哪种一致性哈希算法才是解决分布式缓存问题的王者?
Posted 云加社区
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了哪种一致性哈希算法才是解决分布式缓存问题的王者?相关的知识,希望对你有一定的参考价值。
一、一致性哈希的特性
-
平衡性
不同key通过算法映射后,可以比较均衡地分布到所有的后端节点上。
-
单调性
当有新的节点上线后,系统中原有的key要么还是映射到原来的节点上,要么映射到新加入的节点上,不会出现从一个老节点重新映射到另一个老节点。
-
稳定性
当服务发生扩缩容的时候,发生迁移的数据量尽可能少。
二、问题背景
假设我们有N个cache服务器节点,那如何将数据映射到这N个节点上呢,最简单的方法就是用数据计算出一个hash值,然后用hash值对N取模,如:hash(data) % N,这样只要计算出来的hash值比较均匀,那数据也就能比较均匀地映射到N个节点上了。但这带来的问题就是,如果发生扩缩容,节点的数量发生了变化,那很多数据的映射关系都会发生变化。显然这种方法虽然简单,但并不太能解决我们的需求。
三、四种常见一致性哈希算法
下面分别介绍对比四种比较常见的一致性哈希算法,看看一致性哈希算法是怎么解决这问题的。
1. 经典一致性哈希
经典的一致性哈希算法也就是我们常说的割环法,大家应该都比较熟悉。简单来说就是,我们把节点通过hash的方式,映射到一个范围是[0,2^32]的环上,同理,把数据也通过hash的方式映射到环上,然后按顺时针方向查找第一个hash值大于等于数据的hash值的节点,该节点即为数据所分配到的节点。而更好点的做法是带虚拟节点的方法,我们可以为每个物理节点分配若干个虚拟节点,然后把虚拟节点映射到hash环,分配给每个物理节点虚拟节点数量对应每个物理节点的权重,如下图1所示。这样还是按顺时针的方法查找数据所落到的虚拟节点,再看该虚拟节点是属于哪个物理节点就可以知道数据是分配给哪个物理节点了。
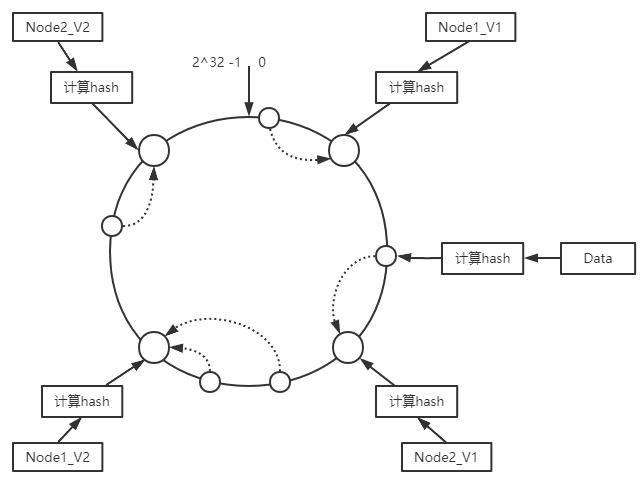
图1
这种割环法的实现多种,下面以比较有名的Ketama Hash实现为例进行对比分析。Ketama Hash的关键源码如下:
#服务器节点例子,第一列为地址,第二列为内存#------ Server --------Mem-##255.255.255.255:6553566666#10.0.1.1:1121160010.0.1.2:1121130010.0.1.3:1121120010.0.1.4:1121135010.0.1.5:11211100010.0.1.6:1121180010.0.1.7:1121195010.0.1.8:11211100typedef struct{unsigned int point; // point on circlechar ip[22];} mcs;typedef struct{char addr[22];unsigned long memory;} serverinfo;typedef struct{int numpoints;void* modtime;void* array; //array of mcs structs} continuum;typedef continuum* ketama_continuum;/** \brief Generates the continuum of servers (each server as many points on a circle).* \param key Shared memory key for storing the newly created continuum.* \param filename Server definition file, which will be parsed to create this continuum.