用Python进行10w+QQ说说数据分析
Posted 程序员野客
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了用Python进行10w+QQ说说数据分析相关的知识,希望对你有一定的参考价值。

Doctor | 作者
https://zhuanlan.zhihu.com/p/27604277
对编程没有兴趣的朋友可以直接看后面的数据分析结果。
开发环境:win7下的python3.5、mysql5.7
编辑器:pycharm2017.1、ipython,Navicat for mysql
需要的python第三方库:selenium、PIL、Requests、MySQLdb、csv、pandas、numpy、matplotlib、jieba、wordcloud另外还用到了无头浏览器PhantomJS。
主要思路:
通过selenium+phantomjs模拟登录qq空间取到cookies和g_qzonetoken,并算出gtk
通过Requests库利用前面得到的url参数,构造http请求
分析请求得到的响应,是一个json,利用正则表达式提取字段
设计数据表,并将提取到的字段插入到数据库中
通过qq邮箱中的导出联系人功能,把好友的qq号导出到一个csv文件,遍历所有的qq号爬取所有的说说
通过sql查询和ipython分析数据,并将数据可视化
通过python的第三方库jieba、wordcloud基于说说的内容做一个词云
闲话不多说,直接上代码。
通过selenium+phantomjs模拟登录qq空间取到cookies和g_qzonetoken,并算出gtk
import re
from selenium import webdriver
from time import sleep
from PIL import Image
#定义登录函数
def QR_login():
def getGTK(cookie):
""" 根据cookie得到GTK """
hashes = 5381
for letter in cookie['p_skey']:
hashes += (hashes << 5) + ord(letter)
return hashes & 0x7fffffff
browser=webdriver.PhantomJS(executable_path="D:\\phantomjs.exe")#这里要输入你的phantomjs所在的路径
url="https://qzone.qq.com/"#QQ登录网址
browser.get(url)
browser.maximize_window()#全屏
sleep(3)#等三秒
browser.get_screenshot_as_file('QR.png')#截屏并保存图片
im = Image.open('QR.png')#打开图片
im.show()#用手机扫二维码登录qq空间
sleep(20)#等二十秒,可根据自己的网速和性能修改
print(browser.title)#打印网页标题
cookie = {}#初始化cookie字典
for elem in browser.get_cookies():#取cookies
cookie[elem['name']] = elem['value']
print('Get the cookie of QQlogin successfully!(共%d个键值对)' % (len(cookie)))
html = browser.page_source#保存网页源码
g_qzonetoken=re.search(r'window\\.g_qzonetoken = \\(function\\(\\)\\{ try\\{return (.*?);\\} catch\\(e\\)',html)#从网页源码中提取g_qzonetoken
gtk=getGTK(cookie)#通过getGTK函数计算gtk
browser.quit()
return (cookie,gtk,g_qzonetoken.group(1))
if __name__=="__main__":
QR_login()通过Requests库利用前面得到的url参数,构造http请求:
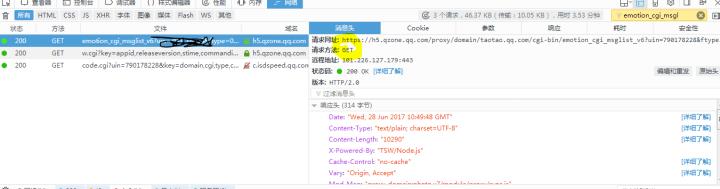

通过抓包分析可以找到上图这个请求,这个请求响应的是说说信息 。

通过火狐浏览器的一个叫json-dataview的插件可以看到这个响应是一个json格式的,开心!
