上千生产节点的JournalNode下线,以及上线异常问题解决
Posted 涤生手记
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了上千生产节点的JournalNode下线,以及上线异常问题解决相关的知识,希望对你有一定的参考价值。
背景: 集群规模上千节点,5台JournalNode节点,现在因为需要维修,下线其中一台JournalNode进行维修。
1.JournalNode下线
在namenode的HA机制下,两个NameNode为了数据同步,会通过一组称作JournalNodes的独立进程进行相互通信。JournalNode属于轻量级的应用,可以同样在运行JournalNode节点上运行datanode,nodemanager等角色,不影响使用的。根据hadoop官网的描述:必须至少有3个JournalNode守护程序(配置三个JournalNode节点),因为必须将edits 日志修改写入大多数JN,防止单节点故障。当前多配几个也可以,官网介绍说:为了实际增加系统可以容忍的故障数量,您应该运行奇数个JN(即3、5、7等)。请注意,当与N个JournalNode一起运行时,系统最多可以容忍(N-1)/ 2个故障,并继续正常运行。我们集群上千个节点运行了5个JN,现在需要下线一台,也不必新增,就剩4个其实也是正常运行的。
JournalNodes得下线比较简单,直接下线即可,停止主机角色进程。等待观察其他几个节点的负载会上升,稳定后即可。
2.JournalNode的上线与异常问题解决