* \return 0 on failure, 1 on success. */static intketama_create_continuum( key_t key, char* filename ){if (shm_ids == NULL) {init_shm_id_tracker();}if (shm_data == NULL) {init_shm_data_tracker();}int shmid;int* data; /* Pointer to shmem location */unsigned int numservers = 0;unsigned long memory;serverinfo* slist;slist = read_server_definitions( filename, &numservers, &memory );/* Check numservers first; if it is zero then there is no error message* and we need to set one. */if ( numservers < 1 ){set_error( "No valid server definitions in file %s", filename );return 0;}else if ( slist == 0 ){/* read_server_definitions must've set error message. */return 0;}syslog( LOG_INFO, "Server definitions read: %u servers, total memory: %lu.\n",numservers, memory );/* Continuum will hold one mcs for each point on the circle: */mcs continuum[ numservers * 160 ];unsigned int i, k, cont = 0;for( i = 0; i < numservers; i++ ){float pct = (float)slist[i].memory / (float)memory;// 按内存权重计算每个物理节点需要分配多少个虚拟节点,正常是160个unsigned int ks = floorf( pct * 40.0 * (float)numservers );int hpct = floorf( pct * 100.0 );syslog( LOG_INFO, "Server no. %d: %s (mem: %lu = %u%% or %d of %d)\n",i, slist[i].addr, slist[i].memory, hpct, ks, numservers * 40 );for( k = 0; k < ks; k++ ){/* 40 hashes, 4 numbers per hash = 160 points per server */char ss[30];unsigned char digest[16];// 在节点的addr后面拼上个序号,然后以该字符串去计算hash值sprintf( ss, "%s-%d", slist[i].addr, k );ketama_md5_digest( ss, digest );/* Use successive 4-bytes from hash as numbers* for the points on the circle: */int h;// 16字节,每四个字节作为一个虚拟节点的hash值for( h = 0; h < 4; h++ ){continuum[cont].point = ( digest[3+h*4] << 24 )| ( digest[2+h*4] << 16 )| ( digest[1+h*4] << 8 )| digest[h*4];memcpy( continuum[cont].ip, slist[i].addr, 22 );cont++;}}}free( slist );// 排序,方便二分查找/* Sorts in ascending order of "point" */qsort( (void*) &continuum, cont, sizeof( mcs ), (compfn)ketama_compare );. . .return 1;}
