你所不知道的 Transformer!
Posted 红色石头Will
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了你所不知道的 Transformer!相关的知识,希望对你有一定的参考价值。

作者 | 台运鹏
这是 Transformer 系列第一篇!
参考论文:https://arxiv.org/abs/1706.03762
章节
Reasons
Self-Attention
Multi-Head Attention
Positional Encoding
Add & Norm
Feed Forward
Residual Dropout
Encoder To Decoder
Shared Weights
Effect
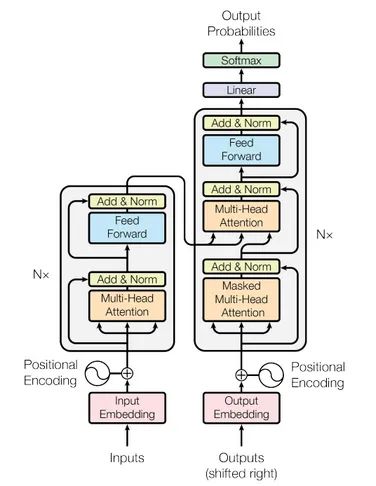
Reasons For Transformer
新模型的产生往往是为了旧模型的问题所设计的。那么,原始模型的问题有哪些呢?
1、无法并行运算
在transformer之前,大部分应该都是RNN,下面简单介绍一下RNN
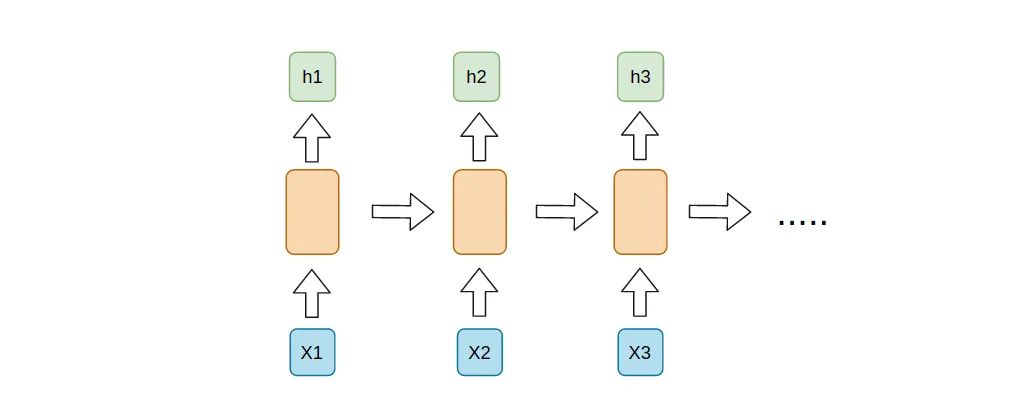
可以看出,在计算X2加进去吐出来的值的时候必须要先把X1得出的参数值与X2放在一起才行。换句话说,RNN的计算是必须一个接一个,并不存在并行运算。如果不能并行运算,那么时间和计算成本均会增加。
2、语义表述不清
传统的word2vec通过将词语转换为坐标形式,并且根据距离之远近决定两个词意思的相近程度。 但是在NLP任务中,尽管是同一个词语,但在不同语境下代表的意思很有可能不同。例如,你今天方便的时候,来我家吃饭吧和我肚子不舒服,去厕所方便一下这两句中方便的意思肯定不一样。可是,word2vec处理之后坐标形式就固定了。
3、突出对待
在一个句子中,当我们需要强调某一个部分的时候,word2vec无法为我们做到这些。比如,
The cat doesn't eat the cake because it is not hungry.
The cat doesn't eat the cake because it smells bad.
第一个句子中it强调的是the cat,在第二个句子中it强调的是the cake。
4、长距离信息缺失
尽管RNN处理序列问题很拿手,但如果一个句子很长,那么我要一直把句首的信息携带到句尾,距离越长,信息缺失的可能性就会变大。
Self-Attention
attention的意思是我们给有意义的内容配以较高的权重,那么自己与自己做attention是什么意思?
