社交软件上“你可能认识的人”到底是怎么找到你的?
Posted 华为云
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了社交软件上“你可能认识的人”到底是怎么找到你的?相关的知识,希望对你有一定的参考价值。
摘要:你老死不相往来的EX,早已记不起相貌的初中同学、前同事、甚至你最不想见到的人——你的BOSS,这些人是怎么出现在你社交软件推荐用户的名单里的呢?这其中关键技术便是:知识库的链接预测,又称为知识图谱补全。

众里寻他千百度,蓦然回首,那人却在推荐名单处。
社交软件最牛的地方之一,一定是用户关系的深度挖掘。明明你已经拉黑了某些人的电话、微信、以及所有社交账号,但TA还是毫不例外地出现在页面上“你可能认识的人”里。这些人包括你老死不相往来的EX,早已记不起相貌的初中同学、前同事、甚至你最不想见到的人——你的BOSS。
▲抖音-发现朋友
那么,这些人是怎么出现在你的名单里的呢?
这其中关键技术便是:知识库的链接预测,又称为知识图谱补全。
一图理解什么是知识图谱?
知识图谱是一种将知识写成结构化三元组的多关系图,包含了实体、概念和关系。
实体指的是现实世界中的事物比如人名、地名、机构等。概念指的是具有同种特性的实体构成的集合,如下图中的“运动员”、“金球奖”等。关系则用来表达不同实体之间的某种联系。
知识图谱用实体和关系组成图谱,为真实世界的各个场景直观建模。构建知识图谱的过程本质是建立认知、理解世界的过程。

如何进行知识图谱补全
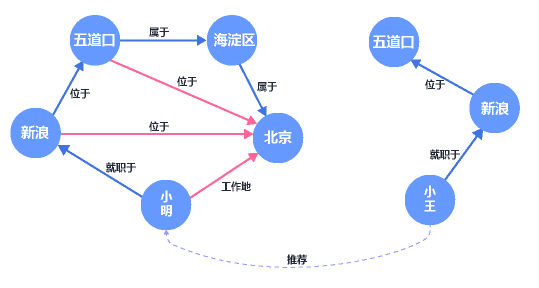
以小明为例,小明就职于位于五道口的新浪,系统可以推测出小明在北京工作。并将同样在北京新浪工作的小王推荐给了他。在下图中,蓝色的箭头表示表示已存在的关系,红色箭头为知识图谱补全后的关系。
知识图谱与知识表示学习的关系
知识图谱是由实体和关系组成,通常采用三元组的形式表示——head(头实体),relation(实体的关系),tail(尾实体),简写为(h,r,t)。知识表示学习任务就是学习h,r,t的分布式表示(也被叫做知识图谱的嵌入表示(embedding))。可以这么说,有了知识图谱的Embedding,AI式的知识图谱应用才成为可能。
如何理解嵌入表示Embedding?
简单来说,embedding是对一个对象(词、字、句子、文章…)在多个维度上的描述,相当于通过数据建模的方法来描述一个对象。
举个例子,我们经常用到的Photoshop里关于颜色的RGB表示法就属于一种非典型的embedding。在这里颜色被拆成三个特征纬度,R(红色强度,取值范围0-255),G(绿色强度,取值范围0-255),B(蓝色强度,取值范围0-255)。RGB(0,0,0)就是黑色。RGB(41,36,33)就是象牙黑。通过这样的方法,我们可以通过数字来描述颜色。

