linux性能优化内核线程CPU利用率高分析
Posted sysu_lluozh
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了linux性能优化内核线程CPU利用率高分析相关的知识,希望对你有一定的参考价值。
在排查网络问题时经常碰到的一个问题,就是内核线程的CPU使用率很高
比如,在高并发的场景中内核线程ksoftirqd的CPU使用率通常就会比较高,根据CPU和网络模块知识可以得知,这是网络收发的软中断导致的
而要分析ksoftirqd这类CPU使用率比较高的内核线程,一般需要借助于其他性能工具进行辅助分析
接下来以ksoftirqd为例,看看如何分析内核线程的性能问题
一、内核线程
既然要讲内核线程的性能问题,在开始之前先看看有哪些常见的内核线程
在Linux中,用户态进程的"祖先"都是PID号为1的init进程。比如Linux中init都是systemd进程,而其他的用户态进程会通过systemd来进行管理
稍微想一下Linux 中的各种进程,除了用户态进程外还有大量的内核态线程
按说内核态的线程应该先于用户态进程启动,可是systemd只管理用户态进程。那么,内核态线程又是谁来管理的呢?
1.1 三个特殊的进程
实际上,Linux 在启动过程中有三个特殊的进程,也就是 PID 号最小的三个进程:
- 0号进程
idle进程,这也是系统创建的第一个进程,它在初始化1号和2号进程后演变为空闲任务,当CPU上没有其他任务执行时就会运行它
- 1号进程
init进程,通常是systemd进程,在用户态运行,用来管理其他用户态进程
- 2号进程
kthreadd进程,在内核态运行,用来管理内核线程
所以,要查找内核线程只需要从2号进程开始,查找它的子孙进程即可
1.2 内核进程查找
比如,可以使用ps命令来查找kthreadd的子进程:
$ ps ‑f ‑‑ppid 2 ‑p 2
UID PID PPID C STIME TTY TIME CMD
root 2 0 0 12:02 ? 00:00:01 [kthreadd]
root 9 2 0 12:02 ? 00:00:21 [ksoftirqd/0]
root 10 2 0 12:02 ? 00:11:47 [rcu_sched]
root 11 2 0 12:02 ? 00:00:18 [migration/0]
...
root 11094 2 0 14:20 ? 00:00:00 [kworker/1:0‑eve]
root 11647 2 0 14:27 ? 00:00:00 [kworker/0:2‑cgr]
从上面的输出,可以看到内核线程的名称(CMD)都在中括号里,所以,更简单的方法就是直接查找名称包含中括号的进程。比如:
$ ps ‑ef | grep "\\[.*\\]"
root 2 0 0 08:14 ? 00:00:00 [kthreadd]
root 3 2 0 08:14 ? 00:00:00 [rcu_gp]
root 4 2 0 08:14 ? 00:00:00 [rcu_par_gp]
...
1.3 几个内核线程
了解内核线程的基本功能,对排查问题有非常大的帮助
比如,在前面案例中提到过ksoftirqd它是一个用来处理软中断的内核线程,并且每个CPU上都有一个
如果知道这点,那么,以后遇到ksoftirqd的CPU使用高的情况,就会首先怀疑是软中断的问题,然后从软中断的角度来进一步分析
其实,除了kthreadd和ksoftirqd外,还有很多常见的内核线程在性能分析中都经常会碰到,比如下面这几个内核线程:
- kswapd0
用于内存回收
- kworker
