09 关于 lzf 压缩
Posted 蓝风9
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了09 关于 lzf 压缩相关的知识,希望对你有一定的参考价值。
前言
在拷贝前面的这一系列的数据结构的代码的时候, 偶然看到了一个 lzf, 呵呵 稍微看了看
本文的 lzf 相关代码 拷贝自 redis-6.2.0
代码来自于 https://redis.io/
一个简单并且快速的字符压缩算法
比较常规的通过引用计算来压缩字符串的算法
关于 lzf 这套代码, redis 项目中也有, liblzf 的官方文档 上面的下载也有
测试用例
//
// Created by Jerry.X.He on 2021/2/25.
//
#include <iostream>
#include "../libs/sds.h"
#include "../libs/lzf.h"
using namespace std;
int main(int argc, char **argv) {
sds str = sdsnew("hello hello hello hello ");
void *compressed = malloc(1024);
int compressedLen = 1024;
int realCompressedLen = lzf_compress(str, sdslen(str), compressed, compressedLen);
void *decompressed = malloc(1024);
int decompressedLen = 1024;
int realDecompressedLen = lzf_decompress(compressed, realCompressedLen, decompressed, decompressedLen);
int x = 0;
}
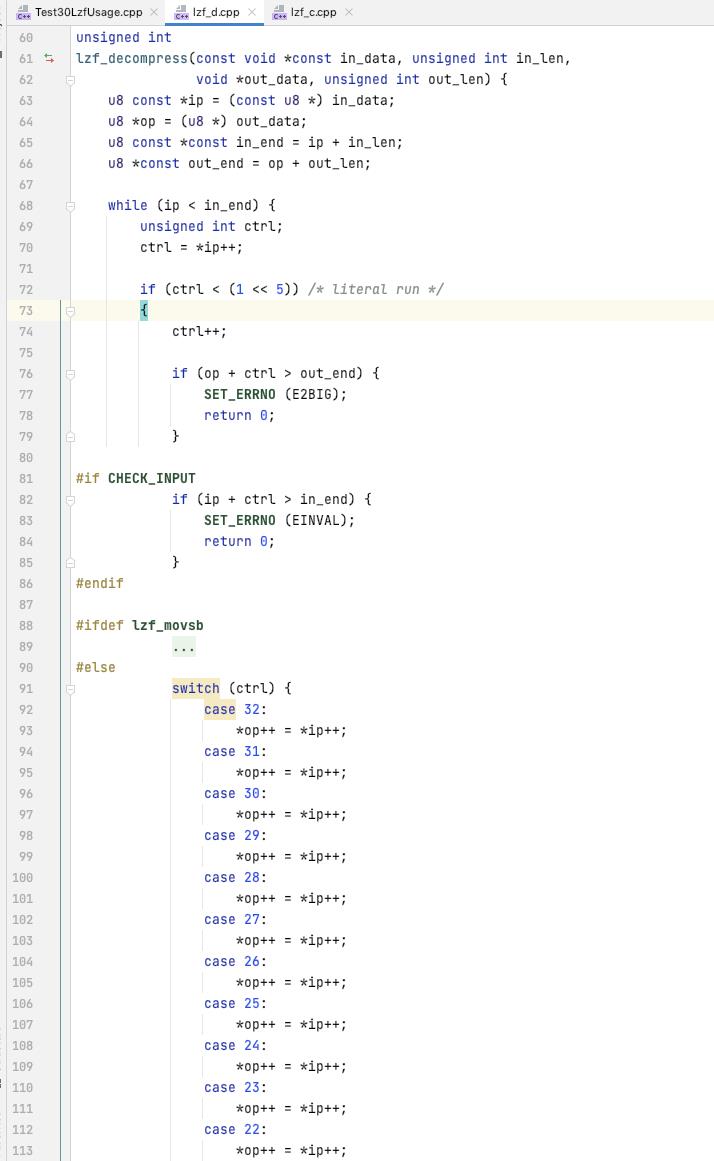
lzf_decompress
先来看一下 lzf 的解压, 先看一下 他压缩的大致的结果 和 原始字符串的映射关系, 有助于理解
