5-Web安全——java反序列化机制分析
Posted songly_
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了5-Web安全——java反序列化机制分析相关的知识,希望对你有一定的参考价值。
通过上一篇的学习相信大家对java序列化机制非常熟悉了,student对象序列化后会以二进制数据存储在stu文件中,这里为了方便分析转换成十六进制显示:
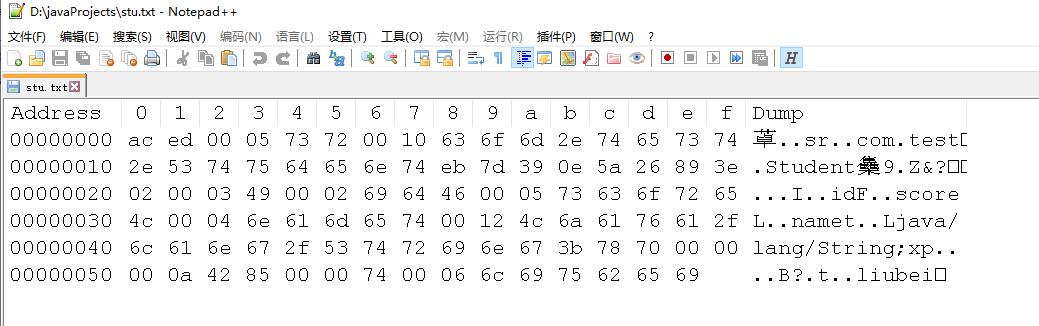
看到这段数据是不是有些眼熟,没错,开头ac ed 00 05这几个字节数据就是序列化的协议版本和魔数,现在我们再来分析java反序列化机制是如何根据二进制数据来还原java对象的。
反序列化机制主要由以下代码实现的:
ObjectInputStream objectInputStream = new ObjectInputStream(fileInputStream);
Student student = (Student) objectInputStream.readObject();不同的是,反序列化需要通过对象输入流ObjectInputStream 类从文件中读取对象序列化的状态,并根据当时对象序列化时的状态重新创建一个新对象,把原来的对象成员属性恢复回来(可以理解为原始对象的副本)。
实例化ObjectInputStream时会调用它的有参构造,进行一些反序列化的初始操作
public ObjectInputStream(InputStream in) throws IOException {
verifySubclass();
//初始化成员属性
bin = new BlockDataInputStream(in);
handles = new HandleTable(10);
vlist = new ValidationList();
serialFilter = ObjectInputFilter.Config.getSerialFilter();
enableOverride = false;
readStreamHeader();
bin.setBlockDataMode(true);
}verifySubclass方法内部通过getClass方法获取当前对象的class类型,如果是ObjectInputStream直接返回
private void verifySubclass() {
Class<?> cl = getClass();
if (cl == ObjectInputStream.class) {
//通常会在此处返回
return;
}
}ObjectInputStream构造方法内部首先调用verifySubclass方法进行一些验证,接着初始化成员属性:bin ,handles ,vlist ,serialFilter 。然后readStreamHeader方法读取魔数和序列化版本信息并进行验证,如果不匹配则抛出序列化的异常,然后setBlockDataMode方法开启Data Block模式(关于Data Block模式在上一篇已经介绍过了,这里不再赘述)。
这里解释一下ObjectInputStream的成员属性:
handler:是一个哈希表,表示从对象到引用的映射
vlist:主要用于提供一个回调(callback)操作的验证集合
bin:和bout的作用是类似的,bin也会一个“容器”,用于从缓冲区以字节流形式读取序列化数据
enableOverride:主要是判断是否重写了writeObject方法,enableOverride是一个boolean类型,true表示重写了writeObject方法
实例化ObjectInputStream后,就开始调用readObject方法反序列化
public final Object readObject() throws IOException, ClassNotFoundException {
//是否重写
if (enableOverride) {
return readObjectOverride();
}
// if nested read, passHandle contains handle of enclosing object
int outerHandle = passHandle;
try {
Object obj = readObject0(false);
handles.markDependency(outerHandle, passHandle);
ClassNotFoundException ex = handles.lookupException(passHandle);
if (ex != null) {
throw ex;
}
if (depth == 0) {
vlist.doCallbacks();
}
return obj;
} finally {
passHandle = outerHandle;
if (closed && depth == 0) {
clear();
}
}
}首先判断是否重写readObject方法,如果没有重写就调用readObject0方法,readObject0方法才是ObjectInputStream的核心方法。
readObject0方法内部实现
private Object readObject0(boolean unshared) throws IOException {
//获取读取模式
boolean oldMode = bin.getBlockDataMode();
//检查是否为Data Block模式
if (oldMode) {
//获取bin字节流缓冲区中剩余的字节数量
int remain = bin.currentBlockRemaining();
//字节数是否大于0
if (remain > 0) {
throw new OptionalDataException(remain);
//如果defaultDataEnd值为true,抛异常
} else if (defaultDataEnd) {
/*
* Fix for 4360508: stream is currently at the end of a field
* value block written via default serialization; since there
* is no terminating TC_ENDBLOCKDATA tag, simulate
* end-of-custom-data behavior explicitly.
