云原生技术分享 | RocketMQ的高可用架构部署攻略
Posted 兴兵乐儿
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了云原生技术分享 | RocketMQ的高可用架构部署攻略相关的知识,希望对你有一定的参考价值。
众所周知,金融行业对于系统的稳定性、可靠性要求非常高,这也是我们在进行系统架构设计时需要重点考虑的一个环节,对于重要系统的可用性HA(High Availability)需要达到 “4个9(也就是99.99%)” 的可用性。
系统引入消息中间件后,虽然能带来一定的优势,如提高了吞吐量,解耦等,但也对实现系统高可用带来了挑战。本文将和大家分享如何配置实现RocketMQ高可用部署。
使用RocketMQ的原则
RocketMQ是阿里开源的消息中间件,它主要由NameServer、Producer、Broker、Consumer四部分构成。
NameServer:NameServer主要负责Broker、Topic和路由信息的管理,功能类似Dubbo的zookeeper。
Broker:消息存储中心,负责存储消息。
Producer:消息生产者,负责产生消息。
Consumer:消息消费者,负责消息消费。
也顺带介绍下——Topic,主题名字,一个Topic由若干Queue组成,queue类似kafka中分区,通过queue提高了topic的水平扩展能力,提高了并发度。
在使用RocketMQ时需主要考虑以下原则:
1. 无论是应用结点还是数据结点,都要有备用(复本)结点,消除单点故障,做到服务高可用;
2. 无论是发送端(Producer),服务端(broker)还是消费端(consumer)都要有一定的容错性,保证服务的高可用,同时确保数据不丢失。
3. 支持故障转移,服务中重要节点出现故障时,备份结点最好能实现自动切换,减少故障修复时间。
接下来,我们针对以下架构进行扩展,实现高可用。
NameServer的高可用
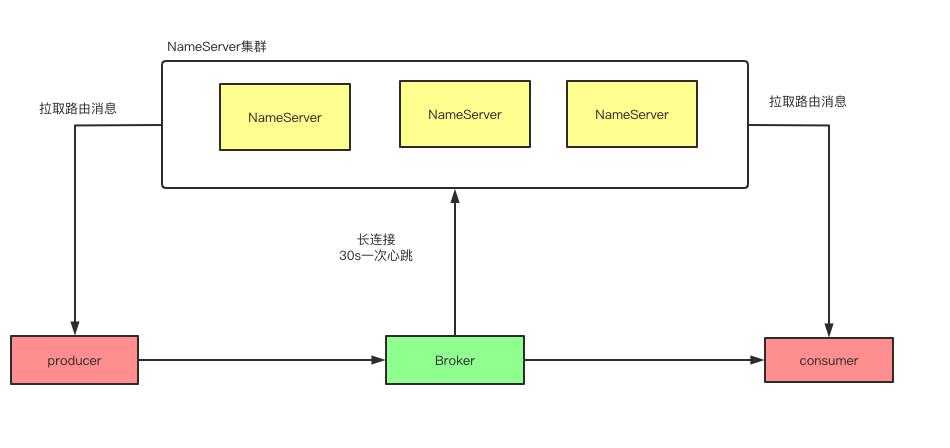
Nameserver是专门针对RocketMQ开发的轻量级协调者,主要功能是临时保存、管理集群路由信息。各个Nameserver节点是无状态的,即每两个Nameserver节点之间不通信,互相不知道彼此的存在。在Broker、生产者、消费者启动时,轮询全部配置的Nameserver节点,拉取路由信息。
要实现生产环境下的高可用RocketMQ集群,首先第一步要实现NameServer的集群化部署,我们可以把NameServer部署在三台机器上,这样可以充分保证NameServer作为路由中心的可用性,只要有一个NameServer在运行,就能保证MQ系统的稳定性。NameServer的设计采用的是Peer-to-Peer的模式,每台NameServer都有完整的集群路由信息。
broker的高可用
在RocketMQ中消息存储的高可用体现在发送成功的消息不能丢、Broker不能发生单点故障,出现Broker异常宕机、操作系统Crash、机房断电或者断网等情况要保证数据不丢。RocketMQ主要通过消息持久化、主从备份的机制来保证。
01
集群部署方案的选择
目前broker支持以下5种部署方式:
单Master模式
这种方式风险较大,一旦Broker重启或者宕机时,会导致整个服务不可用。不建议线上环境使用,可以用于本地测试。
多Master模式
一个集群无Slave,全是Master,例如2个Master或者3个Master,这种模式的优缺点如下:
优点:配置简单,单个Master宕机或重启维护对应用无影响,在磁盘配置为RAID10时,即使机器宕机不可恢复情况下,由于RAID10磁盘非常可靠,消息也不会丢(异步刷盘丢失少量消息,同步刷盘一条不丢),性能最高;
缺点:单台机器宕机期间,这台机器上未被消费的消息在机器恢复之前不可订阅,消息实时性会受到影响。
多Master多Slave模式-异步复制
每个Master配置一个Slave,有多对Master-Slave,HA采用异步复制方式,主备有短暂消息延迟(毫秒级),这种模式的优缺点如下:
优点:即使磁盘损坏,消息丢失的非常少,且消息实时性不会受影响。同时,Master宕机后,消费者仍然可以从Slave消费,而且此过程对应用透明,不需要人工干预,性能同多Master模式几乎一样;
缺点:Master宕机,磁盘损坏情况下会丢失少量消息。
多Master多Slave模式-同步双写
每个Master配置一个Slave,有多对Master-Slave,HA采用同步双写方式,即只有主备都写成功,才向应用返回成功,这种模式的优缺点如下:
优点:数据与服务都无单点故障,Master宕机情况下,消息无延迟,服务可用性与数据可用性都非常高;
缺点:性能比异步复制模式略低(大约低10%左右),发送单个消息的RT会略高,且目前版本在主节点宕机后,备机不能自动切换为主机。
Dledger集群模式
RocketMQ4.5及以上版本支持基于Dledger技术的Broker主从部署架构方案,Dledger 是一个基于 Raft 实现的、高可靠、高可用、强一致的 Commitlog 存储 Library。关于:Dledger 技术在消息领域的探索和应用,大家可以参考(https://www.infoq.cn/article/f6y4QRiDitBN6uRKp*fq)。
Dledger技术是要求至少一个Master带两个Slave,这样有三个Broker组成一个Group,一旦Master宕机,可以从剩余的两个Slave中选举出一个新的Master对外提供服务,实现自动的容灾切换。
02
关于同步刷盘、异步刷盘和同步复制、异步复制的选择
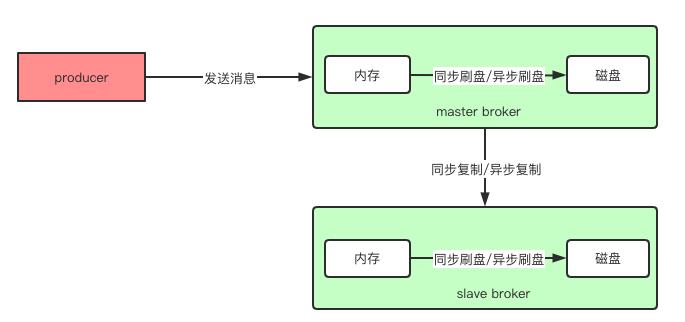
如上图:刷盘是指数据发送到Broker的内存(通常指PageCache)后,持久化到磁盘的方式。
(1) 同步刷盘:只有在消息真正持久化至磁盘后RocketMQ的Broker端才会真正返回给Producer端一个成功的ACK响应。同步刷盘对MQ消息可靠性来说是一种不错的保障,但是性能上会有较大影响,一般适用于金融业务应用该模式较多。
(2) 异步刷盘:能够充分利用OS的PageCache的优势,只要消息写入PageCache即可将成功的ACK返回给Producer端。消息刷盘采用后台异步线程提交的方式进行,降低了读写延迟,提高了MQ的性能和吞吐量。
复制是指Master Broker与slave Broker之间的数据同步方式。分为同步和异步两种。
(1) 异步复制:只要Master写成功即可反馈给客户端写成功状态。
(2) 同步复制:等Master和Slave均写成功后才反馈给produer写成功状态。
大家可以根据项目需求,对同步刷盘、异步刷盘和同步复制、异步复制进行选择。
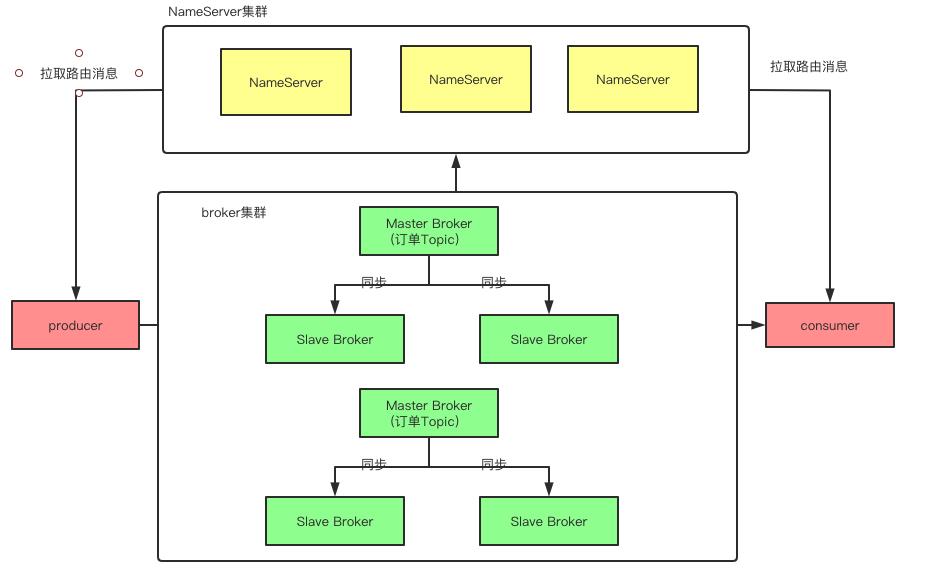
综上,项目架构将变为:
Producer的高可用
01
Producer实例的高可用
