中间件面试专题:kafka高频面试问题
Posted Java极客思维
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了中间件面试专题:kafka高频面试问题相关的知识,希望对你有一定的参考价值。
开篇介绍
![]()
Q:
什么是消息和批次?
消息,Kafka里的数据单元,也就是我们一般消息中间件里的消息的概念。消息由字节数组组成。消息还可以包含键,用以对消息选取分区。
为了提高效率,消息被分批写入Kafka。
批次,就是一组消息,这些消息属于同一个主题和分区。如果只传递单个消息,会导致大量的网络开销,把消息分成批次传输可以减少这开销。但是,这个需要权衡,批次里包含的消息越多,单位时间内处理的消息就越多,单个消息的传输时间就越长。如果进行压缩,可以提升数据的传输和存储能力,但需要更多的计算处理。
Q:
什么是主题和分区?
Kafka的消息用主题进行分类,主题下可以被分为若干个分区。分区本质上是个提交日志,有新消息,这个消息就会以追加的方式写入分区,然后用先入先出的顺序读取。
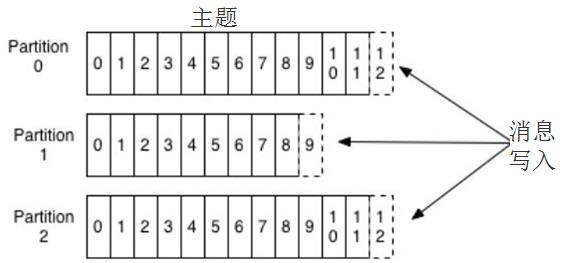
但是因为主题会有多个分区,所以在整个主题的范围内,是无法保证消息的顺序的,单个分区则可以保证。
Kafka通过分区来实现数据冗余和伸缩性,因为分区可以分布在不同的服务器上,那就是说一个主题可以跨越多个服务器。
前面我们说Kafka可以看成一个流平台,很多时候,我们会把一个主题的数据看成一个流,不管有多少个分区。
Q:
Kafka中的ISR、AR代表什么?ISR的伸缩指的什么?
ISR :In-Sync Replicas 副本同步队列
AR :Assigned Replicas 所有副本
ISR是由leader维护,follower从leader同步数据有一些延迟(包括 延迟时间replica.lag.time.max.ms 和 延迟条数replica.lag.max.message 两个维度,当前最新的版本0.10.x中只支持 replica.lag.time.max.ms 这个维度),任意一个超过阈值都会把follower剔除出ISR,存入OSR(Outof-Sync Replicas)列表,新加入的follower也会先存放在OSR中。
注:AR = ISR + OSR
Q:
Broker 和 集群
一个独立的Kafka服务器叫Broker。broker的主要工作是,接收生产者的消息,设置偏移量,提交消息到磁盘保存;为消费者提供服务,响应请求,返回消息。在合适的硬件上,单个broker可以处理上千个分区和每秒百万级的消息量。
多个broker可以组成一个集群。每个集群中broker会选举出一个集群控制器。控制器会进行管理,包括将分区分配给broker和监控broker。
集群里,一个分区从属于一个broker,这个broker被称为首领。但是分区可以被分配给多个broker,这个时候会发生分区复制。
分区复制带来的好处是,提供了消息冗余。一旦首领broker失效,其他broker可以接管领导权。当然相关的消费者和生产者都要重新连接到新的首领上。
Q:
kafka中的zookeeper起到什么作用?
zookeeper是一个分布式的协调组件,早期版本的kafaka用zk做 meta信息存储 , consumer的消费状态 , group的管理 以及 offset 的值。
考虑到zk本身的一些因素以及整个架构较大概率存在单点问题,新版本中逐渐弱化了zookeeper的作用。新的consumer使用了kafka内部的 group coordination 协议,也减少了对zookeeper的依赖。
Q:
kafka follower如何与leader数据同步?
kafka的复制机制既不是完全的同步复制,也不是单纯的异步复制。
完全同步复制要求 All Alive Follower 都复制完,这条消息才会被认为commit,这种复制方式极大的影响了吞吐率。
一步复制方式下,Follower异步的从Leader复制数据,数据只要被Leader写入log就被认为已经commit,这种情况下,如果leader挂掉,会丢失数据;
kafka使用 ISR 的方式很好的均衡了确保数据不丢失以及吞吐率。Follower可以批量的从Leader复制数据,而且Leader充分利用磁盘顺序读以及 send file(zero copy) 机制,这样极大的提高复制性能,内部批量写磁盘,大幅减少了Follower与Leader的消息量差。
Q:
kafka中的消息是否会丢失和重复消费?
消息发送:
kafka消息发送有两种方式:同步(sync)和异步(async);
默认是同步方式,可通过 producer.type 属性进行配置;
kafka通过配置 request.required.acks 属性来确认消息的生产。
0:表示不进行消息接收是否成功的确认;
1:表示当Leader接收成功时确认;
-1:表示Leader和Follower都接收成功时确认;
综上所述,有6种消息产生的情况,消息丢失的场景有:
acks=0,不和kafka集群进行消息接收确认,则当网络异常、缓冲区满了等情况时,消息可能丢失;
acks=1、同步模式下,只有Leader确认接收成功后但挂掉了,副本没有同步,数据可能丢失;
消息消费:
kafka消息消费有两个consumer接口, Low-level API 和 High-level API :
Low-level API:消费者自己维护offset等值,可以实现对kafka的完全控制;
High-level API:封装了对parition 和 offset 的管理,使用简单;
如果使用高级接口High-level API,可能存在一个问题就是当消息消费者从集群中把消息取出来,并提交了新的消息offset值后,还没来得及消费就挂掉了,那么下次再消费时之前没消费成功的消息就"诡异"的消失了;
解决方案:
1 针对消息丢失:同步模式下,确认机制设置为-1,即让消息写入Leader 和 Follower之后再确认消息发送成功;异步模式下,为防止缓冲区满,可以在配置文件设置不限制阻塞超时时间,当缓冲区满时让生产者一直处于阻塞状态。
2 针对消息重复:将消息的唯一标识保存到外部介质中,每次消费时判断是否处理过即可。
Q:
kafka为什么不支持读写分离?
在kafka中,生产者写入消息、消费者读取消息的操作都是与Leader副本进行交互的,从而实现的是一种主写主读的生产消费模型。
kafka并不支持主写从读,因为主写从读有2个很明显的缺点:
数据一致性问题:数据从主节点转到从节点必然会有一个延时的时间窗口,这个时间窗口会导致主从节点之间的数据不一致。某一时刻,在主节点和从节点中A数据的值都为X,之后将主节点中A的值修改为Y,那么在这个变更通知到从节点之前,应用读取从节点中的A数据的值并不为最新的Y值,由此便产生了数据不一致的问题。
延时问题:类似Redis这种组件,数据从写入主节点到同步至从节点的过程中需要经历 网络→主节点内存→网络→从节点内存 这几个阶段,整个过程会耗费一定的时间。而在kafka中,主从同步会比Redis更加耗时,它需要经历 网络→主节点内存→主节点磁盘→网络→从节点内存→从节点磁盘 这几个阶段。对延时敏感的应用而言,主写从读的功能场景并不太适用。
明天,会介绍Spring相关面试题,长按二维码关注我吧~
祝大家都能拿到心仪的offer!
Java极客思维
以上是关于中间件面试专题:kafka高频面试问题的主要内容,如果未能解决你的问题,请参考以下文章