*/
throw new OptionalDataException(true);
}
//关闭Data Block模式
bin.setBlockDataMode(false);
}
byte tc;
//是否读取到TC_RESET标记
while ((tc = bin.peekByte()) == TC_RESET) {
bin.readByte();
handleReset();
}
depth++;
totalObjectRefs++;
try { //判断TC标记
switch (tc) {
case TC_NULL:
return readNull();
case TC_REFERENCE:
return readHandle(unshared);
case TC_CLASS:
return readClass(unshared);
case TC_CLASSDESC:
case TC_PROXYCLASSDESC:
return readClassDesc(unshared);
case TC_STRING:
case TC_LONGSTRING:
return checkResolve(readString(unshared));
case TC_ARRAY:
return checkResolve(readArray(unshared));
case TC_ENUM:
return checkResolve(readEnum(unshared));
case TC_OBJECT:
return checkResolve(readOrdinaryObject(unshared));
case TC_EXCEPTION:
IOException ex = readFatalException();
throw new WriteAbortedException("writing aborted", ex);
case TC_BLOCKDATA:
case TC_BLOCKDATALONG:
if (oldMode) {
bin.setBlockDataMode(true);
bin.peek(); // force header read
throw new OptionalDataException(
bin.currentBlockRemaining());
} else {
throw new StreamCorruptedException(
"unexpected block data");
}
case TC_ENDBLOCKDATA:
if (oldMode) {
throw new OptionalDataException(true);
} else {
throw new StreamCorruptedException(
"unexpected end of block data");
}
default:
throw new StreamCorruptedException(
String.format("invalid type code: %02X", tc));
}
} finally {
depth--;
bin.setBlockDataMode(oldMode);
}
}如果是Data Block模式,计算bin剩余的字节数量,如果字节数量大于0或者defaultDataEnd值为true抛出OptionalDataException异常(可选数据块异常),OptionalDataException异常只有在使用了非法可选数据块才会抛出。虽然readObject0方法读取的对象类型数据本身就属于数据块,如果bin字节流没有使用TC_BLOCKDATA标记声明这是可选数据块,也没有使用TC_BLOCKDATALONG标记可选数据块的开始,说白了就是bin读取对象数据时,如果没有声明这是一个可选数据块,就会抛出OptionalDataException异常。
接着根据读取到的标记调用不同的方法,TC_ARRAY,TC_ENUM,TC_OBJECT,TC_STRING以及TC_LONGSTRING这几种标记会对读取的返回结果调用checkResolve方法以检查反序列化的对象中是否重写了readResolve方法,如果重写了需要执行“Resolve”流程;最后还原Data Block模式。
bin.peekByte会读取stu文件中序列化协议版本和魔数后面的数据0x73,并判断该数据是否为TC_OBJECT标记,通过前面的学习我们已经知道TC_OBJECT标记被定义在ObjectStreamConstants接口中,其值就是0x73。这里会读取到TC_OBJECT标记,调用readOrdinaryObject方法
private Object readOrdinaryObject(boolean unshared) throws IOException {
//是否读取到TC_OBJECT标记
if (bin.readByte() != TC_OBJECT) {
throw new InternalError();
}
ObjectStreamClass desc = readClassDesc(false);
desc.checkDeserialize();
Class<?> cl = desc.forClass();
if (cl == String.class || cl == Class.class
|| cl == ObjectStreamClass.class) {
throw new InvalidClassException("invalid class descriptor");
}
Object obj;
try {
obj = desc.isInstantiable() ? desc.newInstance() : null;
} catch (Exception ex) {
throw (IOException) new InvalidClassException(
desc.forClass().getName(),
"unable to create instance").initCause(ex);
}
passHandle = handles.assign(unshared ? unsharedMarker : obj);
