阿里云函数计算对接kafka实战
Posted 新钛云服
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了阿里云函数计算对接kafka实战相关的知识,希望对你有一定的参考价值。

背景需求
阿里云函数计算式是按调用次数来计算费用的,无需服务器就能进行后端的一些处理,对于调用次数不是特别多的场景比较适用。可以节省成本,但是如果调用次数很多对服务器性能要求不是特别高的情况下建议还是用ECS来部署服务。
函数计算对接kafka实战
新建服务和函数
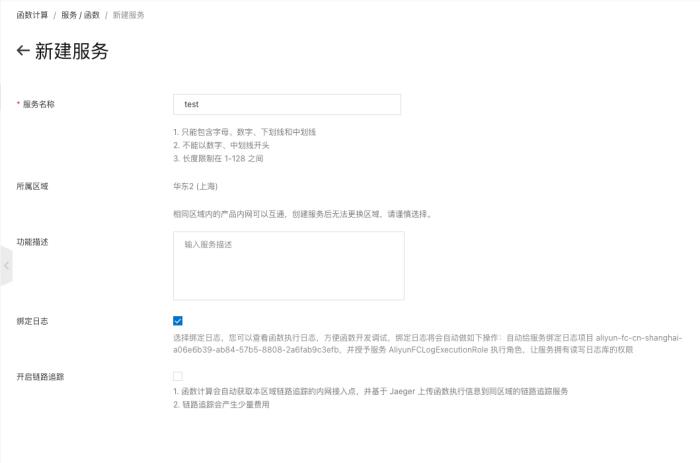
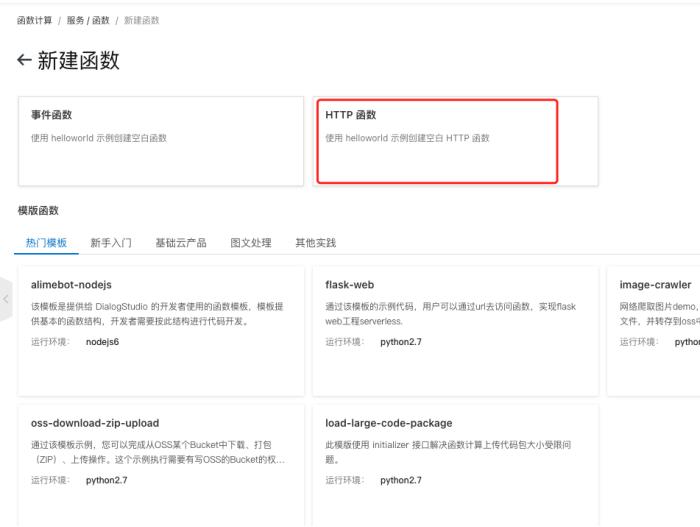
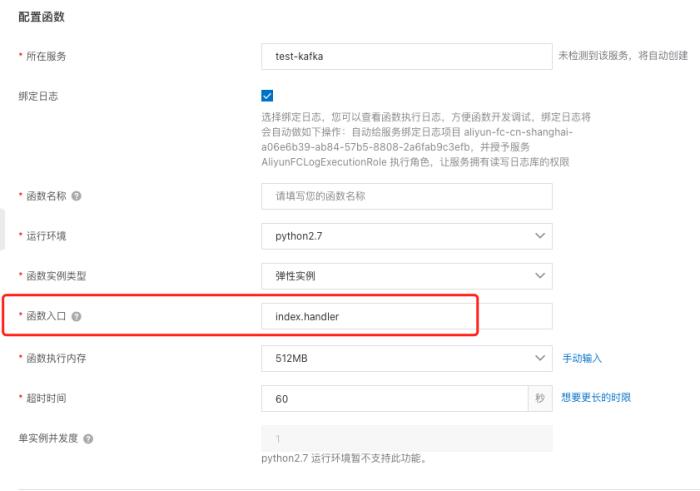
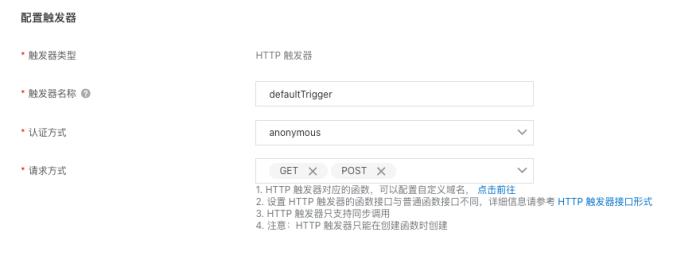
代码开发
kafka_setting = {
'bootstrap_servers': ["XXX", "XXX", "XXX"], #kafka连接地址
'topic_name': 'XXX', #使用的topic名称
'consumer_id': 'XXX' #使用的Consumer Group
}
# -*- coding: utf-8 -*-
# 导入连接kafka所需依赖包和配置
import socket
from kafka import KafkaProducer
from kafka.errors import KafkaError
import setting
conf = setting.kafka_setting
print conf
HELLO_WORLD = b"Hello world!\n"
def handler(environ, start_response):
context = environ['fc.context']
request_uri = environ['fc.request_uri']
for k, v in environ.items():
if k.startswith("HTTP_"):
# process custom request headers
pass
# get request_body
try:
request_body_size = int(environ.get('CONTENT_LENGTH', 0))
except (ValueError):
request_body_size = 0
request_body = environ['wsgi.input'].read(request_body_size)
# get request_method
request_method = environ['REQUEST_METHOD']
# get path info
path_info = environ['PATH_INFO']
# get server_protocol
server_protocol = environ['SERVER_PROTOCOL']
# get content_type
try:
content_type = environ['CONTENT_TYPE']
except (KeyError):
content_type = " "
# get query_string
try:
query_string = environ['QUERY_STRING']
except (KeyError):
query_string = " "
print 'request_body: {}'.format(request_body)
print 'method: {}\n path: {}\n query_string: {}\n server_protocol: {}\n'.format(request_method, path_info, query_string, server_protocol)
# do something here
status = '200 OK'
response_headers = [('Content-type', 'text/plain')]
start_response(status, response_headers)
#以下是kafka操作部分,发送一个消息到kafka
producer = KafkaProducer(bootstrap_servers=conf['bootstrap_servers'],
api_version = (0,10),
retries=5)
partitions = producer.partitions_for(conf['topic_name'])
print 'Topic 下分区: %s' % partitions
try:
future = producer.send(conf['topic_name'], 'hello aliyun-kafka test!')