Ketama Hash的实现简单来说可以分成以下几步:
2)对每个节点按权重计算需要生成几个虚拟节点,基准是每个节点160个虚拟节点,每个节点会生成10.0.1.1:11211-1、10.0.1.1:11211-2到10.0.1.1:11211-40共40个字符串,并以此算出40个16字节的hash值(其中hash算法采用的md5),每个hash值生成4个4字节的hash值,总共40*4=160个hash值,对应160个虚拟节点;
这种割环法的平衡性在虚拟节点数较多且搭配较好的hash函数的情况下,可以具备较好的平衡性和稳定性,实际应用中可以采用比Ketama算法默认160更多的虚拟节点数,hash算法也可以采用其他的算法。在算法的复杂度方面,Ketama算法的复杂度是O(log(vn)),其中n是节点数,v是节点的虚拟节点数。Ketama算法也能很好地满足单调性,当发生节点数量发生伸缩的时候,相当于只是在环上增加或者去掉相应的虚拟节点,也就只会导致变化的节点上的数据发生重新映射,因些能很好满足单调性。
2. Rendezvous hash
这个算法比较简单粗暴,没有什么构造环或者复杂的计算过程,它对于一个给定的Key,对每个节点都通过哈希函数h()计算一个权重值wi,j = h(Keyi, Nodej),然后在所有的权重值中选择最大一个Max{wi,j}。显而易见,算法挺简单,所需存储空间也很小,但算法的复杂度是O(n)。从wiki上摘抄的python实现的核心代码如下:
def determine_responsible_node(nodes, key):"""Determines which node, of a set of nodes of various weights, is responsible for the provided key."""highest_score, champion = -1, Nonefor node in nodes:score = node.compute_weighted_score(key)if score > highest_score:champion, highest_score = node, scorereturn champion
当发生扩缩的时候,相当于增加了一次计算hash的机会,如果计算出来的hash值超过原来的最大值,则该部分key分配到新的节点,缩容的时候则相当于把该节点上的key迁移到该key原本计算出来的hash值次高的节点上。可见,当节点变化的时候,rendezvous hash只会影响到最大权重值落到变化的节点的key,也就是说只有变化的节点上的数据需要重新映射,因些也很符合单调性的要求。而Rendezvous hash算法的平衡性和稳定性则取决于哈希函数的随机特性。
在wiki上还提供了优化方法(Skeleton-based variant)来降低算法的复杂度,如下图2所示,把原始节点分成若干个虚拟组,虚拟组一层一层组成一个“骨架”,然后在虚拟组中按照Rendezvous hash一样的方法计算出最大的节点,从而得到下一层的虚拟组,再在下一层的虚拟组中按同样的方法计算,直到找到最下方的真实节点,最终可以把算法复杂度降低到O(log n)。
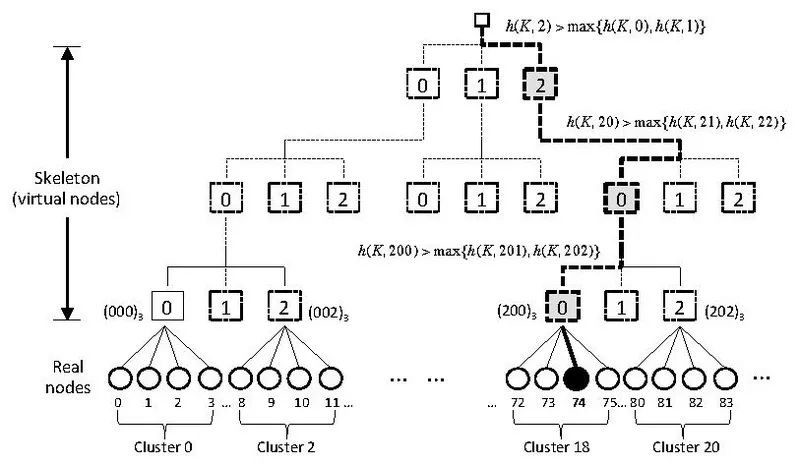
图2
3. Jump consistent hash
Jump consistent hash是Google于2014年发表的论文中提出的一种一致性哈希算法,它占用内存小且速度很快,并且只有大概5行代码,比较适合用在分shard的分布式存储系统中。其完整的代码如下,其输入是一个64位的key及桶的数量,输出是返回这个key被分配到的桶的编号。