# lzf 编码 "hello hello " 之后
编码之后的结果如下 06 68 65 6c 6c 6f 20 68 20 05 01 6f 20
06 68 65 6c 6c 6f 20 68
# ctrl = 0x06, (ctrl < 32) ctrl + 1 表示是 ref 文本的长度, "hello h"
20 05
# 0x20 = 0b0010 0000 -> len 为 1 + 2 = 3, refOffset 的高5bit 为 0
# 0x05 表示的是 refOffset 的低8bit, ref 为 op - 0x05 - 1
# 这里这个 ref 会复制三个字符串 "ell"
01 6f 20
# ctrl = 0x02, (ctrl < 32), ctrl + 1 表示文本的额长度, "o "
多个 entry, 第一个字符为控制字符, 一个 entry 可能是一个常量, 或者是一个引用
如果是常量, (ctrl < 32), ctrl + 1[长度为0没有意义]表示的是字符串常量的长度, 紧接着 ctrl+1 个字符, 表示的是常量的数据
将该常量拷贝到 结果序列里面
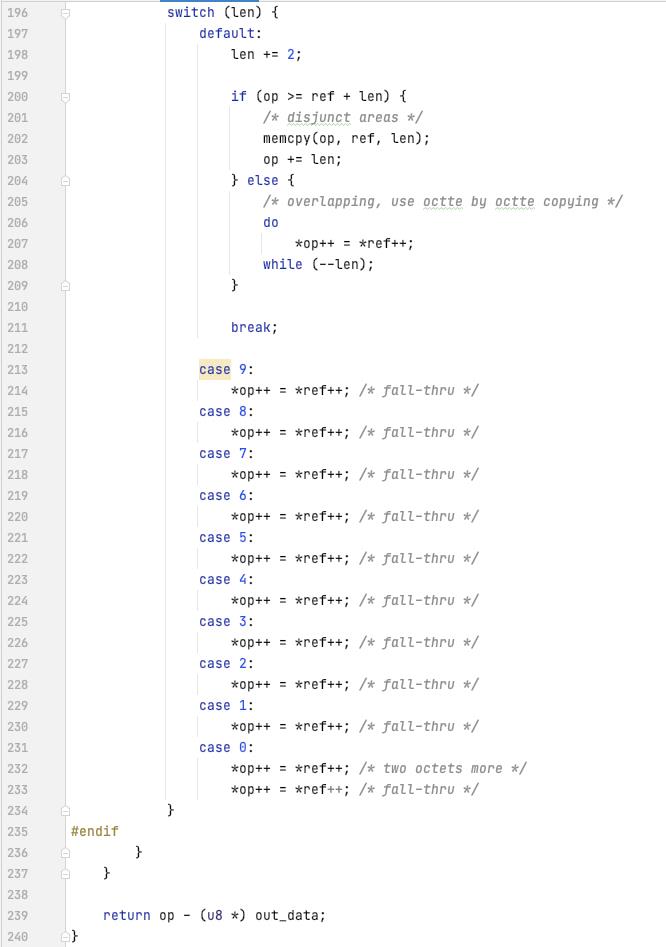
如果是引用, (ctrl >= 32), 高3bit表示的是长度 len, 如果为7, ctrl后面的一个字节组合表示长度
ctrl 的低5bit表示的是 ref 的偏移的高5bit, ctrl 后面的第一字节[len < 7]或者第二字节[len>=7], 表示的是 偏移的低8bit
实际引用的长度为 len+2[编码的时候最小2字节相同才处理为引用], 实际的偏移为 ( ((ctrl & 0x1f) << 8) | ctrl[n] )
然后根据偏移获取 引用的位置, 根据长度拷贝数据信息到 结果序列里面
最终返回 结果序列的长度


lzf_compress
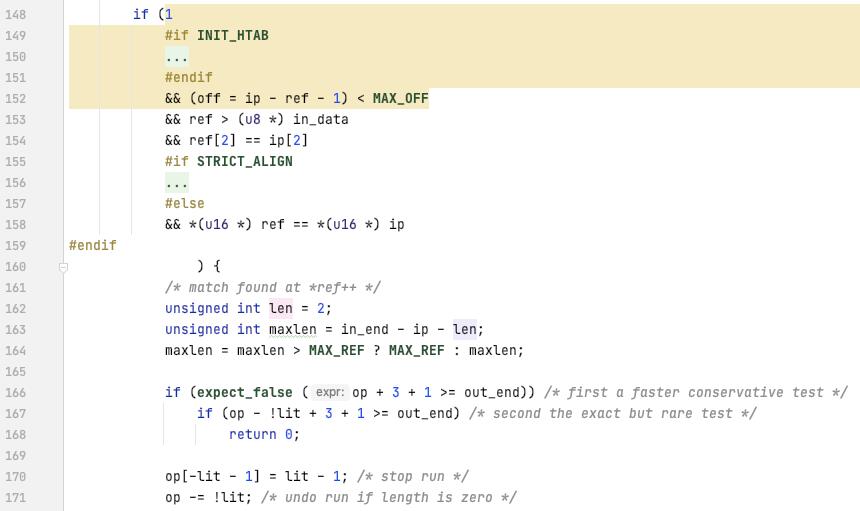
先来看一下 lzf 的压缩, 以一个具体的实例来看压缩的过程, 有助于理解
lzf 压缩 "hello hello ", 最小的共同部分为 长度为2的字符串