然后就是用正则表达式提取字段了,这个没什么意思,直接看我的代码吧:
def parse_mood(i):
'''从返回的json中,提取我们想要的字段'''
text = re.sub('"commentlist":.*?"conlist":', '', i)
if text:
myMood = {}
myMood["isTransfered"] = False
tid = re.findall('"t1_termtype":.*?"tid":"(.*?)"', text)[0] # 获取说说ID
tid = qq + '_' + tid
myMood['id'] = tid
myMood['pos_y'] = 0
myMood['pos_x'] = 0
mood_cont = re.findall('\\],"content":"(.*?)"', text)
if re.findall('},"name":"(.*?)",', text):
name = re.findall('},"name":"(.*?)",', text)[0]
myMood['name'] = name
if len(mood_cont) == 2: # 如果长度为2则判断为属于转载
myMood["Mood_cont"] = "评语:" + mood_cont[0] + "--------->转载内容:" + mood_cont[1] # 说说内容
myMood["isTransfered"] = True
elif len(mood_cont) == 1:
myMood["Mood_cont"] = mood_cont[0]
else:
myMood["Mood_cont"] = ""
if re.findall('"created_time":(\\d+)', text):
created_time = re.findall('"created_time":(\\d+)', text)[0]
temp_pubTime = datetime.datetime.fromtimestamp(int(created_time))
temp_pubTime = temp_pubTime.strftime("%Y-%m-%d %H:%M:%S")
dt = temp_pubTime.split(' ')
time = dt[1]
myMood['time'] = time
date = dt[0]
myMood['date'] = date
if re.findall('"source_name":"(.*?)"', text):
source_name = re.findall('"source_name":"(.*?)"', text)[0] # 获取发表的工具(如某手机)
myMood['tool'] = source_name
if re.findall('"pos_x":"(.*?)"', text):#获取经纬度坐标
pos_x = re.findall('"pos_x":"(.*?)"', text)[0]
pos_y = re.findall('"pos_y":"(.*?)"', text)[0]
if pos_x:
myMood['pos_x'] = pos_x
if pos_y:
myMood['pos_y'] = pos_y
idname = re.findall('"idname":"(.*?)"', text)[0]
myMood['idneme'] = idname
cmtnum = re.findall('"cmtnum":(.*?),', text)[0]
myMood['cmtnum'] = cmtnum
return myMood#返回一个字典我们想要的东西已经提取出来了,接下来需要设计数据表,通过navicat可以很方便的建表,然后通过python连接mysql数据库,写入数据。这是创建数据表的sql代码:
CREATE TABLE `mood` (
`name` varchar(80) DEFAULT NULL,
`date` date DEFAULT NULL,
`content` text,
`comments_num` int(11) DEFAULT NULL,
`time` time DEFAULT NULL,
`tool` varchar(255) DEFAULT NULL,
`id` varchar(255) NOT NULL,
`sitename` varchar(255) DEFAULT NULL,
`pox_x` varchar(30) DEFAULT NULL,
`pox_y` varchar(30) DEFAULT NULL,
`isTransfered` double DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;其实到这里爬虫的主要的代码就算完了,之后主要是通过QQ邮箱的联系人导出功能,构建url列表,最后等着它运行完成就可以了。
这里我单线程爬200多个好友用了大约三个小时,拿到了十万条说说。下面是爬虫的主体代码:
#从csv文件中取qq号,并保存在一个列表中
csv_reader = csv.reader(open('qq.csv'))
friend=[]
for row in csv_reader:
friend.append(row[3])
friend.pop(0)
friends=[]
for f in friend:
f=f[:-7]
friends.append(f)
headers={
'Host': 'h5.qzone.qq.com',
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64; rv:53.0) Gecko/20100101 Firefox/53.0',
'Accept': '*/*',
'Accept-Language':'zh-CN,zh;q=0.8,en-US;q=0.5,en;q=0.3',
'Accept-Encoding': 'gzip, deflate, br',
'Referer': 'https://user.qzone.qq.com/790178228?_t_=0.22746974226377736',
'Connection':'keep-alive'
}#伪造浏览器头
conn = MySQLdb.connect('localhost', 'root', '123456', 'qq_mood', charset="utf8", use_unicode=True)#连接mysql数据库
cursor = conn.cursor()#定义游标
cookie,gtk,qzonetoken=QRlogin#通过登录函数取得cookies,gtk,qzonetoken
s=requests.session()#用requests初始化会话
for qq in friends:#遍历qq号列表
for p in range(0,1000):
pos=p*20
params={
'uin':qq,
'ftype':'0',
'sort':'0',
'pos':pos,
'num':'20',
'replynum':'100',
'g_tk':gtk,
'callback':'_preloadCallback',
'code_version':'1',
'format':'jsonp',
'need_private_comment':'1',
'qzonetoken':qzonetoken
}
