Flink 火了,网友炸了。。
Posted 算法与数据结构
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Flink 火了,网友炸了。。相关的知识,希望对你有一定的参考价值。
剩喜漫天飞玉蝶,不嫌幽谷阻黄莺。2020 年是不寻常的一年,Flink 也在这一年迎来了新纪元。
12 月13 – 15 号,2020 Flink Forward Asia(FFA)在春雪的召唤下顺利拉开帷幕。Flink Forward Asia 是由 Apache 官方授权,Apache Flink Community China 支持举办的会议。经过两年的不断升级和完善,Flink Forward Asia 已成为国内最大的 Apache 顶级项目会议,是 Flink 开发者和使用者的年度盛会!今年由于疫情的原因,Flink Forward Asia 首次采用线上线下双线同步会议的形式,吸引了更多的参会者观看讨论,三天实际总参与人数(UV)超过 9.2 万,单日最高观看人数(UV)超过 4 万。
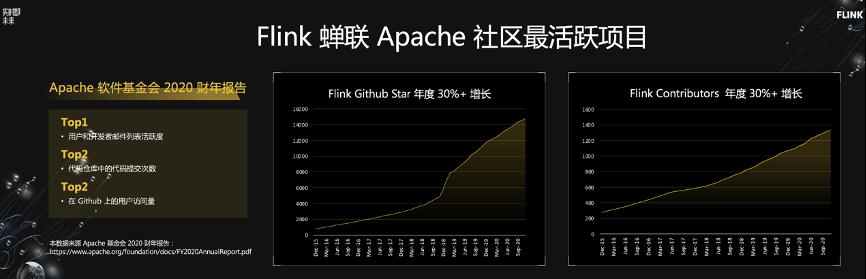
FFA 大会从社区发展,业内影响力和 Flink 引擎生态这三方面总结了 Flink 过去一年内的成绩。
社区方面
,如上图所示,根据 Apache 基金会财年报告公布的各项核心指标显示,Flink 在 2020 年蝉联 Apache 社区最活跃的项目。不仅如此,Flink Github 的星数(代表项目受欢迎程度)和 Flink 的社区代码贡献者(contributor)数量在过去数年中一直保持年均 30%+ 的增长。尤其值得一提的是 Flink 中文社区的繁荣发展:Flink 是当前 Apache 顶级项目中唯一一个开通了中文邮件列表(user-zh@flink.apache.org)的项目,且中文邮件列表的活跃度已超过英文邮件列表;Flink 的官方公众号订阅数超过 3 万人,全年推送超过 200 篇和 Flink 技术,生态以及实践相关的最新资讯。此外,Flink 官方中文学习网站也已经正式开通:https://flink-learning.org.cn/ ,收纳了和 Flink 相关的学习资料,场景案例以及活动信息,希望能对 Flink 感兴趣的同学有所助益。

在业界影响力方面
,经过几年的发展,Flink 已经成为事实上的国内外实时计算行业标准,大部分主流科技公司均已采用 Flink 作为实时计算的技术方案。本届 Flink Forward Asia 邀请到 40 多家一线国内外公司参与分享 Flink 的技术探索和实践经验,上图列出了其中部分公司的 Logo。从图中的 Logo 来看,Flink 技术已经应用到各行各业,深入到我们的日常点滴生活中,从知识分享到在线教育;从金融服务到理财投资;从长短视频到在线直播;从实时推荐搜索到电商服务等等。
从 Flink 引擎生态来看
,2020 年,Flink 在流计算引擎内核,流批一体,拥抱 AI,云原生这四个主打方向上都取得了不错的成绩。特别对于流批一体,今年发布的三个大版本(Flink-1.10 & 1.11 & 1.12)对流批一体进一步作了升级和完善,并首次在阿里巴巴双十一最核心的天猫营销活动分析大屏场景中落地 [1]。经历过双十一洗礼的流批一体将成为在业界大规模推广的起点,开创流批一体新纪元!
