Python 爬虫篇 - 调用有道翻译api接口翻译外文网站的整篇西班牙文实战演示。爬取西班牙语文章调用有道翻译接口进行整篇翻译
Posted 挣扎的蓝藻
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Python 爬虫篇 - 调用有道翻译api接口翻译外文网站的整篇西班牙文实战演示。爬取西班牙语文章调用有道翻译接口进行整篇翻译相关的知识,希望对你有一定的参考价值。
Python 调用有道翻译 api 接口翻译整篇西班牙文实战演示
第一章:翻译效果展示
① 翻译文章示例一【阿尔卡拉门的无海摩纳哥:“不到4万欧元,你就不能在这里租任何东西。”】
文章: 阿尔卡拉门的无海摩纳哥:“不到4万欧元,你就不能在这里租任何东西。”
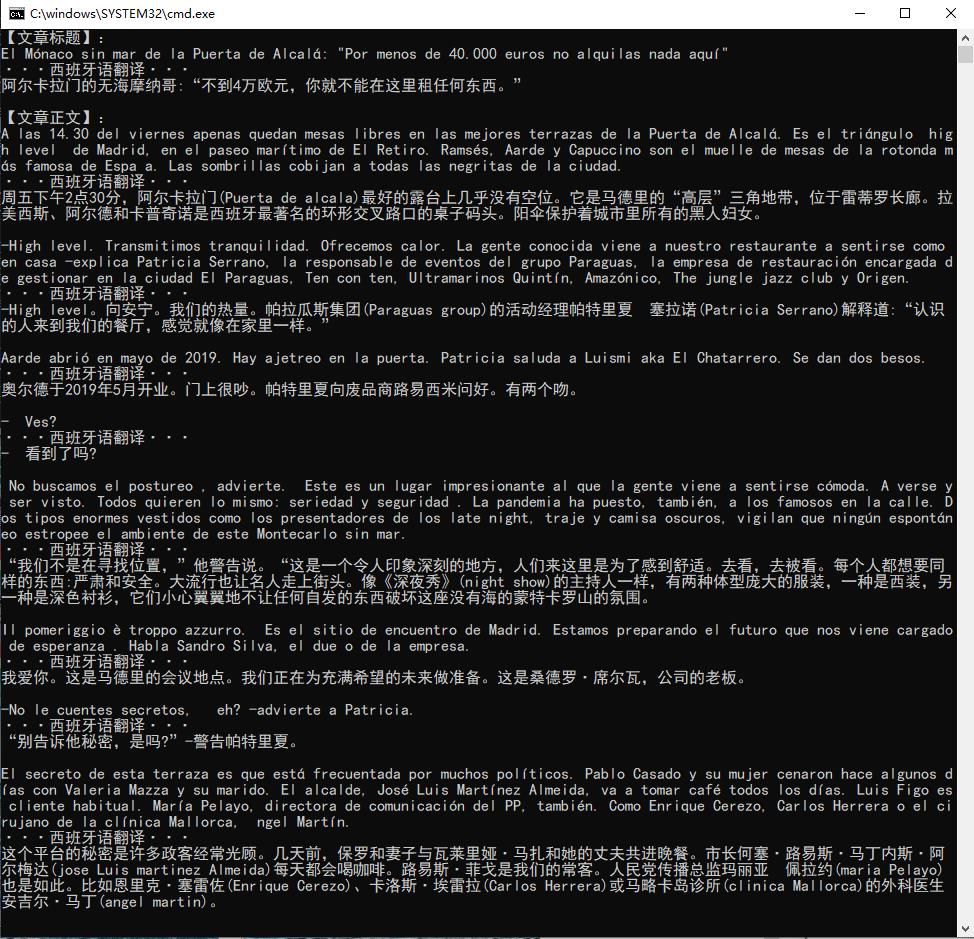
翻译后的效果:
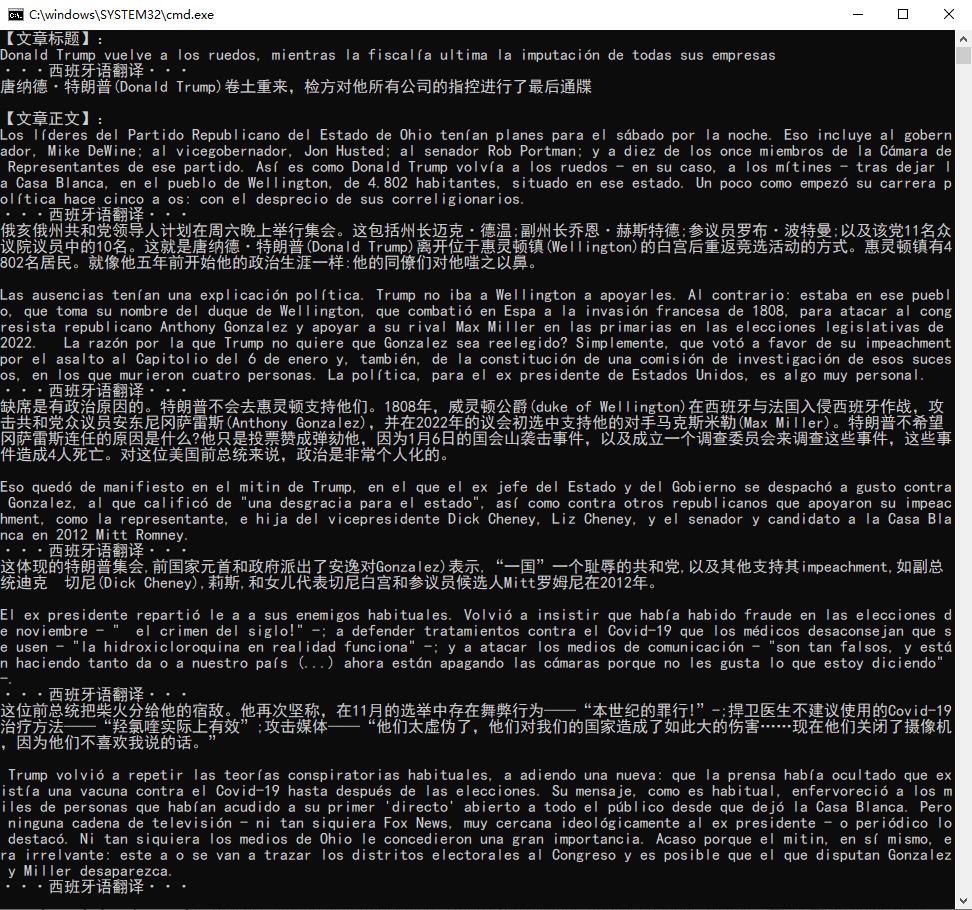
② 翻译文章示例二【唐纳德·特朗普(Donald Trump)卷土重来,检方对他所有公司的指控进行了最后通牒】
文章: 唐纳德·特朗普(Donald Trump)卷土重来,检方对他所有公司的指控进行了最后通牒
第二章:实现
① 文章结构分析
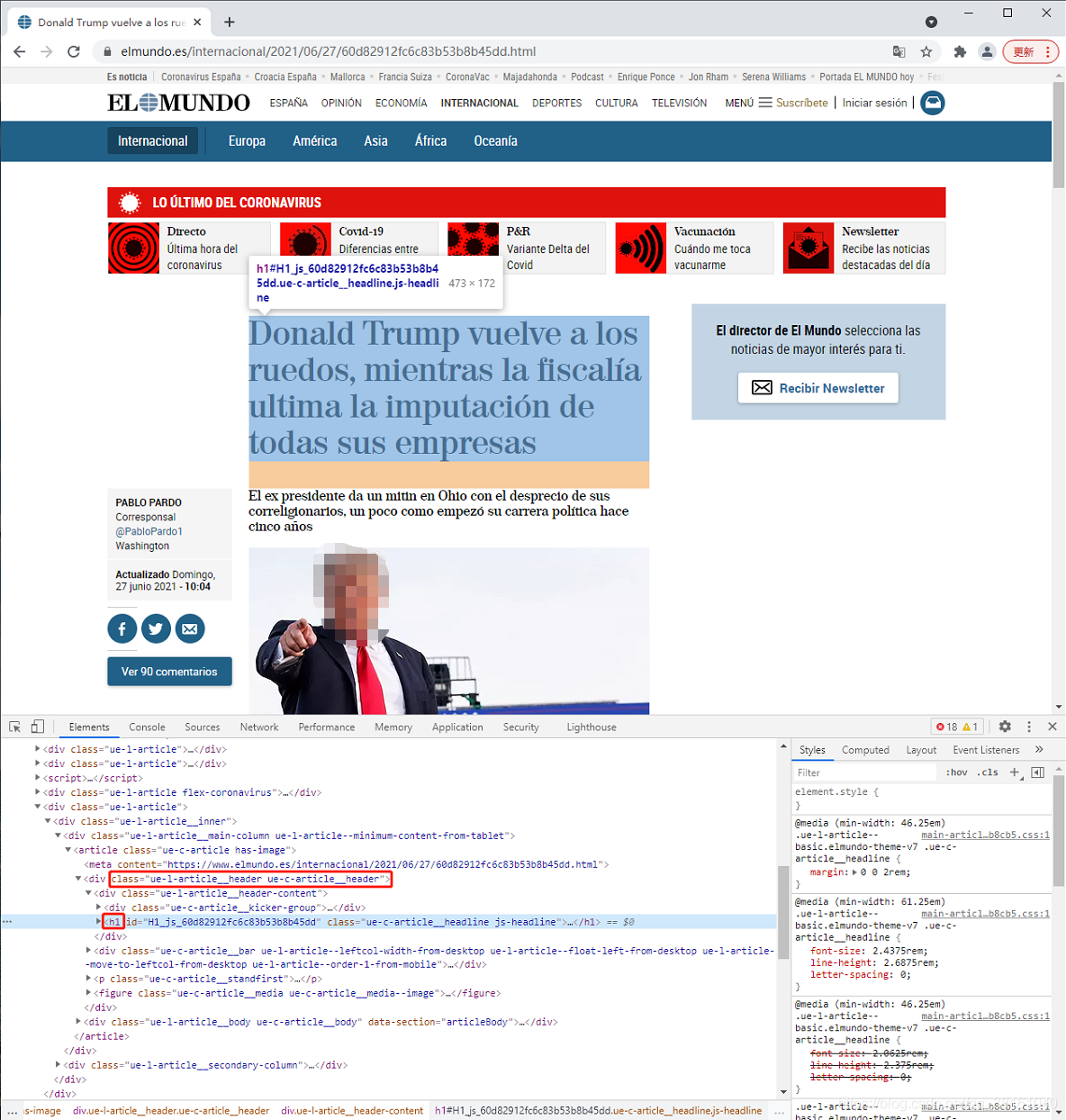
