为何predict()函数计算的Riskscore不等于基因的表达量与其系数的乘积的加权呢?
Posted 医学生之学习生信
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了为何predict()函数计算的Riskscore不等于基因的表达量与其系数的乘积的加权呢?相关的知识,希望对你有一定的参考价值。
相信大家在看构建模型类文献的时候,经常看到有这么一段话,说我们的风险评分Riskscore等于基因的表达量与其系数的乘积的加权。可是轮到自己构建模型的时候,用R语言的predict()函数计算出来的Riskscore,却与放到excel中,手动将这些建模的基因与其系数相乘,然后将这些乘积加起来的结果,并不相等。这是为什么呢,本节将为您解开心中解惑:
首先,我们可以看到下面几篇文献中关于Riskscore的描述:
文献1

文献2

但是我们在做自己的文章的时候,当我们用多因素cox回归建好模型后,用下面的代码计算的Riskscore:
load(file = "multicox_Exp.Rdata") #加载数据
head(multicox_Exp)[1:5,1:5] #看一下数据

数据的行名为样本名,第一列为生存时间,第二列为生存状态,其余为建模的"基因"。下面用predict()函数计算风险评分
riskScore=predict(multiCox,type="risk",newdata=multicox_Exp) #predict函数计算风险评分
riskScore<-as.data.frame(riskScore)
View(riskScore) #可以打开看一下
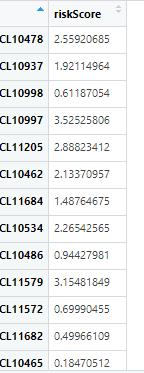
(图A)
相信,接着,很多人都会再用建模的”基因“及其系数,在excel中计算一遍riskscore,用公式:
Riskscore = 基因1的表达量*系数1 + 基因2的表达量*系数2 + … + 基因n的表达量*系数n。得到
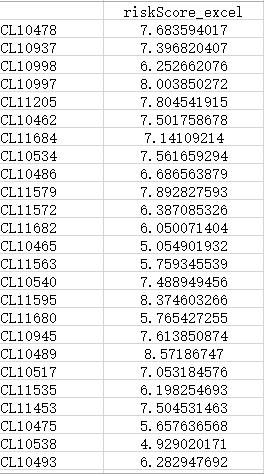
(图B)
对比一下,很明显可以发现,对于同一个样本,其风险评分Riskscore,用predict()函数计算的,与用excel计算的并不相等。但很明确的是,咱们用excel计算Riskscore的时候,用的就是文献中所说的公式啊:基因的表达量与其系数的乘积的加权。这就说明了一个问题,多因素cox回归建模后,用predict()函数计算所得的Riskscore,并不是等于 基因1的表达量*系数1 + 基因2的表达量*系数2 + … + 基因n的表达量*系数n。那么,为什么文献中作者是这么说的呢,难道作者们都错了吗?
首先,我们了解一下cox回归,Cox回归是由英国生物统计学家D.R.COX提出的一种半参数的比例风险模型,可以同时分析多种因素对生存时间影响的多变量生存分析方法,Cox回归公式为:
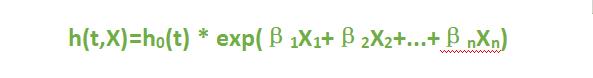
此公式中,β指回归系数,对其取反自然对数exp(β)后可以得到HR值;ho(t)为基准风险函数;h(t,X)为在时间t处与X(协变量)相关的风险函数。多因素cox回归建模后,我们用predict()函数计算得出的风险评分的值实际上是h(t,X), 而不是(β1X1 + β2X2 + …+βnXn) 。我们可以验证一下。
这里先说两个概念,比例风险假定和对数线性假定。比例风险假定是说各危险因素的作用不随时间的变化而变化,即h(t,X)/ho(t)不随时间的变化而变化,这一假定是建立cox回归的前提条件。对数线性假定是说cox回归模型中的协变量应与对数风险比呈线性相关。非常拗口,难以理解?
其实,从上述公式不难看出:
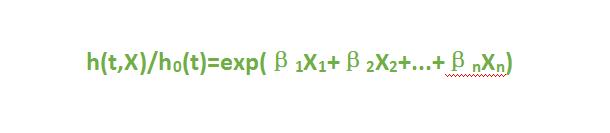
再取ln,得

