ES学习笔记-可视化界面KIbana及ES的增删改查及中文分词配置
Posted 萌萌哒的瓤瓤
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了ES学习笔记-可视化界面KIbana及ES的增删改查及中文分词配置相关的知识,希望对你有一定的参考价值。
「养成习惯,先赞后看!!!」
1.前言
本片博客主要带大家了解一下ES的可视化界面Kibana的安装以及使用.
其次就是ES的基本的增删改查的相关操作.
最后就是就是ES的中文分词的问题.这个具体可以看我关于ES的第一篇博客,里面我详细讲解了ES的搜索算法的重要原理---「(倒排索引)」,正是因为这个,所以我们还需要配置ES的中文分词.
2.可视化界面Kibana
大家使用mysql数据库的时候肯定使用过像Navicat等这些数据库的可视化工具,那么显然Mysql有的,ES肯定也有,ES的可视化工具叫做Kibana,作用呢和Navicat的功能其实是类似的,也是帮助我们能够更加直观的观察ES中各节点以及节点中的相关数据的信息.
了解完Kibana的大体作用之后,我们就来了解一下怎么安装Kibana吧.
-
上传并解压
cd /opt/es
tar -zxvf kibana-6.3.1-linux-x86_64.tar.gz这个过程会比较的长
并不是文件大,而是因为文件的数量比较多
-
在kibana中配置ES的信息
vi kibana.yml
保存退出
-
启动kibana
cd ../bin
nohup ./kibana &

这样我们的kibana就已经启动
即可访问Kibana的页面了
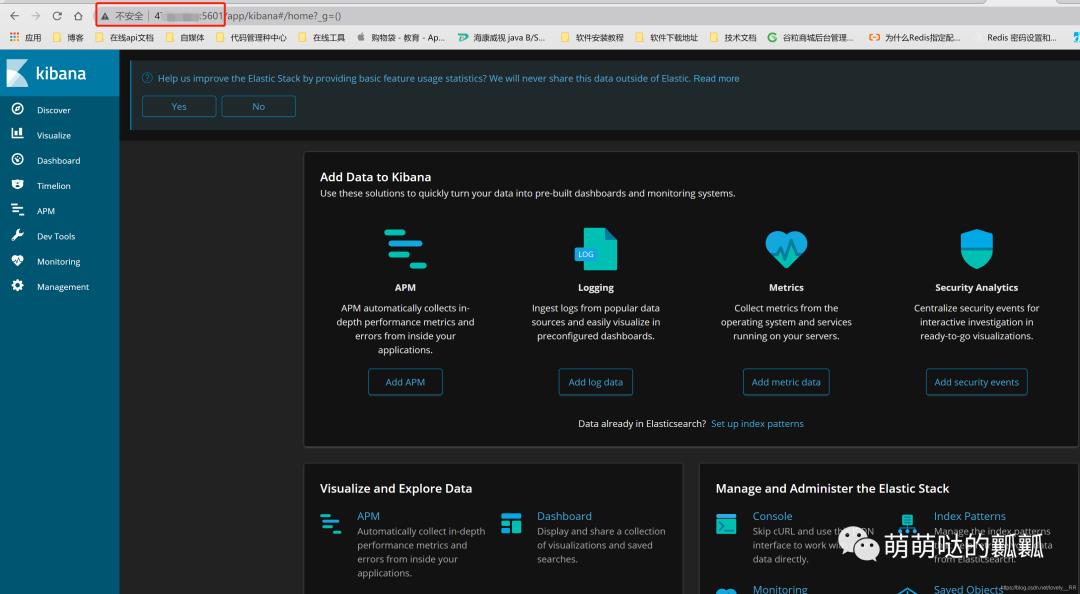
看到这样的页面就说明我们的Kibana已经成功启动并且成功连接到我们的服务器的ElasticSearch了
并且之前我们所有的操作都是在这个界面里面执行的: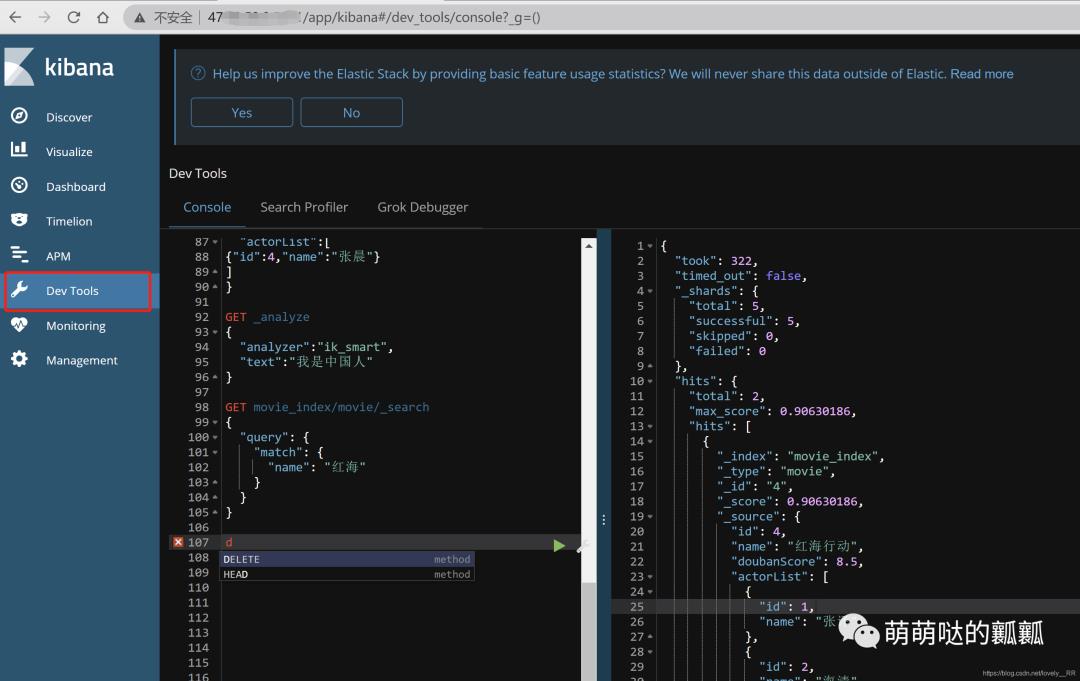
3.增删改查
3.1-增加数据操作
增加一个index及type及document:
PUT /movie_index/movie/1
{ "id":1,
