一致性哈希在大厂的应用
Posted 神技圈子
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了一致性哈希在大厂的应用相关的知识,希望对你有一定的参考价值。
一致性哈希在大厂的应用
作为k-v存储的开山鼻祖,Dynamo从亚马逊研发出来之后就在存储领域引起了轰动。理论上说Dynamo可以无限扩容,且性能是无限线性递增的(后面会将为啥理论上讲是无限线性增长)。Dynamo的动态伸缩让系统的scale-out能力极强。Dynamo延伸出dynamoDB作为nosql 领域的代表DB。Dynamo保证系统无限扩展且同时性能不下降的关键,是让整个存储集群没有中心节点,扩容的所有的节点都能负载均衡,跟集群里面的其他节点对等。要实现这样的能力,需要依赖一种数据的均匀分布的算法,该算法够随机并且在节点变动的时候,不能引起数据大面积失效(必须保证大部分数据在集群出现扩缩容时候不震荡)。这时分布式哈希表(DHT)就应运而生了。
01
数据是如何存储的

传统的哈希分布
讲DHT之前,我们先讲讲分布式集群里面数据会怎么存储。既然是分布式集群,那么数据是分布存储的,不会只存在一个节点上面。那么必然是需要一种存储的逻辑来控制数据是在集群里面的分布存的。举个例子,假设集群里面的有4个节点 node1 node2 node3 node4,要存的数据是存储 1 -20 这20个数字。那么你会怎么建立数据---》节点的存储关系?比较常用的是按节点数取模算法,按该算法数据分布如下:
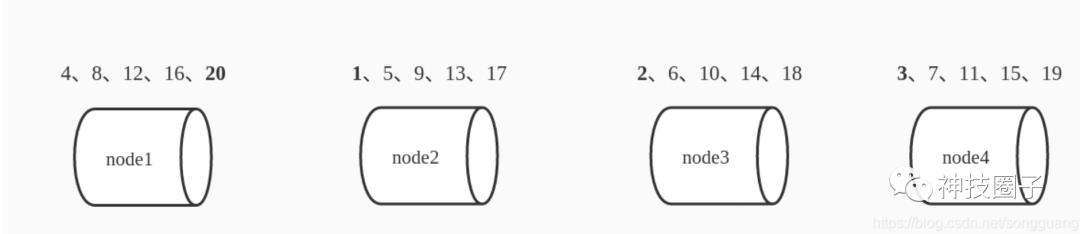
这个映射的关系就是数据n( 1=<n<=20) 按照 m = n%4 +1 存到下标是m的node中去。如果这时候集群里面的节点加一个,变成了node5 ,那么数据该怎么分布式了?