int32_t JumpConsistentHash(uint64_t key, int32_t num_buckets) {int64_t b = -1, j = 0;while (j < num_buckets) {b = j;key = key * 2862933555777941757ULL + 1;j = (b + 1) * (double(1LL << 31) / double((key >> 33) + 1));}return b;}
下面根据论文内容简单介绍下其原理:
-
记ch(key, num_buckets)为桶数量为num_buckets时的hash函数 -
当num_buckets = 1时,显而易见,所有key都会分配给仅有的一个桶,即ch(key, 1) == 0 -
当num_buckets = 2时,为了使用key分布均匀,应该有1/2的key保留在0号桶中,而有1/2的key应该迁移到1号桶中 由此可以发现,当num_buckets由n变为n+1时,ch(key, n+1)的结果中应该有n/n+1结果保持不变,而有1/n+1的结果发生怕了跳变,变成了n
Jump consistent hash的这种思路看上去其实挺简单,就是num_buckets变化的时候,有些key的计算结果会发生变化。假如这里我们取一个随机数来决定每次要不要跳变,并且这个随机数只跟key有关,那么我们得到的初步算法如下:
int ch(int key, int num_buckets) {random.seed(key) ;int b = 0; // This will track ch(key, j +1) .for (int j = 1; j < num_buckets; j ++) {if (random.next() < 1.0/(j+1) ) b = j ; //这个不会经常执行}return b;}
从代码可以看出,算法的复杂度是O(n),而且大家会发现,大多数情况下不会发生跳变,也就是b=j并不会执行,并且随着j越来越大,跳变的可能越来越小,那么有没有什么办法来进行优化,让我们能通过一个随机数来直接得到下一次跳变的j,降低算法的复杂度呢?论文也在此基础上给出了优化后的算法并推理论证:
-
把ch(key, num_buckets)看做是一个随机变量,对于特定的key k,jump consistent hash跟踪了其桶编号的跳变 -
假设b是最后一次跳变的桶编号,也就是ch(k, b) != ch(k, b+1) 且ch(k, b+1) = b -
假设下一次跳变的结果是j,也就是(b, j)之间每一次增加桶的结果都不应该发生跳变,对于(b,j)区间内的任意的i,j是下一次跳变的概率可以记为:P(j ≥ i) = P( ch(k, i) = ch(k, b+1) ) -
幸运的是P( ch(k, i) = ch(k, b+1) )的结果很好算,我们注意到P( ch(k, 10) = ch(k, 11) ) = 10/11, P( ch(k, 11) = ch(k, 12) ) = 11/12, P( ch(k, 10) = ch(k, 12) ) = 10/11 * 11/12 = 10/12。总的来说,如果n ≥ m, P( ch(k, n) = ch(k, m) ) = m / n. 因此对于任意的 i > b有:P(j ≥ i) = P( ch(k, i) = ch(k, b+1) ) = (b+1) / i,也就是j ≥ i的概率是(b+1) / i。 此时我们取一个[0,1]区间的随机数r,规定r < (b+1) / i就有j ≥ i,也就是i ≤ (b+1) / r,这样我们就得到了i的上界是(b+1) / r,而对于任意的i都有j ≥ i,所以j = floor((b+1) / r),这样我们就用一个随机数r来算出了j。
所以上面的算法可以优化成以下实现:
