基于GitBook框架搭建技术文档平台
Posted dotNET跨平台
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了基于GitBook框架搭建技术文档平台相关的知识,希望对你有一定的参考价值。

源宝导读:为了向用户更好的传递ERP开放平台的价值与技术知识,我们基于GitBook框架搭建了一个文档中心站点,本文将介绍此站点的设计与实现过程。
一、项目架构图
因为文档会涉及到很多的产品线,所以目前主要是通过拉取各个产品线的文档仓库,进行合并编译生成方式构建处理,整个的架构和执行流程如下:
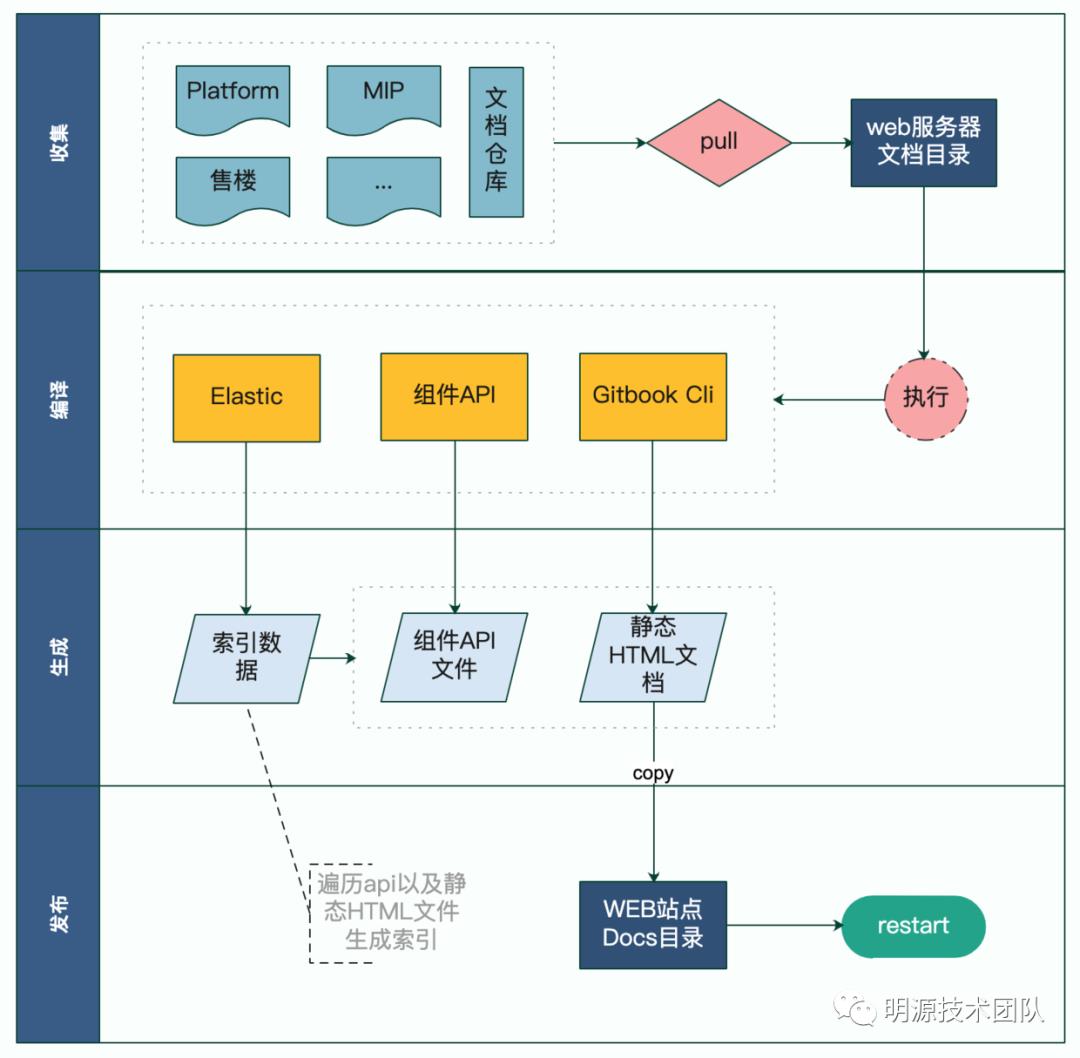
1.1、收集阶段
首先产品需要按照约定好的目录格式建立文档仓库,然后再新增markdown文件书写文档内容,最后提交发布到远程。在服务器端会间隔一段时间周期性的获取远程仓库文档,然后进行后续的编译与生成。
1.2、 编译阶段
当用户将更新的文档推送到远程仓库后,服务器拉取最新的仓库文档,并且启动编译命令,首先调用gitbook build命令来编译文档,每次执行前都会安装最新的主题插件,保证生成的文档都是最新的,执行完毕后将在对应目录下生成编译后的html静态文件。完毕后再会执行npm run build-api来处理平台组件api以及后端接口事件的编译,完毕后会生成可被重复使用的单个接口文件,目的是便于后续查询更加快速。
1.3、 生成阶段
上面数据编译完毕后,会生成相对比较友好的数据格式,此时就需要对这些生成的文件重新生成ElasticSearch的索引,生成索引的目的是为了后续文档搜索调用ElasticSearch的webApi来对文章进行过滤,获取搜索结果。索引完毕后,可以安装elasticsearch-head插件,完毕后可以通过浏览器打开页面在网页上查看生成的结果。
1.4、 发布阶段
当文档和索引生成完毕之后,最后会将文档生成的静态html文件拷贝到开放平台站点static/docs目录中,同时重新启动站点,至此完成站点文档的更新。
二、技术栈
Gitbook
GitBook是一款文档编辑工具,目前主要用来编写文档,同时他还有一些很好的特性能够满足当前的需求,如:
支持Git,一个分布式的文档编辑工具。可多人共同编写文档。
可以通过命令一键打包成静态站点部署到web服务器。
由于采用的是md格式文件存储,现在有许多比较成熟的可视化编辑器,对于写作人员非常友好。
可通过插件模式,来自定义主题风格,满足定制化诉求,具体插件使用可参考http://gitbook.hushuang.me/plugins/create.html。
Nuxt
Nuxt是一个基于Vue.js的通用应用框架,预设了利用Vue.js开发服务端渲染的应用所需要的各种配置。可以将html在服务端渲染,合成完整的html文件再输出到浏览器。目前平台的主要使用的是vue开发应用,所以上手比较容易,内部易于沟通交流。