"hello hello " 计算 hash, 存放于 htab, 存放 "h" 到 out_data
"ello hello " 计算 hash, 存放于 htab, 存放 "e" 到 out_data
"llo hello " 计算 hash, 存放于 htab, 存放 "l" 到 out_data
"lo hello " 计算 hash, 存放于 htab, 存放 "l" 到 out_data
"o hello " 计算 hash, 存放于 htab, 存放 "o" 到 out_data
" hello " 计算 hash, 存放于 htab, 存放 " " 到 out_data
"hello " 计算 hash, 存放于 htab, 存放 "h" 到 out_data
这里之所以继续处理为 literal, 是因为代码里面的 "ref > (u8 *) in_data", 个人觉得可以更新为 "ref >= (u8 *) in_data"
"ello " 计算 hash, 获取 htable 里面的元素, 发现其已经存在, 并且在 in_data 里面, 然后进行比较, 获取长度, 放入 (1|0[off高5bit]) = 0b0010 0000, 放入 off 剩余 8bit, 0b0000 0101 放入到 out_data
呵呵 这里的长度计算似乎是存在问题阿, len 这里最佳期望计算出来应该是 3 才对吧, 这里计算的是 出去末尾2字节, 能匹配的最长的长度 - 2
按照这里 len 为 1, 会跳过三个字符, 接下来是 "o "
"o ", 这里接下来不超过两个字符了, 直接 literal 编码, 放入 0x01 到 out_data, 放入 "o" 到 out_data, 放入 " " 到 out_data
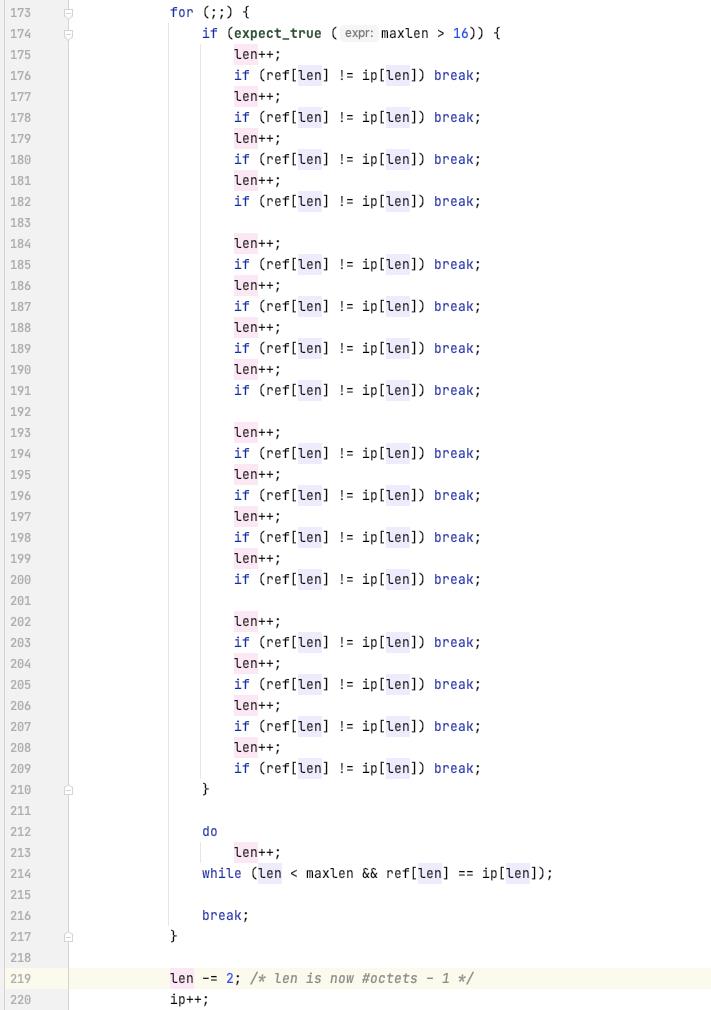
从第一个字符开始遍历给定的字符串
根据前三个字节来计算 hash, 将当前 输入指针 的引用放入 hashTable[hash] 里面
计算当前 指针 和已经存放的 hashTable[hash] 的偏移, 是否在当前字符串的返回内[估算判断], 然后比较数据 至少需要确保 ref 的前两字节 和 当前输入指针的前两字节相同
