linux性能优化系统监控的综合思路
Posted sysu_lluozh
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了linux性能优化系统监控的综合思路相关的知识,希望对你有一定的参考价值。
在实际的性能分析中,一个很常见的现象是明明发生了性能瓶颈,但当登录到服务器中想要排 查的时候,却发现瓶颈已经消失了。或者说,性能问题总是时不时地发生,但却很难找出发生规律,也很难重现
当面对这样的场景时,可能会发现掌握的各种工具、方法都"失效"了。为什么呢?因为它们都需要在性能问题发生的时刻才有效,而在这些事后分析的场景中就很难发挥它们的威力
一、核心监控指标
要解决这个问题就要搭建监控系统,把系统和应用程序的运行状况监控起来,并定义一系列的策略,在发生问题时第一时间告警通知
一个好的监控系统,不仅可以实时暴露系统的各种问题,更可以根据这些监控到的状态,自动分析和定位大致的瓶颈来源,从而更精确地把问题汇报给相关团队处理
要做好监控,最核心的就是全面的、可量化的指标,这包括系统和应用两个方面
- 从系统来说
监控系统要涵盖系统的整体资源使用情况,比如CPU、内存、 磁盘和文件系统、网络等各种系统资源
- 从应用程序来说
监控系统要涵盖应用程序内部的运行状态,这既包括进程的CPU、磁盘I/O等整体运行状况,更需要包括诸如接口调用耗时、执行过程中的错误、内部对象的内存使用等应用程序内部的运行状况
如何对Linux系统进行监控,接下来将继续讲解应用程序监控的思路