JsDoc
JSDoc是一个根据javascript文件中注释信息,生成JavaScript应用程序或库、模块的API文档的工具。平台内部的组件库以及相关工具库接口都是按照JsDoc规范书写的,集成方便,可维护性高,也是业内主流的方式之一。
ElasticSearch
Elasticsearch是一个开源的分布式、RESTful 风格的搜索和数据分析引擎,他提供了许多的webApi接口,对于前端开发使用很友好,同时相关的文档也比较丰富,学习起来不会很盲目,同时部署也比较方便。
项目中还是用其他相关技术,如nodejs、vue、grunt…在此不一一介绍了。
三、生成文档
通过一系列的编译处理,最终将用户书写的文档生成为内部可以持续使用的数据或者文件,具体如下:
3.1、创建文档仓库
首先产品需要建立好自己的文档仓库,然后按照Gitbook的书写规范(http://gitbook.hushuang.me/structure.html)编写自己的业务文档,最后推送到仓库即可,仓库目录结构如下:
SLXT // 产品目录名称src // 书写markdown文件的目录hello-world.md // 文档markdown文件book.json // gitbook配置文件,通常不会调整package.json // 依赖包文件README.md // 帮助指引文件SUMMARY.md // 文档目录md文件
3.2、合并文档仓库
开放平台需要将所有的产品文档仓库拉取到本地,并按照一定的策略进行合并处理,最后在编译生成为静态文件进行同步更新,目前主要合并两块内容:
3.2.1、合并文档目录
各个文档仓库按照约定好的目录结构在仓库根目录下书写正确的SUMMARY.md目录文件,结构如下:
# Summary* 成本系统* 标准扩展接口* [合同登记](/src/biao-zhun-kuo-zhan-jie-kou/he-tong-deng-ji.md)* [新增合同](/src/biao-zhun-kuo-zhan-jie-kou/he-tong-deng-ji/xin-zeng-he-tong.md)* [编辑合同](/src/biao-zhun-kuo-zhan-jie-kou/he-tong-deng-ji/bian-ji-he-tong.md)* [合同审批](/src/biao-zhun-kuo-zhan-jie-kou/he-tong-deng-ji/he-tong-shen-pi.md)* [合同审批中修改](/src/biao-zhun-kuo-zhan-jie-kou/he-tong-deng-ji/he-tong-shen-he-zhong-bian-ji.md)* [设计变更](/src/biao-zhun-kuo-zhan-jie-kou/she-ji-bian-geng.md)...