"name":"operation red sea",
"doubanScore":8.5,
"actorList":[
{"id":1,"name":"zhang yi"},
{"id":2,"name":"hai qing"},
{"id":3,"name":"zhang han yu"}
]
}
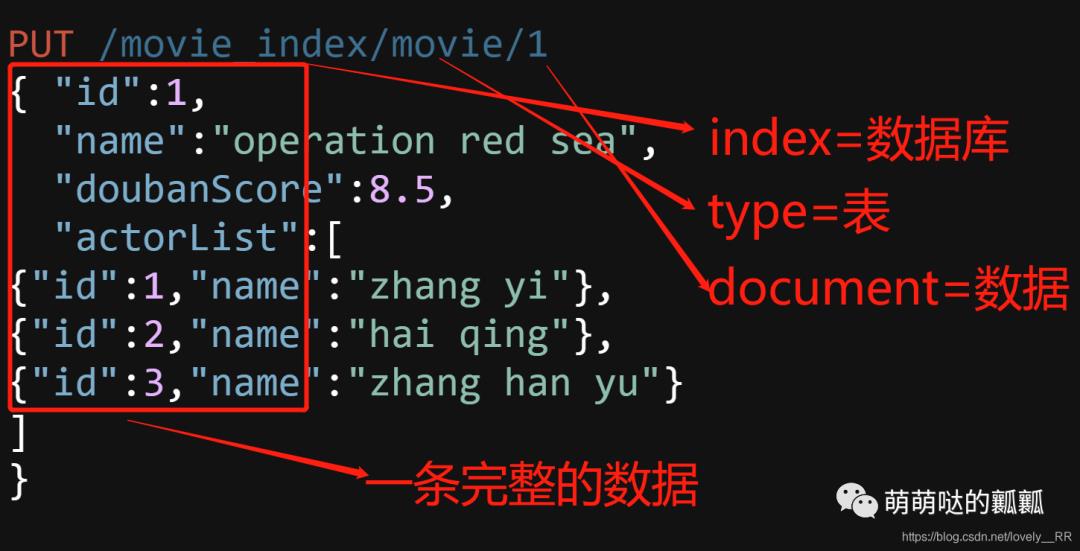
运行之后我们会看到这些结果信息:
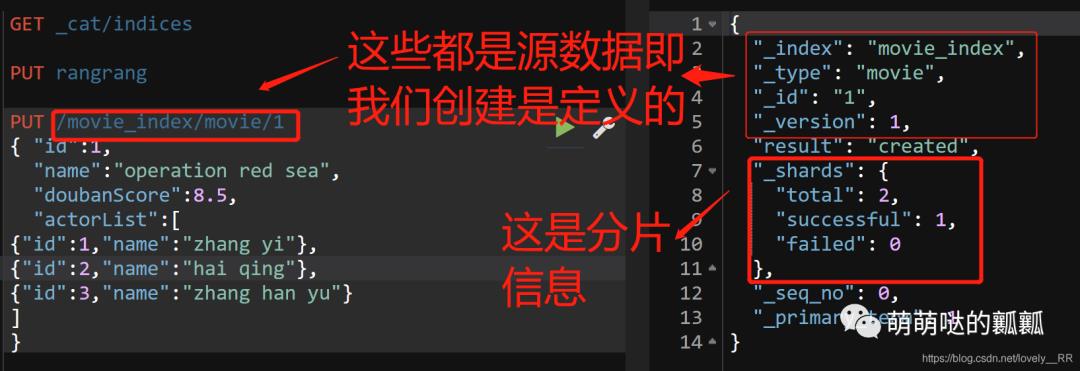
在ElasticSearch中存储数据都是将数据分散存储的即我们所说的 「分片」,这里大家可能会问分片有什么作用呢.这里我们通过一个简单的例子来了解一下分片的作用.
说先第一点就是 「安全」,我们将数据分散存储的话,这样的如果某个分片内的数据失效了,那么显然我们起码能保证其他分片的数据仍然是可用的.这样能够在一定程度上保证数据的安全性
另外一点就是 「效率」,举个例子吧,如果现在我们有1吨=1000斤的水果,这里面有苹果,梨,香蕉等等,我们现在就要把它分类,苹果的放一堆,香蕉的放一堆,如果我现在让你直接将这1000斤水果分出来,那么显然是很难的,但是如果我们先把他分成100份,每份10公斤的话,那么这样分起来就相对简单很多了,这样我们的效率就提高了很多了.
正是因为上面两个原因,ElasticSearch才选择采用分片的方式来存储数据.
之后我们再增加两条信息:
PUT /movie_index/movie/2
{
"id":2,
"name":"operation meigong river",
"doubanScore":8.0,
"actorList":[
{"id":3,"name":"zhang han yu"}
]
}
PUT /movie_index/movie/3
{
"id":3,
"name":"incident red sea",
"doubanScore":5.0,
"actorList":[
{"id":4,"name":"zhang chen"}
]
}
3.2-删除数据操作
删除这个操作也很简单,只需要通过del关键字就能够实现.
