如何选择最佳存储解决方案
Posted 程序员石磊
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了如何选择最佳存储解决方案相关的知识,希望对你有一定的参考价值。
在构建系统时要进行设计考虑和权衡。
1.介绍
要选择正确的存储解决方案,需要以下考虑。
关键因素
- 数据结构
- 查询模式
- 您需要处理的数量或规模
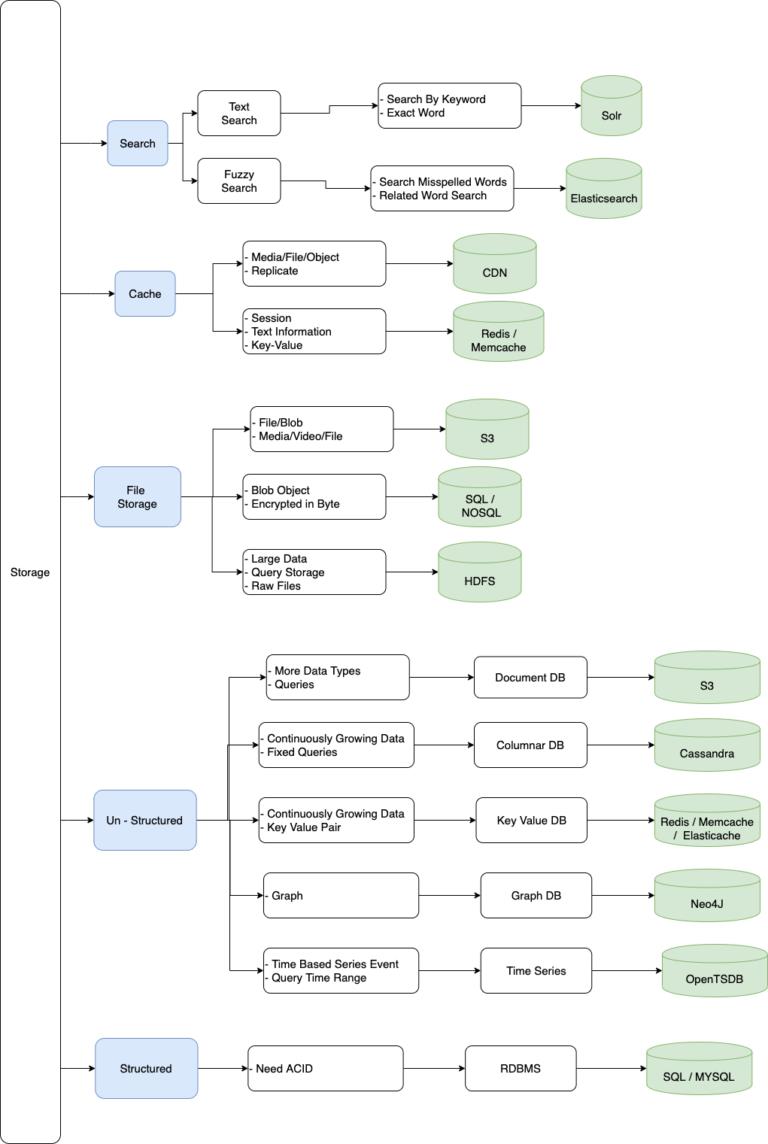
2.缓存解决方案
- 如果您经常调用数据库或远程调用具有高延迟的独立服务,则可能需要[缓存](https://interviewdaemon.com/courses/design-concepts-a-to-z/lessons / caching /)您本地的一些数据。
- 一些关键值缓存存储解决方案是Memcached,Hazelcast,Redis等
- 大多数使用Redis,Memcache和Elasticache。
3.文件存储解决方案
- 文件存储用作图像,视频等的数据存储。
- 数据库旨在存储可以查询的信息,而您不需要查询的文件,只需按原样提供它们即可。这是当我们使用称为Blob存储的东西时。
- Amazon S3主要用于Blob存储
4.CDN
- 通常,blob存储与[内容交付网络](https://interviewdaemon.com/courses/design-concepts-a-to-z/lessons/content-distribution-network-cdn/)或[CDN](https://interviewdaemon.com/courses/design-concepts-a-to-z/lessons/content-distribution-network-cdn/)。
- CDN是遍布全球的服务器网络,可在不同地理位置提供内容并减少延迟。
- 如果您要从中获取内容的服务器离您的地理位置更近,则将以更快的方式将内容传递给您。
5.文本搜索功能
5.1.文本搜索
- 假设您要构建搜索功能,用户可以在其中按电影,流派,演员,女演员,导演等进行搜索。
- 在这里,您可以使用诸如Solr之类的搜索引擎
- 它建立在Apache Lucene之上
5.2.模糊搜索
- 如果您在搜索中搜索拼写错误/不正确的单词,并且搜索结果中包含正确的单词结果,则称为模糊搜索。
- 搜索引擎存储临时数据或索引数据,并且不保证长期数据,因此搜索存储不用作主存储。
- 例如,如果我们输入“ intraviw”,它将根据“面试”进行搜索
- 我们可以从主数据库中将数据加载到它们,以减少搜索延迟并提供基于模糊和相关性的文本搜索。
- 可以支持模糊搜索的Elasticsearch。
- 它也是基于Apache Lucene构建的
6.时间系列数据库
- 假设我们正在尝试建立度量跟踪系统,或者在任何基于时间的数据库中我们都需要一个时间序列数据库。
- 与标准关系数据库不同,时间序列数据库永远不会被随机更新。
- 大部分会依序追加。
- 相对于随机读取,在特定时间范围内会有更多的批量读取。在过去1周,10天,1个月,1年等时间内,有多少人观看了编解码器视频。
- 时间序列数据库的一些示例是OpenTSDB,InfluxDB等。
- 我们还可以使用任何非关系时间序列数据库。
7.分析和数据仓库
- 我们需要一个大型数据库来转储可供我们使用的所有数据,以执行分析。
- 主要用于离线报告,而非事务性
- 存储所有数据,以便他们可以执行分析。
- HDFS通常用于存储海量数据
- Hadoop和Spark是非常常用的数据仓库和处理。
8.SQL与NoSQL
8.1.SQL
- 结构取决于我们用来确定将使用哪种类型的因素
- 如果您需要[ACID](https://interviewdaemon.com/courses/design-concepts-a-to-z/lessons/acid-vs-base-property/)属性,则需要使用关系DBMS。
- 一些示例是mysql,Oracle,Postgres等