本文将对 Keynote 议题作一些简单的归纳总结,抛砖引玉,感兴趣的小伙伴们可以在官网找到相关主题视频观看直播回放。

在主议题之前有两个环节值得提一提。一是阿里巴巴集团副总裁,阿里云智能计算平台负责人,人工智能计算框架 Caffe 之父贾扬清老师作为开场嘉宾,分享了他对开源与云的思考。他指出,开源让云更标准化,而大数据和人工智能一体化则是必然趋势。显而易见地,作为顶级开源项目和实时计算标准的 Flink 在这个过程中承担极其重要的角色。同时他也对 Flink 如何在未来做到计算普惠化和数据智能化提出更多期待,让 Flink 的小松果在各行各业的数据和智能融合中生根发芽!二是由阿里云天池平台和 Intel 联合举办的第二届 Apache Flink 极客挑战赛颁奖典礼。此次挑战赛聚焦防疫主题,在 Apache Flink 平台上支持深度学习应用,吸引了来自 14 个国家和地区,705 所高校,1327 家企业的 3840 位选手,由扬清,李文和湘雯颁奖。

Flink as a Unified Engine
–– Now and Next
主议题由 Apache Flink 中文社区发起人,阿里云智能实时计算和开放平台负责人莫问老师开启,主要介绍 Flink 社区在 2020 年取得的成果以及未来的发展方向,主要包括:流计算引擎内核,流批一体,Flink + AI 融合,云原生这四个方向。值得一题的是,他还特别分享了阿里巴巴作为 Flink 最大的使用者和推动者,在流批一体双十一核心业务场景落地的过程中的经验和心得,相信对很多有类似需求的小伙伴们会有启示。
技术创新是开源项目持续发展的核心,所以首先第一个部分是 Flink 社区在流计算引擎内核方面的创新分享:
我们知道 Flink 的一个最核心的部分是通过分布式全局轻量快照算法 [2, vldb17] 做 checkpoint 来保证强一致性 exactly once 语义。这个算法通过 task 之间 barrier 的传递使得每一个 task 只需要对自己的状态进行快照;当 barrier 最终达到 sink 的时候,我们就会得到一个完整的全局快照(checkpoint)。但在数据反压的情况下,barrier 无法流到 sink,会造成 checkpoint 始终无法完成。Unaligned Checkpoint 解决了反压状态下,checkpoint 无法完成的问题。在 unaligned checkpoint 的模式下,Flink 可以对每个 task 的 channel state 和 output buffer 也进行快照,这样 barrier 可以快速传递到 sink,使得 checkpoint 不受反压影响。Unaligned checkpoint 和 aligned checkpoint(现有的 checkpoint 模式)可以通过 alignment timeout 自动智能的切换,下图给出了示意图。

2)Approximate Failover –– 更加灵活的容错模式
