大数据开发要学会看yarn日志:Task容错机制,任务推测执行,计数器
Posted 涤生手记
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了大数据开发要学会看yarn日志:Task容错机制,任务推测执行,计数器相关的知识,希望对你有一定的参考价值。
背景:yarn的web界面是所有大数据开发都会或多或少查看的,比如任务运行失败,任务运行缓慢,查看详细任务运行进度,详细报错排查,debug等。但是实际从反馈来看,很多大数据开发对yarn界面的日志查看并不深入,对一些常见指标并不熟悉。下面以Hive/MapRedcue任务为例。
1.Task容错机制原理与使用
1.1 map/reduce有failed和killed现象?
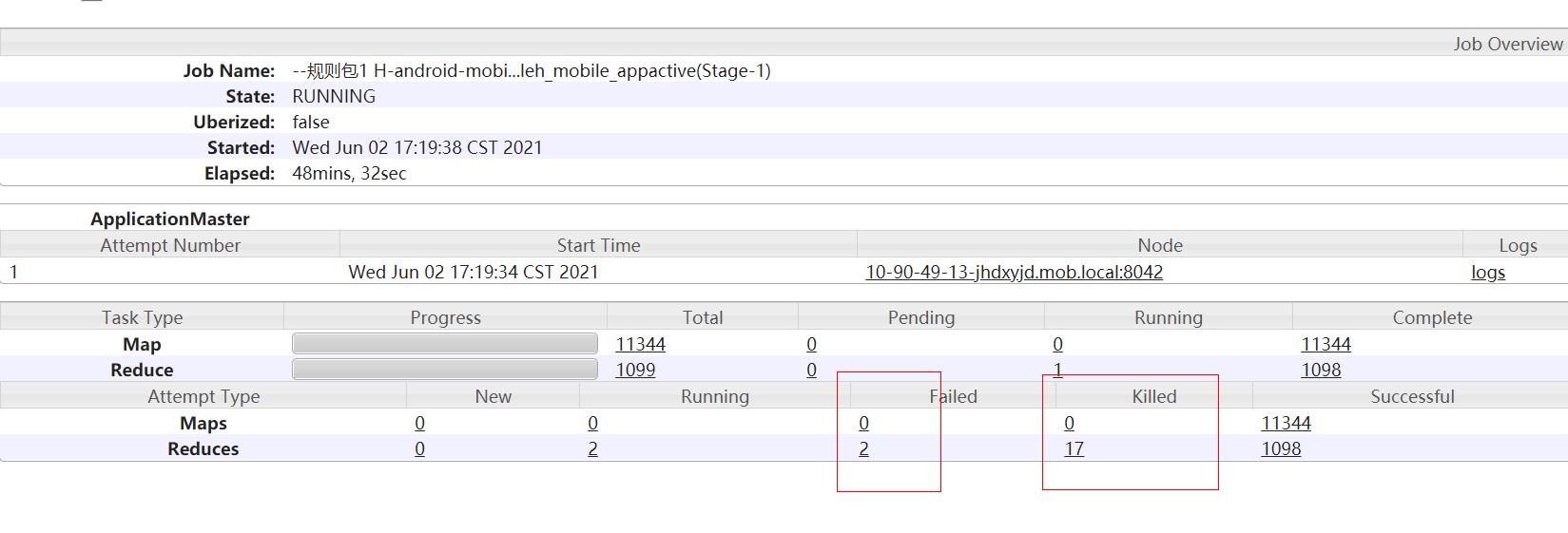
如下任务yarn界面很常见,比如reduce出现了2个failed,17killed,那么对我任务最终结果有没有影响呢?如果没有影响原因是啥呢?比如下面Task Type和 Attemp Type两个栏目都有map/reduce的状态和个数统计,两者的区别是什么?要想深入了解这些问题,就先要弄明白mapredcue/hive任务的Tast容错机制。
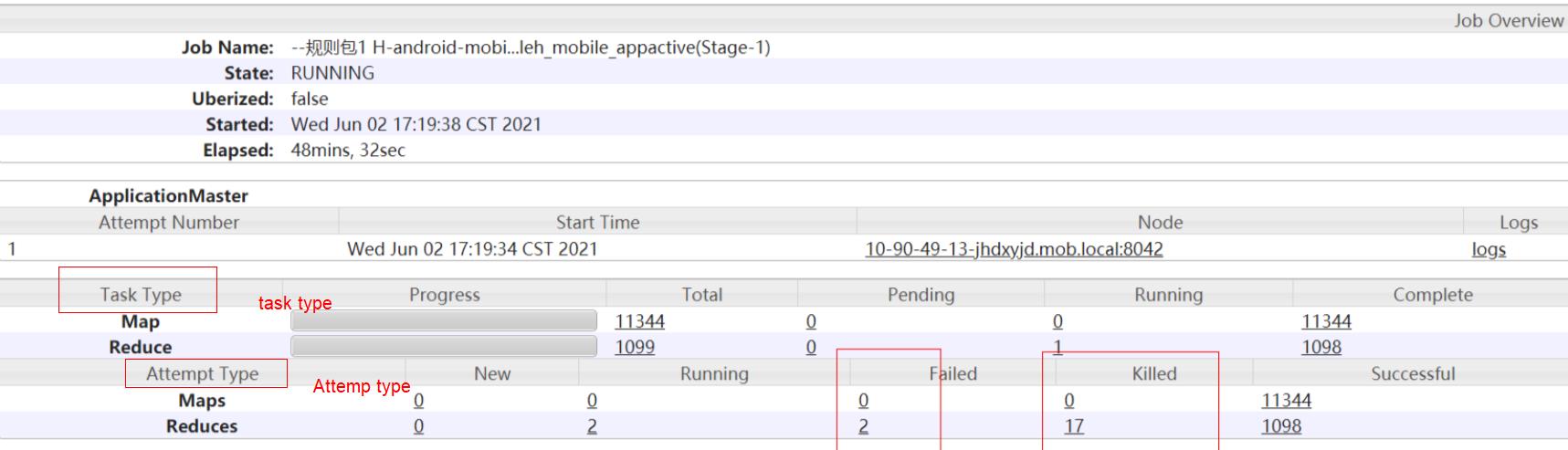
1.2 Task type与Attemp Type的区别