同样按照 m=n%5+1的原则 数据分布变成如下, 通过对比 4 节点到 5 节点数据的分布,发现其实只有4个数据还在原来的节点上,其他的数据分布完全变了,1-4/20=80% 。可以看到新加了一个桶后80%都变了,这就意味这哈希表的每次扩展和收缩都会导致条目分布的重新计算,这个特性在某些场景下是不能接受的。如下图所示

分布式存储系统中,图中的每个桶就相当于一个机器,文件分布在哪台机器由哈希算法来决定,这个系统想要加一台机器由哈希算法来决定,这个系统想要加一台机器时就需要停下来等所有文件重新分布一次才能对外提供服务,而当一台机器掉线的时候尽管只掉了一部分数据,但所有数据访问路由都会出问题,这样整个服务无法平滑地扩缩容,成了有状态的服务。那么怎么实现无状态化呢?今天的主角DHT算法就出现了。DHT 全称(Distributed Hash Table,分布式哈希表)。前面的取模算法之所以会导致数据分布震荡的原因是,数据分布逻辑随着节点的变化规则完全变了,不能让已分布的数据有较好的继承性(即数据依然大部分分布在原来的节点)。
典型的DHT模型有环形结构,会把所有输入key的hash值映射到一个环形的空间上面。我们还是来看上面的例子,数据 1-20 需要存储在四个节点上,环形空间用0-63(2的n次方-1,这里n=6)表示。这里 hash(key)范围属于(0-15] 则映射到node1,hash(key)范围属于(15,31] 则映射到 node2 , hash(key)范围属于(31,47] 则映射到node3,hash(key) 范围属于 (47,63] 则映射到node4 ,按照顺时针方向,数据的hash值放到下一个距离自己最近的node节点上。
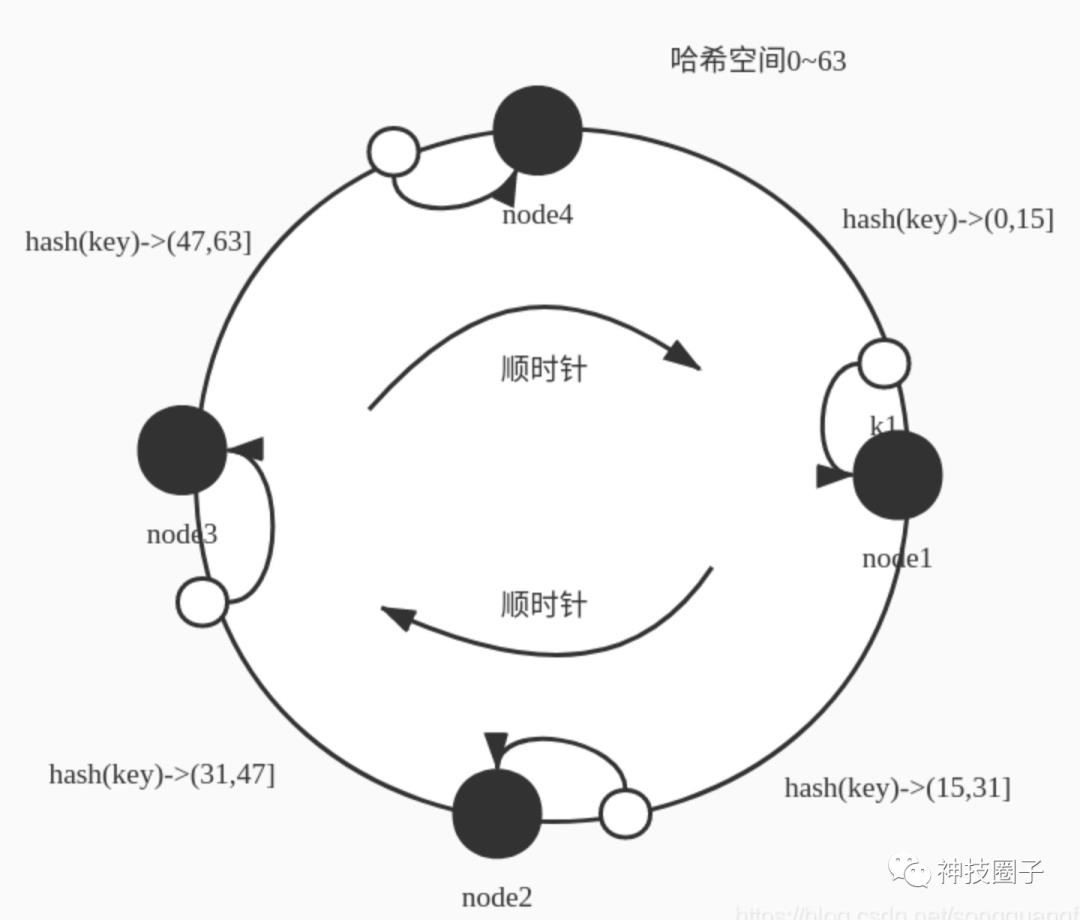