流计算内核引擎部分的另一个提升是 Approximate 单点 Failover。在强一致性 exactly once 语义下,单个节点的失败会导致全部节点的重新启动和回滚。但对某些场景,特别是 AI 训练的场景,其实对语义一致性的要求并没有那么高,反而对于可用性要求更高,所以社区引入了 Approximate Failover 的模式:单个节点的失败只会引起该失败节点的重启和恢复,而整个数据流程是没有中断的。Approximate Failover 在 AI 训练和推荐场景下是强需求,快手和字节跳动的分享中都有提到。
3)Nexmark –– Streaming Benchmark
目前的实时流计算并没有行业内公认的 benchmark,为了填补这项空白,基于 NEXMark[3],Flink 推出了第一版包含 16 个 SQL Query 的 benchmark 工具 Nexmark。Nexmark 一大特点是方便易用,没有外部系统依赖, 同时支持标准的 ANSI SQL。Nexmark 目前业已开
源:
https://github.com/nexmark/nexmark
,可以用来比对不同流计算引擎之间的差异。
第二个重要的部分是流批一体
,开头提到 2020 年是流批一体的新纪元,为什么这么说呢,莫问老师从流批一体架构演进,Flink 批处理性能,以及业界流批一体数据生态这三个方面给出了答案。
Flink-1.10 & 1.11 两个大版本实现了 SQL & Table 层的流批一体化和解决生产可用性问题;刚刚发版的 Flink-1.12 解决了 DataStream 层的流批一体化;从 1.13 版本开始,Flink 将逐步淘汰 DataSet 这套 API。在全新的流批一体架构中,Flink 完成了统一的流批表达,统一的流批执行,以及统一可插拔的 runtime 支持。分会场中的《基于 Flink DataStream API 的流批一体处理》有对这个部分更为详细的介绍。
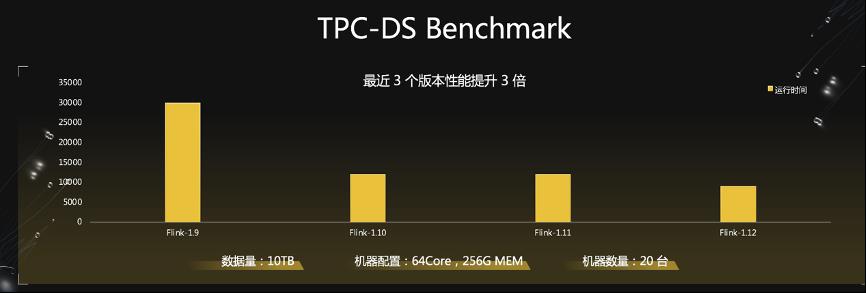
大家比较关心的批的性能:经过三个版本的迭代,以 TPC-DS 为基准,Flink-1.12 比 Flink-1.9(去年的版本)提速 3 倍!数据量 10TB,20台 64Core 机器的配置下,TPC-DS 运行时间收敛到万秒以内。这意味着 Flink Batch 的性能已经不亚于任何一个业界主流的 Batch 引擎了。
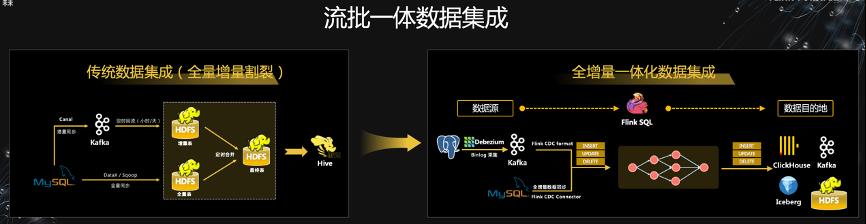
莫问老师指出,流批一体不仅仅只是一个技术问题,它也对业界数据生态的演化也起到了深远的作用,比较典型的场景包括数据同步集成(数据库里的数据同步到数仓中)和基于 Flink 流批一体的数仓架构/数据湖架构。传统的数据同步集成采用全量增量定时合并的模式,而 Flink 流批一体混合 connector 可以实现全量增量一体化数据集成(读取数据库全量数据后,可以自动切换到增量模式,通过 CDC 读取 binlog 进行增量同步),全量和增量之间无缝自动切换,如下图所示。