ClassNotFoundException resolveEx = desc.getResolveException();
if (resolveEx != null) {
handles.markException(passHandle, resolveEx);
}
if (desc.isExternalizable()) {
readExternalData((Externalizable) obj, desc);
} else {
readSerialData(obj, desc);
}
handles.finish(passHandle);
if (obj != null &&
handles.lookupException(passHandle) == null &&
desc.hasReadResolveMethod())
{
Object rep = desc.invokeReadResolve(obj);
if (unshared && rep.getClass().isArray()) {
rep = cloneArray(rep);
}
if (rep != obj) {
// Filter the replacement object
if (rep != null) {
if (rep.getClass().isArray()) {
filterCheck(rep.getClass(), Array.getLength(rep));
} else {
filterCheck(rep.getClass(), -1);
}
}
handles.setObject(passHandle, obj = rep);
}
}
return obj;
}readOrdinaryObject又校验了一次TC_OBJECT标记,然后调用readClassDesc方法读取当前对象所属类的类描述信息,调用checkDeserialize方法检查当前对象是否可反序列化。
readClassDesc方法主要是根据读取到的TC标记,判断当前读取的对象属于哪一种类型,根据不同的类型调用不同的read前缀方法
private ObjectStreamClass readClassDesc(boolean unshared) throws IOException {
//这里还是读取TC标记
byte tc = bin.peekByte();
ObjectStreamClass descriptor;
switch (tc) {
case TC_NULL:
descriptor = (ObjectStreamClass) readNull();
break;
case TC_REFERENCE:
descriptor = (ObjectStreamClass) readHandle(unshared);
break;
case TC_PROXYCLASSDESC:
descriptor = readProxyDesc(unshared);
break;
case TC_CLASSDESC:
descriptor = readNonProxyDesc(unshared);
break;
default:
throw new StreamCorruptedException(
String.format("invalid type code: %02X", tc));
}
if (descriptor != null) {
validateDescriptor(descriptor);
}
return descriptor;
}readClassDesc方法内部中bin.peekByte()会继续读取stu文件后面的字节数据0x72,并判断读取到的TC标记,然后调用不同的方法。
很明显0x72显然是TC_CLASSDESC标记,接着会调用readNonProxyDesc方法
private ObjectStreamClass readNonProxyDesc(boolean unshared) throws IOException {
//是否读取到TC_CLASSDESC标记
if (bin.readByte() != TC_CLASSDESC) {
throw new InternalError();
}
ObjectStreamClass desc = new ObjectStreamClass();
//判断读取的模式是否为unshared
int descHandle = handles.assign(unshared ? unsharedMarker : desc);
passHandle = NULL_HANDLE;
ObjectStreamClass readDesc = null;
try {
readDesc = readClassDescriptor();
} catch (ClassNotFoundException ex) {
throw (IOException) new InvalidClassException(
"failed to read class descriptor").initCause(ex);
}
Class<?> cl = null;
ClassNotFoundException resolveEx = null;
bin.setBlockDataMode(true);
final boolean checksRequired = isCustomSubclass();
try {
if ((cl = resolveClass(readDesc)) == null) {
resolveEx = new ClassNotFoundException("null class");
} else if (checksRequired) {
ReflectUtil.checkPackageAccess(cl);
}
} catch (ClassNotFoundException ex) {
resolveEx = ex;
}
// Call filterCheck on the class before reading anything else
filterCheck(cl, -1);
skipCustomData();
try {