用于执行内核工作队列,分为绑定CPU(名称格式为kworker/CPU86330)和未绑定CPU(名称格式为kworker/uPOOL86330)两类
- migration
在负载均衡过程中把进程迁移到CPU上,每个CPU都有一个migration内核线程
- jbd2/sda1-8
jbd是Journaling Block Device的缩写,用来为文件系统提供日志功能,以保证数据的完整性
sda1-8表示磁盘分区名称和设备号,每个使用了ext4文件系统的磁盘分区都会有一个jbd2内核线程
- pdflush
用于将内存中的脏页(被修改过,但还未写入磁盘的文件页)写入磁盘
了解这几个容易发生性能问题的内核线程,有助于更快地定位性能瓶颈
接下来看看今天的案例
二、案例准备
本次案例用到两台虚拟机,它们的关系如下:
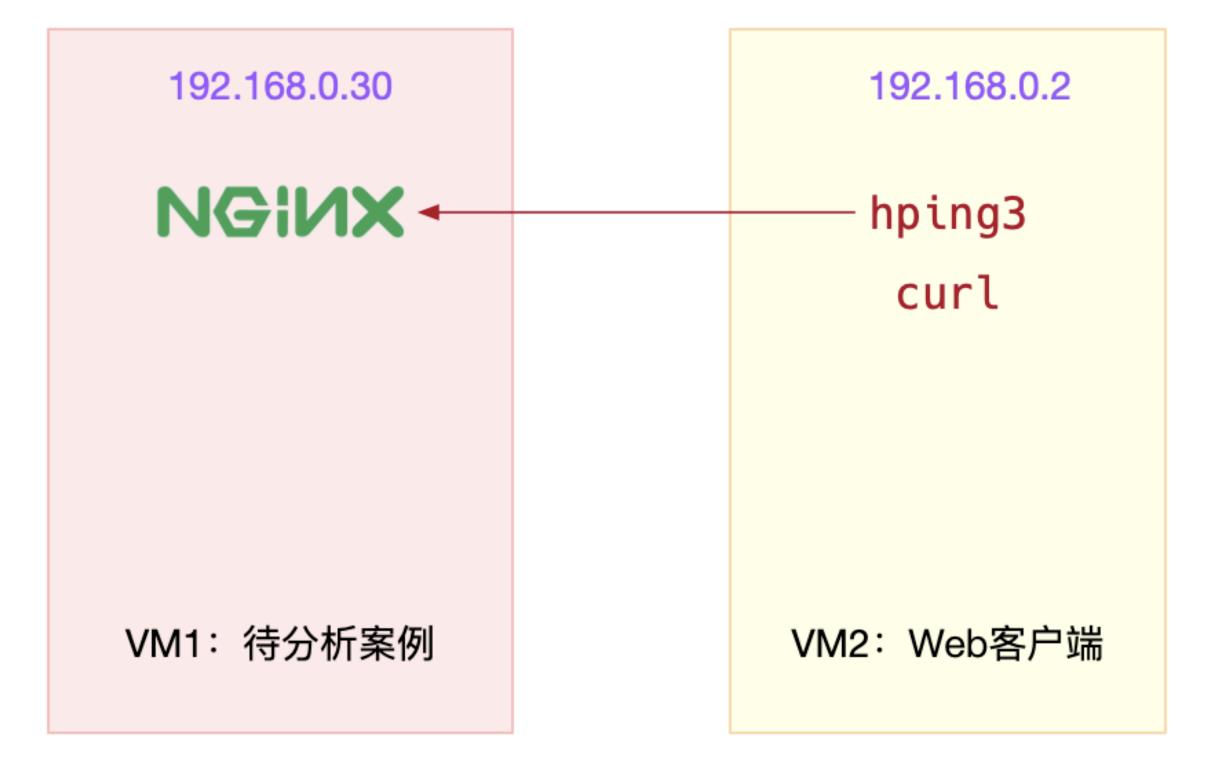
在第一个终端启动最基本的nginx应用,执行下面的命令:
# 运行Nginx服务并对外开放80端口
$ docker run ‑itd ‑‑name=nginx ‑p 80:80 nginx
在第二个终端,使用curl访问Nginx监听的端口,确认Nginx正常启动,运行curl命令后如果Nginx服务启动成功那么可以看到下面这个输出界面:
$ curl http://192.168.0.30/
<!DOCTYPE html>
<html>
<head>
<title>Welcome to nginx!</title>
...
三、案例分析
是在第二个终端中,运行hping3命令模拟Nginx的客户端请求:
# ‑S参数表示设置TCP协议的SYN(同步序列号),‑p表示目的端口为80
# ‑i u10表示每隔10微秒发送一个网络帧
# 注:如果你在实践过程中现象不明显,可以尝试把10调小,比如调成5甚至1
$ hping3 ‑S ‑p 80 ‑i u10 192.168.0.30
再回到第一个终端,发现系统的响应明显变慢
不妨执行top观察系统和进程的CPU使用情况:
$ top
top ‑ 08:31:43 up 17 min, 1 user, load average: 0.00, 0.00, 0.02
Tasks: 128 total, 1 running, 69 sleeping, 0 stopped, 0 zombie
%Cpu0 : 0.3 us, 0.3 sy, 0.0 ni, 66.8 id, 0.3 wa, 0.0 hi, 32.4 si, 0.0 st
%Cpu1 : 0.0 us, 0.3 sy, 0.0 ni, 65.2 id, 0.0 wa, 0.0 hi, 34.5 si, 0.0 st
KiB Mem : 8167040 total, 7234236 free, 358976 used, 573828 buff/cache
KiB Swap: 0 total, 0 free, 0 used. 7560460 avail Mem
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
9 root 20 0 0 0 0 S 7.0 0.0 0:00.48 ksoftirqd/0
18 root 20 0 0 0 0 S 6.9 0.0 0:00.56 ksoftirqd/1
2489 root 20 0 876896 38408 21520 S 0.3 0.5 0:01.50 docker‑containe
3008 root 20 0 44536 3936 3304 R 0.3 0.0 0:00.09 top
1 root 20 0 78116 9000 6432 S 0.0 0.1 0:11.77 systemd
...