二、USE法
在开始监控系统之前,肯定最想知道怎么才能用简洁的方法,来描述系统资源的使用情况
当然可以使用各种性能工具,来分别收集各种资源的使用情况
不过不要忘记每种资源的性能指标可都有很多,使用过多指标本身耗时耗力不说,也不容易建立起系统整体的运行状况
在这里,可以使用一种专门用于性能监控的USE(Utilization Saturation and Errors)法
2.1 USER法类别
USE法把系统资源的性能指标,简化成了三个类别,即使用率、饱和度以及错误数
- 使用率
表示资源用于服务的时间或容量百分比
100%的使用率,表示容量已经用尽或者全部时间都用于服务
- 饱和度
表示资源的繁忙程度,通常与等待队列的长度相关
100%的饱和度,表示资源无法接受更多的请求
- 错误数
表示发生错误的事件个数
错误数越多,表明系统的问题越严重
2.2 资源性能指标
这三个类别的指标,涵盖了系统资源的常见性能瓶颈,所以常被用来快速定位系统资源的性能瓶颈
这样,无论是对CPU、内存、磁盘和文件系统、网络等硬件资源,还是对文件描述符数、连接数、连接跟踪数等软件资源,USE方法都可以帮你快速定位出是哪一种系统资源出现了性能瓶颈
那么,对于每一种系统资源又有哪些常见的性能指标呢?根据各种系统资源原理并不难想到相关的性能指标。把常见的性能指标画了一张表格如下:
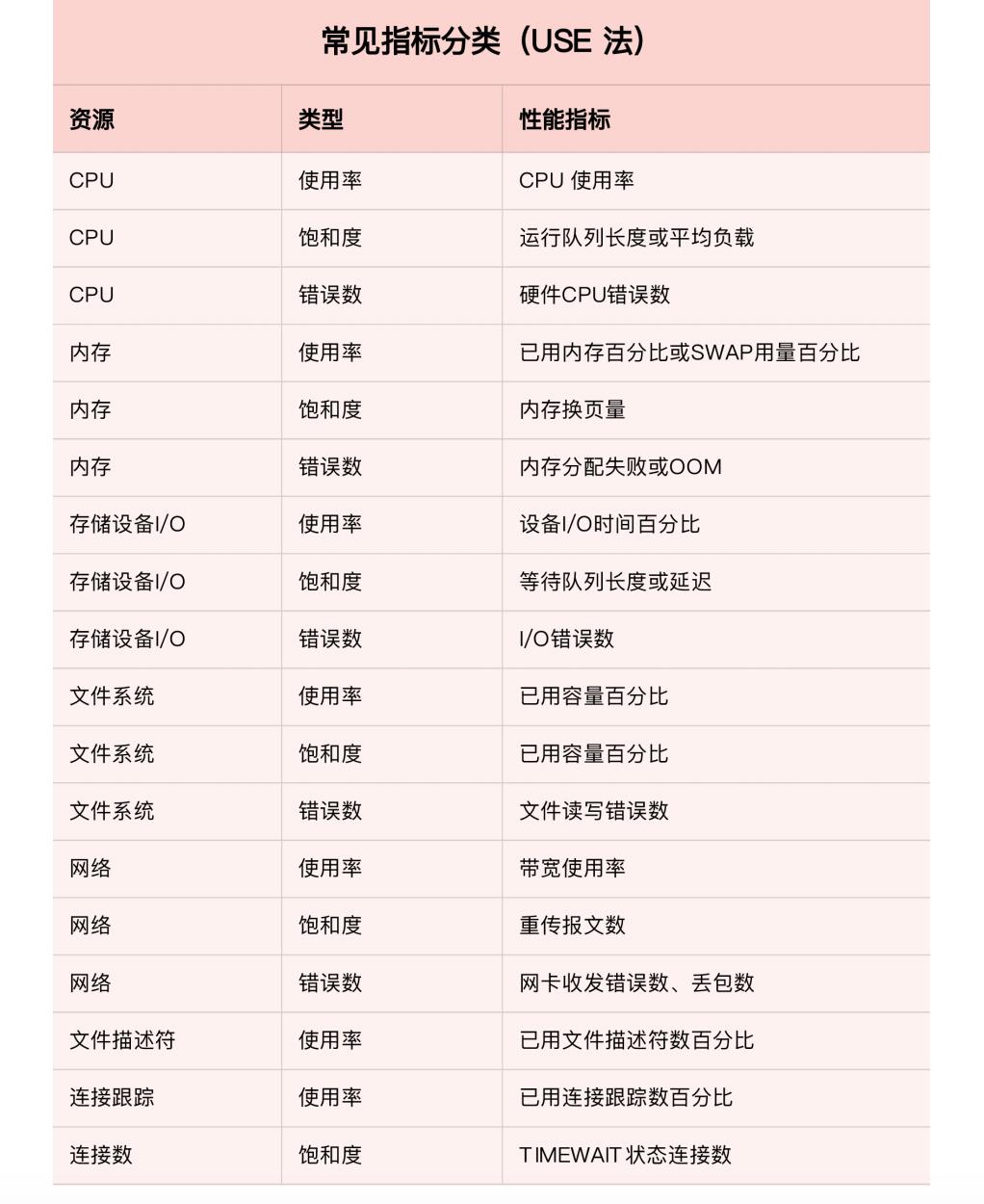
不过,需要注意的是,USE方法只关注能体现系统资源性能瓶颈的核心指标,但这并不是说其他指标不重要
