大数据处理工具KafkaZkSpark
Posted 平凡人笔记
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了大数据处理工具KafkaZkSpark相关的知识,希望对你有一定的参考价值。
搭建kafka和zk集群环境
安装环境
MAC操作系统
VMware Fusion虚拟机
3个centos7服务器
安装虚拟机 飞机票
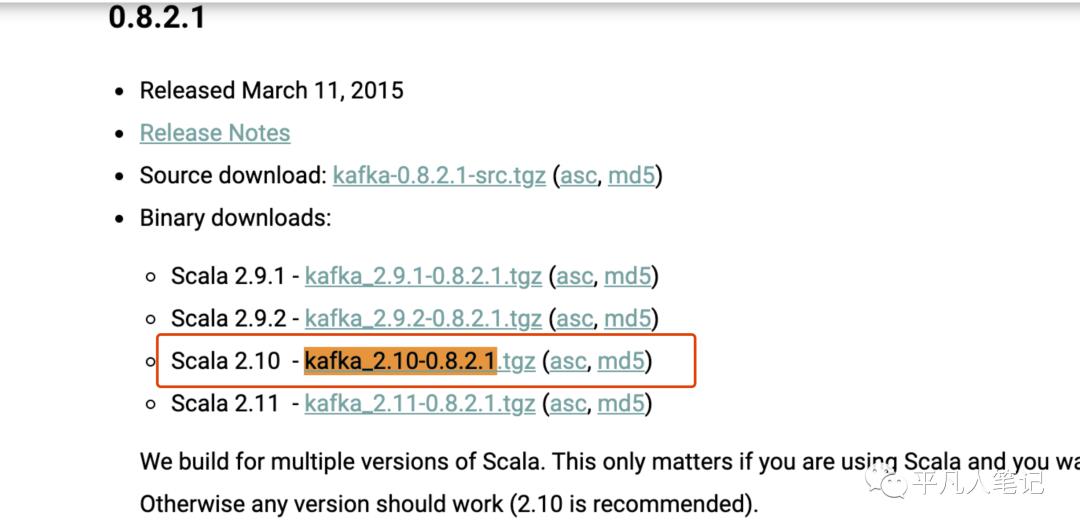
安装包下载
https://kafka.apache.org/downloads.html
服务器环境准备
-
安装文件上传工具
yum install lrzsz
-
查看服务器ip
ip addr show
centos-1 192.168.84.128
centos-2 192.168.84.129
centos-3 192.168.84.130
-
通过ssh工具连接

这个工具很好用

先安装下centos-1服务器环境
-
上传kafka安装包
mkdir /opt/kafka
通过rz将压缩包上传kafka_2.10-0.8.2.1.tgz
解压tar xvf kafka_2.10-0.8.2.1.tgz
-
创建zk目录
创建zk数据目录 并设定服务器编号
mkdir /opt/zk_data
cd /opt/zk_data
vi myid
该文件内容为1、2、3分别对应centos-1、centos-2、centos-3
配置zk
kafka安装包中内置zk服务
-
配置zookeeper.properties
vi /opt/kafka/kafka_2.10-0.8.2.1/config/zookeeper.properties
# zk服务器之间的心跳时间间隔 以毫秒为单位
tickTime=2000
# zk 数据保存目录 zk服务器的ID文件也保存到这个目录下
dataDir=/opt/zk_data/
# zk服务器监听这个端口 然后等待客户端连接
clientPort=2181
# zk集群中follower服务器和leader服务器之间建立
# 初始连接时所能容忍的心跳次数的极限值
initLimit=5
# zk集群中follower服务器和leader服务器之间请求和应答过程中所能容忍的心跳次数的极限值
syncLimit=2
# server.N N代表zk集群服务器的编号
# 服务器IP地址:该服务器于leader服务器的数据交换端口:选举leader服务器时用到的通信端口
server.1=192.168.84.128:2888:3888
server.2=192.168.84.129:2888:3888
server.3=192.168.84.130:2888:3888
配置kafka
-
配置kafka broker
mkdir /opt/kafka/kafka-logs
vi /opt/kafka/kafka_2.10-0.8.2.1/config/server.properties
#kafka broker的唯一标识 集群中不能重复
broker.id=0
# broker监听端口 用于监听producer或者consumer的连接
port=9092
# 当前broker服务器 ip地址或机器名
host.name=192.168.84.128
#broker作为zk的client 可以连接的zk的地址信息
zookeeper.contact=192.168.84.128:2181,192.168.84.129:2181,192.168.84.130:2181
# 日志保存目录
log.dirs=/opt/kafka/kafka-logs