传统的数仓架构分别维护一套实时数仓和离线数仓链路,这样会造成开发流程冗余(实时离线两套开发流程),数据链路冗余(两遍对数据的清洗补齐过滤),数据口径不一致(实时和离线计算结果不一致)等问题。而 Flink 的流批一体数仓架构将实时离线链路合二为一,可以完全的解决上述这三个问题。不仅于此,Flink 的流批一体架构和数据湖所要解决的问题(流批一体存储问题)也完美契合。现在比较主流的数据湖解决方案 Iceberg,Hudi 和 Flink 都有集成。其中,Flink + Iceberg 已有完整的集成方案;而 Flink + Hudi 的整合也在积极对接中。
第三个大的方向是与 AI 的融合
。莫问老师从语言层,算法层和大数据与 AI 一体化流程管理这三个方面总结了 2020 年
Flink 在 AI 融合方面的进展
。从语言层来讲,Flink 对 AI 的主流开发语言 Python 的支持 PyFlink 逐步走向成熟:Flink 的 DataStream API 和 Table API 都已 Python 化,用户可以用纯 Python 语言开发 Flink 程序;Flink SQL 中支持 Python UDF/UDTF;PyFlink 集成了常用的 Python 类库如 Pandas,在 PyFlink 中可以直接调用 Pandas UDF/UDAF。从算法层面来看,去年开源的:Alink https://github.com/alibaba/alink(基于 Flink 的流批一体的传统机器学习算法库)新增了数十个开源算法,提供基于参数服务器的大规模分布式训练,训练过程与预测服务的衔接更加顺畅。
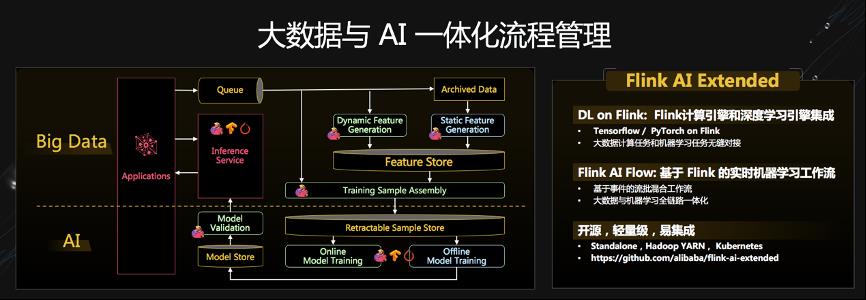
大数据与 AI 一体化流程管理也是一个很值得深入探讨的问题,其背后的本质问题是在离线学习实时化的大背景下,如何设计离线在线机器学习一体化的流程管理架构,以及该架构如何与大数据工作流程相结合,实现大数据与机器学习全链路一体化的问题。这套完整的解决方案 Flink AI Extended 不仅支持深度学习引擎和 Flink 计算引擎的集成(TensorFlow / PyTorch on Flink),它的工作流(Flink AI Flow)也应用了上述的一体化设计思想。目前 Flink AI Extended 也已经开源:
https://github.com/alibaba/flink-ai-extended
。此外,在分会场议题中有对 Flink AI Extended 更详细的讨论和全流程 demo《基于 Flink 的在线机器学习系统架构探讨》,感兴趣的同学可以找来看看并试用一下。
此外还有一个重要的方向是 Flink 与云原生生态 Kubernetes 的深度融合。Kubernetes 目前广泛应用在各种在线业务上,其生态本身发展也很快,可以给 Flink 在生产中提供更好的运维能力。从 Flink-1.10 版本开始,Flink 经过三个版本的迭代,到 Flink-1.12,Flink 已经可以原生地运行在 Kubernetes 之上,对接 K8S 的 HA 方案,并不再依赖 ZooKeeper,达到生产可用级别。
同时,Flink 的 JobManager 可以和 K8S Master 直接通信,实现动态扩缩容,并支持对 GPU 的资源调度。