诸如系统日志、进程资源使用量、缓存使用量等其他各类指标,也都需要监控起来。只不过,它们通常用作辅助性能分析,而USE方法的指标则直接表明了系统的资源瓶颈
三、监控系统
3.1 监控系统内容
掌握USE方法以及需要监控的性能指标后,接下来要做的就是:
- 首先,建立监控系统,把这些指标保存下来
- 然后,根据这些监控到的状态,自动分析和定位大致的瓶颈来源
- 最后,再通过告警系统,把问题及时汇报给相关团队处理
可以看出,一个完整的监控系统通常由数据采集、数据存储、数据查询和处理、告警以及可
视化展示等多个模块组成。所以,要从头搭建一个监控系统其实也是一个很大的系统工程
不过,幸运的是,现在已经有很多开源的监控工具可以直接使用,比如最常见的Zabbix、 Nagios、Prometheus等等
3.2 Prometheus基本原理
以Prometheus为例介绍这几个组件的基本原理,Prometheus的基本架构如下图所示:
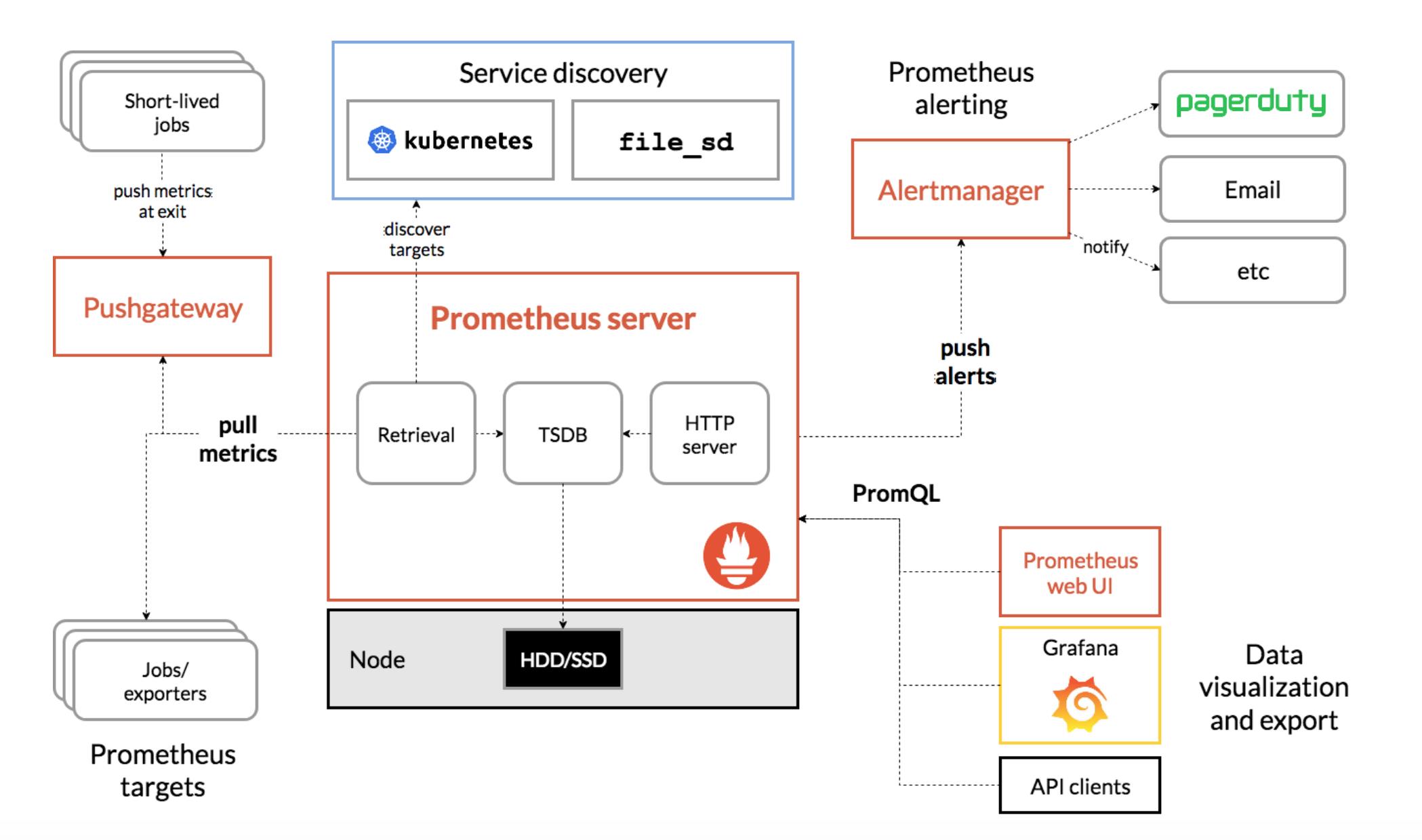
3.2.1 数据采集模块
先看数据采集模块
最左边的Prometheus targets就是数据采集的对象,而Retrieval则负责采集这些数据
从图中可以看到,Prometheus同时支持Push和Pull两种数据采集模式
- Pull模式
由服务器端的采集模块来触发采集
只要采集目标提供了HTTP接口,就可以自由接入(这也是最常用的采集模式)
- Push模式