这时候如果加一个节点 node5,变成5个,hash范围还是0-63,则映射规则会变化,新加入的节点也要分摊一部分空间的映射。则可能的一种空间分配的方式,节点node5 添加到 node4 和node 1 之间,这时候的空间分配可能变成如下,范围属于(0-15] 则映射到node1,hash(key)范围属于(15,31] 则映射到 node2 , hash(key)范围属于(31,47] 则映射到node3,hash(key) 范围属于 (47,55] 则映射到node4 ,hash(key)范围属于(55,63] 映射到node5 如下图表示 :
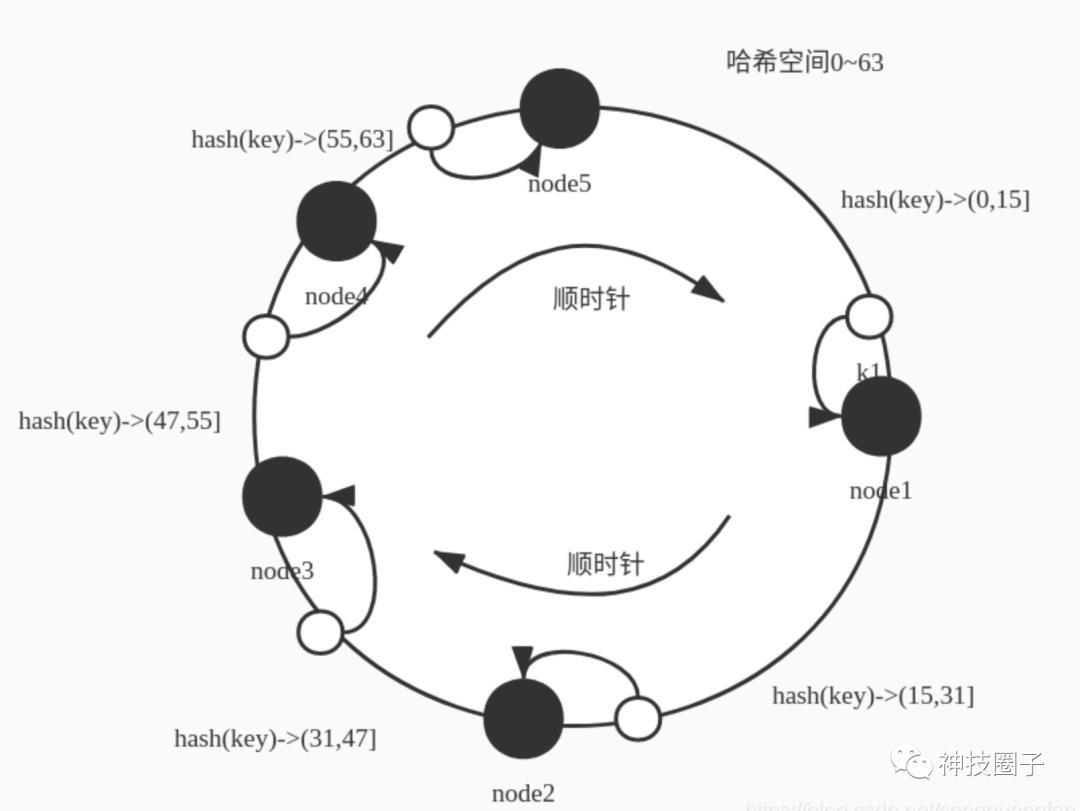
如果反之,这时候一个节点退出集群,少了一个节点。比如node3退出了,那么数据会如何分布?按照数据会按hash值按顺时针方向找距离自己最近的那个node节点存放,则范围属于(0-15] 则映射到node1,hash(key)范围属于(15,31] 则映射到 node2 , hash(key)范围属于(31,63] 则映射到node4 , node4的负载是其他节点2倍:如下图
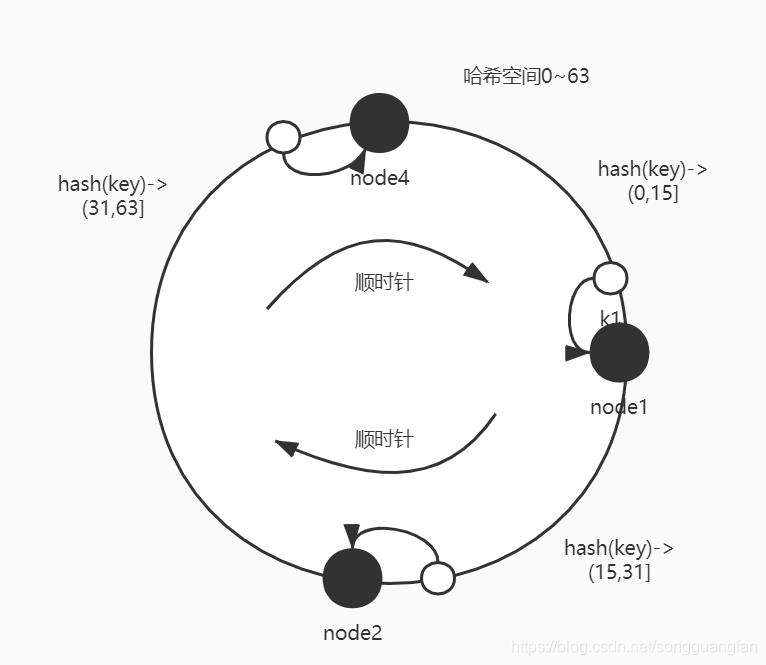
很明显的看到,新增了一个节点如果映射空间分配满,则1-8/64=87.5%的数据依然会分布在原来的节点上,减少了一个节点,则有1-16/64=75%分布在原来的节点上。数据的动荡范围大幅度降低。对比前后两种模式,大家就能感受到DHT算法做分布式数据分布的好处。第二种方式有没有啥问题?工程里面是这样直接使用的吗?下面会就工程里面的使用方式做优化。
02
DHT优化