实在还不会怎么用markdown写这个数学公式的下标,就在word中写了,思路如上图,下面我们直接去减减,看看结果吧:
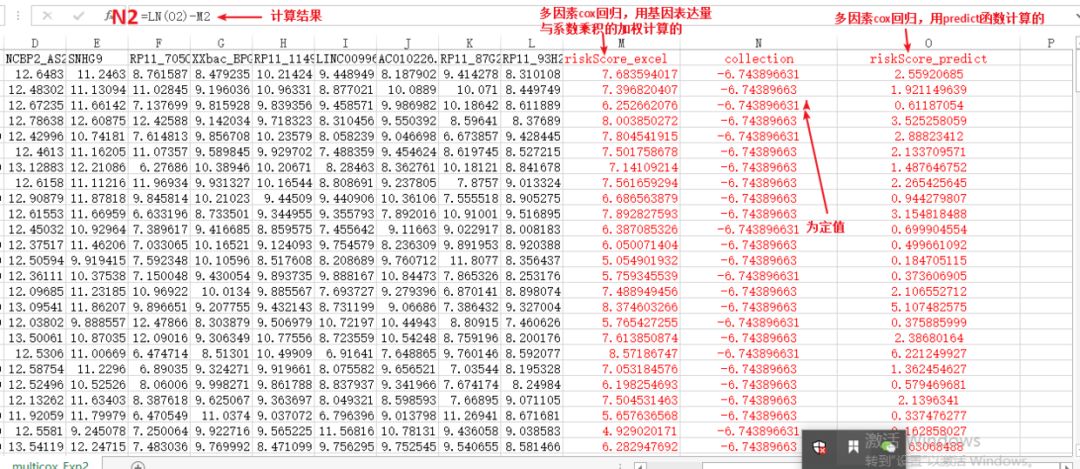
可以看到,计算结果collection这一列,几乎为一个定值(多了一个1的可能由于保留小数点后位数的不同所致)。其实collection这一列的计算结果就是 :lnho(t) 。
说到这,我想大家已经明白,如果我们用是多因素cox回归构建的模型,并且,用了函数predict()计算患者的风险评分,代码:
riskScore=predict(multiCox,type="risk",newdata=yourdata_Exp)
那么,我们在写论文的时候,就不能用开头的那几篇论文中的陈述方法来说表示我们的riskscore,而应该用
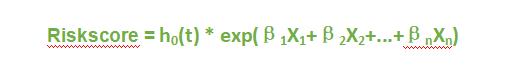
来描述我们构建的riskscore。
注意,上面咱说的是不能用陈述,是指不能用那个说法,毕竟我们明明用A方法计算的riskscore,却用B方法的描述方法来说A,这说法肯定不恰当吧。
那么,问题来了,假如我们用了多因素cox回归建模的,究竟可不可以用 基因1的表达量*系数1 + 基因2的表达量*系数2 + … + 基因n的表达量*系数n 来表示患者的riskscore呢? 嗯,可以的。上面可以看出,两种计算方式是呈对数线性关系的,这两种方法都是正确的。而且,
Riskscore = *基因1的表达量系数1 + 基因2的表达量*系数2 + … + 基因n的表达量*系数n 似乎是很多论文都喜欢采取的表示方式。所以如果我们在用多因素cox回归构建模型后,想用开头那几篇论文的这种方式(基因表达量与其系数的乘积的加权),那么,请记得手动excel中或者自己写个代码计算喔,而不是再用predict函数了喔。
wait,,wait,, 您以为这就结束了???,no,no,这不像咱的风格吖,那就再来点干货吧,
上面,我们一直在强调,用多因素cox回归建模后,用predict()函数计算所得的风险评分,与用excel加权计算的,并不相等。但是咱没说lasso回归的不相等吖,那么,lssso回归构建模型后,再用predict()函数计算所得的风险评分,与excel表手动加权计算的风险评分是否相等呢?,,下面我们一探究竟吧
library(glmnet) #加载R包
rt$riskScore <- predict(fit_predict, x, s=cv.fit$lambda.min, type="link") #计算风险评分
接着我们再在excel中计算一下,对比一下:
很开心,有木有,两者的计算结果完全一致,以后终于又可以有机会不用手动了。这里也说明了,用lasso回归构建模型后,用predict()函数,代码如下,计算的风险评分,就是 = 基因1的表达量*系数1 + 基因2的表达量*系数2 + … + 基因n的表达量*系数n 。是故很多用lasso回归构建模型的文献,在论文中陈述其riskscore时说riskscore等于基因表达量与其系数的乘积的加权。
library(glmnet) #加载R包
rt$riskScore <- predict(fit_predict, x, s=cv.fit$lambda.min, type="link") #计算风险评分
小结一下:关于predict()函数计算风险评分,用多因素cox回归建模后的(predict()函数计算的riskscore)。
与用lasso回归建模后(predict函数计的riskscore),是不太一样的。所以在论文中描述风险评分时也是不一样的。所以,为了避免麻烦,而且很多文献都是用基因表达量与其系数的乘积的加权计算风险评分的 :如果我们是用多因素cox回归构建模型的,可在excel中将基因表达量与其系数的乘积一个个加起来计算风险评分喔!这样在论文中陈述风险评分的计算时,才可以说是基因表达量与系数的乘积的加权。而对于lasso回归构建的模型,则可以直接用pridicr函数计算风险评分就可,因为它与用excel计算是一样的,就是等于基因表达量与其系数的乘积的加权。
研一已经过去2/3了,回想起还是很多感概,非常感激我们老师当初接受我的调剂并招收了我,培养我送出去学习,感激良多!后来又遇上了非常nice、对我们非常好的新导师,谢谢两位老师!在学习生信的路上,陆续又认识了果子老师、洲更老师、健明老师、小洁老师、Y姐,感谢几位老师们的帮助和指导,努力向您们学习,还认识了来自五湖四海的这条“道”上的师兄师姐们。哈哈,非常开心,女朋友也加入了我们的队伍!!两位老师非常支持和鼓励我们学习,同门师姐们和一谦也加进来一起学习了,还有本科几位非常优秀的师弟师妹们!
路漫漫,大家一起努力学习,谢谢!
图片:来源于网络
以上是关于为何predict()函数计算的Riskscore不等于基因的表达量与其系数的乘积的加权呢?的主要内容,如果未能解决你的问题,请参考以下文章
sklearn: LogisticRegression - predict_proba(X) - 计算
R语言使用cph函数和rcs函数构建限制性立方样条cox回归模型使用rms包的Predict函数计算指定连续变量和风险比HR值的关系可视化连续变量和风险值HR的关系
R语言使用Predict函数计算指定连续变量和风险比HR值的关系基于限制性立方样条分析方法限制性立方样条cox回归模型
R语言使用caret包的predict函数对模型在测试集上的表现进行推理和预测计算模型的混淆矩阵设置参数mode计算基于混淆矩阵产生的衍生指标(特异度敏感度F1ppvnpv等)