response=s.request('GET','https://h5.qzone.qq.com/proxy/domain/taotao.qq.com/cgi-bin/emotion_cgi_msglist_v6',params=params,headers=headers,cookies=cookie)
print(response.status_code)#通过打印状态码判断是否请求成功
text=response.text#读取响应内容
if not re.search('lbs', text):#通过lbs判断此qq的说说是否爬取完毕
print('%s说说下载完成'% qq)
break
textlist = re.split('\\{"certified"', text)[1:]
for i in textlist:
myMood=parse_mood(i)
'''将提取的字段值插入mysql数据库,通过用异常处理防止个别的小bug中断爬虫,开始的时候可以先不用异常处理判断是否能正常插入数据库'''
try:
insert_sql = '''
insert into mood(id,content,time,sitename,pox_x,pox_y,tool,comments_num,date,isTransfered,name)
VALUES (%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s)
'''
cursor.execute(insert_sql, (myMood['id'],myMood["Mood_cont"],myMood['time'],myMood['idneme'],myMood['pos_x'],myMood['pos_y'],myMood['tool'],myMood['cmtnum'],myMood['date'],myMood["isTransfered"],myMood['name']))
conn.commit()
except:
pass
print('说说全部下载完成!')下面是爬取的数据,有100878条!
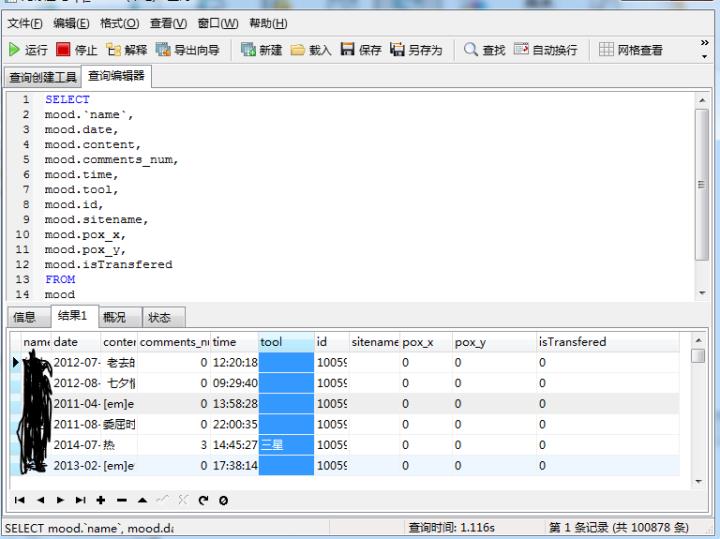
拿到数据后,我先用sql进行聚合分析,然后通过ipython作图,将数据可视化。
统计一年之中每天的说说数目,可以发现每年除夕这一天是大家发说说最多的一天(统计了2013到2017年)
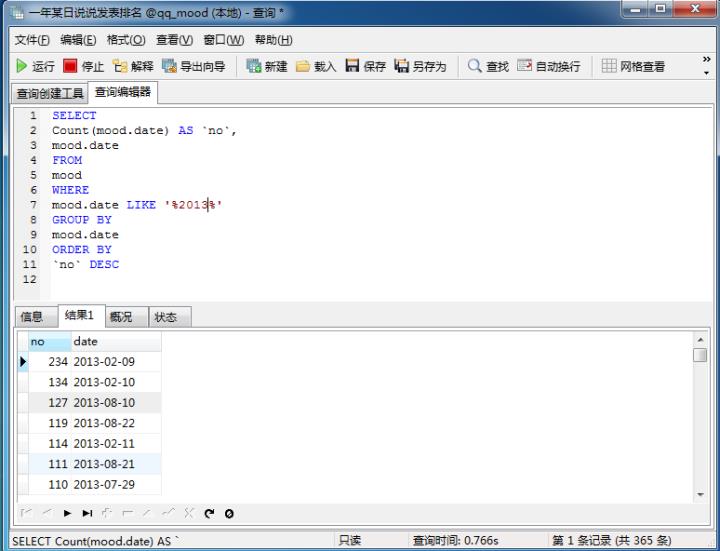
通过两个辅助表,可以看到分年,分月,分小时段统计的说说数目,下面是代码和数据图:

其余的几个图代码都是类似的,我就不重复发了。(其实主要是cmd里面复制代码太不方便了,建议大家用ipython notebook)

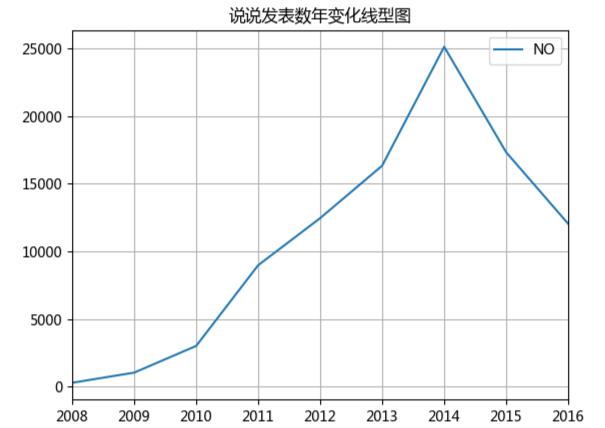
额,可以看出2014年9月达到了一个高峰,主要是因为我的朋友大都是是2014年九月大学入学的,之后开始下降,这可能是好多人开始玩微信,逐渐放弃了QQ,通过下面这个年变化图可以更直观的看出:
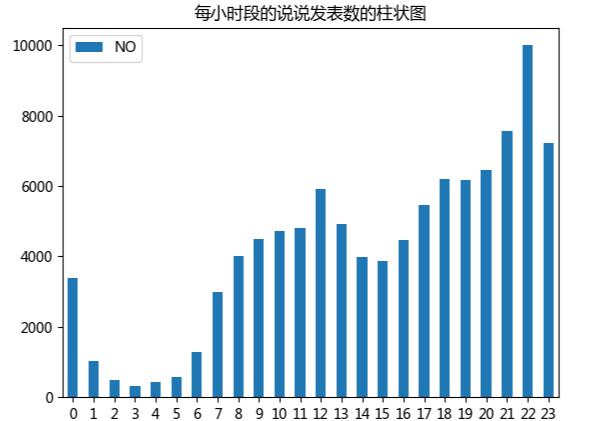
通过这个每小时段说说发表的数目柱形图,可以发现大家在晚上22点到23点左右是最多的,另外中午十二点到一点也有一个小高峰
tool发表说说用的工具这个字段的数据比较脏,因为发表工具可以由用户自定义。最后我用Excel的内容筛选功能,做了一个手机类型的饼图:
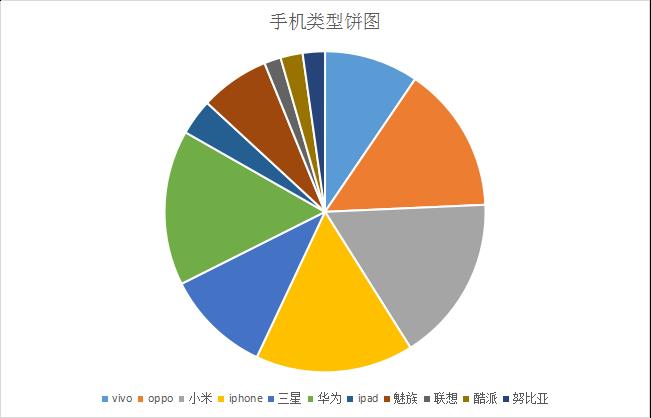
通过这个饼图可以看出使用最多的手机是苹果,小米,魅族,华为这四个手机品牌。(这个结果有很大的因素是因为我的好友大多数学生党,偏向于性价比高的手机)