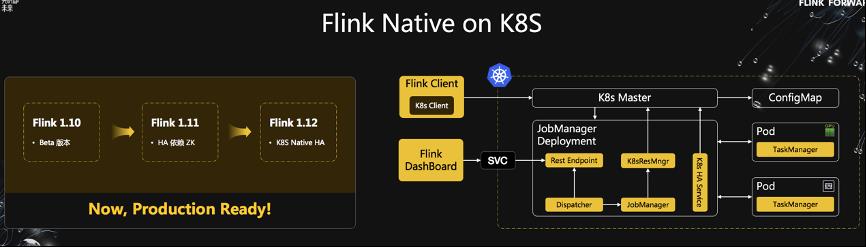
接下来,莫问老师分享了 Flink 在阿里巴巴(Flink 最大的使用者和推动者)的前世,今生和未来。2016 年,Flink 在双十一搜索推荐场景中首次亮相,并用 Flink 实现搜索推荐和在线学习全链路实时化。2017 年,Flink 成为阿里巴巴集团内实时计算的标准解决方案。2018 年,Flink 正式上云,使用 Flink 的实时数据解决方案更好的为中小企业服务。2019 年,阿里巴巴收购了 Flink 的初创公司 Ververica,并将 Blink 回馈给社区,向国际化迈进一步。到 2020 年,Flink 已经成为事实上的全球实时计算标准。目前各大云厂商(阿里云,AWS)和大数据厂商(Cloudera)等均已将 Flink 内置作为标准的云产品。到今年双十一,Flink 已包揽阿里内部所有集团(包括蚂蚁,钉钉,菜鸟等)的全链路实时化解决方案,规模达到百万级 CPU Core。并且在资源没有增长的情况下,提高了一倍业务能力。今年双十一的实时数据处理峰值更是达到 40 亿条记录/秒的新高。
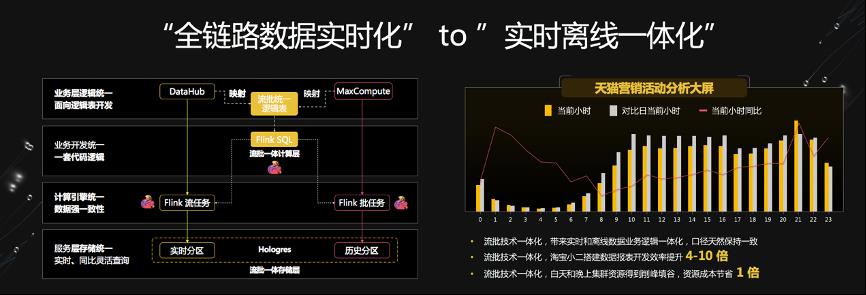
莫问老师强调,“全数据链路实时化”并不是终点,阿里巴巴的目标是“实时离线一体化”。2020 年,Flink 迎来了实时离线流批一体的新纪元 –– 首次在双十一最核心场景天猫营销活动分析大屏场景中落地,并带来了巨大的收益:
实时和离线逻辑业务的一体化使得数据结果天然保持一致;同时使得业务开发效率提升了 4-10 倍;流批任务的错峰调度使得资源成本节省了 1 倍,如上图所示。在行业实践分会场中的《流批一体技术在天猫双 11 的应用》对此有更详尽的介绍,感兴趣的同学可以参考一下。在行业内,字节跳动,美团,快手,知乎,小米,网易等都在探索 Flink 流批一体的落地。
第二场议题由美团实时计算负责人鞠大升老师带来,主要分享了 Flink 在美团内部的应用。鞠大升老师首先分享了美团数仓的整体架构。如下图所示。美团数据架构包括数据集成系统、数据处理系统、数据消费和数据应用四部分。Flink 主要应用在 Kafka2Hive、实时数据处理、Datalink 等(图中红圈的部分),而他本次分享也主要集中在这几个部分。Flink 在美团的主要应用场景包括实时数仓,实时分析;推荐搜索;风控监控;安全审计。这几个应用场景其实也是 Flink 现在的几个最主流的应用场景。在美团的应用场景中,Flink 每天的峰值数据达到 1.8 亿条记录/s。
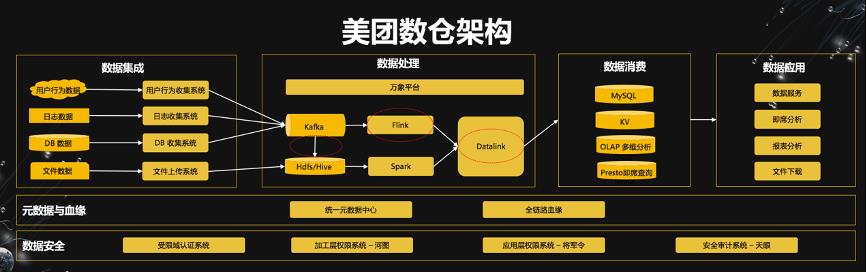
美团的分享有两个比较有趣的部分,一是提出了“增量生产”这个概念。这其实和莫问老师提到的全量增量一体化数据集成异曲同工。但在这个概念里,增加了数据时效性,数据质量和生产成本之间的权衡考量,也即如何在一个数仓业务中在满足时效性的情况下能更有效的控制成本和提升数据质量。二是美团基于 Flink 架构解决了分布式异构数据源同步(Datalink)的问题。他们基于 Flink 的同步系统可以将同步任务通过 Task Manager 分散到集群中,使得整体架构有很好的扩展性;另一方面,离线和实时的同步任务可以都统一到 Flink 框架中,所以离线和实时所有同步的组件都可以共用。