从top的输出中可以看到,两个CPU的软中断使用率都超过30%,而CPU使用率最高的进程正好是软中断内核线程ksoftirqd/0和ksoftirqd/1
已经知道ksoftirqd的基本功能,可以猜测是因为大量网络收发引起CPU使用率升高,但它到底在执行什么逻辑却并不知道
3.1 pstack内核进程
对于普通进程,要观察其行为有很多方法,比如strace、pstack、lsof等等,但这些工具并不适合内核线程,比如,如果使用pstack或者通过/proc/pid/stack查看ksoftirqd/0(进程号为9)的调用栈时,分别可以得到以下输出:
$ pstack 9
Could not attach to target 9: Operation not permitted.
detach: No such process
pstack 报出的是不允许挂载进程的错误
$ cat /proc/9/stack
[<0>] smpboot_thread_fn+0x166/0x170
[<0>] kthread+0x121/0x140
[<0>] ret_from_fork+0x35/0x40
[<0>] 0xffffffffffffffff
/proc/9/stack方式虽然有输出,但输出中并没有详细的调用栈情况
3.2 perf内核线程
那还有没有其他方法观察内核线程ksoftirqd的行为呢?
既然是内核线程,自然应该用到内核中提供的机制,CPU性能工具中的perf,是内核自带的性能剖析工具