totalObjectRefs++;
depth++;
desc.initNonProxy(readDesc, cl, resolveEx, readClassDesc(false));
} finally {
depth--;
}
handles.finish(descHandle);
passHandle = descHandle;
return desc;
}readNonProxyDesc方法主要是读取当前序列化对象所属类的类描述信息,在此之前会先判断读取模式是否为unshared方式,如果是nshared方式就从unsharedMarker中读取对象。unsharedMarker主要是用于在handles对象的映射表中标记“unshared”状态的对象,因为unshared和非unshared的反序列化方式是不一样的。
接着调用readClassDescriptor方法创建一个新的ObjectStreamClass对象调用readNonProxy方法来读取序列化对象的类描述信息
protected ObjectStreamClass readClassDescriptor() throws IOException, ClassNotFoundException {
//创建新的ObjectStreamClass对象
ObjectStreamClass desc = new ObjectStreamClass();
//读取类描述信息
desc.readNonProxy(this);
return desc;
}readNonProxy方法主要是读取当前对象的类描述信息,跟进readNonProxy方法
void readNonProxy(ObjectInputStream in) throws IOException, ClassNotFoundException {
//先从字节流中读取类名信息
name = in.readUTF();
//读取类的serialVersionUID
suid = Long.valueOf(in.readLong());
isProxy = false;
//从字节流中读取SC_*标记信息,通过该标记信息设置对应的成员属性:
byte flags = in.readByte();
hasWriteObjectData = ((flags & ObjectStreamConstants.SC_WRITE_METHOD) != 0);
hasBlockExternalData = ((flags & ObjectStreamConstants.SC_BLOCK_DATA) != 0);
externalizable = ((flags & ObjectStreamConstants.SC_EXTERNALIZABLE) != 0);
boolean sflag = ((flags & ObjectStreamConstants.SC_SERIALIZABLE) != 0);
if (externalizable && sflag) {
throw new InvalidClassException(
name, "serializable and externalizable flags conflict");
}
serializable = externalizable || sflag;
isEnum = ((flags & ObjectStreamConstants.SC_ENUM) != 0);
if (isEnum && suid.longValue() != 0L) {
throw new InvalidClassException(name,
"enum descriptor has non-zero serialVersionUID: " + suid);
}
//读取成员属性的数量信息
int numFields = in.readShort();
if (isEnum && numFields != 0) {
throw new InvalidClassException(name,
"enum descriptor has non-zero field count: " + numFields);
}
//从字节流中读取字段的信息
fields = (numFields > 0) ?
new ObjectStreamField[numFields] : NO_FIELDS;
for (int i = 0; i < numFields; i++) {
//类型代码
char tcode = (char) in.readByte();
//字段名
String fname = in.readUTF();
//字段类型字符串
String signature = ((tcode == 'L') || (tcode == '[')) ? in.readTypeString() : new String(new char[] { tcode });
try {
//字段的具体信息
fields[i] = new ObjectStreamField(fname, signature, false);
} catch (RuntimeException e) {
throw (IOException) new InvalidClassException(name,
"invalid descriptor for field " + fname).initCause(e);
}
}
computeFieldOffsets();
}readNonProxy方法和ObjectOutputStream 类的writeNonProxy方法作用是类似的,不过readNonProxy函数是用于反序列化,readNonProxy方法中读取SC_*标记信息的目的是判断并校验当前对象以什么方式反序列化,由于readNonProxy方法是使用默认序列化方式对非动态代理类进行反序列化操作,从字节流中读取每一个字段的信息(TypeCode、fieldName、fieldType),如果是其他方式这里会抛异常。
我们重点来分析readNonProxy方法:
in.readUTF()会从字节流中读取类名信息:类名和类名的长度,这里会读取stu文件中的这一段数据:00 10 63 6f 6d 2e 74 65 73 74 2e 53 74 75 64 65 6e 74,前面两个字节00 10表示类名的长度,0x10转换成十进制就是16,剩下的字节数表示类名,转换为ASCII码值就是com.test.Student。
suid = Long.valueOf(in.readLong())会读取Student对象所属类的uid(如果没有自定义设置uid则jdk会自动随机生成一个uid),也就是读取stu文件中的这一段数据:e4 28 4b cd bb 76 5c 44 ,这一端数据是jdk随机生成的Student类的uid。
byte flags = in.readByte()这行代码会从stu文件中读取SC标记也就是02这段数据(readByte方法表示从in字节流中读取一个字节数据),接下来会判断是否设置了SC_WRITE_METHOD,SC_BLOCK_DATA,SC_EXTERNALIZABLE,SC_SERIALIZABLE其中任何一个标记。
这里简单介绍一下SC标记,以上4个SC标记也定义在ObjectStreamConstants接口中,该接口中定义了TC标记和SC标记
final static byte SC_WRITE_METHOD = 0x01;
final static byte SC_BLOCK_DATA = 0x08;
final static byte SC_SERIALIZABLE = 0x02;
final static byte SC_EXTERNALIZABLE = 0x04;SC_WRITE_METHOD表示当前可序列化对象是否重写了writeObject方法
SC_BLOCK_DATA表示一个可外部化的类在写入字节流数据时是否使用了STREAM_PROTOCOL_2协议
SC_SERIALIZABLE表示当前可序列化对象是否实现了Serializable接口
SC_EXTERNALIZABLE表示当前可序列化对象是否实现了Externalizable接口
因此sflag的值会设置为SC_SERIALIZABLE标记,接着会根据SC标记继续校验当前反序列化对象,如果该实现了Externalizable接口会抛出InvalidClassException异常。
接着这段代码是判断当前对象所属类是否为一个enum枚举类型,如果是枚举类型,并且suid不为0L则抛出异常
serializable = externalizable || sflag;
isEnum = ((flags & ObjectStreamConstants.SC_ENUM) != 0);
if (isEnum && suid.longValue() != 0L) {
throw new InvalidClassException(name,"enum descriptor has non-zero serialVersionUID: " + suid);
}这段代码中readShort方法会从stu文件中继续读取了00 03两个字节数据(因为readShort方法表示从in字节流中读取两个字节数据),0x03就是成员属性的数量(注意:被transient关键字修饰的成员属性不在计数范围内)。
int numFields = in.readShort();
if (isEnum && numFields != 0) {
throw new InvalidClassException(name,"enum descriptor has non-zero field count: " + numFields);
}从stu文件中读取完成员属性数量后,这里又校验了一次:判断读取到的成员属性数量是否为0,也就是意味着如果一个可序列化对象中的成员属性个数为0或者成员属性数量都被transient关键字修饰的话,那么反序列化会失败。
在这个for循环中是依次读取可序列化对象的成员属性的信息(TypeCode、fieldName、fieldType),如下所示:
for (int i = 0; i < numFields; i++) {
//类型代码
char tcode = (char) in.readByte();
//字段名
String fname = in.readUTF();
//字段类型字符串
String signature = ((tcode == 'L') || (tcode == '[')) ? in.readTypeString() : new String(new char[] { tcode });
try {
//字段的具体信息
fields[i] = new ObjectStreamField(fname, signature, false);
} catch (RuntimeException e) {
throw (IOException) new InvalidClassException(name,
"invalid descriptor for field " + fname).initCause(e);
}
}readByte方法会从stu文件中读取0x49一个字节数据,0x49转换为ASCII码值就是字符I,表示该属性的数据类型为int
readUTF方法会从stu文件中读取0x 64 69两个字节数据(注意:readUTF读取的字节数是可变长,不固定的),0x 64 69转换为字符就是成员属性id
ObjectStreamField对象一般用于描述一个可序列化对象中的成员属性定义的信息,以及在字节流中字段的各种信息(包括TypeCode、fieldName、fieldType),这里调用了ObjectStreamField的有参构造,定义如下:
ObjectStreamField(String name, String signature, boolean unshared);name表示字段名,signature表示字段类型,最后一个参数表示写入的方式,false表示非unshared方式(前面已经介绍过了)。
到这,反序列化的核心方法readNonProxy已经分析完毕。
分析完readNonProxy方法,再回到readNonProxyDesc方法中,分析后面的代码:
} catch (ClassNotFoundException ex) {