future.get()
print 'send message succeed.'
except KafkaError, e:
print 'send message failed.'
print e
# return value must be iterable
return [HELLO_WORLD]
代码上传
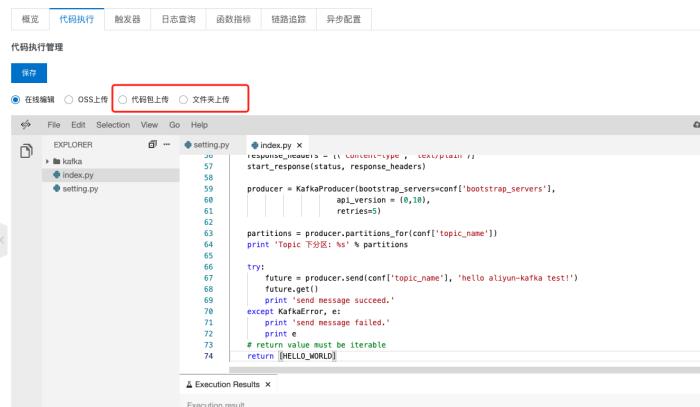
环境设置
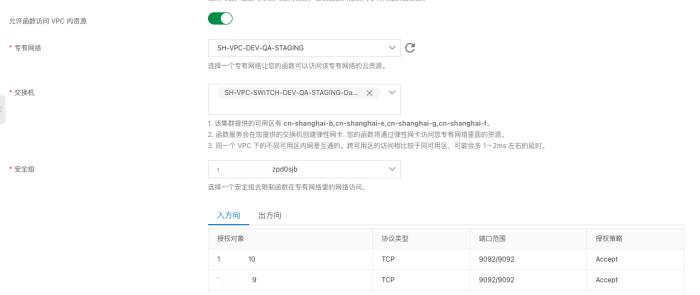

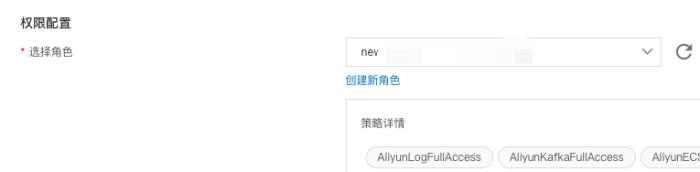
测试运行
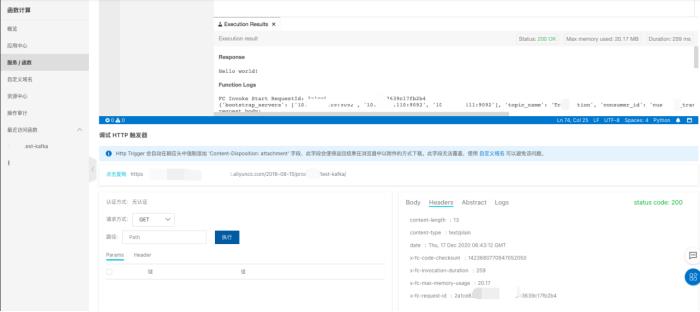
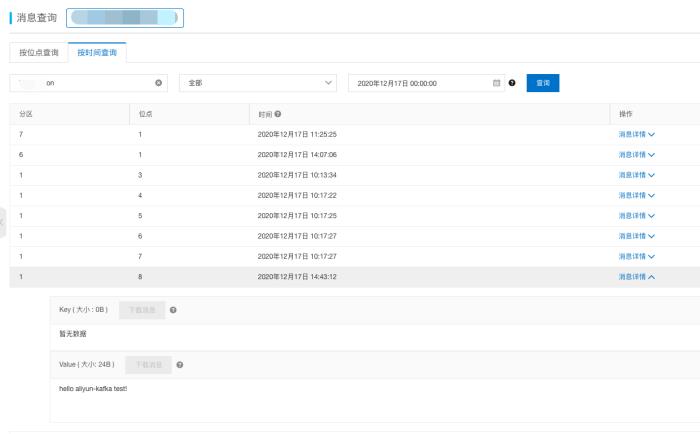
总结
了解新钛云服
往期技术干货
点 以上是关于阿里云函数计算对接kafka实战的主要内容,如果未能解决你的问题,请参考以下文章