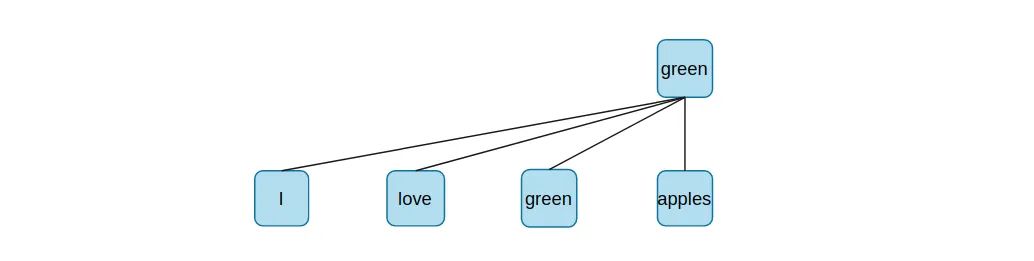
比如这个句中的"green",self的意思就是说拿这个词与整个句子其他的词语分别算相似程度。如此便考虑了词与上下文和句子整体之间的关系。当然,自己与自己肯定是联系最紧密。我们的目的是让机器能够判定出某个词语与整个句子之间的关系。
那么,如何计算self-attenion呢?
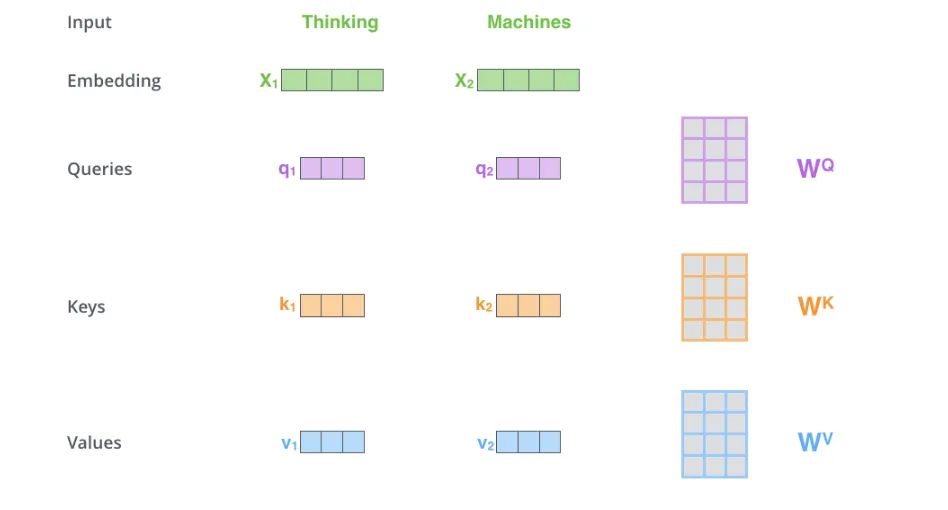
首先将词编码成向量,总不大可能直接将词输进去。其次定义三个矩阵, 这三个矩阵分别代表了Query,Key,Value,分别代表去查询的,被查询的以及实际的特征信息。W的意思是权重的意思,可以类比于梯度下降,权重一般都是初始化一个参数,然后通过训练得出。最后用词向量与矩阵分别做点积即可得到q1,q2,k1,k2,v1,v2。
用q1,q2分别与k1,k2的转置做点积,q代表的要查的,而k是被查的。如此便可得到两者的关系了。
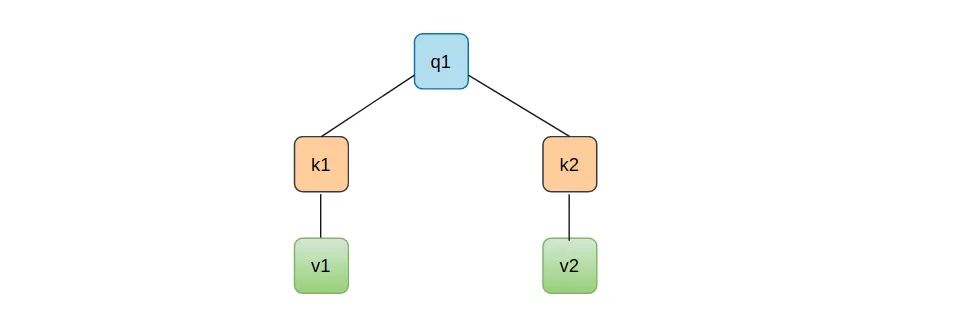
注意力一共分为additive attention和这里提到的dot product attention,那么为什么偏要用后者而非前者呢?