目前,美团在数据处理这一层还没有实现完全的流批统一,所以鞠大升老师表示,未来的目标希望在数据处理以及数据存储本身都能达到流批统一。
Apache Flink 在快手的过去、现在和未来
第三场议题由快手大数据架构团队负责人赵健博老师带来,主要分享了快手实时计算选型 Flink 的原因和 Flink 在快手内部应用的场景,以及快手在这些应用场景内的相关技术改进。快手选型 Flink 的原因其实回答了为什么 Flink 能成为业界实时计算的标准:1)亚秒级的处理延迟,这对快手内部的实时应用是个硬性强需求;2)丰富的窗口计算模式,自带的标准化状态存储以及 Exactly Once 的强一致性保证能够极大的简化业务开发和调试的复杂度;3)流批一体架构的演进进一步简化数据和业务架构的复杂性。快手表示非常看好 Flink 流批一体在数据全场景落地。
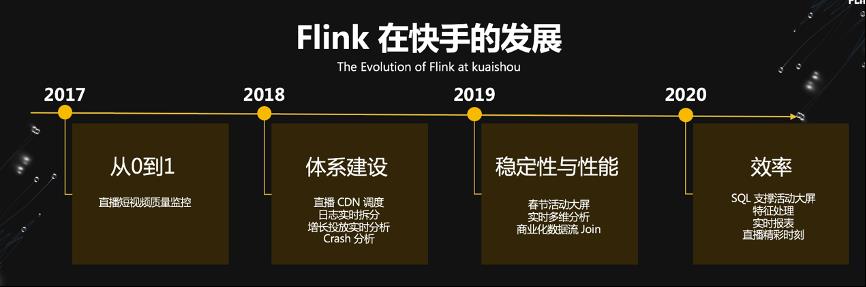
快手使用 Flink 从 2017 年开始,从 0 到 1 今年已是第四个年头,发展过程如上图所示。快手使用 Flink 主要场景包括实时 ETL 数据集成,实时报表,实时监控,实时特征处理(AI),目前每天的峰值可以达到 6 亿条记录 /s。针对上述每一个场景快手都分享了很详细的实例,特别是特征处理(Feature Processing/Engineering),在很多 AI 场景中还是很有代表性的。
快手还分享了自研的状态存储(SlimBase)在其内部的应用。SlimBase 主要分为三层,State Interface 层,KV Cache 层和 File System(Distributed)层;其中 KV Cache 是读操作能加速的关键。当 SlimBase KV Cache 层都被命中时,SlimBase 相对于 RocksDB 有 3-9 倍的读写效率提升;而 Cache 层不能都被命中的情况下(需要访问文件系统),读性能有一些下降。除了 SlimBase,快手对 Flink 的稳定性(包括硬件故障,依赖服务异常,任务过载)和负载均衡方面都提出一些改进的解决方案。分会场议题《快手基于 Apache Flink 的持续优化实践》对此有更详细的介绍。
对于未来的规划,赵健博老师老师表示会推动 Flink 的流批一体在快手内部落地,并结合 Flink 的流批一体推动 AI 数据流实时化以提升训练模型的迭代速度。随着越来越多业务使用 Flink,快手对 Flink 的稳定性也提出更多的要求(比如快速 Failover 的能力),所以快手在这方面也会有更多的投入。
主议题的最后一场是由戴尔科技集团软件开发总监滕昱老师带来的流式存储议题:Pravega。这个议题比较有趣的是讨论了流式存储的抽象 Stream Abstraction。传统的文件系统对于流式存储来说并不是一个好的抽象,原因 1)文件的大小有限制,但是流式数据是持续注入的;2)在持续的数据注入中对存储的并发度也需要动态调整,这就涉及到多个文件的维护和操作;3)有序的流式数据的定位寻址问题在文件系统接口中也无法很好的被支持;4)现在业界惯用的联合使用消息队列(Kafka)+ 文件系统的混合抽象也仍然没有减轻应用程序开发和维护的难度。