MapRecue/Hive 任务分成maptask和reducetask,每个类型的task的总数一般是根据数据量和参数配置决定,在任务起始阶段已经确定。yarn界面的Task Type统计的就是提交yarn时需要执行的task任务数量。而实际一个task允许尝试多次运行,每次运行尝试的实例就被称Task Attempt,也就是yarn任务日志界面Attempt Type里统计的数据。这也就是为啥map/reduce的实例都是以attmp_****开头的原因,因为任务的运行实例是attemp。

注意:任务还是task开头的,两个查看的入口是不同的,我们一般关注的是task的进度,一个task任务可以有多个attmpt实例在跑,具体牵扯到推测执行。
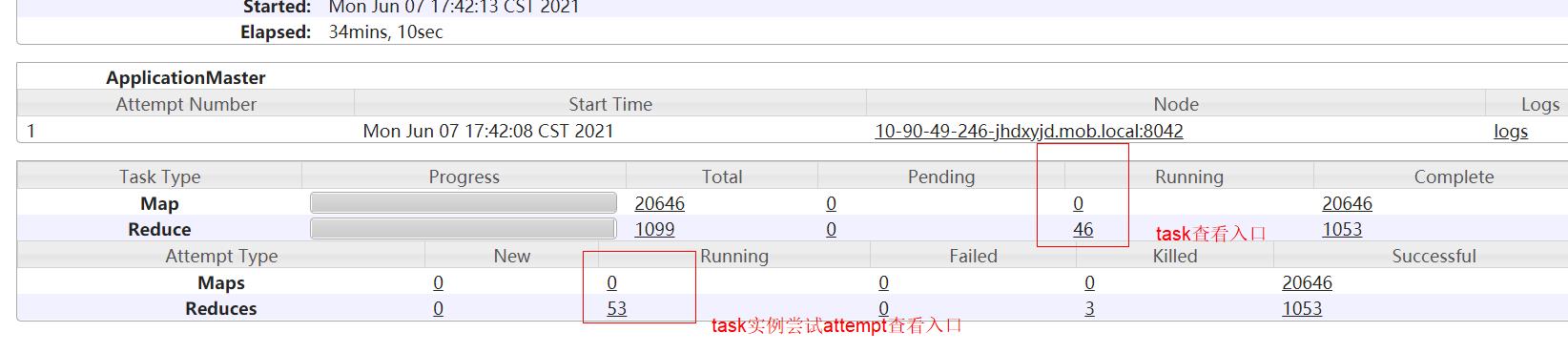
1.3Task的容错机制的使用
实际生产中,map/reduce task会因为多方面原因如机器老化,资源不足,进程崩溃,带宽限制等出现部分map/reduce task实例失败的情况,这是极其正常且容易发生的事。如果这个时候整个任务就直接报错了,那么代价就太大了。所以hadoop就引入了task容错机制。map/reduce实例失败后,在退出之前向APPMaster发送错误报告,错误报告会被记录进用户日志,APPMaster然后将这个任务实例标记为failed,将其containner资源释放给其他任务使用。
通过如下两个参数控制map/reduce的task一旦失败了map/reduce实例可以重试的次数,一般直接使用默认值就可以,所以实际开发中,不要关注单个map的失败,只要不失败四次,对任务就没有影响。每次失败后APPMaster都会试图避免在以前失败过的节点上重新调度该任务,直到任务成功,或者超过4次,超过4次则不会在尝试,默认作业容错率是0,这时候整个任务失败。
1.控制Map Task失败最大尝试次数,默认值4
mapred.map.max.attempts ---废弃参数
mapreduce.map.maxattempts ---推荐新参数
2.1.控制Reduce Task失败最大尝试次数,默认值4
mapred.reduce.max.attempts ---废弃参数
mapreduce.reduce.maxattempts---推荐新参数1.3.1任务任务实例出现failed/killed的场景
1.任务实例attempt长时间没有向MRAPPMaster报告,后者一直没收到其进度的更新,一般attempt实例与APPMaster3s通信一次,前者像后者报告任务进度和状态;超出阈值,任务变会被认为僵死“”被标记失败failed,然后MRAPPMaster会将其JVM杀死,释放资源。然后重新尝试在其他节点启动一个新的任务实例。
mapreduce.task.timeout=600000 ms,10分钟
The number of milliseconds before a task will be terminated if it neither reads an input, writes an output, nor updates its status string. A value of 0 disables the timeout.2.任务attempt失败fialed的其他原因比较多,比如代码有问题,outofmemory,GC.
