Excel 只能自动按照默认编码读取,不一致就会出现乱码问题了。
掌握了这点相信乱码已经无法阻挡我们前进的步伐了:只需将不带 bom 头编码的 csv 文件,用文本编辑器(工具随意,推荐 notepad++ )打开并转换为带 bom 的编码形式(具体编码方式随意),问题解决。
当然,如果你是像我一样的码农哥哥,在生成 csv 文件的时候写入 bom 头更直接点,用户会感谢你的。
附录:
对于 utf-8 编码,unicode 标准中是没有 bom 定义的,微软在自己的 utf-8 格式的文本文件之前加上了EF BB BF三个字节作为识别此编码的 bom 头,这也解释了为啥大部分乱码都是 utf-8 编码导致的原因
window新建的txt、wps默认是ANSI编码格式
比如csv文件,修改编码格式为UTF-8:
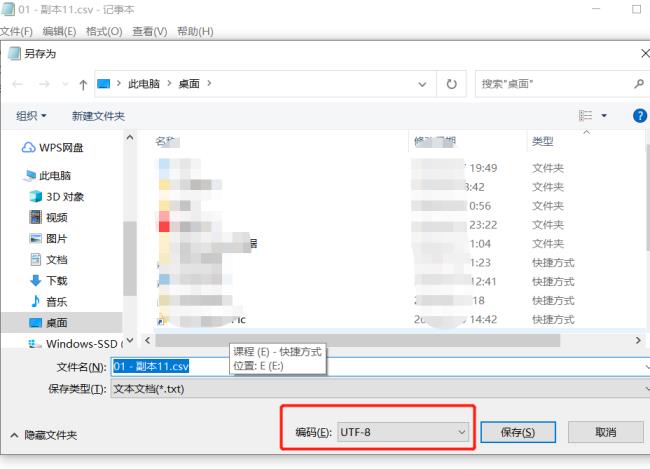
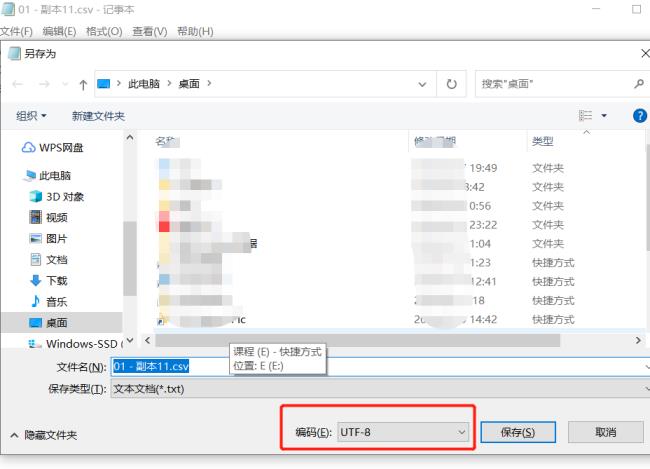
第一步:选中已经转换好的csv文件,并右击鼠标,选择【打开方式】-【记事本】
第二步:点击【文件】-【另存为】
第三步:编码选择UTF-8后,点击【保存】
这样修改之后的csv文件的编码就是UTF-8了。 参考技术B csv文件其实就是一个文本文件。因此用第三方的记事本软件打开,就能看到它的编码。追问
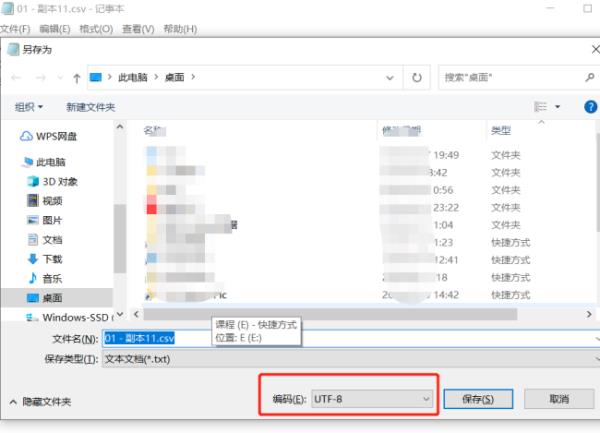
是不是点击保存,编码这里默认显示的就是默认编码?
因为不了解,显示的utf-8是重新选择的,还是文件本身的编码格式.