由于开放平台的文档目录都是由平台管理的,所以在平台的文档目录下面会约定好各个产品文档对应的目录位置,如:
# Summary* 平台文档* 基础知识* [开发基础知识](/src/zi-yuan-yu-gui-fan/tong-yong-ji-shu.md)* DevOps概念及Git基本操作* [Git基本操作](https://open.mingyuanyun.com/docs/rdc/kuai-su-ru-men/git-ji-ben-cao-zuo.html)* 平台整体介绍* [开放平台技术白皮书](/src/ping-tai-zheng-ti-jie-shao/kai-fang-ping-tai-bai-pi-shu.md)....* [集成平台](mip)* [研发协同平台](rdc)* [流程中心](wd_lczx)* [工作流](gzl)* 业务文档* [售楼系统](slxt)* [成本系统](cbxt)....
上面类似[集成平台](mip)这样的标识会在编译的时候替换为产品文档目录SUMMARY.md中的内容,并将产品目录内的/src路径替换成实际产品的简称,如/src -> /cbxt
3.2.2、合并文档文件
合并完目录后,我们还需要将产品的文档全部拷贝到临时的文档目录中,暂且称为docs目录,同时还需要将通用的gitbook的book.json以及刚刚合并的SUMMAYR.md拷贝进去,合并后的临时docs目录如下:
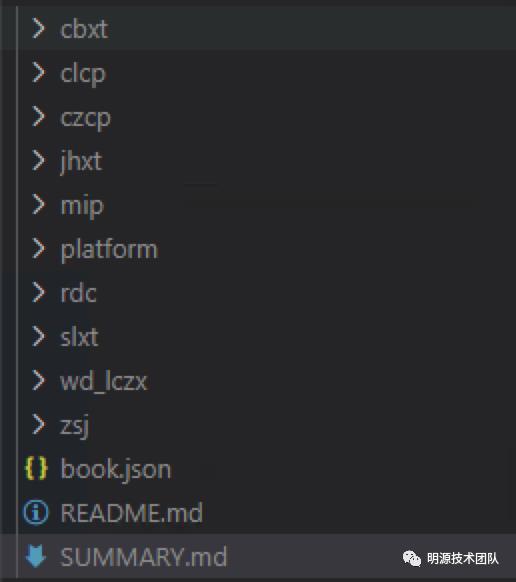
最后通过执行gitbook generate生成静态的html文档。
通过这种方式就可以有效的解决合并产品文档的问题,也满足了平台管理整个开放平台文档目录的诉求。
3.3、索引文档中的内容
现在有了大量的产品文档,在实际使用的时候,用户需要根据关键词去搜索文档,基于这个场景,引入了开源的ElasticSearch搜索引擎,目前主要有两个步骤:
3.3.1、识别并索引静态文档中的特殊标记内容
借助于cheerio第三方库,可以很容易的从已生成的文档html文档中拿到需要的标签内容,如:
const cheerio = require('cheerio')...// 读取静态html文件内容const fileContent = fs.readFileSync(options.filePath, 'utf8')if (!fileContent) {return Promise.resolve()}let $ = cheerio.load('<div id="_content_">' + fileContent + '</div>')// 匹配第一个h1的标签内容const title =$('h1').first().text() || ''// 匹配blockquote标签内容const description = $('blockquote').text() || ''return {title,description}
提取到h1以及blockquote中的内容后,可以给后续ElasticSearch生成索引使用。
3.3.2、批量生成文档搜索索引
获取到文档提取的特征内容后,调用ElasticSearch创建索引的接口,完成对文档的索引,代码片段如下:
ElasticSearchClientInstance.index({index: options['index'],type: options['type'],body: {title: '前端数值计算', // 文章标题system: '建模平台', // 所属系统url: '', // 生成的url地址description: '日常开发中,我们经常遇到浮点数计算不准确问题,为此平台提供了mapnumber数值计算库,用来解决数值计算不准确的问题', // 文档描述,尽量贴近关键词,便于搜索content: '...', // 文章内容summary: '...', // 文章摘要},},function(error) {if (!error) {console.log(title + '生成成功')}resolve()})
当索引重新生成后,后面用户在搜索文档的时候,通过根据搜索关键词调用ElasticSearch提供的搜索API接口,即可返回搜索后的结果数据集合,相关代码如下:
function search ({ keyword, pageSize, pageIndex, index, system }) {let operator = 'and'if (keyword.match(/[\s +]/)) {operator = 'or'}// 查询条件let query = {bool: {must: {multi_match: {...}},filter: {term: {system}}}}// 处理分页const from = pageIndex * pageSize// 执行搜索const { hits } = ElasticSearchClientInstance.search({size: pageSize,from,index,body: {query}})...}
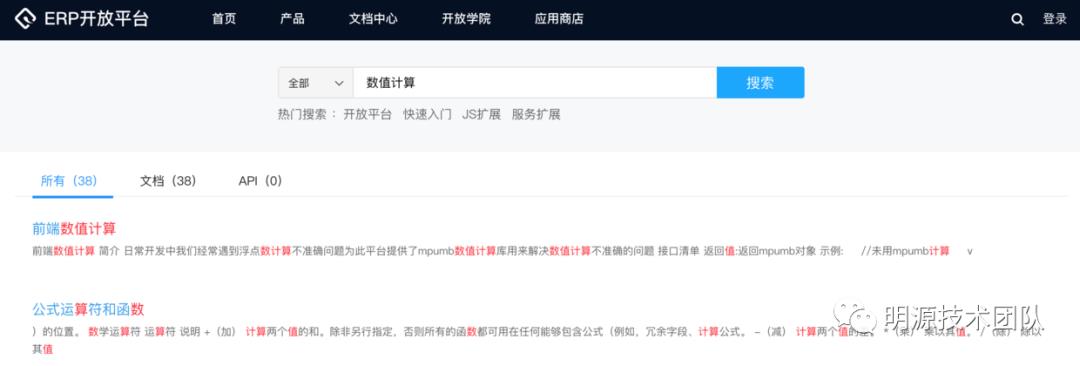
最终用户使用的时候,输入关键词即可完成搜索,如图:
四、创建文档主题插件
GitBook插件是在NPM上发布的遵循定义的约定的节点包,所以可以很好的满足我们多个产品文档同时应用同一个主题包的诉求,下面简单说明如何创建以及发布Gitbook插件。
注意:GitBook从3.0版本开始支持自定义主题。
4.1、主题插件参考目录结构
开放平台GitBook主题插件的目录结构如下:
gitbook-plugin-theme-document_assets // 静态资源文件目录_layouts // 布局模板文件目录index.js // 主题入口配置文件package.json // 包描述文件README.md // 项目说明文件
4.2、定义插件package.json
标准的npm包描述文件,注意如果是主题插件包名称需要以gitbook-plugin-theme作为前缀命名,结构如下:
{"name": "gitbook-plugin-theme-doc","dependencies": {},"description": "文档描述","license": "ISC","main": "index.js","readmeFilename": "README.md","engines": {"gitbook": ">=3.0.0"},"scripts": {"test": "echo \"Error: no test specified\" && exit 1"},"version": "1.0.0"}
4.3、主题插件运行时入口
主要是定义主题插件编译时的配置信息,下面简单介绍常用的配置:
// index.jsmodule.exports = {// 站点配置website: {assets: './_assets/', // 插件静态资源目录地址js: [ // 站点引用的js文件,相对assets目录'xxxx.js'],css: ['xxxx.css' // 站点引用的css文件,相对assets目录]},// 后面还有关于插入自定义逻辑或增强插件的钩子以及块,这里不做详细介绍,具体可参阅http://gitbook.hushuang.me/plugins/create.html...}
4.4、调整主题布局
有些场景下需要对生成的模板进行个性化调整,如调整导航菜单的结构,那么这个时候可以进入./_layouts/website/page.html模板进行相关的调整,gitbook内置了很多的上下文变量来提供给模板使用,如需要访问导航数据并对导航模板结构进行处理,可参考如下处理:
...<ul class="doc-header-nav"><!--循环输出导航-->{% for mainNav in book.navigation %}<!--如果配置了链接输出A标签,否则输出SPAN标签-->{% if mainNav.url %}<a href="{{mainNav.url}}" target="{{ mainNav.target}}">{{ mainNav.text }}</a>{% else %}<span>{{ mainNav.text }}</span>{% endif %}<!--如果是个菜单导航,那么输出子级-->{% if mainNav.children %}<span class="doc_trangle"></span><ul class="doc-header-nav__sub">{% for subNav in mainNav.children %}<li><a href="{{subNav.url}}" target="{{ subNav.target}}">{{ subNav.text }}</a></li>{% endfor %}</ul>{% endif %}</li>{% endfor %}</ul>...