由各个采集目标主动向Push Gateway(用于防止数据丢失)推送指标,再由服务器端从Gateway中拉取过去(这是移动应用中最常用的采集模式)
由于需要监控的对象通常都是动态变化的,Prometheus还提供了服务发现的机制,可以自动根据预配置的规则动态发现需要监控的对象。这在Kubernetes等容器平台中非常有效
3.2.2 数据存储模块
第二个是数据存储模块
为了保持监控数据的持久化,图中的TSDB(Time series database)模块,负责将采集到的数据持久化到SSD等磁盘设备中
TSDB是专门为时间序列数据设计的一种数据库,特点是以时间为索引、数据量大并且以追加的方式写入
3.2.3 数据查询和处理模块
第三个是数据查询和处理模块
刚才提到的TSDB,在存储数据的同时,其实还提供了数据查询和基本的数据处理功能,而这也就是PromQL语言
PromQL提供了简洁的查询、过滤功能,并且支持基本的数据处理方法,是告警系统和可视化展示的基础
3.2.4 告警模块
第四个是告警模块
右上角的AlertManager提供了告警的功能,包括基于PromQL语言的触发条件、告警规则的配置管理以及告警的发送等
不过,虽然告警是必要的,但过于频繁的告警显然也不可取。所以,AlertManager还支持通过分组、抑制或者静默等多种方式来聚合同类告警,并减少告警数量
3.2.5 可视化展示模块
最后一个是可视化展示模块
Prometheus的web UI提供了简单的可视化界面,用于执行PromQL查询语句,但结果的展示比较单调。不过,一旦配合 Grafana就可以构建非常强大的图形界面