int ch(int key, int num_buckets) {random. seed(key) ;int b = -1; // bucket number before the previous jumpint j = 0; // bucket number before the current jumpwhile(j<num_buckets){b=j;double r=random.next(); // 0<r<1.0< span="">j = floor( (b+1) /r);}return b;}</r<1.0<>
这里算法的复杂度变成了O(ln n),代码里的随机函数需要是一个均匀的随机数生成器,论文中这里采用了一个64位的线性同余随机数生成器,所以对于key本来就是64位整数的,也不需要再对key进行hash计算了。Jump consistent hash的平衡性也取决于线性同余随机数生成器,因此也有着比较好的平衡性,论文中也与Karger经典的一致性哈希算法进行了对比,下图3为其对比结果,从标准差来看,jump consistent hash的平衡性比经典的一致性哈希算法好很多。而当节点数量发生变化的时候,jump consistent hash会发生跳变的key的数量已经是理论上的最小值1/n了。但jump consistent hash也有一个比较明显的缺点,它只能在尾部增删节点,而不太好在中间增删,对于那种节点随机故障需要剔除的情况,如果用这个算法就需要再采用其他方法来处理了。
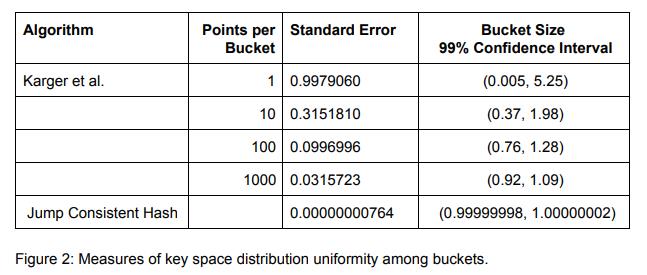
图3
4. Maglev hash
Maglev hash是Google于2016年发表的一篇论文中提出来的一种新的一致性哈希算法。Maglev hash的基本思路是建立一张一维的查找表,如图4所示,一个长度为M的列表,记录着每个位置所属的节点编号B0...BN,当需要判断某个key被分配到哪个节点的时候,只需对key计算hash,然后对M取模看所落到的位置属于哪个节点。
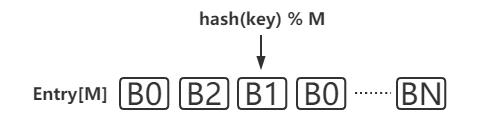
图4
如何查找看上去很简单,问题是如何产生这个查找表。接下来以图5为例介绍下如何生成查找表,假设我们有三个节点,B0、B1、B2,我们为每个节点生成长度为M(图5中M=7)的permutation list(偏好序列),序列是(0,M-1)的随机数(如何生成这个序列我们下面解释),如图5所示,B0的偏好序列是[3,0,4,1,5,2,6]。另外我们准备一个长度为M的待填充的查找表Entry。然后我们按B0、B1、B2的顺序,根据每个节点的偏好序列中的数字来填充查找表Entry。我们把偏好序列中的数字作为查找表中的目标位置,把该序列的节点编号填充到查找表的目标位置上,如果目标位置已经被占用,则继续往下查看偏好序列的下一个数字。以图5举例,具体步骤如下:
1)首先从B0的开始,B0偏好序列的第一个数字是3,所以查找表的3号位置填上B0
2)按顺序轮到B1,其偏好序列的第一个数字是0,所以查找表的0号位置填上B1
3)接着轮到B2,发现第一个数字是3,而查找表的3号位置已经被占用,那继续看B2的偏好序列的第二个数字是4,所以查找表的4号位置填上B2
4)然后又回到B0,这时发现B0的第二个数字是0已经被占用,往下看偏好序列的第三个数字是4,也被占用了,则继续往下看第四个数字是1,查找表的1号位置没被占用,所以查找表的1号位置填上B0
5)按此规则继续处理B1、B2,直到把查找表的所有位置都填满
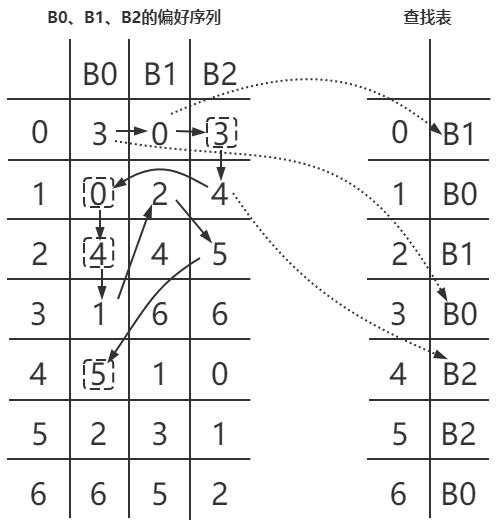
图5
论文中也给出了查找表生成过程的伪代码,如下图6所示:

图6