具体的模板变量可参考gitbook变量(http://gitbook.hushuang.me/ templating/variables.html),同理对于文档目录的个性化处理也可以参考这个方式去做。
4.5、发布主题
通过以上步骤创建了自定义主题,这个时候就可以发布主题了,主题以theme-前缀插件方式发布。例如,主题doc将从theme-doc插件加载,然后从gitbook-plugin-theme-doc NPM包加载。
4.6、使用自定义主题插件
发布主题后,在创建gitbook的项目中,通过更改book.json中的plugins来引入自定义的主题插件,如下:
// book.json"title": "开放平台文档","plugins": ["theme-doc" // 增加theme-doc的插件依赖],"pluginsConfig": {},....
每次执行gitbook install命令后会自动安装主题插件,并引用到当前文档项目中。
五、自定义主页
门户站点使用Nuxtjs开发,得益于Nuxtjs的机制,可以很容易的实现产品定制化主页的开发诉求,而且开发上手容易,成本不高,下面以MIP主页为例简单说明一下开发步骤:
5.1、新增主页页面
拉取开发平台仓库后,在site目录下面新增产品主页目录及文件,如图:
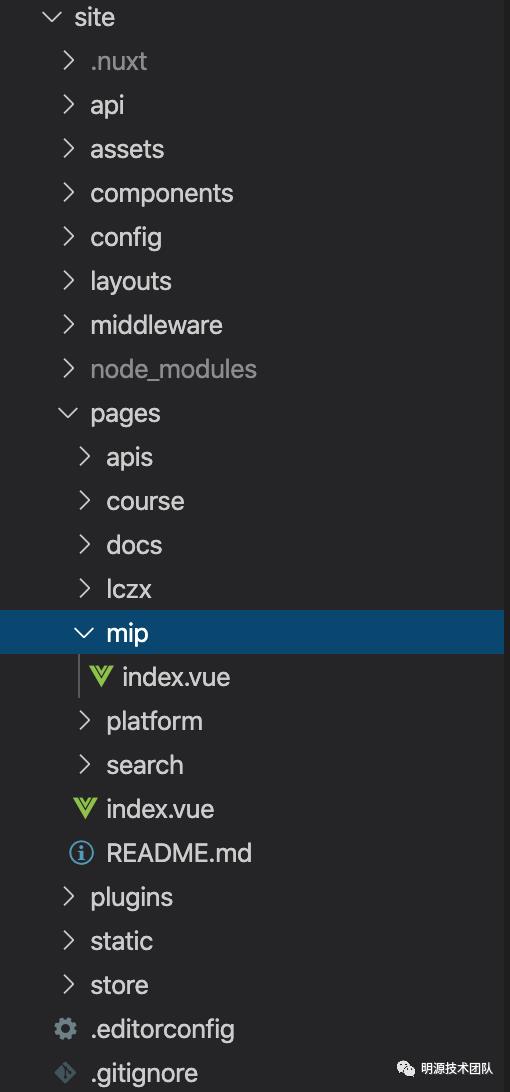
这里新增了mip的文件夹,同时在文件夹中新建了index.vue文件,因为Nuxtjs的默认路由是根据目录结构定义好的,所以刚刚新增的产品文件夹最终会生成/mip路由,访问http://localhost: 3000/mip就能显示新增的主页。
5.2、调整主页布局样式
Nuxtjs是基于vue的后端渲染引擎,所以整个模板语法都是和Vue保持一致的,并且也是支持单文件模式,示例如下:
// ~ site/mip/index.vue<template><!--在这里可以直接写页面的布局--><div class="page-mip">MIP主页</div></template><script>// 此处写页面的逻辑export default {name: 'PageMip',data () {return {...}},computed: {...},methods: {...}}</script><style>/*** 页面的样式*/.page-mip{...}</style>
注意:因为Nuxtjs是默认根据pages里面的结构生成路由的,所以pages里面都应该是页面维度的组件,不能把页面拆分为多个细粒度的模块进行组合,否则会生成不符合预期的路由,遇到这种情况可以在sites下面创建components解决此问题。
5.3、使用静态资源
页面中会使用大量的图片或者其它的媒体资源,这个时候可以通过将资源文件放到sites/static/目录下,通过绝对路径的方式访问,如:
在模板中可以通过以下方式使用:
<template><img src="/images/conact_us/conact_us_1.svg"></template><style>.page-mip{background-image: url('/images/conact_us/conact_us_1.svg');}</style>