我们可以看到文章标题是在 class="ue-l-article__header-content" 的 div 下的 h1 里的内容。
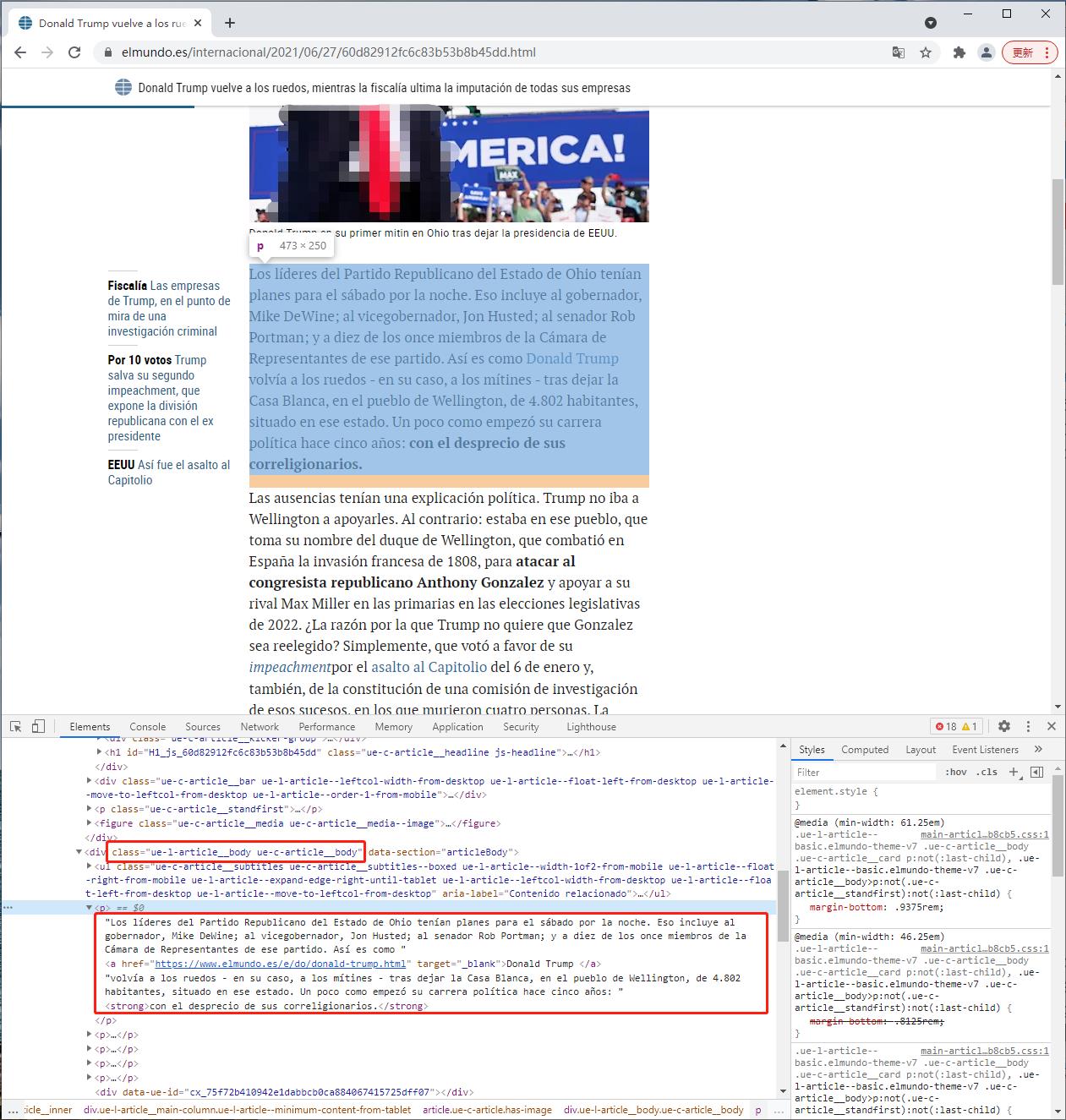
正文内容在 class="ue-l-article__body ue-c-article__body" 的 div 下的 p 元素里。
② 文章内容爬取
利用 BeautifulSoup 库对内容进行爬取。
bs4 模块通过 pip install bs4 即可进行安装。
注:文章内注释的翻译部分的代码就是后面要用到的翻译接口。
from urllib.request import urlopen
from bs4 import BeautifulSoup
def article_structure(article_url):
"""
xiaolanzao, 2021.06.27
【作用】
对传入网站的文章内容进行爬取
【参数】
article_url : 需要进行翻译的中文
【返回】
无
"""
url = urlopen(article_url)
soup = BeautifulSoup(url, 'html.parser') # parser 解析