DELETE movie_index/movie/2
这里我们选择的是直接删除id为2的这条记录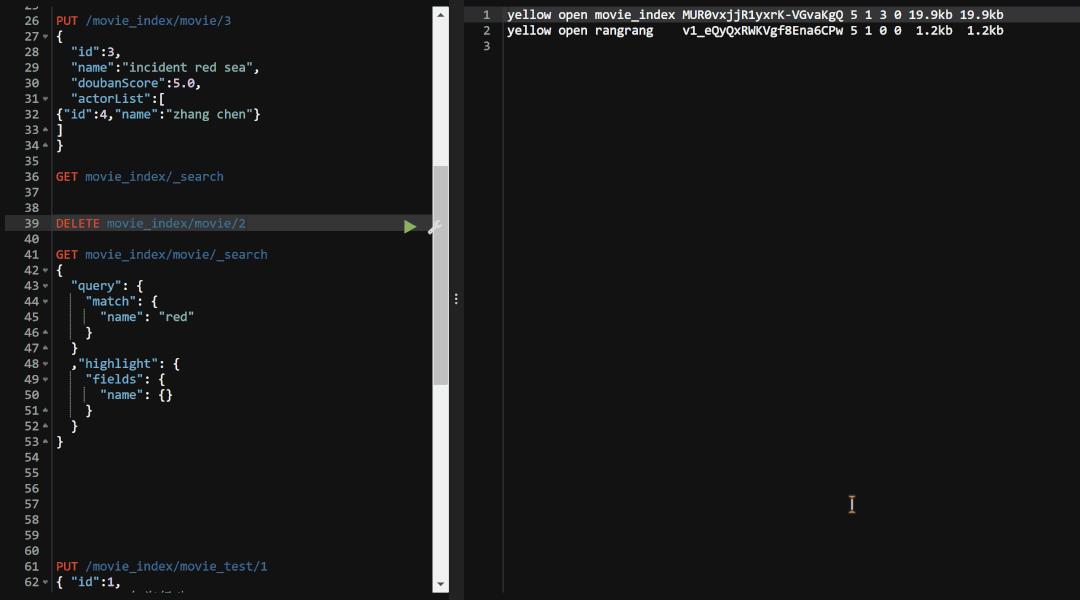 测试完成之后我们的确可以看到id为2的数据已经被删除了,能够删除数据.这里还有一个注意点就是ElasticSearch5.0的版本以后就 「
测试完成之后我们的确可以看到id为2的数据已经被删除了,能够删除数据.这里还有一个注意点就是ElasticSearch5.0的版本以后就 「不再支持删除单个type了」 ,如果去执行该命令的话,我们会看到会报下面的错误
 就是告诉我们是不能直接删除type的,但是我们可以通过 「
就是告诉我们是不能直接删除type的,但是我们可以通过 「POST命令来删除type下面所有的数据或者是直接删除index之后再重新创建type即可」.
这里我们就简单再来看看post命令是如何进行删除操作的.
POST movie_index/movie/_delete_by_query
{
"query":{
"match":{
"name":"red"
}
}
}
这里的"query"就代表我们的删除条件,整段代码的意思就是删除movie_index索引节点下movie这个type里面name里面有red关键字的所有记录.这里我们执行来看看.
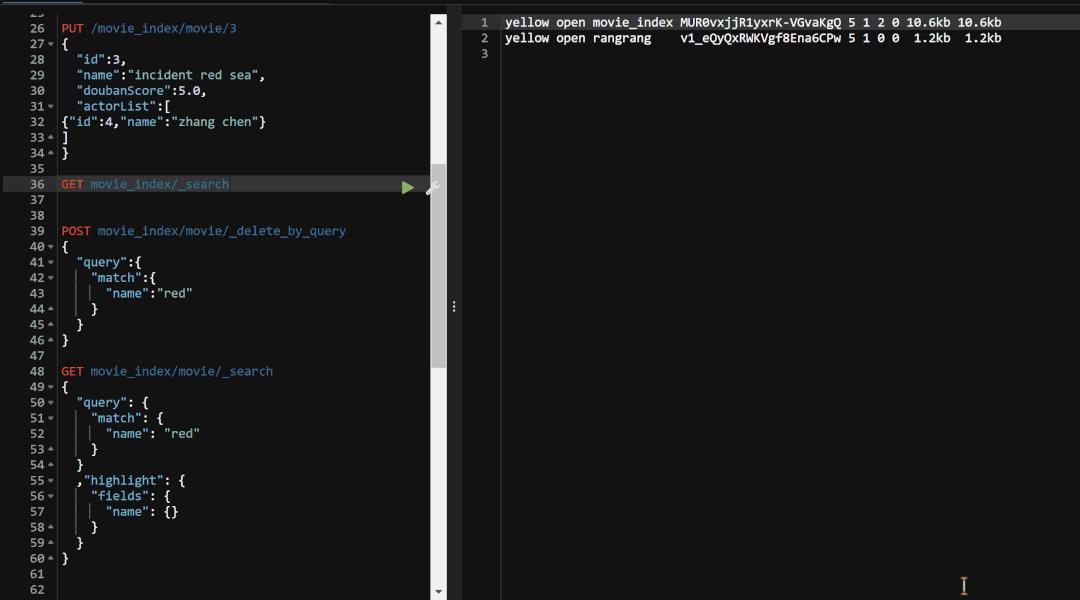 可以看到执行完毕之后,我们type下的两条含有red关键字的数据都已经删除了.这样我们关于删除操作就已经介绍完毕了.
可以看到执行完毕之后,我们type下的两条含有red关键字的数据都已经删除了.这样我们关于删除操作就已经介绍完毕了.
3.3-修改数据操作
讲完删除操作,我们再来看看elasticSearch的修改操作,大家都知道elasticSearch是基于文本的,所以 「文本的修改本质上就是覆盖」 ,所以这里我们还是通过put操作来进行.
在执行修改操作之前我们先将之前我们删除的数据重新添加到我们的索引节点的type下面.
添加完毕之后我们再来看看我们的修改操作,但是呢,在执行修改操作之前呢,我们先来看看我们之前说过的关于elasticSearch6与之前的版本有一个不同的地方就是 「elasticSearch6只支持一个索引节点下面有且只能有一个type」 ,这里我们来测试一下.
测试之后我们能够发现的确能够发现的确只这样,只能一个索引节点下面有且只能有一个type.
再验证完这个之后我们再来看看我们具体的修改操作是什么样的.
PUT /movie_index/movie_test/1
{ "id":1,
"name":"红海行动",
"doubanScore":8.5,
"actorList":[
{"id":1,"name":"张译"},
{"id":2,"name":"海清"},
{"id":3,"name":"张涵予"}
]
}
其实本质上的操作和我们之前的添加操作的代码 是一样的,只需要稍微注意一下id就行了.这样我们再来看看我们执行之后的结果如何吧.