因为内积在实际中可以用高度优化矩阵运算,所以更快,同时空间利用率也很好。在此,简要解释一下内积可以表示两向量关系的原因,在坐标系中,当两个向量垂直时,其关系最小,为0。其实就是cos为0。假如a1,a2两个向量很接近,那么,它们之间的夹角会很小,可知cos就很大,代表联系就越紧密。
在K的维度很小的时候,两种注意力机制几乎一致,但是当K的维度上升之后,发现内积效果开始变差。其实,可以联系一下Softmax图像,当值变得很大的时候,梯度变化量几乎很难观察到,又被称为梯度消失问题,这是为什么做scale的第一个原因。
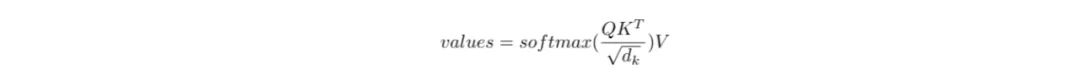
在论文中提到

两者做点积之后还需要除以矩阵K的维度开根号,Q,K,V矩阵维度是q x d_k,p x d_k,p x d_v,softmax是沿着p维进行的,但是很多时候大方差会导致数值分布不均匀,经过softmax之后就会大的愈大,小的愈小,这里除以一个矩阵K的维度其实类似于一个归一化,让它的方差趋向于1,分布均匀一点,这是第二个原因,所以在原paper里面又叫做Scaled Dot-Product Attention。
那为什么除以一个矩阵K的维度开根号能使方差变为1呢?首先对于随机分布的q,k,方差均为1,期望均为0。我们把特定的一个q_i,k_i看成X,Y。
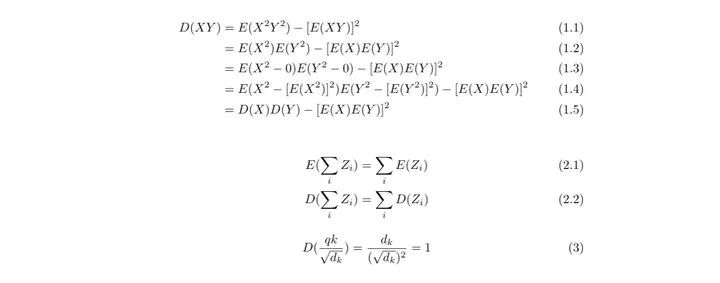
那么q与k做点积之后的结果均值为0,方差为d_k。方差太大不稳定,所以除以矩阵K的维度开根号,参照链接(https://www.zhihu.com/question/339723385) 。
例如 v = 0.36v1 + 0.64v2,v1,v2是矩阵V里的。
既然都是矩阵运算,那么都是可以并行加速的。
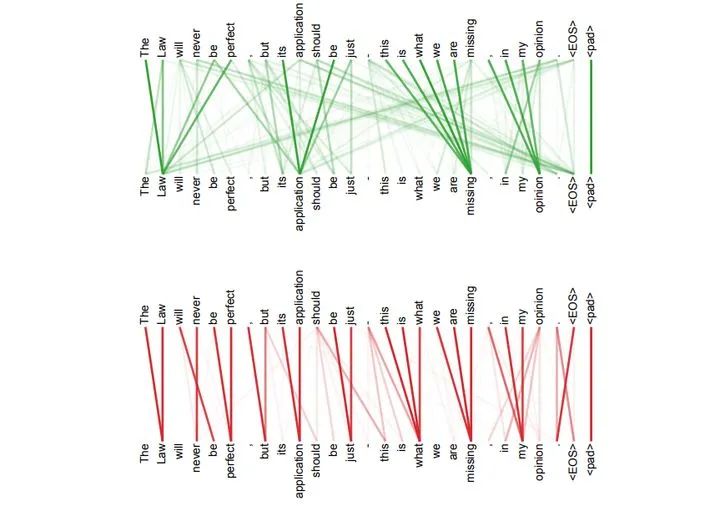
self-attention除了可以捕获到句子语法特征外,还可以在长序列中捕获各个部分的依赖关系,而同样的处理用RNN和LSTM需要进行按照次序运算,迭代几次之后才有可能得到信息,而且距离越远,可能捕获到的可能性就越小。而self-attention极大程度上缩小了距离,更有利于利用特征。
Multi-head Attention
理解了自注意力,那么什么是多头注意力呢?