# 读取文章标题
alert_header = soup.find('div', class_="ue-l-article__header-content").find('h1')
print("【文章标题】:")
print(alert_header.string)
# print("···西班牙语翻译···")
# print(spanish_translator(alert_header.string))
# 读取文章正文
alert_body = soup.find('div', class_="ue-l-article__body ue-c-article__body").contents # 所有body里的p节点
print("\\n【文章正文】:")
for i in alert_body:
if(i.name == "p"):
print(i.getText())
# print("···西班牙语翻译···")
# print(spanish_translator(i.getText()))
print()
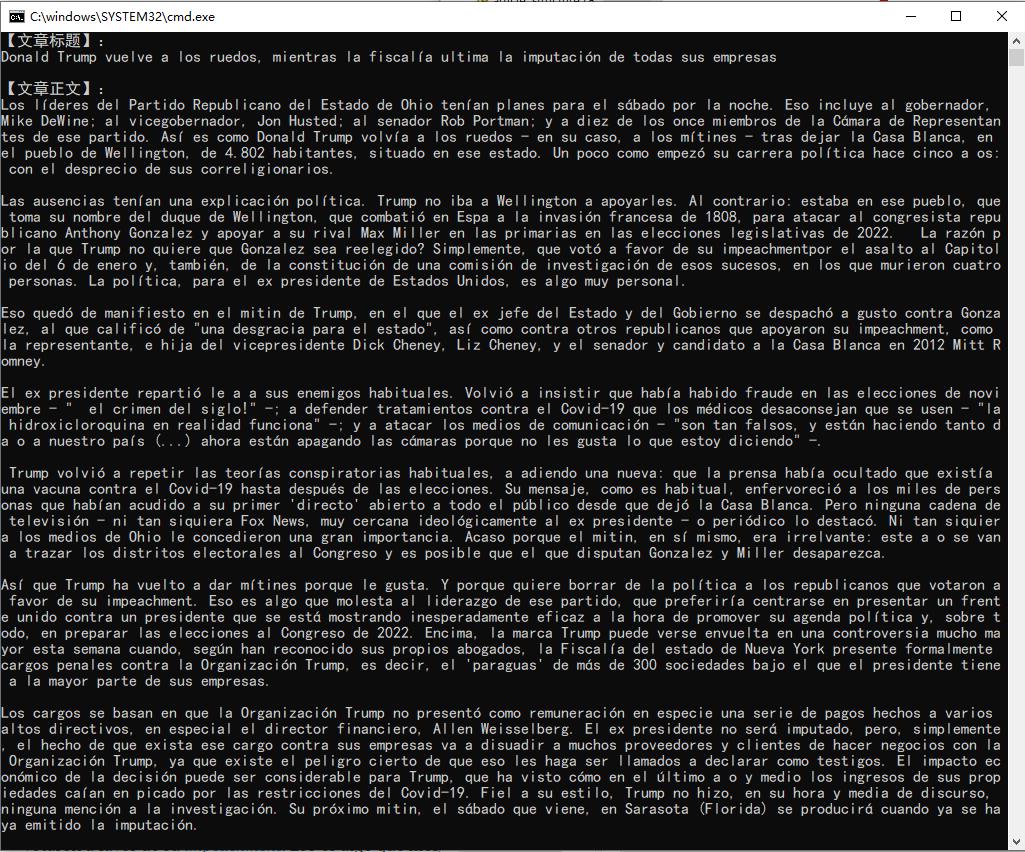
这是爬取后的文章。
③ 有道翻译接口
翻译接口如下,json 参数里面的 from,设置为西班牙文用的是 es。
实现过程,还有有道 api 的配置过程可以看我的这篇文章:
Python 技术篇-有道翻译api接口调用详细讲解、实战演示,有道智云·AI开放平台
import requests
import time
import hashlib
import uuid
def spanish_translator(translate_text):
"""
xiaolanzao, 2021.06.27
【作用】
将传入的西班牙语内容翻译为中文
【参数】
translate_text : 需要进行翻译的中文
【返回】
翻译后的西班牙文
"""
youdao_url = 'https://openapi.youdao.com/api' # 有道api地址
input_text = "" # 翻译文本生成sign前进行的处理
# 当文本长度小于等于20时,取文本
if(len(translate_text) <= 20):
input_text = translate_text
# 当文本长度大于20时,进行特殊处理
elif(len(translate_text) > 20):
input_text = translate_text[:10] + str(len(translate_text)) + translate_text[-10:]
app_id = "xxx" # 应用id
app_key = "xxx" # 应用密钥
time_curtime = int(time.time()) # 秒级时间戳获取
uu_id = uuid.uuid4() # 随机生成的uuid数,为了每次都生成一个不重复的数。
sign = hashlib.sha256((app_id + input_text + str(uu_id) + str(time_curtime) + app_key).encode('utf-8')).hexdigest() # sign生成
data = {
'q':translate_text,
'from':"es",
'to':"zh-CHS",
'appKey':app_id,
'salt':uu_id,
'sign':sign,
'signType':"v3",
'curtime':time_curtime,
}
r = requests.get(youdao_url, params = data).json() # 获取返回的json()内容
return r["translation"][0] # 获取翻译内容
喜欢的点个赞❤吧!
以上是关于Python 爬虫篇 - 调用有道翻译api接口翻译外文网站的整篇西班牙文实战演示。爬取西班牙语文章调用有道翻译接口进行整篇翻译的主要内容,如果未能解决你的问题,请参考以下文章