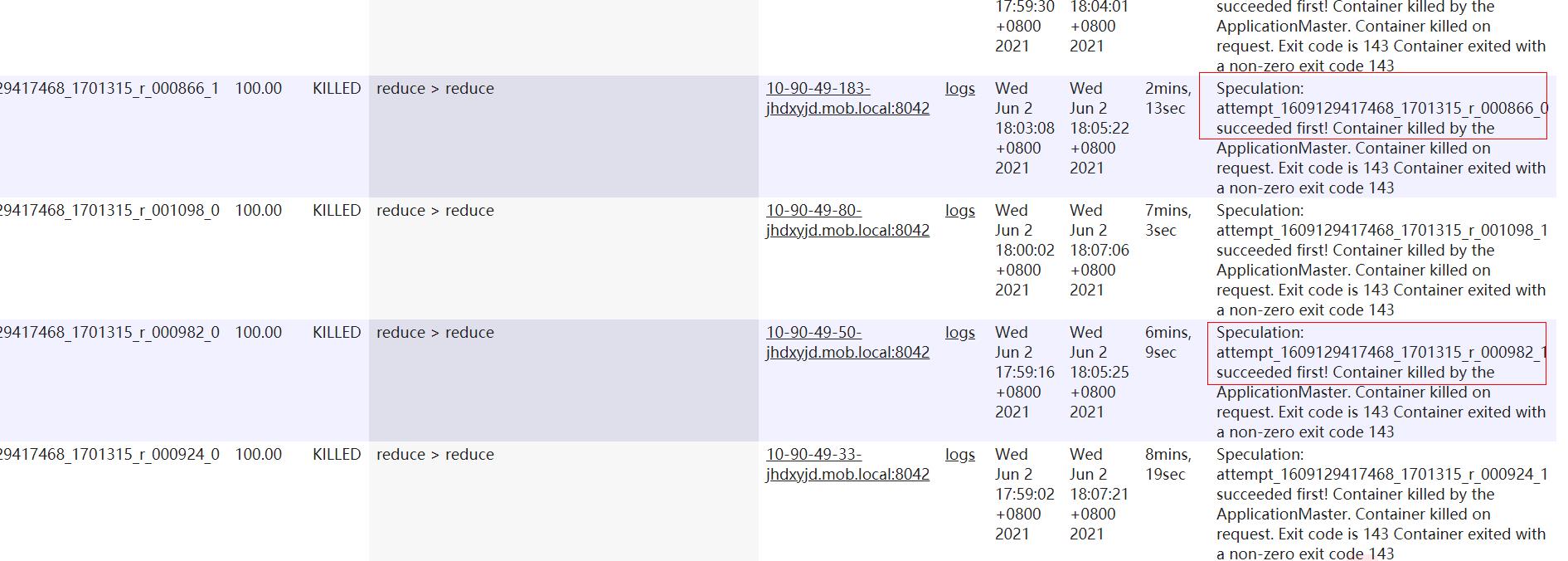
3.一个任务实例attempt被killed一般就两种情况,一是客户端主动请求杀死任务,二是框架主动杀死任务。对于后者,一般是由于作业被杀死或者该任务的备任任务(推测执行)已经执行完成,这个任务不需要继续执行了,所以被Killed。比如nodemanager节点故障,比如停止等,这时候上面的所有任务实例都会被标记为killed。其他再比如任务执行超出某些阈值范围,比如动态分区超过最大文件数,所有任务都会被杀死killed.
如下任务被杀死就是因为MRAPPMaster主动要求杀死的备份任务
2.任务的推测执行
实际开发中查看yarn日志可能会遇到,为啥显示有257reduce没跑完,下面attempt里却有261redcues 处于running状态呢?