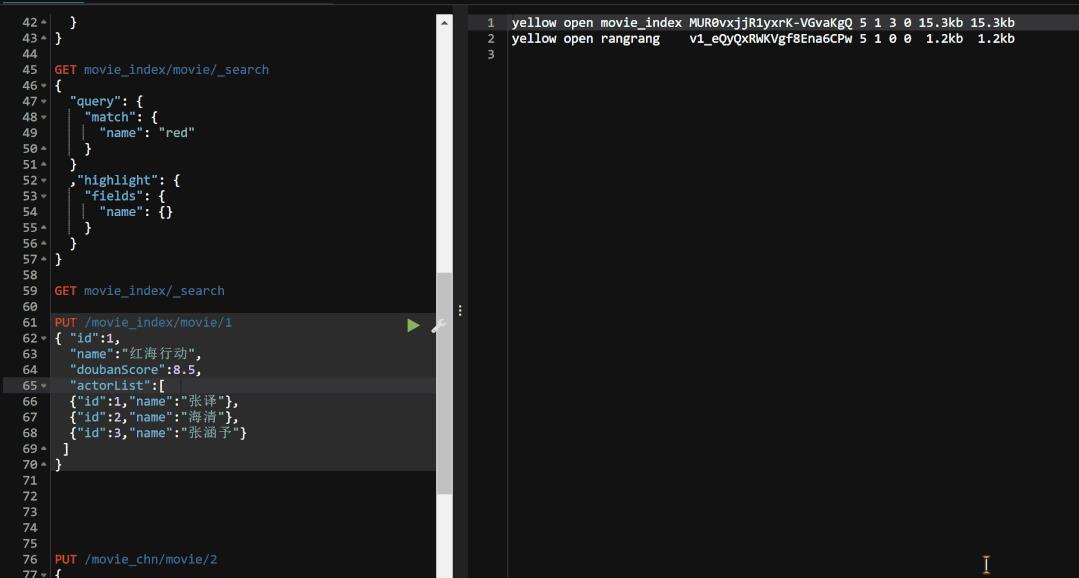
3.4-查询数据操作
在看完修改操作之后就只剩下我们的最后一个查询操作了.接下来我们来查询一下这些数据
GET movie_index/_search
这条语句的操作意思就是查找movie_index节点下的所有信息
查询结果:
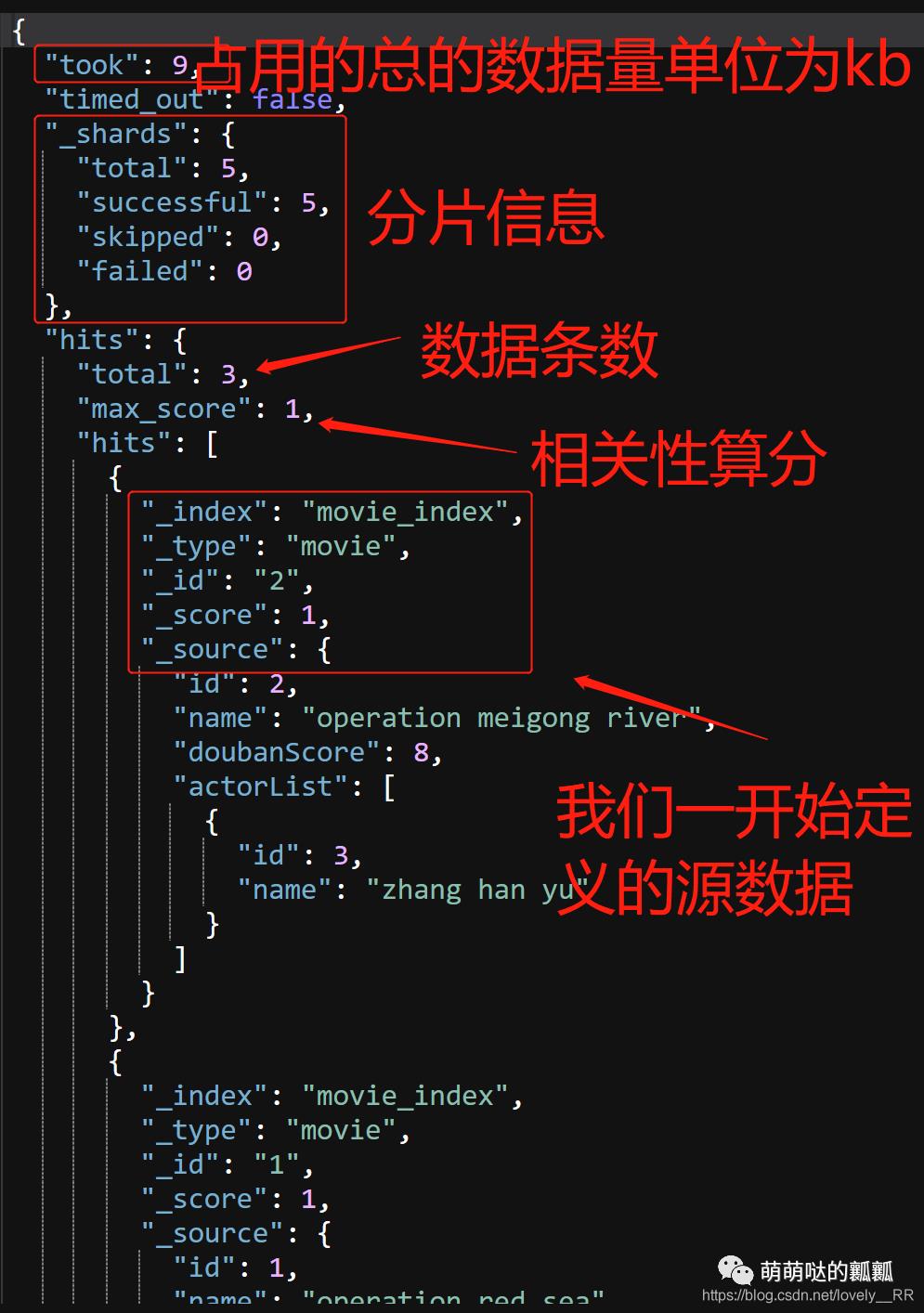
因为我们没有添加任何的 「筛选条件」,所以我们每条数据的相关性算分都是1,在之后我们的查询过程中我们添加完条件之后我们再来回顾就能发现相关性算分的变化了.