介绍完查找表是如何生成的,还剩下一个问题就是各节点的偏好序列又是如何生成的。论文中给出的方法是取两个不相关的hash函数,然后以各个节点的名字使用两个hash函数分别计算,得到一个offset和一个skip,如下图7所示,有了offset和skip,对于i号节点的偏好序列的第j个数,则通过(offset + j * skip) mod M就可以得到。论文中还强调了,这里的M必须是一个素数,这是为了让每个skip值跟M互质。另外,算法的复杂度是O(MlogM),最坏情况是O(M*M),这种情况发生在节点数量N=M,并且每个节点生成的序列都是一样的情况下,为了避免这种情况,一般建议选择一个值远大于N的M。
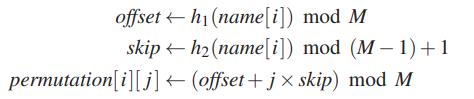
图7
论文中说明了,按这种方法生成的查找表,每个节点分到的槽位基本是M/N个,最多只有1的差别,其中N是指所有节点的数量,由此可以看到,Maglev hash有很好的平衡性。下图8是论文中给出的,Maglev hash与经典一致性hash及Rendezvous在均衡性方面的实现对比结果,其中的small跟large分别代码查找表大小为65537和655373,而min跟max分别代表最小及最大的槽位占比。从图中可以看到,无论是在small还是large的情况下,Maglev hash的均衡性都是最好的,而在small的情况下经典一致性hash及Rendezvous的最小及最大的槽位占比相差还是挺大的,当然这种情况可以随着查找表的增大而有所下降。
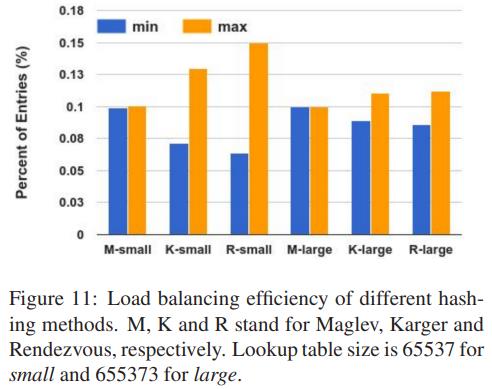
图8
接下来看下当节点发生增删的时候,对生成的查找表有什么影响。以下图9为例,我们在图5原来的基础上假设B1节点出现故障被淘汰掉了,这必然导致查找表里的一些槽位编号发生变化,从图9可以看到,当B1节点删除后,有3个槽位发生了变化,其中0号跟2号位置,由于B1节点的删除被重新分配给了B0,这符合一致性hash的单调性,比较好理解,但还发生了一个从B0到B2的重新映射,这是不符合一致性哈希算法的单调性要求的,论文中也指出了这种情况的存在。
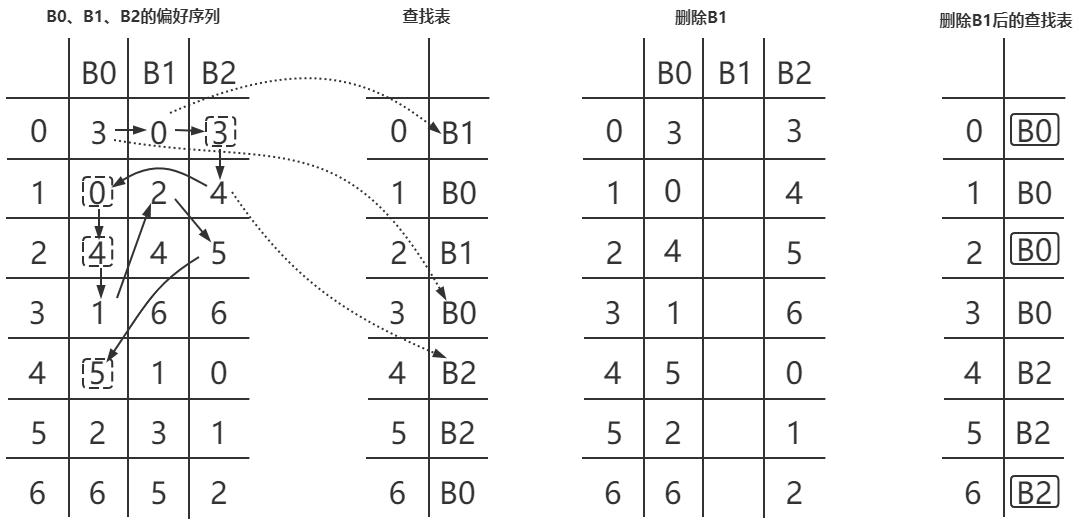
图9
在稳定性方面,经典一致性哈希、Rendezvous和Jump consistent hash都做到了在后端节点数量发生变化的时候的最小重新映射,而从图9删除节点的情况来看,Maglev hash并没有做到最小重新映射。针对这个问题,论文中也对Maglev hash对后端节点数量变化的容忍性做了测试实验,下图10是其测试结果,展示了相同后端节点数量、不同查找表大小的情况下,槽位映射结果发生变化的百分比与后端节点故障的百分比的关系。从图10可以看到,随着后端节点故障百分比的增加,槽位映射结果发生变化的百分比也在增加,但是在查找表大小比较大的情况下,Maglev hash对后端节点的增删有更好的容忍性。
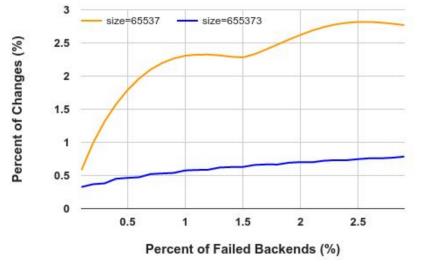
图10
但尽管是这样,Google仍然只采用65537的查找表大小,据说是觉得后端节点同时故障的概率小,而且还有其他保护机制,另外是当查找表大小从65537增加到655373的时候,查找表的生成时间从1.8ms增加到22.9ms,所以查找表也不能无限扩大。
四、总结
下面简单地以一个表格对以上四种一致性哈希算法进行对比总结:
| 算法 | 扩容 |
缩容 |
平衡性 |
单调性 |
稳定性 |
时间复杂度 |
| Ketama | 好 |
好 | 较好 |
好 | 较好 |
O(log vn) |
| Rendezvous | 好 |
好 | 较好 |
好 | 较好 |
O(n) |
Jump consistent hash |
好 |
需要额外处理 | 好 | 好 | 好 | O(ln n) |
| Maglev hash | 较好 |
较好 | 好 | 较好 | 较好 | O(MlogM),最坏O(M*M) |
作者简介
周晓场,腾讯后台开发工程师,目前在天美工作室负责游戏服务器开发相关工作,毕业于华南理工大学计算机学院。
以上是关于哪种一致性哈希算法才是解决分布式缓存问题的王者?的主要内容,如果未能解决你的问题,请参考以下文章