- 付款系统主要需要交易和原子性。
- [强一致性](https://interviewdaemon.com/courses/design-concepts-a-to-z/lessons/database-consistency/)主要可以通过SQL数据库来实现。
8.2.NoSQL
- 假设您正在尝试为诸如Amazon之类的商品建立目录,您想在其中存储有关具有各种属性的不同产品的信息。
- 例如,不同产品的这些属性通常不同。药品将有有效期,但冰箱将具有能量等级。
- 在这种情况下,我们的数据不能表示为表格。这意味着我们需要使用NoSQL数据库。
- 如果您需要[BASE](https://interviewdaemon.com/courses/design-concepts-a-to-z/lessons/acid-vs-base-property/)属性,则可以使用非关系数据库前进。
- 对于[最终一致性](https://interviewdaemon.com/courses/design-concepts-a-to-z/lessons/database-consistency/),我们可以使用NoSQL数据库
- 最常见的NoSQL DB是MongoDB,Cassandra,DynamoDB
8.2.1.基于文档(基于查询的数据)
- 如果我们拥有大量数据-不仅是数量,而且还有各种各样的属性-并且我们需要运行各种各样的查询,则需要使用一种称为Document DB的东西。
- 使用文档数据库,随机查询或其他查询最有效
- Couchbase或MongoDB是一些常用的文档数据库
8.2.2.图形存储
- 这些类型的数据库使数据可视化更加容易。
- 它们非常善于在节点的帮助下存储不同数据点之间的关系。
- 图形存储可能不是最可扩展的数据库。
- 但是,它们在防止欺诈等使用案例方面效率很高。
- 图形数据库的常见示例是Neo4j 和 JanusGraph。
8.2.3.Key-value 存储
- 这些都是非常简单的数据库管理系统,存储关键值对。
- 最终目标是快速获取基本数据。
- 这些类型的数据库的常见用例是排行榜和购物车数据。
- redis是流行的key value 存储。
8.2.4.柱状数据库(不断增加的数据)
- 有限的查询种类,但是数据库的大小持续快速增加。例如订单,目录
- 现在,Uber司机的数量将逐日增加,即每天收集的数据也会逐日增加。这成为越来越多的数据。
- 在这种情况下,我们使用诸如Cassandra或HBase之类的列式数据库。
9.不同数据库的组合
示例:Amazon.com
- 对于一个我们只有一件库存产品,但有多个用户试图购买它的产品,它应该只卖给一个用户,这意味着我们在这里需要ACID。因此,一个明显的选择应该是像MySQL这样的关系数据库。
- 与亚马逊产品相关的数据将会不断增加,并且会有各种各样的属性。我们应该使用像Cassandra这样的Columnar NoSQL数据库。。
- 我们可以在MySQL数据库中存储尚未交付的订单数据,一旦订单完成,我们可以将其移到Cassandra永久存储。。
- 用于报告系统有多少人购买了一个特定的项目。因此,报告不能针对单个产品,而应该针对产品的子集,这些产品可以在Cassandra或MySQL中。这样的需求就是我们最好的选择是像Mongo DB这样的文档DB的一个例子。
- 假设您想要查看上个月有多少人买了糖,您可以从Mongo DB获取订单id,并使用此订单id从Cassandra或MySQL获取其余数据。
资料来源:https://www.codekarle.com/system-design/Database-system-design.html
https://towardsdatascience.com/choosing-the-right-database-in-a-system-design-interview-b8af9c6dc525
以上是关于如何选择最佳存储解决方案的主要内容,如果未能解决你的问题,请参考以下文章