Producer作为业务系统中向消息队列发送消息的重要服务,需要集群部署,一方面,消除单个服务因外部原因(如服务器宕机)等导致的单点故障,另一方面,各个节点之间无状态,多个节点共同承担业务需求,实现负载均衡。
02
消息发送的高可用
通常,我们希望在突发网络抖动、Broker或者Nameserver服务异常等极端情况下,Producer服务都有一个较高的容错性,保证服务可用性,而不是导致消息丢失或者其他未知的状态。
Producer 通过重试机制和故障规避机制实现消息发送的高可用。
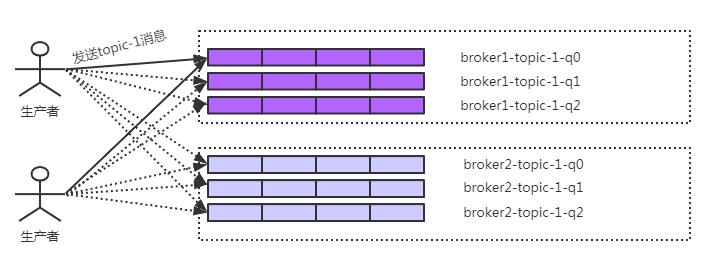
重试机制就是在发送失败时重试多次,尽可能的保障能把消息成功发出去。在创建topic时,RocketMQ默认会把topic的多个message queue创建在多个broker组上。Producer在发送消息时,默认会轮询所有queue,消息就会被发送到不同的queue上,这样当一个broker组的master不可用后,Producer仍然可以给其他组的master发送消息。
故障规避机制就是如果在消息发送过程中发现错误,那么就把这个broker加上一定的规避时间,这段时间内都不会去选择这个broker发消息,以提高发送消息的成功率。
Consumer的高可用
01
Consumer实例的高可用
Consumer作为业务系统中向消息队列发送消息的重要服务,需要集群部署,配置统一的group,一方面,可以消除单个服务因外部原因(如服务器宕机)等导致的单点故障,另一方面,各个节点之间无状态,通过设置统一的group,多个节点共同承担业务需求,实现负载均衡,一个topic的队列只能被一个Consumer实例消费,如果超过则会产生消费者无法消息,因此同一个group下Consumer实例的数量要小于等于topic中message queue的数量。
02
消息消费的高可用
实际业务场景中无法避免消费消息失败的情况,可能由于网络原因导致,或者业务逻辑错误导致、broker服务异常等。但无论发生什么情况,都需要保证消费服务的可用性,可以进行正常的消息消费。RocketMQ主要通过消费重试机制、Rebalance机制和消息ACK机制来保证。
重试-死信机制:当消息消费失败时,会被发送到重试队列,然后重试消费。当达到最大重试次数(默认为16次)还没有成功时,消息会发送到死信队列,死信队列中的消息可以后台开一个线程,再次尝试重新消费。
注:消息消费失败的场景是非常常见,笔者之前在维护应用日志系统的时候,经常遇到如消息格式异常导致消息处理失败的情况。如果没有死信队列,则需要应用系统在开发时考虑处理失败时消息的数据保存。
Rebalance机制:consumer并不能配置从master读还是slave读。当master不可用或者繁忙的时候consumer会被自动切换到从slave读。这样当master出现故障后,consumer仍然可以从slave读,保证了消息消费的高可用。
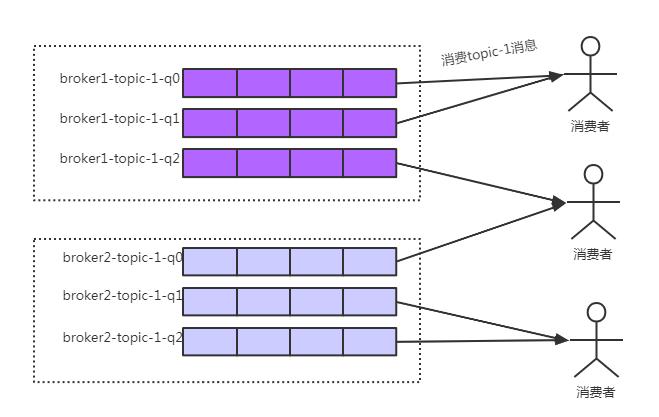
每个consumer实例平均分配每个consumer queue
通过各个服务的集群部署,保证了服务的高可用,通过存储结点的冗余备份,保证了数据的不丢失。最终部署以及使用RocketMQ的高可用架构如下:
以上就是RocketMQ高可用架构的部署方案介绍。下一讲我们将从可靠性方面来讲解使用RocketMQ如何保证顺序消息、消息绝对不丢失、避免消息重复消费等问题。
推荐阅读
以上是关于云原生技术分享 | RocketMQ的高可用架构部署攻略的主要内容,如果未能解决你的问题,请参考以下文章