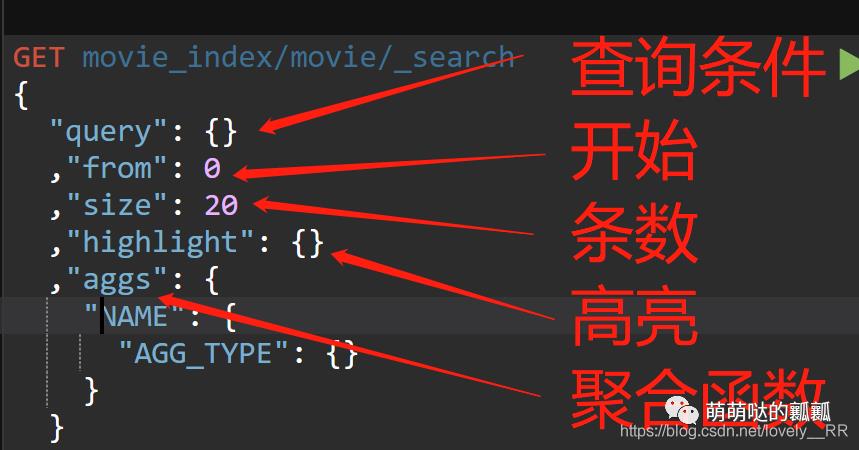
之后我们来看看elasticSearch关于查询的各个命令
GET movie_index/movie/_search
{
"query": {}
,"from": 0
,"size": 20
,"highlight": {}
,"aggs": {
"NAME": {
"AGG_TYPE": {}
}
}
}
3.4.1-关键字查询
我们先来测试一下关键字查询
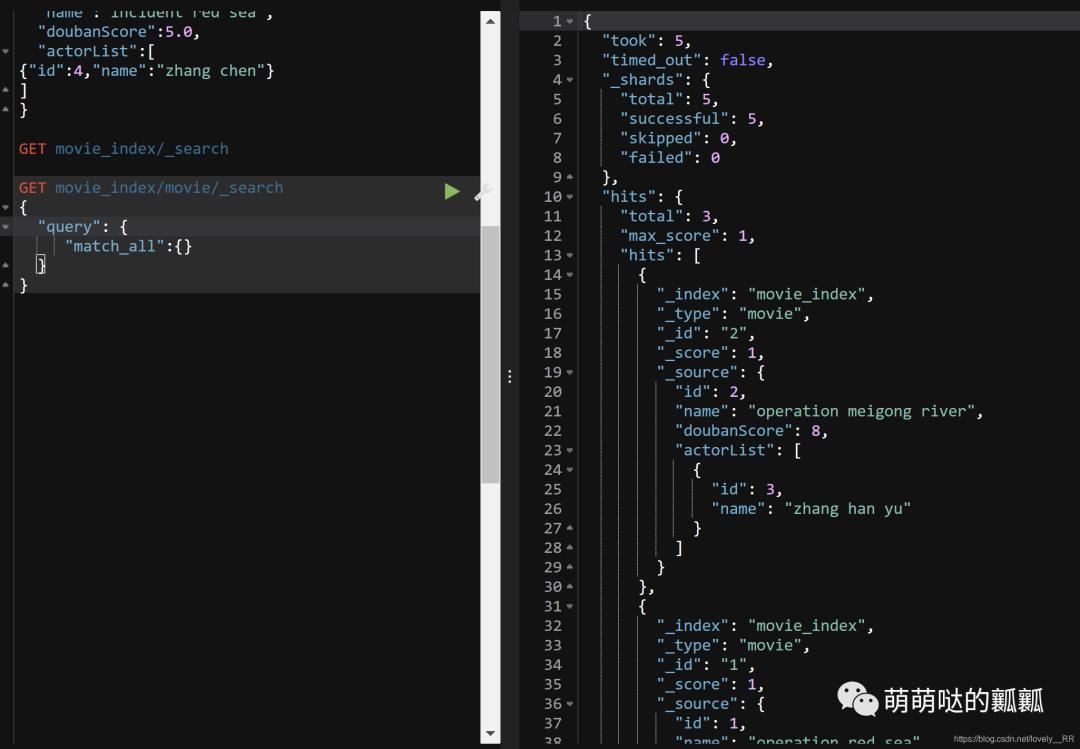
GET movie_index/movie/_search
{
"query": {
"match": {
"name": "red"
}
}
}
这里我们可以看到Field就类似我们数据库中的字段,后面的就是我们需要匹配的内容,并且我们能够看到查询出来的两条数据的相关性算分其实是差不多的.这里 我们猜测可能是通过关键字在该字段出现的频率来计算相关性算分.
这里我们需要注意一点那就是关键字查询中的关键字是不能为空的,通过下面这张图大家就知道什么意思. 大家通过这张图就能理解了,关键字查询是不支持关键字为空的查询的,如果关键字为空的话,那么查询出来是会直接报错的.所以我们必须要添加相应的关键字,如果没有是没有关键字的查询的话,就需要按照下面的样子写,这样就不会报错了.
大家通过这张图就能理解了,关键字查询是不支持关键字为空的查询的,如果关键字为空的话,那么查询出来是会直接报错的.所以我们必须要添加相应的关键字,如果没有是没有关键字的查询的话,就需要按照下面的样子写,这样就不会报错了.
 添加的那段代码的意思就是全匹配,大家应该都能看的懂.
添加的那段代码的意思就是全匹配,大家应该都能看的懂.
关键字查询测试结束之后,我们再来测试一下分页查询.
3.4.2-分页查询
这里的分页查询和mysql中的分页查询操作本质上是没有区别的.