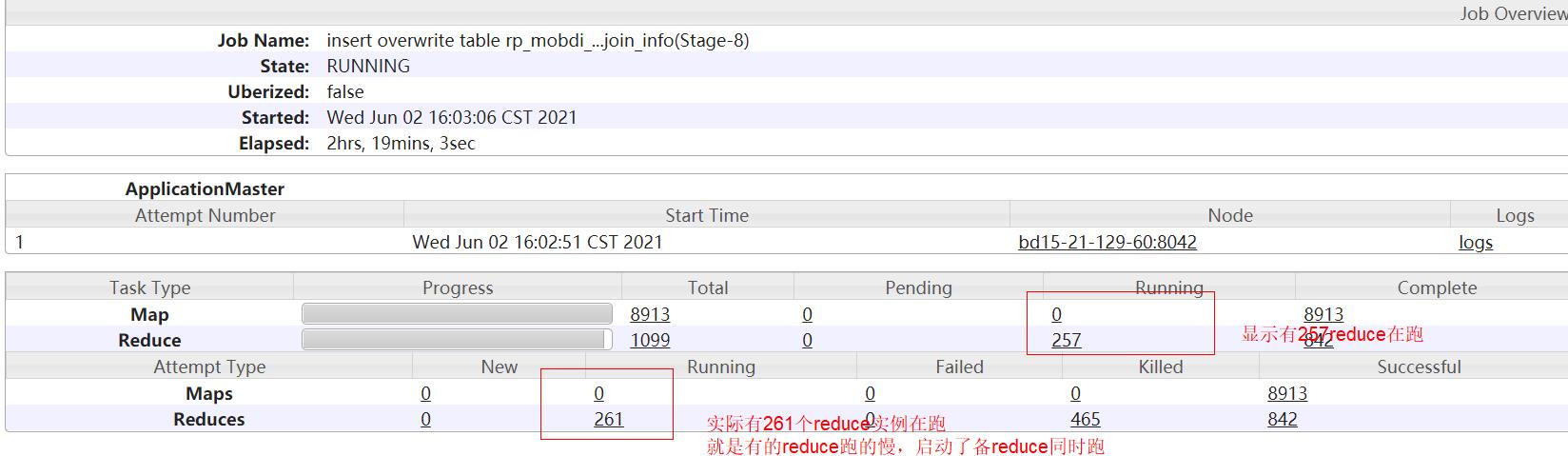
MRappMaster当监控到一个任务实例的运行速度慢于其他任务实例时,会为该任务启动一个备份任务,让这个两个任务同时处理一份数据,如map/reduce。谁先处理完,成功提交给MRappMaster就采用谁的,另一个则会被killed,这种方式可以有效防止那些长尾任务拖后腿。是为任务推测speculative execution。
任务推测执行的好处就是空间换时间,防止长尾拖后腿的,比如某个实例所在的机器不行跑的贼慢,重启一个很快执行完了。任务推测的坏处就是两个重复任务,浪费资源,降低集群的效率,尤其redcue任务的推测执行,拉群map数据加大网络io,而且推测任务可能会相互竞争。
默认集群开启推测执行,可以基于集群计算框架,也可以基于任务类型单独开启,map任务建议开启,reduce可以结合实际谨慎开启。
mapreduce.map.speculative=true
---默认,开启map推测执行
mapreduce.reduce.speculative=true
---默认,开启reduce推测执行,都可单独开。
mapreduce.job.speculative.speculative-cap-running-tasks=0.1