正常机器经过1个小时维修后,重新上线,启动JN的角色进程。启动上面的datanode,nodemanager等进程。发现datanode,nodemanager的角色都是正常的。但是JN角色虽然进程启动成功了,但是监控界面内显示告警,没有与namenode同步。查看后台日志后,显示报异常:java.io.FileNotFoundException: /hadoop/dfs/jn/ShareSdkHadoop/current/last-promised-epoch.tmp (No such file or directory)

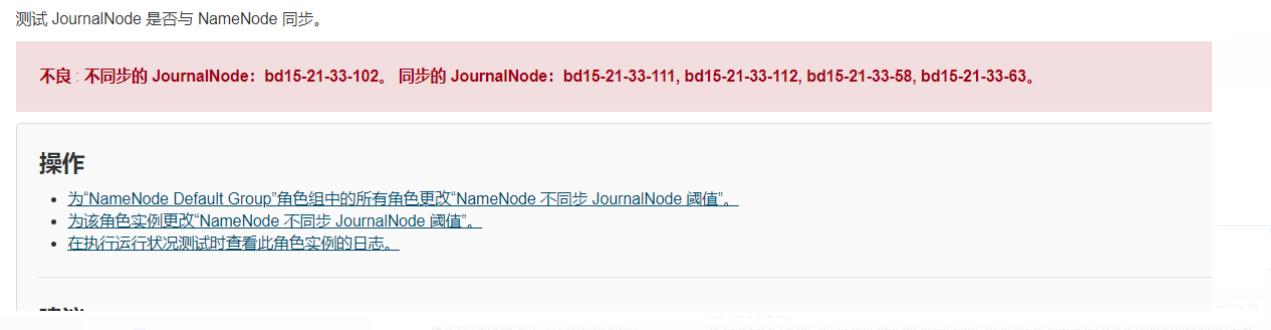

3.解决方案
这种类似于JN下线后,重新上线的,比如更换了硬盘,存储等。重新上线后会碰到与namenode不同步的情况,这种情况会有多种报错,比如更换了新硬盘后,重启JournalNode 会出现"JournalNotFormattedException: Journal Storage Directory /data/2/dfs/jn/nameservice1 not formatted" 这样的错误,以及sync同步异常的问题,以及/hadoop/dfs/jn/ShareSdkHadoop/current/last-promised-epoch.tmp (No such file or directory)。异常问题种类很多。
尖叫提示:但是解决的方式最简单有效的,就是进入JN的配置目录,以我们的为例如下:/hadoop/dfs/jn/ShareSdkHadoop/current
1.首先将该目录下所有的东西都清空(一般来说超多JN的掉线时间会默认上线后清空这些目录。)。如下:在该目录下in_use.lock是因为jn正在使用的锁。