也是只要规定我们的起始点以及页的大小即可.
GET movie_index/movie/_search
{
"query": {
"match_all":{}
}
, "from": 0
, "size": 2
}

可以看到总数据量是三条,但是这里我们查询出来只显示了前面的两条数据,显然分页查询已经执行成功
3.4.3-查询内容高亮显示
测试完分页查询操作之后,我们再来测试一下高亮显示,其实这里的高亮显示是和上面的关键字查询是想匹配的,就和我们正常的高亮显示是一样的,大家想想我们一般会让什么东西高亮显示呢,很明显就是我们需查找的东西.所以高亮显示一般就是与关键字查询相匹配的.
代码如下:
GET movie_index/movie/_search
{
"query": {
"match": {
"name": "red"
}
}
,"highlight": {
"fields": {
"name": {}
}
}
}
highlight里面值需要填写我们对于关键字查询中字段的名称就行了,可以填写额外的字段,但是我们并不知道该字段中需要高亮显示的内容,所以是不会生效的,但是也不不会报错的.
这里我们运行一下看看:
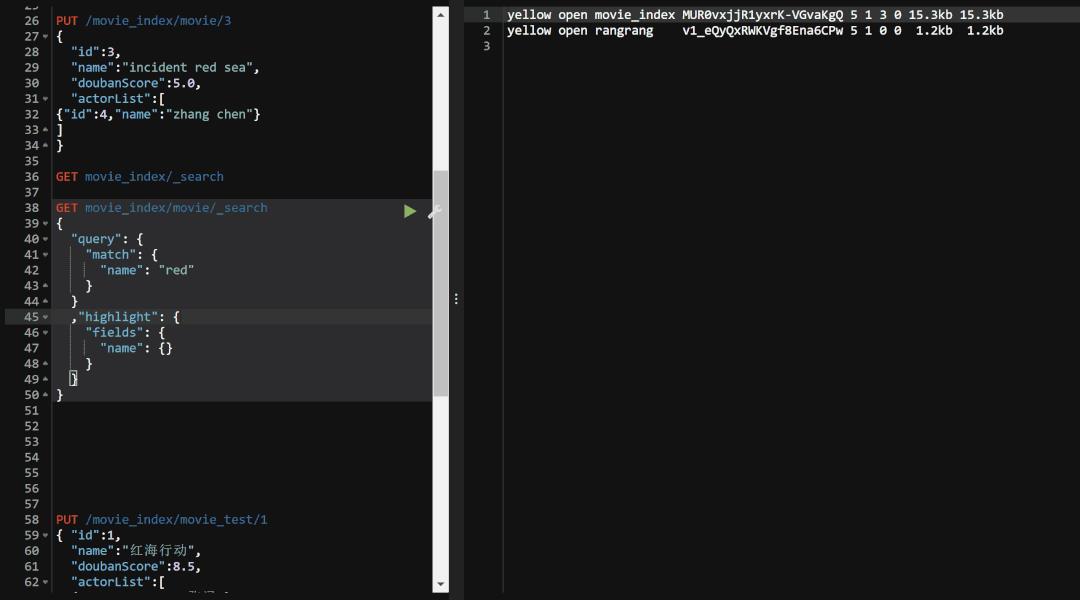 可以看到 「
可以看到 「高亮显示并不是直接将匹配的内容颜色发生改变,而是像html语言一样,添加了一个标记而已.」
3.4.4-聚合函数
测试完高亮显示之后我们最后再来看看聚合函数.
在看聚合函数之前,我们需要了解两个概念.一个就是就是 桶 ,另一个就是 指标 ,这样说大家可能不懂,和我们平常的关系型数据库对应起来,大家就知道他们俩的意思了.
-
桶,类似于数据库中的 「group by」,就好比将我们的数据按照地区分为上海桶,江苏桶等或者是按照性别分为男桶与女桶.主要的作用就是划分 -
指标,类似于数据库中的 「各种数据分析的函数」,像count,max,min,avg等函数.主要的作用就是进行数据的分析.
4.ES中文分词
还记得我们之前讲过的,ES内部的算法是通过 「倒排索引」 的方式来进行的,并且当初我们讲的关于倒排索引的第一步就是先将我们存入数据库的内容进行 「分词」 的处理,所以我们现在就需要测试一下ES的分词操作是否能够正常执行完毕.
我们先来测试一下ES对英文的分词是怎么样的,通过下图我们就能够看出来ES对英文的分词是完全可以的
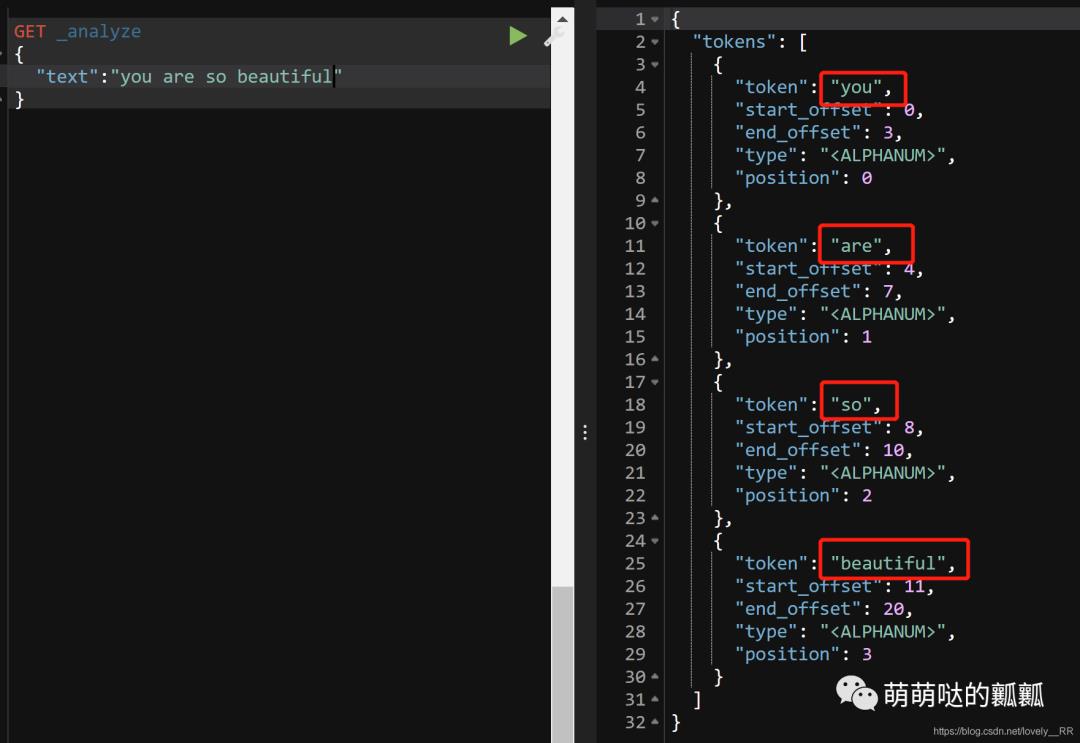 但是很显然我们之后操作的数据肯定都是中文的,所以我们现在需要来测试一下看看ES是否能够识别我们的中文.
