从分布式AKF原则的角度看Kafka的架构设计
Posted 行百里er
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了从分布式AKF原则的角度看Kafka的架构设计相关的知识,希望对你有一定的参考价值。
AKF设计原则
在项目规模日益扩大,传统的单体项目无法满足需求的背景下的,也就是当需要「分布式系统」来提供更强的系统性能的时候,我们往往考虑如何进行系统架构和划分,在这种情况下,须有一个系统的方法论,以应对日益复杂的分布式系统。
AKF就是这样一种理论。AKF 可扩展立方 (Scalability Cube),其理论可用三个坐标轴的概念进行概括。
基于X轴水平扩展
这种方式是复制服务和数据,将服务和数据放在多个不同的机器上,以解决服务可用性问题。
也就是将服务运行多个实例,做集群加上负载均衡提供访问,这样可以提升服务的可用性。
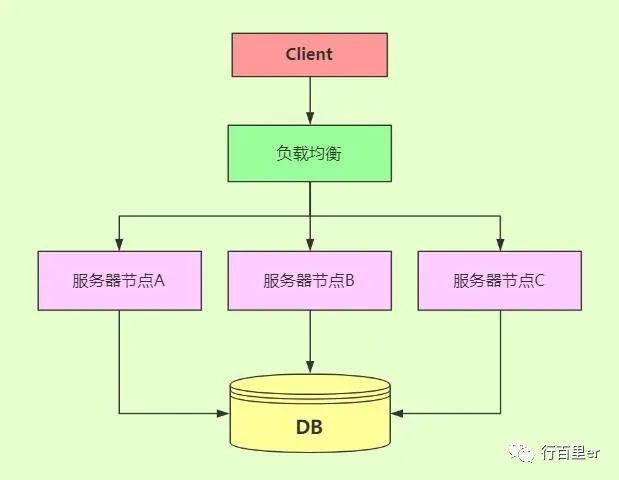
这种方式扩展系统部署方便,负载均衡做好后只需要复制程序到各个服务器节点即可。
但是,如果业务量到达一定级别,用户请求频率变高,此时可以分离业务,这就是AKF原则之基于Y轴扩展系统。
基于Y轴功能划分
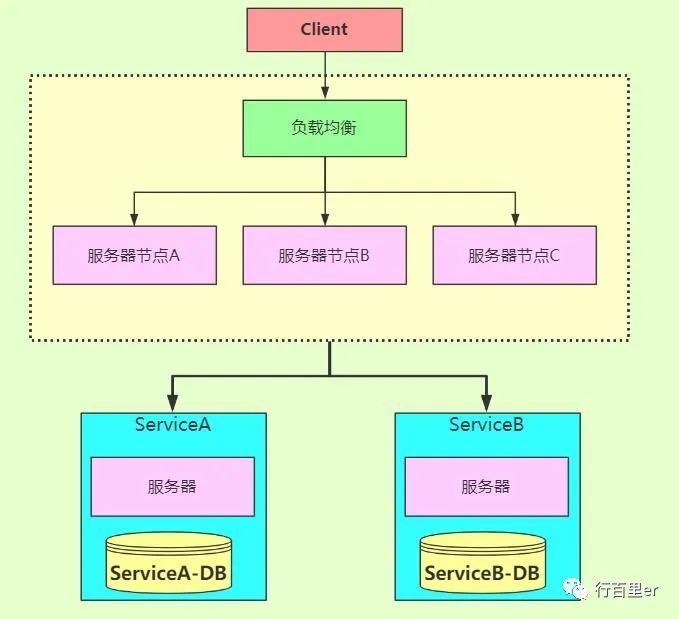
当系统遇到性能瓶颈后,拆分系统功能,使得各组件的职责、分工更细,也可以提升系统的效率。比如,当我们将应用进程对数据库的读写操作拆分后,就可以扩展单机数据库为主备分布式系统,使得主库支持读写两种 SQL,而备库只支持读 SQL。
这种就是在AKF Y轴上进行业务功能上的划分,结合X轴水平复制,能够大大提升系统的性能。
基于Z轴数据分区
Z轴扩展通常是指基于请求和用户独特的需求,进行系统划分,并使得划分出来的子系统相互隔离,但又是完整的。
「关系型数据库常用的分库分表操作就是 AKF 沿 Z 轴拆分系统的实践」。
❝可以体验下mysql的读写分离:
基于ShardingSphere-JDBC的MySQL读写分离
❞