-
配置broker地址列表
vi /opt/kafka/kafka_2.10-0.8.2.1/config/producer.properties
# 集群中的broker地址列表
broker.list=192.168.84.128:9092,192.168.84.128:9092,192.168.84.128:9092
# Producer类型 async 异步生产者 sync 同步生产者
producer.type=async
-
配置consumer
vi /opt/kafka/kafka_2.10-0.8.2.1/config/consumer.properties
# consumer可以连接的zk服务器地址列表
zookeeper.contact=192.168.84.128:2181,192.168.84.128:2181,192.168.84.128:2181
打包配置好的kafka安装包并上传到其他服务器
tar cvf kafka_2.10-0.8.2.1.tar ./kafka_2.10-0.8.2.1
得到kafka_2.10-0.8.2.1.tar
scp ./kafka_2.10-0.8.2.1.tar root@192.168.84.129:/opt/kafka
scp ./kafka_2.10-0.8.2.1.tar root@192.168.84.130:/opt/kafka
传到centos-2和centos-3之后
分别操作
解压
tar xvf kafka_2.10-0.8.2.1.tar
vi /opt/kafka/kafka_2.10-0.8.2.1/config/server.properties
文件中的 broker.id 和 host.name
broker.id,可以分别复制 1 和 2
host.name 需要改成当前机器的 IP
安装jdk1.8
每个服务器都需要安装java环境
-
切换阿里云源
mv /etc/yum.repos.d/CentOS-Base.repo /etc/yum.repos.d/CentOS-Base.repo.backup
wget -O /etc/yum.repos.d/CentOS-Base.repo http://mirrors.aliyun.com/repo/Centos-7.repo
或者
curl -o /etc/yum.repos.d/CentOS-Base.repo http://mirrors.aliyun.com/repo/Centos-7.repo
-
清除缓存
yum makecache
-
备注
OpenJDK Development Environment:开发版本带JDK
不要下载 Open JDK runtime Environment只有JRE
-
安装jdk1.8
yum -y install java-1.8.0-openjdk-devel.x86_64
安装路径
/usr/lib/jvm/java-1.8.0-openjdk-1.8.0.272.b10-1.el7_9.x86_64
-
全局环境变量配置
vi /etc/profile
export JAVA_HOME=/usr/lib/jvm/java-1.8.0-openjdk-1.8.0.272.b10-1.el7_9.x86_64
export PATH=$JAVA_HOME/bin:$PATH
export CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
. /etc/profile
关闭防火墙
报错信息:
2020-09-14 03:28:23,562 [myid:0] - WARN [WorkerSender[myid=0]:QuorumCnxManager@588] - Cannot open channel to 3 at election address h6/192.168.1.16:3888
java.net.ConnectException: 拒绝连接 (Connection refused)
此时需要关闭防火墙
sudo systemctl stop firewalld #临时关闭
sudo systemctl disable firewalld #然后reboot 永久关闭
sudo systemctl status firewalld #查看防火墙状态
分别启动zk
mkdir /opt/kafka/run
mkdir /opt/kafka/run/kafka
mkdir /opt/kafka/run/zk
cd /opt/kafka/run/zk
nohup /opt/kafka/kafka_2.10-0.8.2.1/bin/zookeeper-server-start.sh /opt/kafka/kafka_2.10-0.8.2.1/config/zookeeper.properties &
分别启动kafka
cd /opt/kafka/run/kafka
nohup /opt/kafka/kafka_2.10-0.8.2.1/bin/kafka-server-start.sh /opt/kafka/kafka_2.10-0.8.2.1/config/server.properties &
查看kafka和zk进程是否启动
ps -ef | grep kafka
验证kafka、zk环境是否可用
创建消息主题
/opt/kafka/kafka_2.10-0.8.2.1/bin/kafka-topics.sh --create
--replication-factor 3
--partition 3
--topic user-behavior-topic
--zookeeper 192.168.84.128:2181,192.168.84.129:2181,192.168.84.130:2181
通过console producer生产消息
启动console producer
/opt/kafka/kafka_2.10-0.8.2.1/bin/kafka-console-producer.sh --broker-list 192.168.84.128:9092 --topic user-behavior-topic
通过console consumer消费消息
在另一台机器打开consumer
/opt/kafka/kafka_2.10-0.8.2.1/bin/kafka-console-consumer.sh --zookeeper 192.168.84.129:2181 --topic user-behavior-topic --from-beginning
如果在producer console输入一条消息 能从consumer console看到这条消息就代表安装是成功的
centos-1 生产消息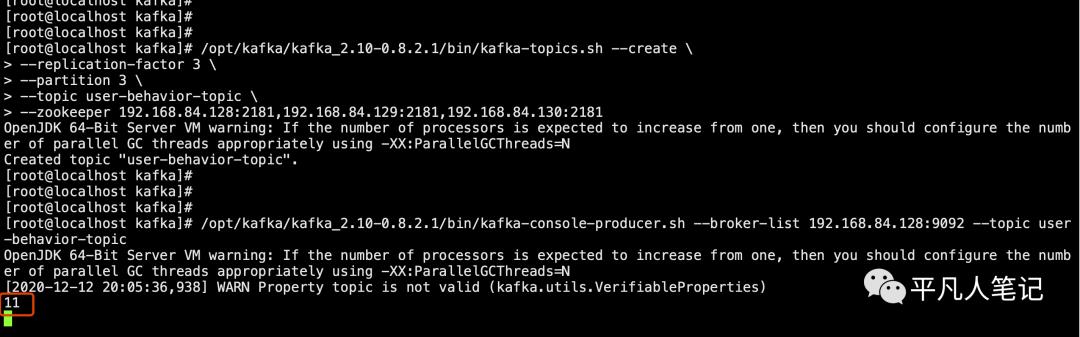
centos-2 消费消息
说明kafka和zk集群环境是可用的
Spark
安装包下载
https://www.apache.org/dyn/closer.lua/spark/spark-3.0.1/spark-3.0.1-bin-hadoop2.7.tgz
tar xvf spark-3.0.1-bin-hadoop2.7.tgz
依赖条件
jdk1.8
python 2.7.5
部署方式