类比一下CNN,当我们不断提取特征的时候会用到一个叫卷积核的东西(filter),我们为了最大化提取有效特征,通常选择一组卷积核来提取,因为不同的卷积核对图片的不同区域的注意力不同。比如,我们要识别一张鸟的图片,可能第一个卷积核更关注鸟嘴,第二个卷积核更关注鸟翅膀等等。
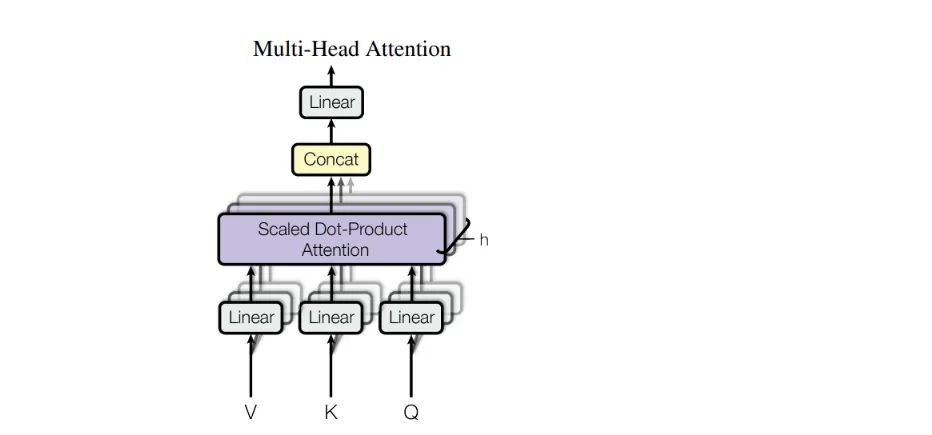
在Transformer中也是如此,不同的Q,K,V矩阵得出的特征关系也不相同,同样,不一定一组Q,K,V提取到的关系能解决问题,所以保险起见,我们用多组。这里可以把一组Q,K,V矩阵类比为一个卷积核,最后再通过全连接层进行拼接降维。
Positional Encoding
为什么要进行位置编码呢?
我上面阐述的注意力机制是不是只说了某个词与它所处的句子之间的关系,但是在实际自然语言处理中,只知道这个词与句子的关系而不知道它在哪个位置是不行的。
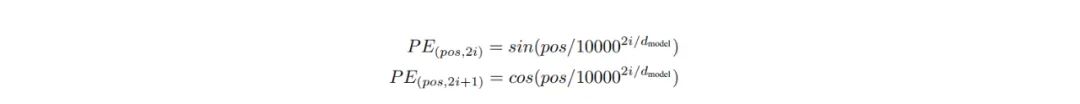
在这篇论文中,用到了正余弦函数,pos代表的是位置,i是位置编码的维度,d_model是输入的维度,因为位置编码要和输入加在一起,所以两者维度一致。那么,为什么用正余弦呢?原论文中说对于一个已知的PE_pos,对于一个确定的k,PE_pos+k都可以被表示为PE_pos的线性组合。
那么,既然有了公式,那位置编码是算出来的还是学出来的呢?其实算出来和学出来的效果差不多,但是考虑到算出来的可以接受更长的序列长度而不必受训练的干扰,所以在这个模型中,位置编码是通过公式算出来的。
Add & Norm
Add 的意思是残差相连,思路来源于论文Deep residual learning for image recognition(https://openaccess.thecvf.com/content_cvpr_2016/html/He_Deep_Residual_Learning_CVPR_2016_paper.html),Norm指的是Layer Normalization,来源于论文Layer normalization(https://arxiv.org/abs/1607.06450)。
论文中指出
That is, the output of each sub-layer is LayerNorm(x + Sublayer(x)), where Sublayer(x) is the function implemented by the sub-layer itself
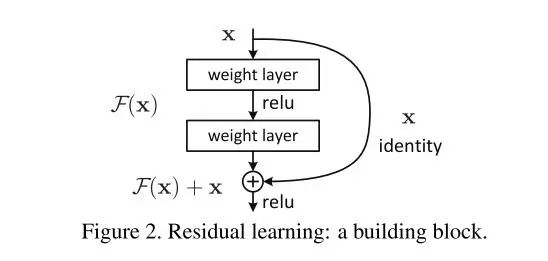
意思是上一层的输入和输出结果相拼接,然后进行归一化,这样可以更加稳定。肯定会有读者好奇为什么不直接将输出结果归一化,偏要把输入结果拼接到输出结果然后再归一化。