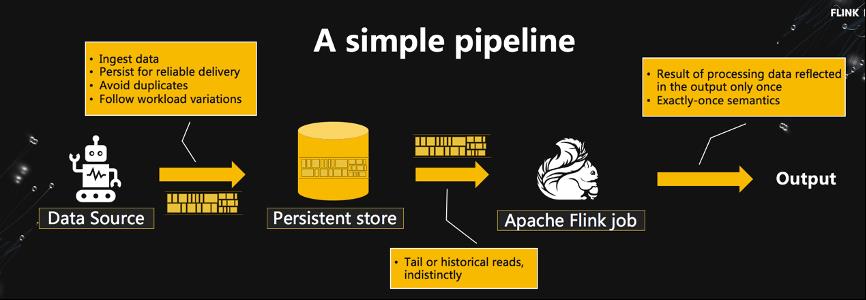
根据上述需求,Dell 科技集团设计了基于 Stream Abstraction 的流式存储系统 Pravega。Pravega 将流存储动态 scaling,动态 scaling 以后如何保证流数据逻辑上有序,流数据定位和寻址以及 checkpointing 等等一系列问题都封装在 Stream abstraction 之下。在这种抽象之下,流式存储可以和流式计算引擎无缝衔接,也给流式计算屏蔽了很多流存储端的复杂性,从而使整个端到端仅一次性处理(exactly once)的 pipeline 被极大的简化(如上图所示)。目前 Pravega 已经是一个 CNCF 开源项目,在 Pravega 最新一期官方 blog(
https://blog.pravega.io/
)中,Pravega 发布了基于 OpenMessaging Benchmark 对比 Kafka 和 Pulsar 的各项性能指标。此外,Pravega 在分会场中有一场关于 Pravega Flink connector 的分享,《Pravega Flink connector 的过去,现在和未来》,感兴趣的同学可以看一下。
除了主会场阿里巴巴,美团,快手,Dell 科技集团的分享,分会场由行业实践,核心技术,开源生态,金融行业,机器学习和实时数仓六个子议题超过 40 家企业机构参与分享,包括天猫,字节跳动,亚马逊,LinkedIn,爱奇艺,蚂蚁,好未来,小米,微博,腾讯,知乎,京东,PingCAP,网易,360 等,后续会有更多的对分会场议题的专场分享文章,敬请期待!
没有一个冬天不能逾越,没有一个春天不会来临。2020 年是不寻常的一年,虽然疫情肆虐,但是 Flink 社区在 2020 年持续繁荣,蝉联最活跃的 Apache 项目;Flink 也成为了事实上的国内外实时计算标准。过去一年,Flink 在流计算引擎内核,流批一体,AI融合,云原生这四个方向上都取得了不错的成绩,未来也会在这四个方向上继续耕进。2020 年是 Flink 的新纪元,流批一体首次在阿里巴巴双十一最核心的业务场景中落地,这将是流批一体在业界大规模推广的起点。未来可期,让我们携手共进,一起努力,把握好机遇共同迎接挑战,共创美好的 Flink 2021!
[2, vldb17] [State Management in Apache Flink]
{https://pdfs.semanticscholar.org/6fa0/917417d3c213b0e130ae01b7b440b1868dde.pdf}
[3] [NEXMark – A Benchmark for Queries over Data] {http://datalab.cs.pdx.edu/niagara/pstream/nexmark.pdf}