更多关于Nuxtjs的使用文档,可参考Nuxtjs官方中文文档(https://zh.nuxtjs.org/guide/ #nuxt-js-%E6%98%AF%E4%BB%80%E4%B9%88-)。
六、API生成机制
组件api文档采用的是现在流程的jsDoc生成,它通过识别代码中约定好的注释生成可被后续重复使用的json数据,最后通过编译生成html展现给用户阅读。
6.1、约定注释规范
在写组件或者工具库的api时候都会带上符合jsDoc规范的注释,下面列举一些常用的注释标记:
:标明函数是一个构造器函数,意味着需要使用 new 关键字来返回一个实例:作为对象的一个函数类型成员:描述一个可触发的事件:指定要描述参数的名称。还可以包含参数的数据类型:标记是否是公开的:记录一个函数的返回值
实际使用示例如下:
/*** 格式化数字* @public* @function* @param {Number} val 要格式化的数字* @param {String} format 格式字符串,`#,###.000`:保留三位小数,`#,###`:没有小位数* @example* utility.formatNumber(123123123.123, '#,###.000') // 返回值:123,123,123.123* utility.formatNumber(123123123.123, '#,###.00') // 返回值:123,123,123.12* @return {String} 转换后的字符串*/function formatNumber () {...}
想了解更多jsDoc的使用规范,可以参考jsDoc中文文档(https://www.html.cn/doc/ jsdoc/tags-example.html)。
6.2、编译生成API数据
借助jsDoc提供的编译库,可以遍历项目中指定的文件进行解析,最终会得到api.json的文件。文件的内容结构大致如下:
[{"description": "<p>设置模式</p>", // 接口描述"kind": "function", // 接口类型,可以为class、var、function"longname": "AddressSelect#setMode", // 接口完整名称"name": "setMode", // 接口名称"memberof": "AddressSelect", // 接口所属父类"params": [{ // 接口参数"type": {"names": ["Number"]},"description": "<p>要设置的模式值</p>","name": "mode"}],"examples": ["//设置编辑模式\rAddressSelect.setMode(2);\rAddressSelect.getMode(); //return 2;\r//设置查看模式\rAddressSelect.setMode(3);\rAddressSelect.getMode(); //return 3;"] // 接口示例},...