1、 底层资源调度可以依赖外部的资源调度框架:相对稳定的Mesos、Hadoop YARN模式
2、使用spark内建的standalone模式
-
Local[N]本地模式 使用N个线程
-
Local Cluster[Worker,core,Memory]
伪分布式 可以配置所需要启动的虚拟工作节点的数量
以及每个工作节点所管理的CPU数量和内存尺寸
Spark://hostname:port:Standalone模式
-
Yarn client
主程序运行在本地 具体任务运行在yarn集群
-
YARN standalone/Yarn cluster
主程序逻辑和任务都运行在YARN集群中
-
需要部署Spark到相关节点
Mesos://hostname:port:Mesos 模式
-
需要部署Spark和Mesos到相关节点
上面的部署方式:实际应用中spark应用程序的运行模式取决于传递给 sparkcontext的master环境变量的值
个别模式还需要依赖辅助程序接口来配合使用
示例代码
examples/src/main
运行脚本
bin/run-example[params]
计算PI
spark-3.0.1-bin-hadoop2.7/bin/run-example SparkPi 10 > Sparkpilog.txt
日志包含两部分
一部分是通用日志信息由一系列脚本及程序产生(计算机信息、spark信息)
另一部分是运行程序的输出结果
计算词数
假设有一个数据文件wordcountdata.txt
统计该文件单词出现的个数
spark-3.0.1-bin-hadoop2.7/bin/run-example JavaWordCount ./wordcountdata.txt
RDD
一个spark的任务对应一个RDD
RDD是弹性分布式数据集即一个RDD代表一个被分区的只读数据集
一个RDD生成
可以来自于内存集合和外部系统
也可通过转换操作来自于其他RDD map filter join
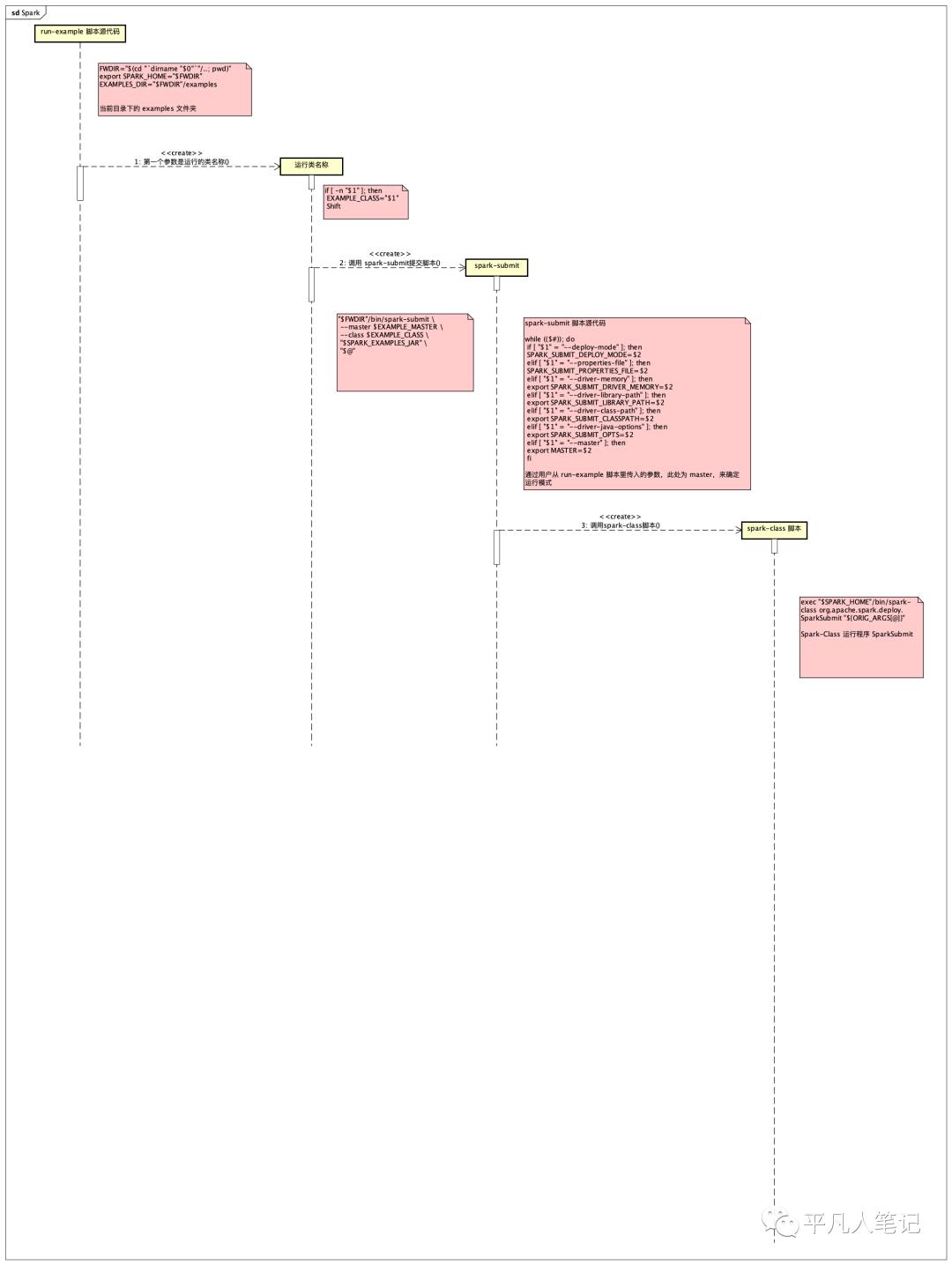
脚本的调用过程
Run-example.sh->load-spark-env.sh->lib 目录下的 jar 包文件->spark-submit.sh->spark-class
Scala
1、
scala最终启动的是jvm线程
所以它可以访问java的库文件 例如java.io.File
2、
通过Main函数的方式启动了一个JVM进程
随后针对该进程又托管了一系列线程级别的操作
3、
scala 简单 轻巧 相对java 非常适合并行计算框架的编写
运行过程
函数
-
map
根据现有数据集返回一个新的分布式数据集
由于每个原元素经过func函数转换后组成
-
flatMap
每一个输入函数 会被影射为0到多个输出函数
返回值是一个Seq 而不是单一元素
-
reduceByKey
在一个(K,V)对的数据集上使用返回一个(K,V)对的数据集
Key相同都会被指定的reduce聚合在一起
总体工作流程
无论本地模式
还是分布式模式
内部程序逻辑结构都是类似的
只是其中部分模块有所简化
本地模式中 集群管理模块被简化为进程内部的线程池
spark环境部署
使用docker部署 spark集群
飞机票
结尾
下篇文章通过一个实际案例来介绍下如何使用 spark streaming
案例描述:
假设某论坛需要根据用户对站内网页的
点击量,停留时间,以及是否点赞,
来近实时的计算网页热度,
进而动态的更新网站的今日热点模块,
把最热话题的链接显示其中。
以上是关于大数据处理工具KafkaZkSpark的主要内容,如果未能解决你的问题,请参考以下文章