还有一个比较好玩的就是把经纬度信息导出来,通过智图位置智能平台可以生成一个地图,这个地图的效果还是非常好的(2000条数据免费,本来有位置信息的说说有3500条,剔除了国外的坐标后我从中随机选了2000条)
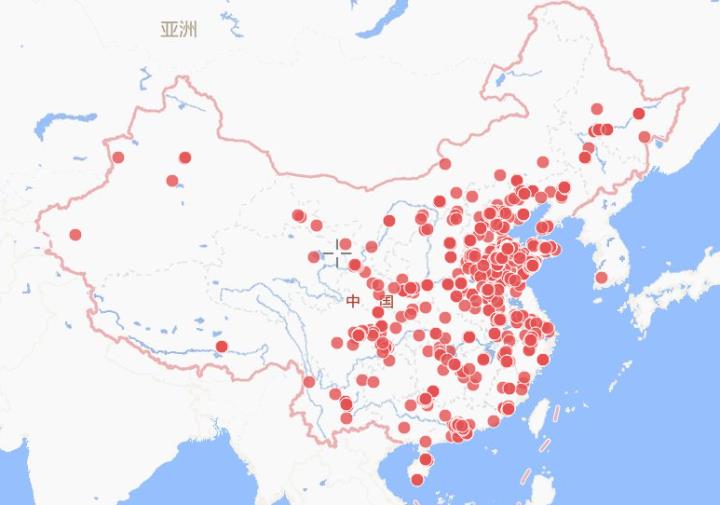
因为涉及到个人隐私问题,这个地图的链接就不分享了。
最后,通过将mood表中的content字段导出为txt文本文件,利用python的jieba和wordcloud这两个第三方库,可以生成基于说说内容的词云。下面是代码:
#coding:utf-8
import matplotlib.pyplot as plt
from wordcloud import WordCloud,ImageColorGenerator,STOPWORDS
import jieba
import numpy as np
from PIL import Image
#读入背景图片
abel_mask = np.array(Image.open("qq.jpg"))
#读取要生成词云的文件
text_from_file_with_apath = open('mood.txt',encoding='utf-8').read()
#通过jieba分词进行分词并通过空格分隔
wordlist_after_jieba = jieba.cut(text_from_file_with_apath, cut_all = True)
stopwords = {'转载','内容','em','评语','uin','nick'}
seg_list = [i for i in wordlist_after_jieba if i not in stopwords]
wl_space_split = " ".join(seg_list)
#my_wordcloud = WordCloud().generate(wl_space_split) 默认构造函数
my_wordcloud = WordCloud(
background_color='black', # 设置背景颜色
mask = abel_mask, # 设置背景图片
max_words = 250, # 设置最大现实的字数
stopwords = STOPWORDS, # 设置停用词
font_path = 'C:/Windows/fonts/simkai.ttf',# 设置字体格式,如不设置显示不了中文
max_font_size = 42, # 设置字体最大值
random_state = 40, # 设置有多少种随机生成状态,即有多少种配色方案
scale=1.5,
mode='RGBA',
relative_scaling=0.6
).generate(wl_space_split)
# 根据图片生成词云颜色
#image_colors = ImageColorGenerator(abel_mask)
#my_wordcloud.recolor(color_func=image_colors)
# 以下代码显示图片
plt.imshow(my_wordcloud)
plt.axis("off")
plt.show()
my_wordcloud.to_file("cloud.jpg")下面是效果图:

不会ps,做的不是很美观...
对于这个小demo,我总结了一以下的几个问题:
爬虫没有采用多线程和异步IO导致效率太低。(主要是twisted这个库不太懂,后面我可能会结合scapy这个框架,重写这个爬虫,利用他的twisted模块加上异步IO的功能)
对于python中的关于绘图的,和数据分析的这几个库了解的不好,导致数据可视化这块做的不好。
本文为转载分享&推荐阅读,若侵权请联系后台删除
以上是关于用Python进行10w+QQ说说数据分析的主要内容,如果未能解决你的问题,请参考以下文章