生成好数据后,接下来可以对数据进行进一步处理。
6.3、生成细粒度的API模块文件
jsDoc生成的api.json文件数据尺寸非常大,在实际使用的时候需要根据当前api所属的类拆分为小的模块文件,当请求某个组件的api接口列表的时候,后台服务只需要根据请求的参数从api目录中获取到对应的文件,同时将数据返回给前端,生成的api数据文件如下:
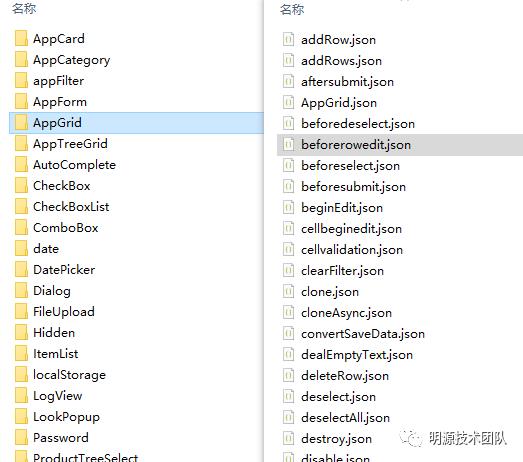
通过拆分大文件为小文件方式,减轻实际请求中的解析性能问题,加快前端用户使用的体验。
6.4、API应用页面展示
根据上述步骤,现在有了比较合理的api数据文件,此时在前端界面中会显示api的菜单列,如图:
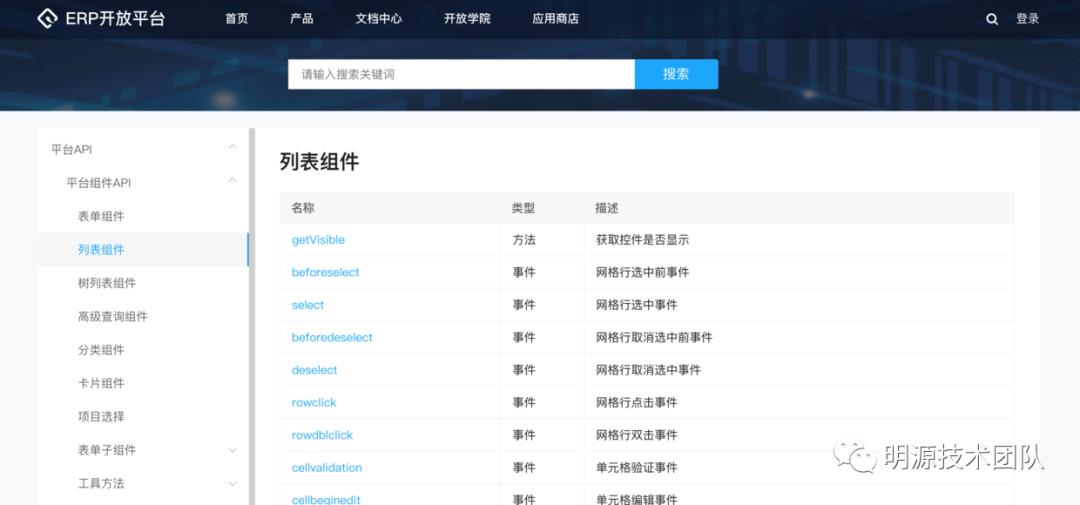
当用户点击接口时,会将当前用户点击的接口信息发送给后端请求,后端请求根据生成的api文件目录结构,获取到对应的接口数据返回给前端,前端再来渲染出来。
注意:目前仅平台支持组件api文档,产品暂不支持。
七、如何跨应用组件公用
文档项目目前存在门户站点以及文档站点两个独立的应用,其中文章反馈不仅在业务文档中使用了,同时在api文档中也需要,这个时候通过vue cli自动的组件lib打包方式,可以将通用的组件发布为内部的npm包,供两个应用使用,在vue cli中的配置如下:
// vue.config.jsmodule.exports = {// 修改 src 为 examples,可以对组件进行测试pages: {index: {entry: 'examples/main.js',template: 'public/index.html',filename: 'index.html'}},// 强制内联CSScss: {extract: false},...}// package.json{"name": "doc-platform-component",..."scripts": {"serve": "vue-cli-service serve","build": "vue-cli-service build","lint": "vue-cli-service lint","lib": "vue-cli-service build --target lib --name docComponent --dest lib packages/index.js" // 指定打包方式为lib方式},...}
后面执行npm run build生成组件lib文件,结果如图:
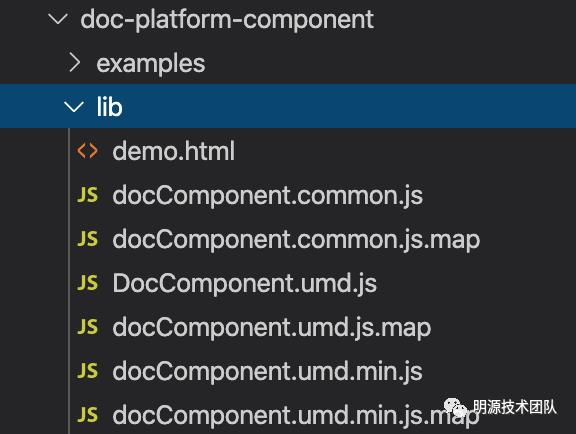
编译完毕后,在通过npm publish 发布内部组件包,供其他应用使用。
关于编译配置具体的使用方式参见构建目标-库(https://cli.vuejs.org/zh/guide/build-targets.html#%E5%BC%82%E6%AD%A5-web-components-%E7%BB%84%E4%BB%B6),这种方式的好处是,配置简单,上手容易,且为官方提供的方式,不需要额外的依赖项,对于简单的应用维护成本也低。
八、收集用户反馈