下图中,使用了 2 种 Z 轴扩展系统的方式。首先是基于客户端的地理位置,选择不同的 IDC 就近提供服务。其次是将不同的用户分组,比如乘客用户组与司机用户组,这样在业务上分离用户群体后,还可以有针对性地提供不同服务。
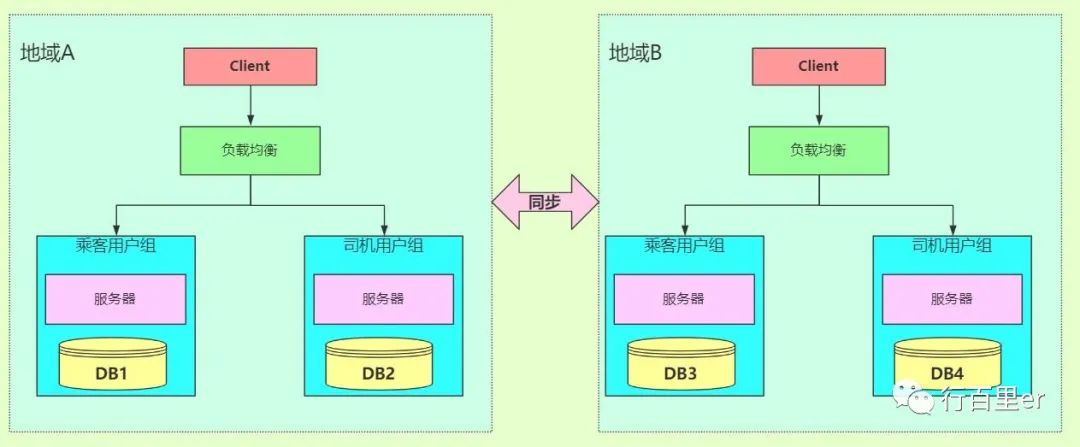
「Kafka一个分布式流处理平台」,说到分布式,我们就从「AKF」的角度来分析一下Kafka的架构设计。
Kafka
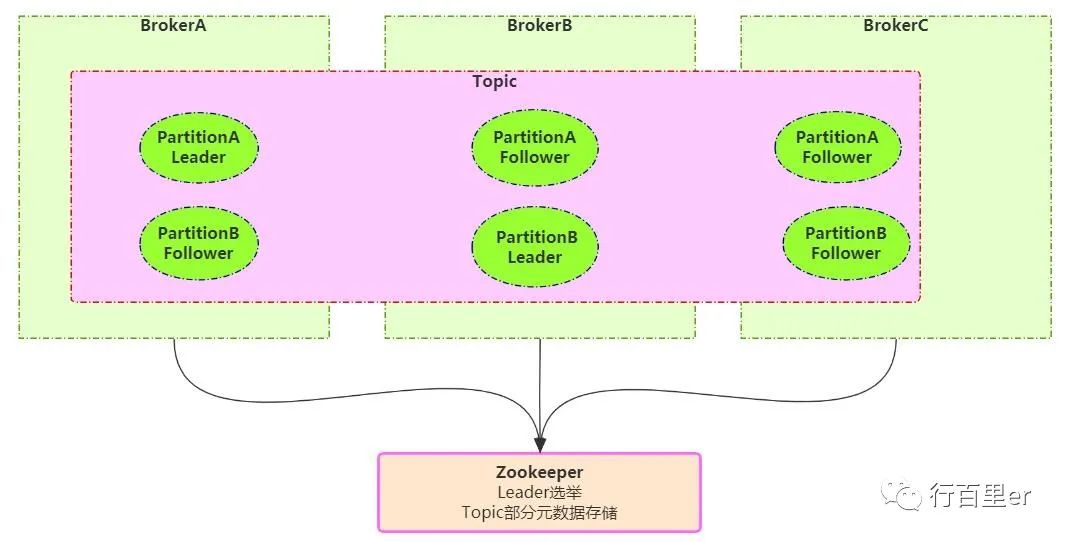
Kafka 基础架构
「Kafka集群以Topic形式负责分类集群中的Record,每一个Record属于一个Topic。」
每个Topic底层都会对应「一组分区的日志」用于「持久化Topic中的Record」。同时在Kafka集群中,Topic的「每一个日志的分区都一定会有1个Borker担当该分区的Leader」,「其他的Broker担当该分区的follower」。
Leader负责分区数据的读写操作,follower负责同步改分区的数据。这样如果分区的Leader宕机,改分区的其他follower会选取出新的leader继续负责该分区数据的读写。
其中集群的中Leader的监控和Topic的部分元数据是存储在「Zookeeper」中。
Topics and Partitions
Kafka中所有消息是通过Topic为单位进行管理,每个Kafka中的Topic通常会有多个订阅者,负责订阅发送到该Topic中的数据。「Kafka负责管理集群中每个Topic的一组日志分区数据」。
「生产者将数据发布到相应的Topic。负责选择将哪个记录分发送到Topic中的哪个Partition。」 例如可以round-robin方式完成此操作,然而这种仅是为了平衡负载。也可以根据某些语义分区功能(例如基于记录中的Key)进行此操作。
每组日志分区是一个「有序的不可变的的日志序列」,分区中的每一个Record都被分配了唯一的序列编号称为是「offset」,Kafka 集群会「持久化」所有发布到Topic中的Record信息,该Record的持久化时间是通过配置文件指定,默认是168小时。