四、组件结合
针对以上的组件,对每个模块都有了比较清晰的认识。接下来,继续深入了解这些组件结合起来的整体功能
比如,以刚才提到的USE方法为例,使用Prometheus可以收集Linux服务器的CPU、内存、磁盘、网络等各类资源的使用率、饱和度和错误数指标。然后,通过Grafana以及PromQL查询语句,就可以把它们以图形界面的方式直观展示出来
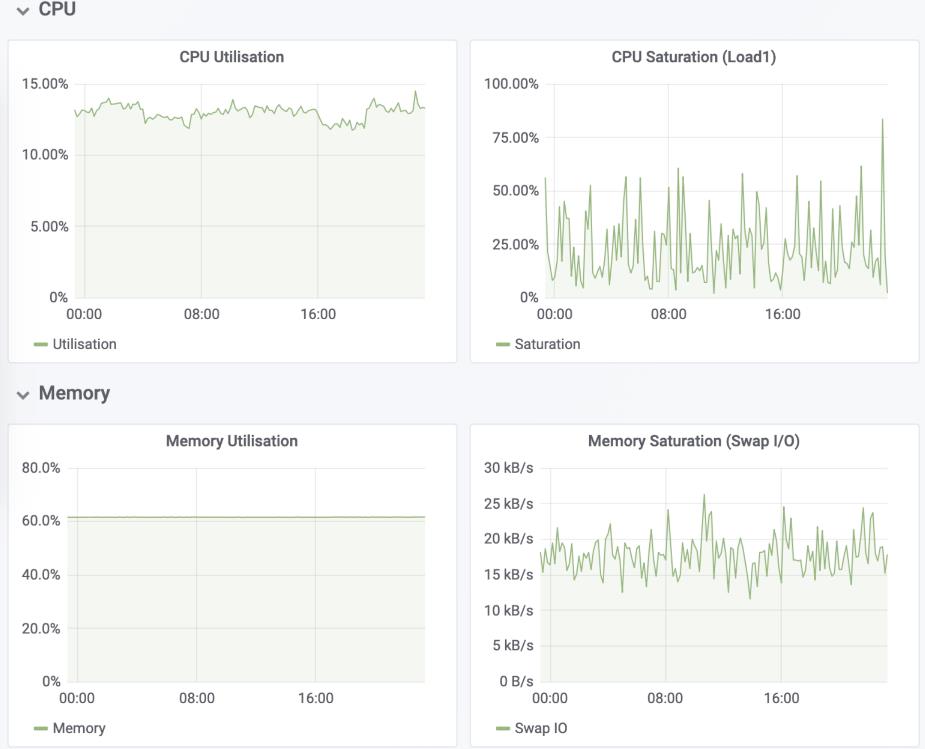
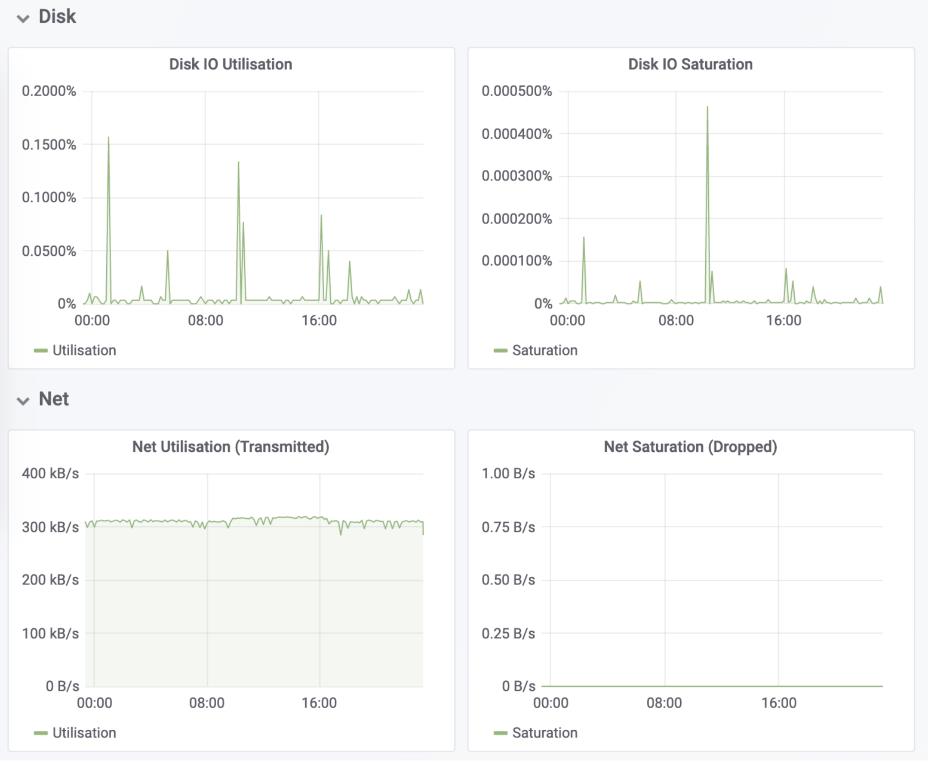
五、小结
一起梳理了系统监控的基本思路
系统监控的核心是资源的使用情况,包括CPU、内存、磁盘和文件系统、网络等硬件资源,以及文件描述符数、连接数、连接跟踪数等软件资源。而这些资源,都可以通过USE法来建立核心性能指标
USE法把系统资源的性能指标,简化成了三个类别,即使用率、饱和度以及错误数。 这三者任一类别过高时,都代表相对应的系统资源有可能存在性能瓶颈
基于USE法建立性能指标后,还需要通过一套完整的监控系统,把这些指标从采集、存储、查询、处理,再到告警和可视化展示等串联起来
可以基于Zabbix、Prometheus等各种 开源的监控产品,构建这套监控系统。这样,不仅可以将系统资源的瓶颈快速暴露出来,还可以借助监控的历史事后追查定位问题
以上是关于linux性能优化系统监控的综合思路的主要内容,如果未能解决你的问题,请参考以下文章