Flink 流批一体太强了!Spark Streaming 根本不是对手?
Posted yangyidba
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Flink 流批一体太强了!Spark Streaming 根本不是对手?相关的知识,希望对你有一定的参考价值。
Flink 今年战绩太牛了!
Flink 虽然比 Spark 晚了一些,但随着其持续不断的努力,加上以阿里双 11 作为应用战场代表,其实时计算峰值达到了破纪录的每秒 40 亿条记录,战绩尤其显著,现在已成为实时计算的首选技术之一,与 Spark 并驾齐驱。
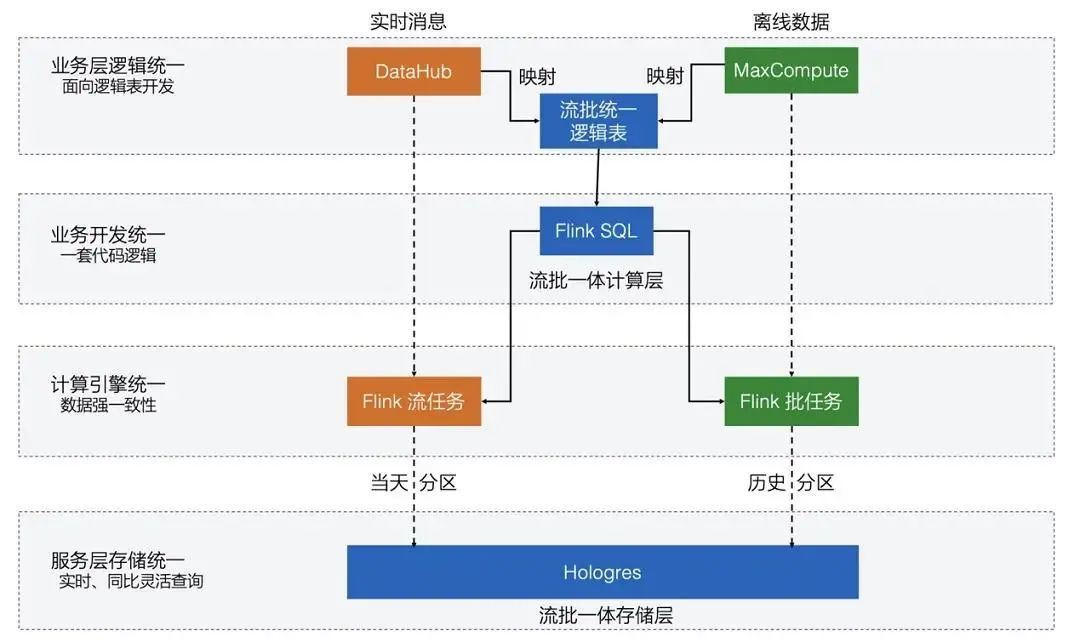
阿里基于Flink的计算层架构图
很多朋友,都玩过 Apache Storm,Spark Streaming 和 Apache Flink,也是目前主流的流计算技术,但真正能同时做到低时延、Exactly-Once 数据一致性保障及高吞吐的,只有 Flink 一个。
还很多公司的大数据处理,处在离线处理阶段,但未来,必定是以 Flink 为代表的实时计算技术作为重要发展方向,因为随着 AI 的广泛应用,信息处理的实效性要求也越来越高,模型的在线推理成为计算引擎的核心能力。Flink 实时计算技术与 AI 是绝配,未来可期!
从工作环境来看,怎么上手呢?我们需要用动态的思维,来看待流处理数据,因为它是一种动态行为,倒逼我们回归数据产生的本质,数据是按照特定事件的先后关系在整个系统中进行流转并被处理的。基于真实数据,流处理是用来挖掘客观事实背后隐藏价值的最重要手段,数据即是黄金。
Flink 的状态管理和容错,是非常核心的一块儿,回归业务,在千亿级海量数据实时处理场景中,Flink 如何落地应用?如何设计Flink StateBackend ?Flink两阶段提交核心源码有哪些?海量大数据去重普适架构又该怎么做?
具体几个业务场景,你是怎么解决的?
1)如何实现一个 SQL on Stream 的 SQL 实时计算平台?
2)面对千亿级数据的业务场景,Flink 的架构方案如何设计?
3)海量数据实时处理,保证精确处理的架构设计方案如何设计?

快速掌握阿里奉为“神器”的 Flink 计算引擎
由前 58 技术委员会主席孙玄联手 58 到家 CTO 沈剑老师,结合 10 多年一线大厂实践经验,打造的《大数据架构师必备技能—千亿级企业大数据计算引擎 Flink State 架构设计深度剖析与案例深度实践》在线专栏课。3 天沉浸式学习,让你在实践中了解 Flink State 架构设计的原理,学完能轻松应对大厂大数据资深开发 / 架构师面试!
不赚钱,交个朋友
9.8 ≈ 半杯奶茶

以上是关于Flink 流批一体太强了!Spark Streaming 根本不是对手?的主要内容,如果未能解决你的问题,请参考以下文章