perf对指定的进程或者事件进行采样,并且还可以用调用栈的形式输出整个调用链上的汇总信息
不妨使用perf试着分析一下进程号为9的ksoftirqd
在终端一执行下面的perf record命令,并指定进程号9以便记录ksoftirqd的行为:
# 采样30s后退出
$ perf record ‑a ‑g ‑p 9 ‑‑ sleep 30
在上述命令结束后,继续执行perf report命令可以得到perf的汇总报告,按上下方向键以及回车键展开比例最高的ksoftirqd就可以得到下面这个调用关系链图:
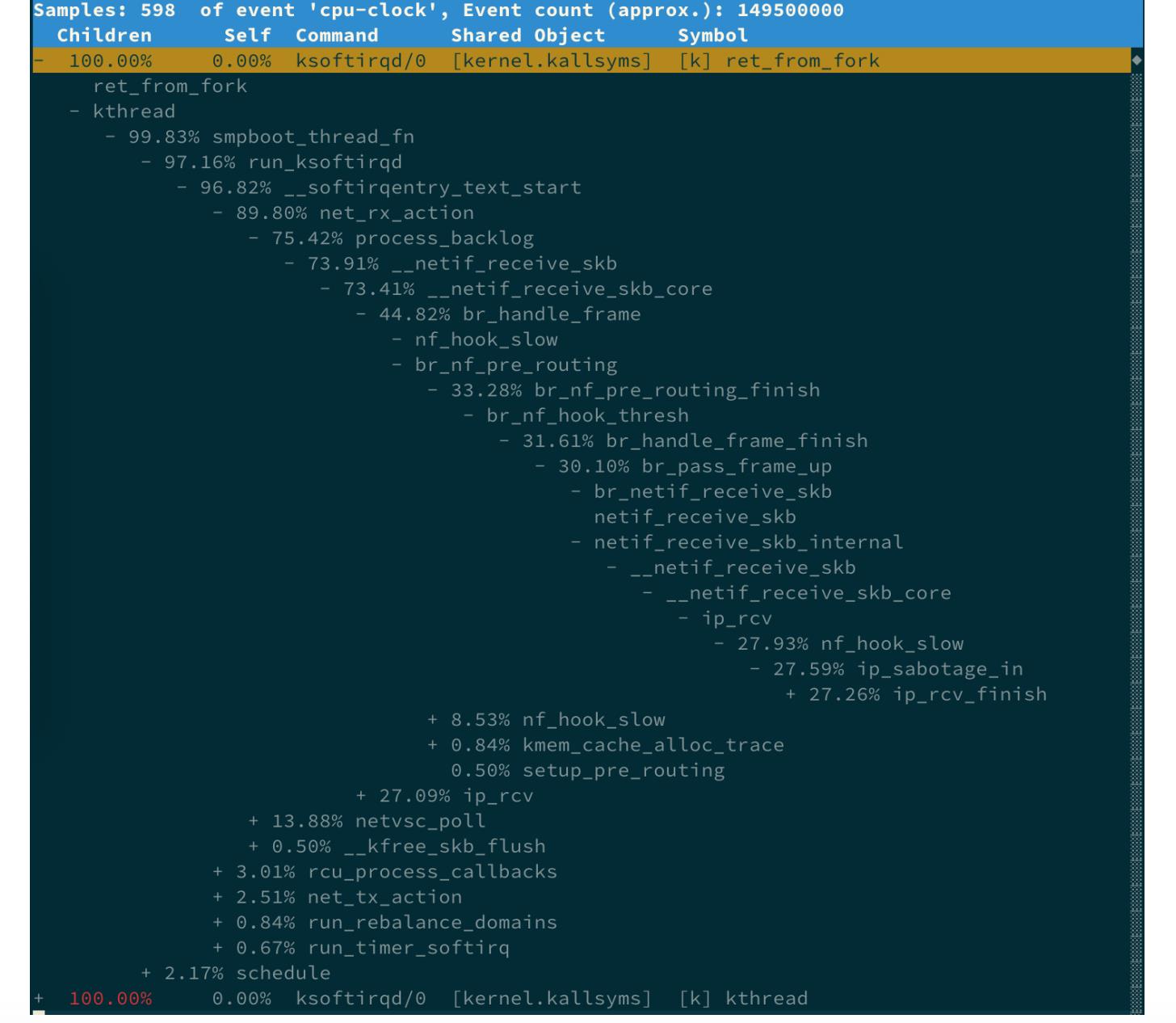
从这个图中,可以清楚看到ksoftirqd执行最多的调用过程。通过这些函数,可以大致看出它的调用栈过程:
- net_rx_action和netif_receive_skb
表明这是接收网络包(rx 表示 receive) - br_handle_frame
表明网络包经过了网桥(br表示 bridge) - br_nf_pre_routing
表明在网桥上执行了netfilter的PREROUTING(nf表示netfilter)
PREROUTING主要用来执行DNAT,可以猜测这里有DNAT发生 - br_pass_frame_up
表明网桥处理后再交给桥接的其他桥接网卡进一步处理
比如,在新的网卡上接收网络包、执行netfilter过滤规则等等
3.3 docket容器网络