文档的持续优化和更新需要用户的及时反馈,在每篇文档中提供了用户提交反馈的表单,同时这个组件也是跨应用的通用组件,最终效果如图:
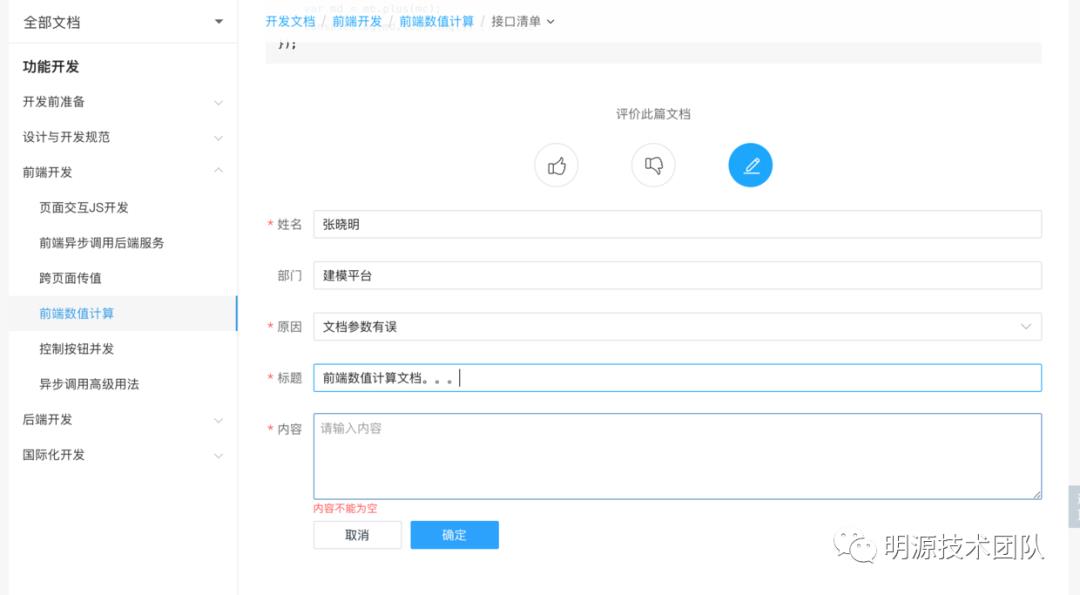
用户点击提交后,实际上是在jira系统中针对开发平台项目登记了一条反馈,此时管理人员通过登录jira系统,即可对这个反馈进行相关的处理,在实现层面只需要如下方式即可接入jira系统提供的api:
// 生成请求的tokenconst token = 'xxxxxbbbbbcccccddddd=='// 调用jira开放的新增issue接口const request({method: 'POST',url: 'https://jira.mingyuanyun.com/rest/api/2/issue',headers: {'cache-control': 'no-cache','Authorization': `Basic ${token}`,'Content-Type': 'application/json'},body: JSON.stringify({fields: {project: {id: 'xxxx'},issuetype: {id: 'xxxx'},components: [{id: 'xxxx'}],customfield_10204: 'xxxx',summary: `反馈标题`,description: '反馈内容'}})})
注意:使用jira的接口,需要生成好token,并且写入请求的headers里面。
总结
使用Gitbook以及nuxtjs方式打包构建生成静态站点,通过git来管理文档的提交以及用户权限,目前来看主要的优势是开发成本比较低,对于前端开发也比较友好,很多的知识点也再可接受的范围内,后续扩展功能相对比较容易,比如后续增加的几个产品页面都是基于nuxt良好的机制很快的开发完毕的。
随着文档的数量越来越多,每次全量打包编译导致整个构建环节时间逐渐增加,也是后面需要优化的环节,可以通过拉取git变更集,分析出需要重新编译的文件进行增量更新,提升这块的性能。
在文档搜索这块由于前期对ElasticSearch这块经验的不足,有些文章并不能很好的被精准搜索到,后续可以通过以下几个方式进行一定优化,如:
加强对文章的书写规范要求,文章的描述和子标题中应尽可能的多带有和当前文章贴近的语义关键词。
针对文章不同的片段在过滤时增加不同级别的权重,可以为主标题权重最高、子标题其次、再就是描述中的关键词,最后是文章内容,通过增加不同的权重设置可以对搜素结果进行按权重排序。
针对中文可以安装中文的分词插件,优化中文分词规则,使搜索结果更友好。
未来在文档这块可以采取线上编写以及发布更新方式,这样的好处是用户不需要在本地安装一些开发工具来编写以及预览文档了,同时所有用户的体验也是一致性,当然最主要的是文档的更新也是实时的,不需要再定时去构建了,相信随着后面的不断优化,文档这块能越来越好。
------ END ------
作者简介
杨同学: 研发工程师,目前负责ERP建模平台的设计与开发工作。
也许您还想看
以上是关于基于GitBook框架搭建技术文档平台的主要内容,如果未能解决你的问题,请参考以下文章