如果还有读者不明白Backprogation,建议看BP,这里简要说明一下,求后向传播的过程中,设残差相连之后输入的层为L层,那么,肯定要求这一层对残差相连的时候的偏导数,而这时x是作为自变量的,所以对于F(x)+ x,求偏导后x就会变为1,那么无论什么时候都会加上这个常数1,这样会一定程度上缓解梯度消失这个问题。
这里选取的是层归一化(Layer Normalization),用CNN举例,假如我们的输入是 ,分别代表样本数量(每一个神经元对应着一个样本),通道数,高度和宽度,那么LN就是对于单独的每一个样本做归一化,计算 个值的均值和标准差然后应用到这个样本里面。归一化的公式如下:
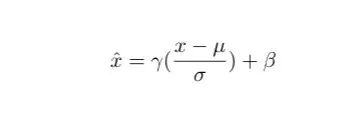
Feed Forward
Feed-Forward Network究竟做了啥呢?
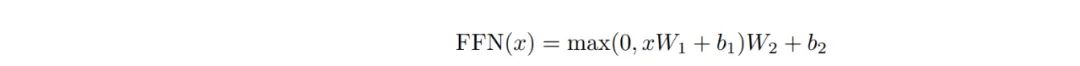
首先它会引入RELU进行非线性变化,也就是公式前半部分所为,而且经过这一层之后会被升维,之后把这一层的结果连接到下一层进行线性变化,同时进行降维,保证输入输出维度一致。
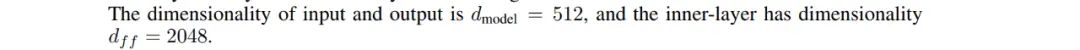
Residual Dropout
在此模型中还在输入,输出层和位置编码拼接中采用了dropout,这里的比例是0.1。
Encoder To Decoder
接下来要把左侧的编码器和右侧的解码器进行相连,细心观察图会发现只有两个箭头到了右边,这两个箭头代表的是K,V矩阵,Q矩阵由右侧解码器提供。
另外,解码器会MASK掉序列的某些部分,因为如果要判断机器是否真正理解了整段句子的意思,可以把后面遮掉,它如果猜的出来,那么说明机器理解了。具体来说,对于位置i,通常会将i+1后面的全都MASK掉,这样机器就是从前面学到的,它没有提前看到后面的结果。
其他结构与编码器一致,最后再进行线性变化,最终用softmax映射成概率。
Shared Weights
我们需要把输入和输出转换为向量表示,而向量表示的方法是提前学到的。此外,最后用的线性转换以及softmax都是学出来的。和常规的序列模型一致,输入输出以及线性转换用的权重矩阵是共享的,只不过在输入输出层用的时候乘以模型维度开根号。
Effect

一般来说,维度d肯定比序列长度n大很多,所以每一层的复杂度此模型吊打RNN。模型结果对比没多说的,几乎是碾压式的。
推荐阅读
(点击标题可跳转阅读)
重磅!
AI有道年度技术文章电子版PDF来啦!

扫描下方二维码,添加 AI有道小助手微信,可申请入群,并获得2020完整技术文章合集PDF(一定要备注:入群 + 地点 + 学校/公司。例如:入群+上海+复旦。

长按扫码,申请入群
(添加人数较多,请耐心等待)
感谢你的分享,点赞,在看三连 
以上是关于你所不知道的 Transformer!的主要内容,如果未能解决你的问题,请参考以下文章