那猜测的对不对呢?实际上,最开始用Docker启动了容器,而Docker会自动为容器创建虚拟网卡、桥接到docker0网桥并配置NAT规则。这一过程如下图所示:
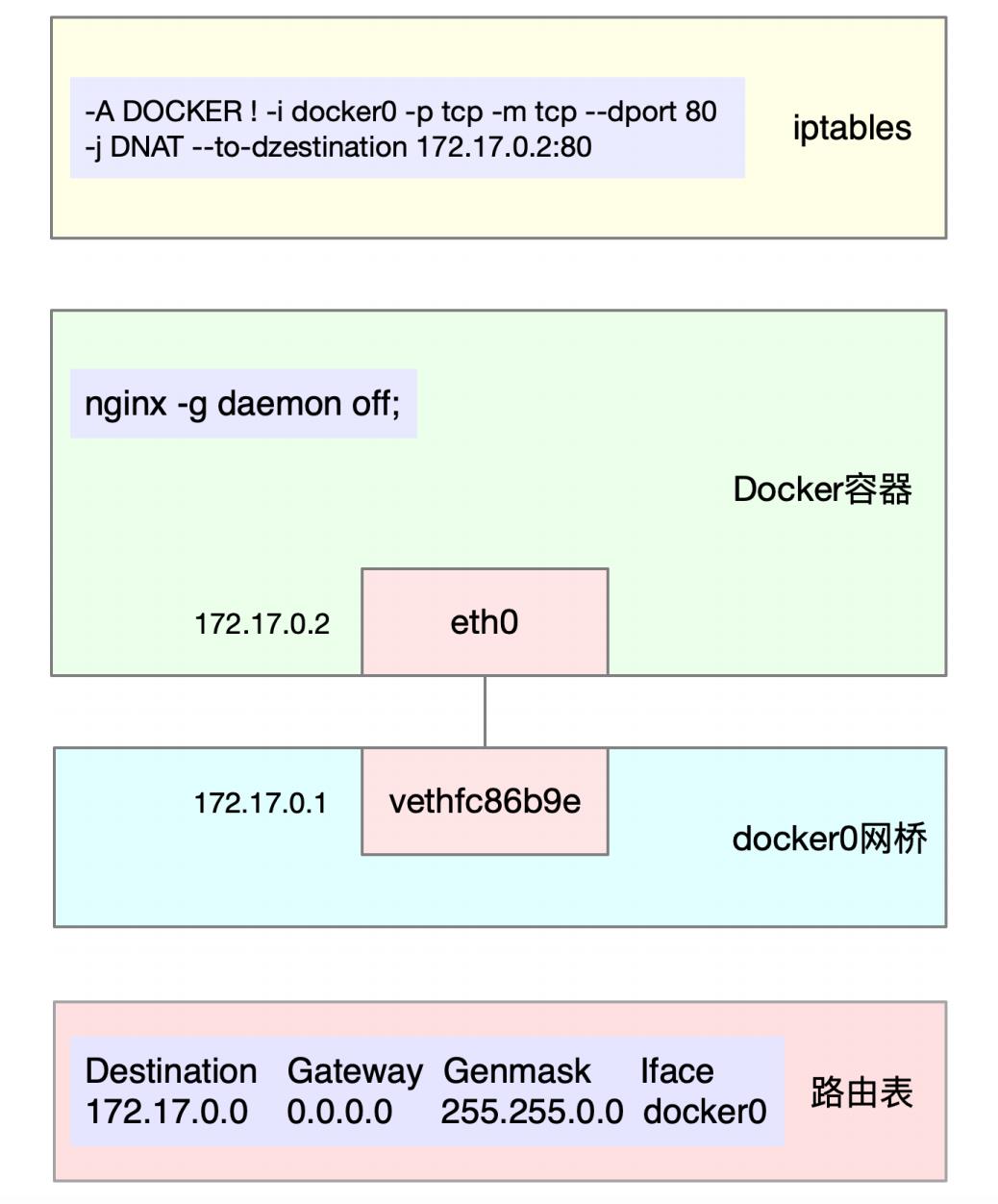
当然了,perf report界面的调用链还可以继续展开,但如果展开更多的层级时,最后几个层级会超出屏幕范围。这样,即使能看到大部分的调用过程,却也不能说明后面层级就没问题
那么,有没有更好的方法来查看整个调用栈的信息呢?
3.4 火焰图示例
针对perf汇总数据的展示问题,通过矢量图的形式更直观展示汇总结果。下图就是一个针对 mysql的火焰图示例
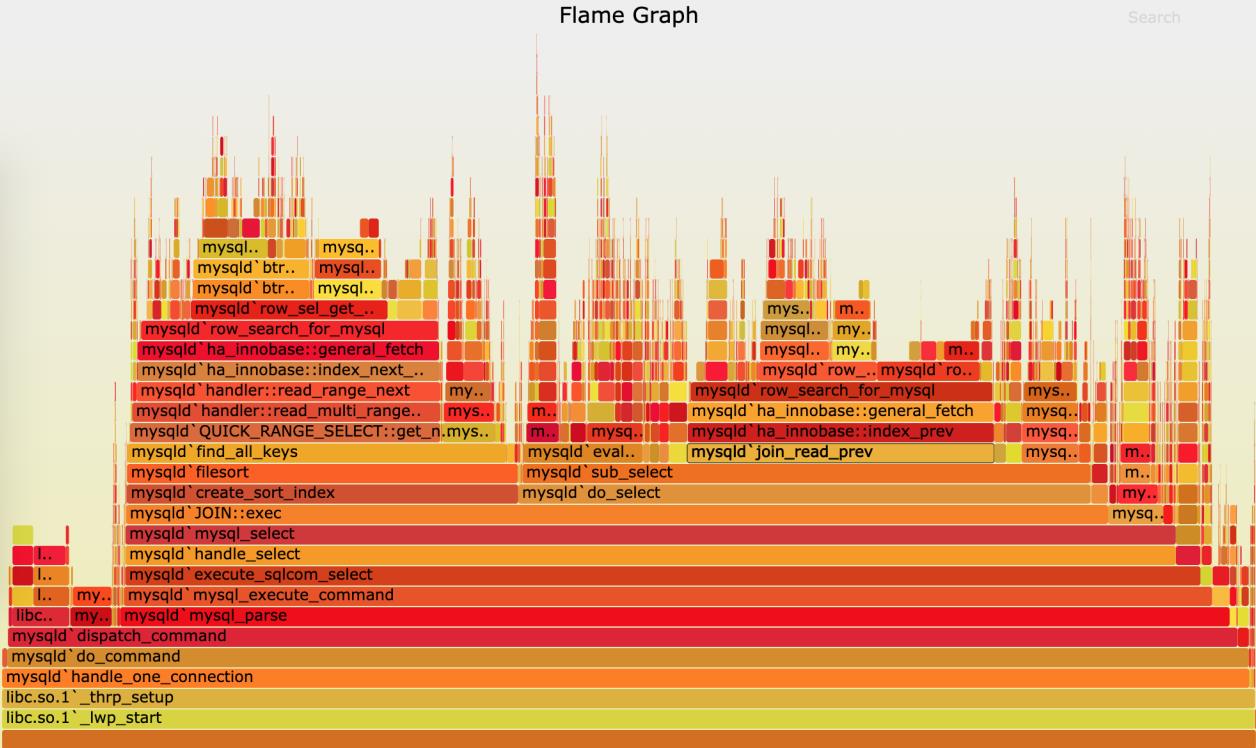
这张图看起来像是跳动的火焰,因此也就被称为火焰图。要理解火焰图最重要的是区分清楚横轴和纵轴的含义
- 横轴表示采样数和采样比例
一个函数占用的横轴越宽,就代表它的执行时间越长。同一层的多个函数,则是按照字母来排序
- 纵轴表示调用栈
由下往上根据调用关系逐个展开。换句话说,上下相邻的两个函数中,下面的函数是上面函数的父函数。这样,调用栈越深,纵轴就越高
注:图中的颜色并没有特殊含义,只是用来区分不同的函数
火焰图是动态的矢量图格式,所以它还支持一些动态特性
比如,鼠标悬停到某个函数上时就会自动显示这个函数的采样数和采样比例。而当用鼠标点击函数时,火焰图就会把该层及其上的各层放大,方便观察这些处于火焰图顶部的调用栈的细节
3.5 火焰图类型