但是很显然我们之后操作的数据肯定都是中文的,所以我们现在需要来测试一下看看ES是否能够识别我们的中文.
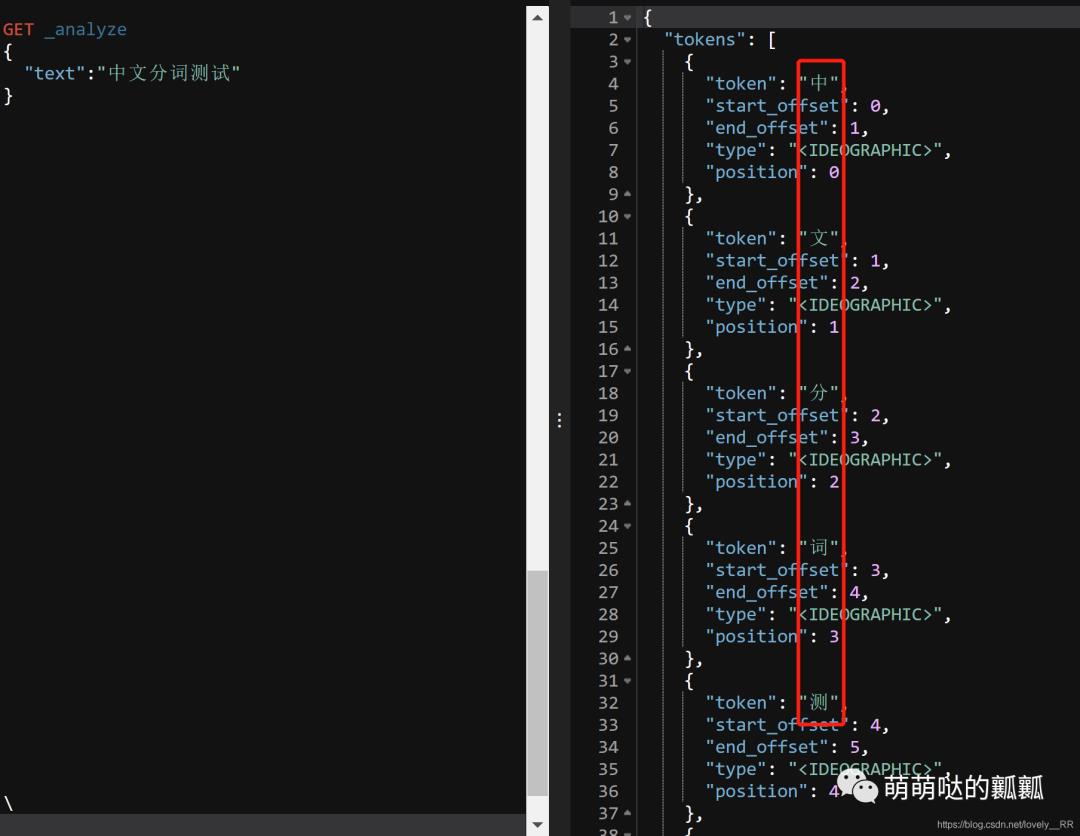
可以看到执行完毕之后我们发现ES是不能够识别中文的分词的.他只能将中文看成是单个字的集合,「并不能够理解词语这个概念」,既然不能够正确识别我们的词语,那么我们现在就需要配置相关的中文分词插件.
我们需要将我们的IK分词器上传到我们ES的plugins目录下面,在这里我们需要注意一点就是「plugins目录下面是专门用来存放我们的插件的」,并且这之后我们需要注意一点就是在:plugins目录下面都是「将单个目录识别成一个插件的」,不能够将一个插件解压成多个文件夹,并且「必须是一个单个的文件夹里面包含该插件的所有配置信息」,并且「不能是多层目录嵌套的那种」,否则都是识别不出来的,具体解压的格式应该是下面这种格式的.

这样的格式才是正确的格式.
解压完成之后,我们就需要将我们的ES重启,这样我们的插件才能够生效.
ES重启之后我们再去看看我们的分词器是否能够正常使用了.我们安装的分词插件是一个叫做IK的分词插件.这个插件有两种分析语法,一种是ik_smart,另外一个就是ik_max_word.
ik_smart就是比较简单的分词器
ik_max_word则是一个功能更加强悍的分词器
这里我们通过下面这个例子就能够看出来了.