知识表示学习都有哪些方法
知识表示学习的关键是设计合理的得分函数,在给定事实三元组为真的情况下我们希望最大化得分函数。它从实现形式上可分为以下两类:
基于结构的方法
该类模型的基本思想是从三元组的结构出发学习知识图谱的实体和联系的表示,其中最为经典的算法是TransE模型。该方法的基本想法是头向量表示h与关系向量表示r之和与尾向量表示t越接近越好,即h+r≈t。这里的“接近”可以使用L1或L2范数进行衡量。原理图如下:
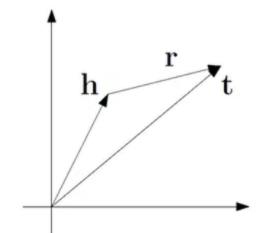
该类知识表示学习模型还有:TransH, TransR, TransD,TransA等。
基于语义的方法
这类模型是从文本语义角度出发学习KG的实体和关系的表示。这类表示方法主要有LFM, DistMult, ComplEx, ANALOGY, ConvE等。
知识表示学习的应用
由于基于表示学习,可以将知识图谱的实体和关系进行向量化表示,方便后续下游任务的计算,典型应用有以下几种:
1)相似度计算:利用实体的分布式表示,我们可以快速计算实体间的语义相似度,这对于自然语言处理和信息检索的很多任务具有重要意义。
如何进行相似度计算呢?举个例子。
假设"李白"这个词的embedding一共是5维,其值为[0.3, 0.5, 0.7, 0.03, 0.02],其中每个维度代表和某个事物的相关性,这五个数值分别代表[诗人,作家, 文学家,自由职业者,侠士]的含义。
而"王维"=[0.3, 0.55, 0.7, 0.03, 0.02],"牛顿"=[0.01, 0.02, 0.06, 0.4, 0.01],我们可以用余弦距离(几何中,夹角余弦可用来衡量两个向量方向的差异;机器学习中,借用这一概念来衡量样本向量之间的差异。)来计算这几个词的距离,显而易见李白和王维的距离更近,和牛顿的距离更远。 由此可以判断“李白” 和“王维”更为相似。
2)知识图谱补全。构建大规模知识图谱,需要不断补充实体间的关系。利用知识表示学习模型,可以预测2个实体的关系,这一般称为知识库的链接预测,又称为知识图谱补全。上文中“五道口小明”的例子可以很好的解释。
3)其他应用。知识表示学习已被广泛用于关系抽取、自动问答、实体链接等任务,展现出巨大的应用潜力。
自动问答是与知识表示学习深度结合的一大应用。对于智能问答产品来说,后台设计时,一般分为3层,输入层、表示层、输出层。输入层简而言之就是问题库,这里集合了所有用户可能会问到的问题。再经过表示层的知识抽取,最终返回结果。
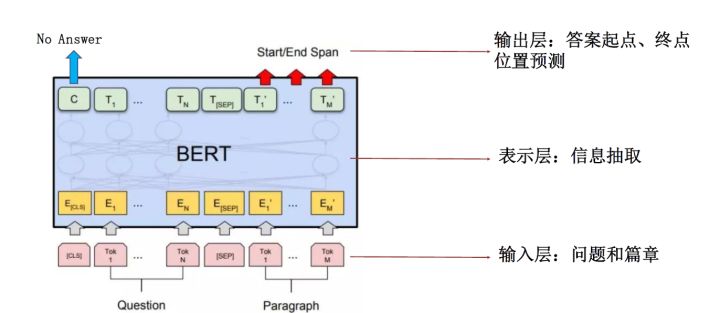
典型的智能问答产品有苹果Siri、微软小冰、百度、阿里小蜜等。这些问答产品的一大特色是,可以使搜索结果更精准,而不是返回一堆相似的页面让你自己去筛选,达到“所答即所问”。比如,搜索“王思聪的身价多少”,返回来的结果就是具体的数字。
总结
简而言之,社交产品基于知识图谱知识补全技术,通过实体和关系的表示对缺失三元组进行预测,在已知头实体以及头实体间的关系,预测其尾实体。也就是说,它们是根据用户画像来进行朋友推荐的,如果你不想那些“老熟人”出现在你的推荐名单里,最好的方法是,关掉社交产品上的地理定位、尽可能少地透露个人信息。
参考资料
1、刘知远,孙茂松,林衍凯,谢若冰《知识表示学习研究进展》
以上是关于社交软件上“你可能认识的人”到底是怎么找到你的?的主要内容,如果未能解决你的问题,请参考以下文章