--在任何时刻可以被推测执行的任务数百分比
--其他还有很多关于推测执行的参数,可以参考官网3.任务进度与计数器
经常参看某个整个任务进度或者task进度,你知道这个进度是怎么计算出来的?
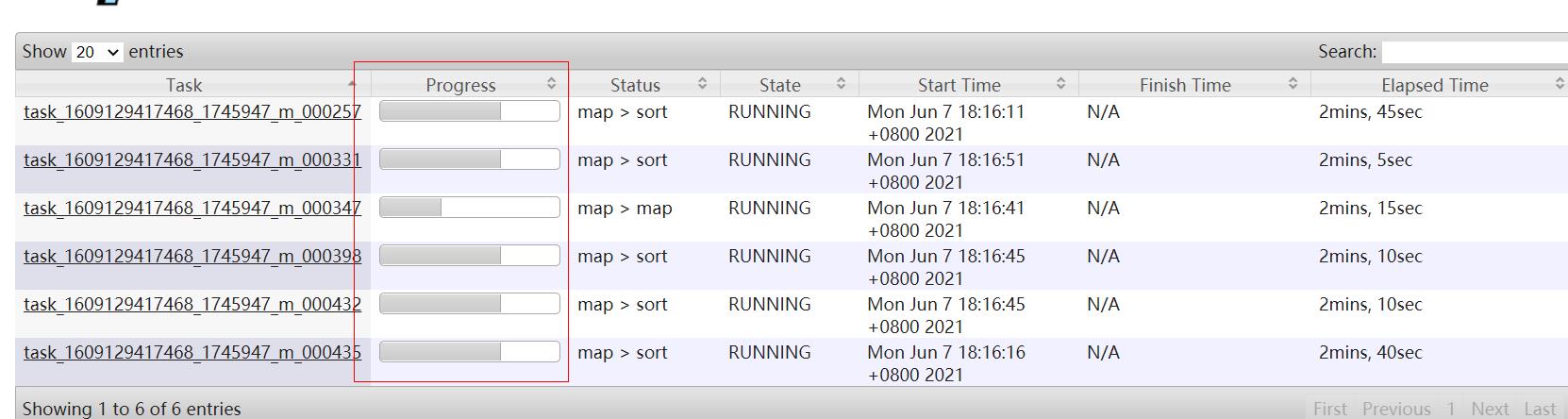
map/reduce任务task运行时,会和MRAPPMaster进行通信,间隔3s,通过UMbilical接口汇报自己的 任务进度以及任务状态,最终汇总展示如上图所示。
map任务比较简单,任务进度就是对切片输入的数据总量已处理的占比。比如处理完了85%的数据了那么进度就是85%,主要通过计数器统计。
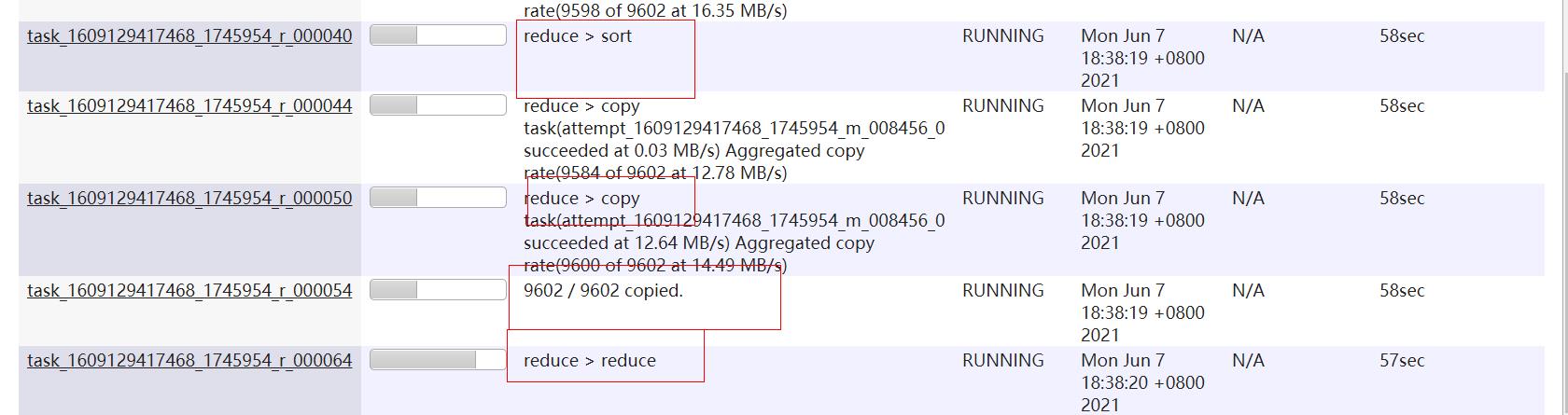
reduce任务根据redue阶段的完成统计的,三个过程依次是;拉取复制map数据1/3,合并排序1/3,reduce函数聚合处理1/3;比如某个reduce处理了map输出的数据一半,则该reduce的进度是1/3+1/3+1/3*1/2。
如下反应了一个reuce的三个阶段
以上是关于大数据开发要学会看yarn日志:Task容错机制,任务推测执行,计数器的主要内容,如果未能解决你的问题,请参考以下文章