这是我们指定分词器是 「ik_smart」 后的分词结果:
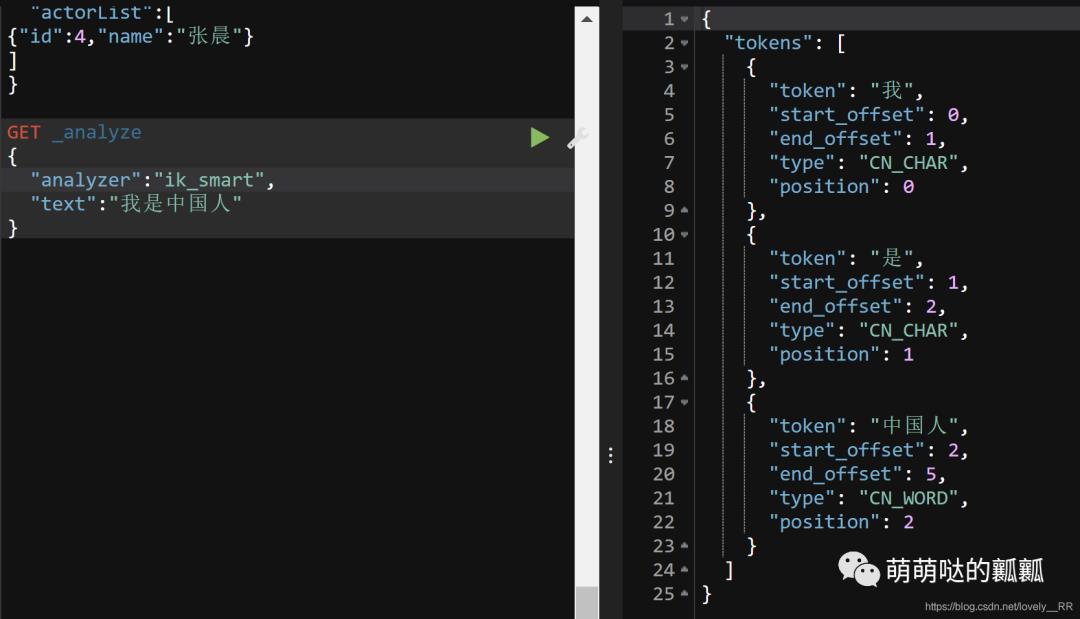
这是我们指定分词器是 「ik_max_word」 后的分词结果:
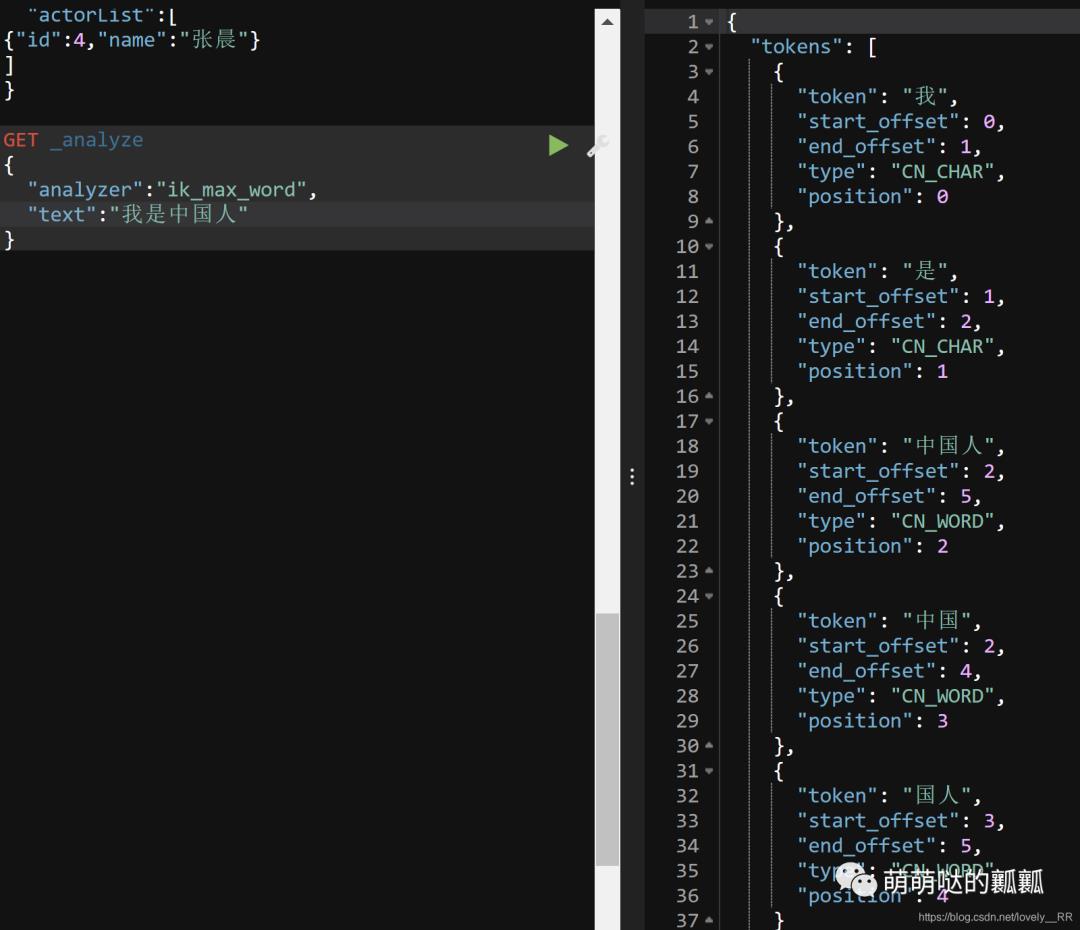
对比上面的结果,我们就能发现的确能够比较明显的看出来ik_max_word分词器的效果是更加强悍的.他不仅是将一句话拆成多个连续的词语,并且像 「"中国人"」 这个词语,他还能分解成 「"中国人,中国,国人"」 三个词语.这样就能够更好的实现分词的效果.
了解完分词之后,我们再来看看分词结果的各个属性分别代表什么意思
这时候大家可能又要说了,为什么需要产生这么一些分词结果呢?这里就要提到我们之前说过的一个概念就是 「相关性算分」 .因为这个相关性算分可能需要知道这个分词是在那里出现的,一共出现了几次等等,这些都是会直接影响相关性算分的结果的,所以分词结果才是这样的.
这样我们的ES中文分词就已经配置完毕了.
「不点在看,你也好看!」
「点点在看,你更好看!」
以上是关于ES学习笔记-可视化界面KIbana及ES的增删改查及中文分词配置的主要内容,如果未能解决你的问题,请参考以下文章