log.retention.hours=168
Kafka底层会定期的「检查日志文件」,然后将过期的数据从log中移除,由于Kafka使用硬盘存储日志文件,因此使用Kafka长时间缓存一些日志文件是不存在问题的。
在消费者消费Topic中数据的时候,每个「消费者会维护本次消费对应分区的偏移量」,消费者会在消费完一个批次的数据之后,「会将本次消费的偏移量提交给Kafka集群」,因此对于每个消费者而言可以随意的控制该消费者的偏移量。
因此在Kafka中,「消费者可以从一个topic分区中的任意位置读取队列数据」,由于每个消费者控制了自己的消费的偏移量,多个消费者之间彼此相互独立。
Kafka中对Topic实现日志分区的有以下目的:
-
首先,它们允许日志扩展到超出单个服务器所能容纳的大小。每个单独的分区都必须适合托管它的服务器,但是「一个Topic可能有很多分区,因此它可以处理任意数量的数据」。
-
其次每个服务器充当其某些分区的Leader,也可能充当其他分区的Follwer,因此群集中的负载得到了很好的平衡。
「Replica」:副本,为实现备份的功能,保证集群中的某个节点发生故障时,该节点上的 Partition 数据不丢失,且 Kafka 仍然能够继续工作,Kafka 提供了副本机制,一个 Topic 的每个分区都有若干个副本,一个 Leader 和若干个 Follower。
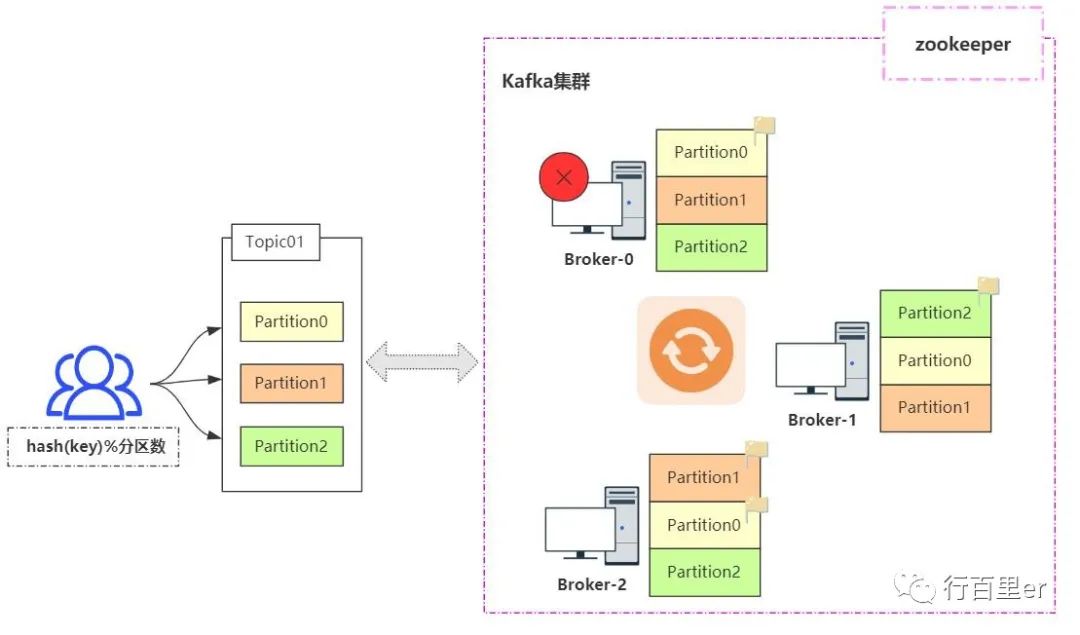
「类比于AKF设计原则,Topic就相当于沿Y轴进行的功能划分,而分区就是沿Z轴进行数据分片分区,X轴就是Partition副本划分。」
小结
-
AKF原则中 「Y轴」一般是基于功能进行划分的,类比于Kafka中的 「Topic」,一般一个业务订阅一个Topic; -
「Z轴」一般是数据分区,类比于Topic中的 「Partition」; -
「X轴」提供高可用,Kafka集群为了高可用,可搭建多个 「Partition副本」,在主节点的Partition上进行R/W。
往期推荐
以上是关于从分布式AKF原则的角度看Kafka的架构设计的主要内容,如果未能解决你的问题,请参考以下文章