throw (IOException) new InvalidClassException(
"failed to read class descriptor").initCause(ex);
}
Class<?> cl = null;
ClassNotFoundException resolveEx = null;
bin.setBlockDataMode(true);
final boolean checksRequired = isCustomSubclass();
try {
//调用resolveClass处理当前类信息
if ((cl = resolveClass(readDesc)) == null) {
resolveEx = new ClassNotFoundException("null class");
} else if (checksRequired) {
ReflectUtil.checkPackageAccess(cl);
}
} catch (ClassNotFoundException ex) {
resolveEx = ex;
}
//校验是否执行反序列化
filterCheck(cl, -1);
//调用skipCustomData方法跳过自定义信息的读取
skipCustomData();
try {
totalObjectRefs++;
depth++;
desc.initNonProxy(readDesc, cl, resolveEx, readClassDesc(false));
} finally {
depth--;
}
//调用handles的finish方法完成引用Handle的赋值操作
handles.finish(descHandle);
//将结果赋值给passHandle成员属性
passHandle = descHandle;
return desc;
}首先开启Data Block模式(bin.setBlockDataMode(true)),调用resolveClass方法处理当前类的信息,接着调用filterCheck方法判断反序列化过滤器判断是否执行反序列化,最后将得到的类描述信息返回给descriptor变量。
resolveClass是ObjectInputStream类的成员方法,内部实现如下
protected Class<?> resolveClass(ObjectStreamClass desc) throws IOException, ClassNotFoundException {
String name = desc.getName();
try {
return Class.forName(name, false, latestUserDefinedLoader());
} catch (ClassNotFoundException ex) {
Class<?> cl = primClasses.get(name);
if (cl != null) {
return cl;
} else {
throw ex;
}
}
}resolveClass方法的作用是根据字节流中读取的类描述信息,通过Class.forName方式来加载本地类,如果子类继承ObjectInputStream类重写了resolveClass方法就可能变换读取源(默认实现是从字节流中读取),子类可以在resolveClass方法中自定义行为。resolveClass方法在字节流中对每一个类的类描述信息只会调用一次,和ObjectOutputStream类的annotateClass方法有些类似。
readNonProxyDesc方法最后将得到的类描述信息返回给descriptor变量,validateDescriptor方法的验证后将descriptor作为结果返回给readOrdinaryObject方法
readOrdinaryObject方法拿到当前对象的类描述信息返回readObject0方法,又接着调用了checkResolve方法
checkResolve方法内部实现
private Object checkResolve(Object obj) throws IOException {
//是否重写了readResolve方法
if (!enableResolve || handles.lookupException(passHandle) != null) {
//没有重写直接返回
return obj;
}
Object rep = resolveObject(obj);
if (rep != obj) {
// The type of the original object has been filtered but resolveObject
// may have replaced it; filter the replacement's type
if (rep != null) {
if (rep.getClass().isArray()) {
filterCheck(rep.getClass(), Array.getLength(rep));
} else {
filterCheck(rep.getClass(), -1);
}
}
handles.setObject(passHandle, rep);
}
return rep;
}checkResolve方法主要是检查反序列化的对象中是否重写了readResolve方法,如果重写了需要执行“Resolve”流程,如果没有重写则直接返回对象信息,通常这里会直接返回obj到readObject方法。
checkResolve方法在返回之前会执行finally语句的代码,执行depth是为了返回到readObject方法中执行回调(doCallbacks),以结束反序列化流程。

继续分析readObject方法

调用vlist成员的doCallbacks来执行完成过后的回调逻辑,到这反序列化操作基本执行完毕。
参考资料
本文参考了panda师傅的反序列化流程分析:https://www.cnpanda.net/sec/928.html
以上是关于5-Web安全——java反序列化机制分析的主要内容,如果未能解决你的问题,请参考以下文章