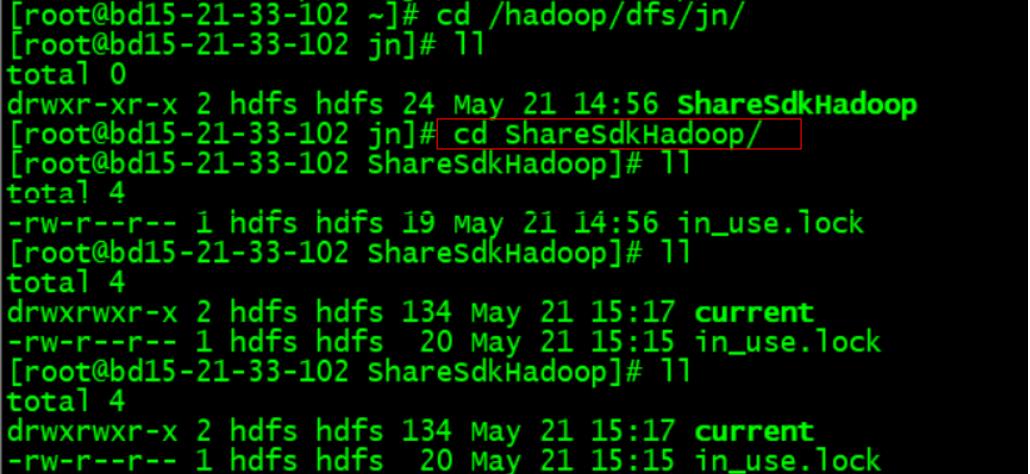
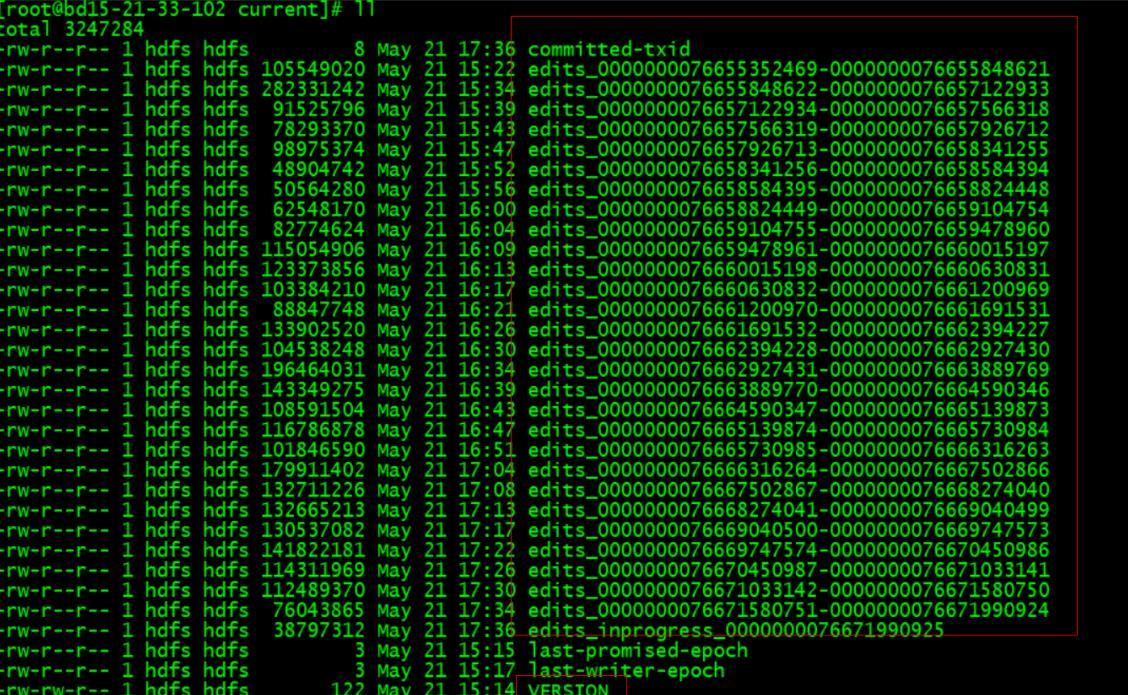
2.在current目录创建一个文件touch VERSION,在这个VERSION文件里,追加如下内容。注意这个VERSION里的内容要跟其他 active 的JN保持一致,直接从其他JN的节点里的VERSION复制过来即可。但是要注意,如果是单namenode HA的话,所有的JN的VERSION一致,如果是多namenode联邦的话,要跟同一namedenode的JN的内容保持一致。
#Sat Jul 18 19:25:41 CST 2020
namespaceID=25563396
clusterID=cluster24
cTime=0
storageType=JOURNAL_NODE
layoutVersion=-60然后需要将这个VERSION文件的用户与组,以及读写权限配置和其他的JN一致如下:
3.配置完以后直接重启JN,即可,等几分钟以后。就可以看到它不仅重建了如last-promised-epoch,last-write-epoch等文件,也开始同步了edits。从其监控指标看也已经恢复正常。
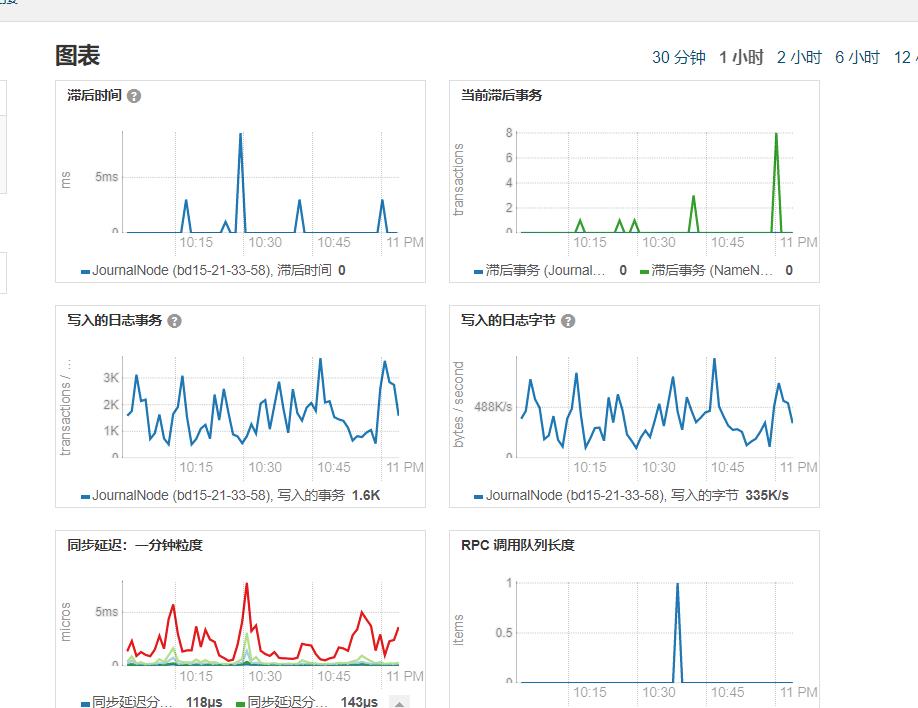
这类问题网上报错七七八八,解决方案也八八九九,比如通过复制edits等,搞起来比较麻烦,简单的方式就是直接初始化即可。
具体可以参考官网:
以上是关于上千生产节点的JournalNode下线,以及上线异常问题解决的主要内容,如果未能解决你的问题,请参考以下文章