更新之前的常量的长度, 计算当前 ref 的长度, 偏移, 编码当前 ref 的信息[len + offset]
编码最后的几个字节的数据信息
返回编码的数据的长度


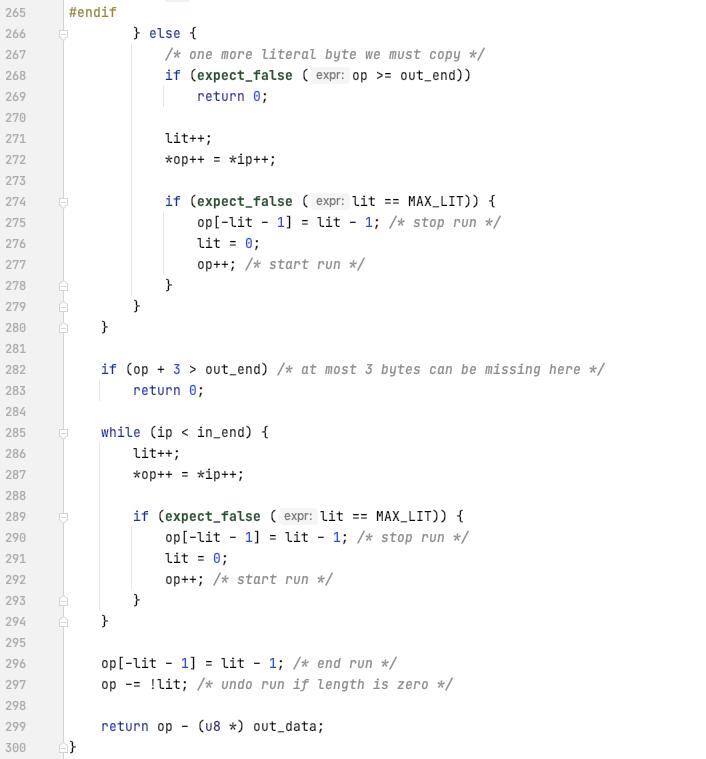
lzf 的一些思考
## lzf 编码 "hello hello " 理想情况下压缩之后的结果为 "05 68 65 6c 6c 6f 20 80 05"
# 长度为 6 的 literal "hello "
05 68 65 6c 6c 6f 20
# 0b 1000 0000, len 为 4, refOffset 高5bit为 0b00000, refOffset 低8bit为 0b0000 0101, refOffset 为 5
# ref 指向 "hello " 真实长度为 len + 2 = 6
80 05
## lzf 编码 "hello hello hello hello " 理想情况下压缩之后的结果为 "05 68 65 6c 6c 6f 20 e0 09 05"
# 长度为 6 的 literal "hello "
05 68 65 6c 6c 6f 20
# 0b 1110 0000, len 标记 为 7, refOffset 高5bit为 0b00000, 接下来 0x09 还是表示长度, len 为 0x07+0x09=16, refOffset 低8bit为 0b0000 0101, refOffset 为 5
# ref 指向 "hello hello hello hello " 真实长度为 len + 2 = 18
e0 09 05
但是为什么 压缩出来的数据并不是我们只管感受能够看到的 "理想的结果" 呢
我找了一下 官方文档, 似乎是 也没有细节的描述, 可能 得找找相关的论文看看吧
官方如此设计 应该是针对一些特殊的场景吧, 呵呵 可能是一些 我们目前没有考虑到的场景
完
参考
liblzf 的官方文档
liblzf 的 release 库下载
以上是关于09 关于 lzf 压缩的主要内容,如果未能解决你的问题,请参考以下文章