上面mysql火焰图的示例,表示了CPU的繁忙情况,这种火焰图也被称为on-CPU火焰图
如果根据性能分析的目标来划分,火焰图可以分为下面这几种:
- on-CPU火焰图
表示CPU的繁忙情况,用在CPU使用率比较高的场景中
- off-CPU 火焰图
表示CPU等待 I/O、锁等各种资源的阻塞情况
- 内存火焰图
表示内存的分配和释放情况
- 热/冷火焰图
表示将on-CPU和off-CPU结合在一起综合展示
- 差分火焰图
表示两个火焰图的差分情况,红色表示增长,蓝色表示衰减
差分火焰图常用来比较不同场景和不同时期的火焰图,以便分析系统变化前后对性能的影响情况
3.6 问题分析总结
不过,回想一下网络收发的流程可能会觉得它缺了好多步骤
比如,这个堆栈中并没有TCP相关的调用,也没有连接跟踪conntrack相关的函数
实际上,这些流程都在其他更小的火焰中,可以点击上图左上角的"Reset Zoom"回到完整火焰图中,再去查看其他小火焰的堆栈
所以,在理解这个调用栈时要注意,从任何一个点出发、纵向来看的整个调用栈,其实只是最顶端那一个函数的调用堆栈,而非完整的内核网络执行流程
另外,整个火焰图不包含任何时间的因素,所以并不能看出横向各个函数的执行次序
到这里,找出了内核线程ksoftirqd执行最频繁的函数调用堆栈,而这个堆栈中的各层级函数就是潜在的性能瓶颈来源。这样,接下来想要进一步分析和优化时也就有了根据
以上是关于linux性能优化内核线程CPU利用率高分析的主要内容,如果未能解决你的问题,请参考以下文章