首先的问题,一开始四个节点是把空间均匀分配的,加入个新节点后,node4 和 node5 分摊的空间明显比其他节点少了一半,减少一个节点node3之后,node4的分摊的空间又是其他节点的2倍。这就使得各个节点的负载能力不同了,各个节点的能力无法均衡。所以首先这里有一个问题,分摊空间的节点最好是不变的,不变那怎么增加节点或者删除节点呢?所以真正的工程应用上引申出logic节点的概念,又叫partition。空间一开始就按partition分配好,如把空间
映射到partition(每个partition用p表示)。
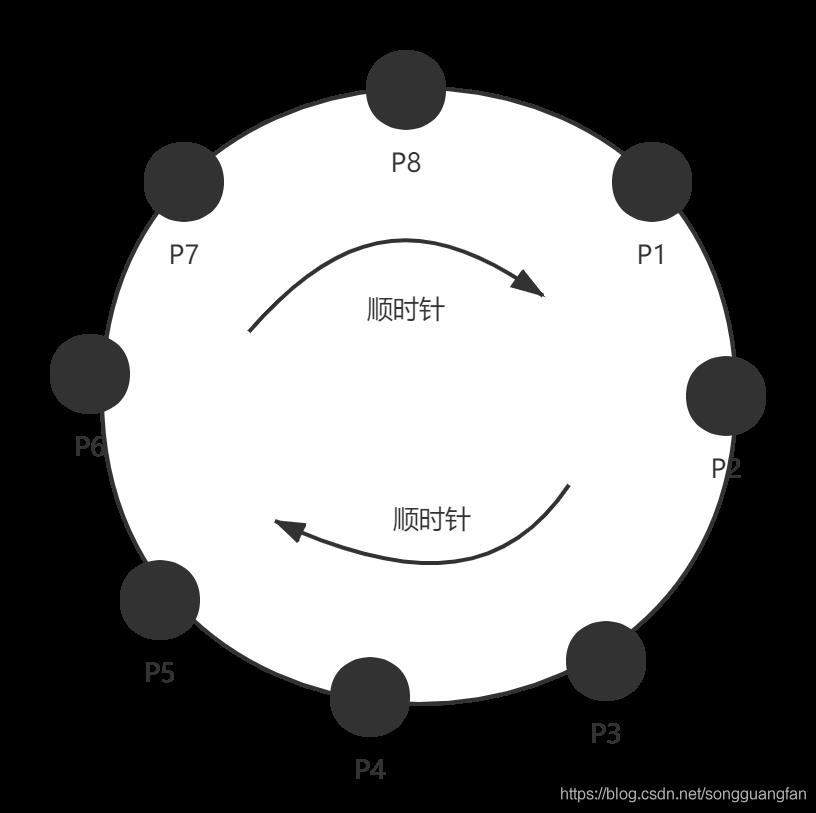
见上图把空间分成了8份。这8个逻辑空间是不会再变化的,然后就有一层逻辑节点到物理节点的映射关系,再以前4个物理节点为例,那么partition到node的映射关系如下图:
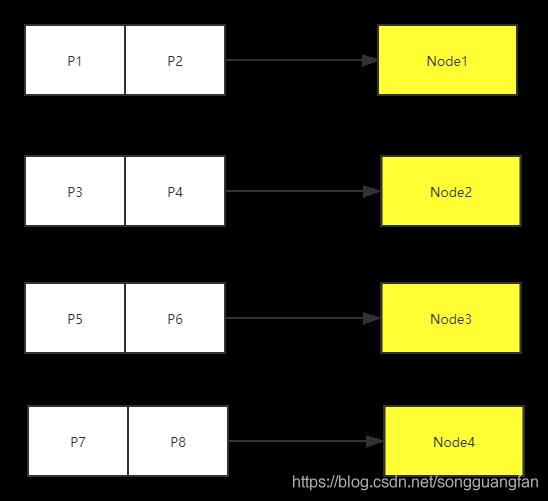
这时候如果新增一个节点node5,则映射关心将会变化,会从node2、node3上把partition迁移到node5上。这种叫做数据均衡算法,它是节点在出现变化时系统保持各节点负载均衡的一种机制,这个算法会对系统可靠性以及性能影响很大。
从上图的增加节点数据重新迁移分配可以看出,partition必须足够多,不然各个物理节点负载能力还是会有比较大的差异(比如上图,迁移后,node2和node3的负载不其它节点少了一半)。
一般在工程应用里面增加或者退出节点的时候,系统是会对业务IO做降级处理的,优先保障数据的均衡完成。因为存储产品的工程应用里面选择了CAP的AP两个点,从而实现最终一致性。
本章对一致性哈希进行了讲解,后续将介绍在分布式存储系统中,数据是如何保证可靠性以及一致性的。
~ 神技圈子 ~
带你一起成长
为大厂后端工程师
以上是关于一致性哈希在大厂的应用的主要内容,如果未能解决你的问题,请参考以下文章