Python中CSV文件的编码错误
【中文标题】Python中CSV文件的编码错误【英文标题】:Wrong encoding on CSV file in Python 【发布时间】:2021-08-10 18:53:35 【问题描述】:我不确定我是否正确地提出了这个问题,但这是我的问题:
我有一个 .csv 文件 (InjectionWells.csv),我需要根据逗号将其拆分为列。当我这样做时,它只是不起作用,我只能认为可能是一种编码,但我不知道如何修复它。有人能解释一下吗?
以下是实际文件的几行:
API#,Operator,Operator ID,WellType,WellName,WellNumber,OrderNumbers,Approval Date,County,Sec,Twp,Rng,QQQQ,LAT,LONG,PSI,BBLS,ZONE,,,
3500300026,PHOENIX PETROCORP INC,19499,2R,SE EUREKA UNIT-TUCKER #1,21,133856,9/6/1977,ALFALFA,13,28N,10W,C-SE SE,36.9003240,-98.2182600,” 2,500",300,切诺基,,,
3500300163,CHAMPLIN EXPLORATION INC,4030,2R,CHRISTENSEN,1,470258,11/27/2002,ALFALFA,21,28N,09W,C-NW NW,36.8966360,-98.1777200,"2,400","1,000" ,红叉,,,
3500320786,LINN OPERATING INC,22182,2R,NE CHEROKEE UNIT,85,329426,8/19/1988,ALFALFA,24,27N,11W,SE NE,36.8061130,-98.3258400,"1,050","1,000" ,红叉,,,
3500321074,SANDRIDGE 勘探与生产有限责任公司,22281,2R,VELMA,2-19,281652,7/11/1985,ALFALFA,19,28N,10W,SW NE NE SW,36.8885890,-98.3185300,"3,152" ,"1,000",红叉,,,
我已经尝试了这两种方法,但没有一种可以工作:
1.
import pandas as pd
df=pd.read_csv('InjectionWells.csv', sep=',')
print(df)
import pandas as pd
test_data2=pd.read_csv('InjectionWells.csv', sep=',', encoding='utf-8')
test_data2.head()
【问题讨论】:
如果不破坏机密性,显示几行实际 csv 可能会有所帮助。 我包含了指向 CSV 文件的链接,但您是对的,也许显示一些行会更容易理解,但仍然有很多列,我觉得可能包含太多但现在您可以看到。 我无法使用提供的链接中的文件重现您的问题。无论有没有sep 参数,它都能很好地加载。可能是您的环境有问题。您是否可能不小心尝试加载压缩文件?你使用的是什么版本的 Pandas 和 Python?
我还能够使用您提供的数据和代码正确加载 CSV。
@jrbergen 我只加载 CSV 文件而不压缩,我使用的是 Python 3.8 版本和 pandas 1.1.3
【参考方案1】:
由于您的 csv 文件还包含一些非 ascii 字符,因此您需要传递不同的编码。 utf-8 无法处理。
我试过了,它工作正常:-
import pandas as pd
test_data2=pd.read_csv('InjectionWells.csv', sep=',', encoding='ISO-8859-1')
print(test_data2)
请在 cmets 中寻求帮助
很乐意提供帮助!!!
【讨论】:
这可能是问题所在,但如果不传递encoding='utf-8',文件会在此处正常加载,可能会将包含非 utf8 兼容字符的条目替换为 NaN。但这并不能解释他的第一个示例不加载数据框。
那是因为当通过pandas.read_csv()读取时没有传递编码,默认编码为None,errors="replace"表示如果pandas不能编码任何东西那么它就会简单地将其命名为 Nan 并且不会失败。请参考:- pandas.pydata.org/docs/reference/api/pandas.read_csv.html
您好,感谢您的帮助。我尝试了您的建议,但没有解决问题。我尝试再次从原始源下载文件并将其替换为旧文件并工作。也许我用 Python 做的一些事情影响了文件。这次我发布了一个链接,其中包含我正在处理的确切 CSV 文件 (drive.google.com/file/d/1F79iKrXQTLGIaiRhdl5GXtqPMpcqcoAP/…) 并出现错误,以查看是否有人可以澄清我遇到此问题的原因。
让我看看
@Alok Raj 完全正确;这就是我想说的。因此,仅显示 NaNs 的 OP 示例没有意义,因为在不传递编码的情况下加载相同的文件时我没有看到。 @Ricardo Ortega 很高兴它现在可以工作了,也许你的文件在弄乱它的时候已经损坏了。以上是关于如何查看csv文件的编码格式,我只能在用 wps的Excel 里打开 ?的主要内容,如果未能解决你的问题,请参考以下文章