干货 | 一步步拆解 Elasticsearch BM25 模型评分细节
Posted 铭毅天下
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了干货 | 一步步拆解 Elasticsearch BM25 模型评分细节相关的知识,希望对你有一定的参考价值。
Elasticsearch 5 之前的版本,评分机制或者打分模型基于 TF-IDF 实现。
从 Elasticsearch 5 开始,Elasticsearch 的默认相似度算法是 Okapi BM25,Okapi BM25模型于 1994 年提出,BM25 的 BM 是缩写自 Best Match, 25 是经过 25 次迭代调整之后得出的算法,该模型也是基于 TF/IDF 进化来的,Okapi 信息检索系统是第一个实现此功能的系统,之后被广泛应用在不同系统里。
相似性(评分/排名模型)定义了匹配文档的评分方式, 对一组文档执行搜索并提供按相关性排序的结果。在这篇文章中,我们将一步步拆解 Okapi BM25 模型的内部工作原理。
在拆解评分算法之前,必须简单解释一下背后的理论——Elasticsearch 基于 Lucene。要了解 Elasticsearch,我们必须了解 Lucene。
1、Okapi BM25 基本概念
Okapi BM25 模型的计算公式如下:
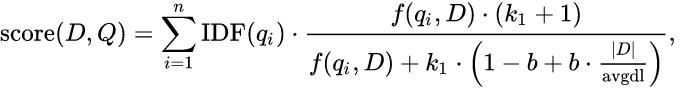
类似的公式,我看到后的第一反应:这是科研人员才能搞懂的事情,我等只能围观。
但,为了进一步深入算分机制,我们一个个参数拆解一下,期望能“拨开云天、豁然开朗”!
上述公式中:
D:代表文档。
Q:代表查询。
K1:自由参数,默认值:1.2。
b:自由参数,默认值:0.75。
参见 Lucene 官方文档:
https://lucene.apache.org/core/8_0_0/core/org/apache/lucene/search/similarities/BM25Similarity.html
2、词频 TF
词频英文释义:TF(Term Frequency) ,即:分词单元(Term)在文档中出现的频率。
由于每个文本的长度不同,一个单词在长文档中出现的次数可能比短文档中出现的次数要多得多。
一个词出现的次数越多,它的得分就越高。
 可以简记为:
可以简记为:
特定分词单元 Term 出现次数 (Number of times term t appears in a document)
TF = ----------------------------------------------
所在文档 Terms 总数 (Total number of terms in the document)
3、逆文档频率 IDF
逆文档频率英文释义: IDF(Inverse Document Frequency),衡量分词单元Term的重要性。
但是,众所周知,诸如“the”、“is”、“of、“that”、“的”、“吗”等之类的特定词可能会出现很多次但重要性不大。
因此,我们需要通过计算以下公式来降低常用分词单元的权重,同时扩大稀有分词单元的权重。
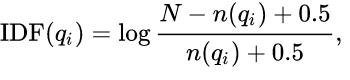
文档数(Total number of documents)
IDF = log ---------------------------------------
包含特定分词单元 Term 的文档数 (Number of documents with term t in it)
4、实战探索
4.1 索引准备
本文基于:7.12.0 版本的 Elasticsearch 进行拆解验证。
创建索引:got,并制定字段 quote 为 text 类型,同时指定:english 分词器。
DELETE got
PUT got
{
"settings": {
"number_of_shards": 1,
"number_of_replicas": 0
},
"mappings": {
"properties": {
"quote": {
"type": "text",
"analyzer": "english"
}
}
}
}
4.2 数据准备
bulk 批量导入数据,数据来自《权利的游戏》电视剧的台词。
POST _bulk
{ "index" : { "_index" : "got", "_id" : "1" } }
{ "quote" : "A mind needs books as a sword needs a whetstone, if it is to keep its edge." }
{ "index" : { "_index" : "got", "_id" : "2" } }
{ "quote" : "Never forget what you are, for surely the world will not. Make it your strength. Then it can never be your weakness. Armor yourself in it, and it will never be used to hurt you." }
{ "index" : { "_index" : "got", "_id" : "3" } }
{ "quote" : "Let them see that their words can cut you, and you’ll never be free of the mockery. If they want to give you a name, take it, make it your own. Then they can’t hurt you with it anymore." }
{ "index" : { "_index" : "got", "_id" : "4" } }
{ "quote" : "When you play the game of thrones, you win or you die. There is no middle ground." }
{ "index" : { "_index" : "got", "_id" : "5" } }
{ "quote" : "The common people pray for rain, healthy children, and a summer that never ends. It is no matter to them if the high lords play their game of thrones, so long as they are left in peace." }
{ "index" : { "_index" : "got", "_id" : "6" } }
{ "quote" : "If you would take a man’s life, you owe it to him to look into his eyes and hear his final words. And if you cannot bear to do that, then perhaps the man does not deserve to die." }
{ "index" : { "_index" : "got", "_id" : "7" } }
{ "quote" : "Sorcery is the sauce fools spoon over failure to hide the flavor of their own incompetence." }
{ "index" : { "_index" : "got", "_id" : "8" } }
{ "quote" : "Power resides where men believe it resides. No more and no less." }
{ "index" : { "_index" : "got", "_id" : "9" } }
{ "quote" : "There’s no shame in fear, my father told me, what matters is how we face it." }
{ "index" : { "_index" : "got", "_id" : "10" } }
{ "quote" : "Love is poison. A sweet poison, yes, but it will kill you all the same." }
{ "index" : { "_index" : "got", "_id" : "11" } }
{ "quote" : "What good is this, I ask you? He who hurries through life hurries to his grave." }
{ "index" : { "_index" : "got", "_id" : "12" } }
{ "quote" : "Old stories are like old friends, she used to say. You have to visit them from time to time." }
{ "index" : { "_index" : "got", "_id" : "13" } }
{ "quote" : "The greatest fools are ofttimes more clever than the men who laugh at them." }
{ "index" : { "_index" : "got", "_id" : "14" } }
{ "quote" : "Everyone wants something, Alayne. And when you know what a man wants you know who he is, and how to move him." }
{ "index" : { "_index" : "got", "_id" : "15" } }
{ "quote" : "Always keep your foes confused. If they are never certain who you are or what you want, they cannot know what you are like to do next. Sometimes the best way to baffle them is to make moves that have no purpose, or even seem to work against you." }
{ "index" : { "_index" : "got", "_id" : "16" } }
{ "quote" : "One voice may speak you false, but in many there is always truth to be found." }
{ "index" : { "_index" : "got", "_id" : "17" } }
{ "quote" : "History is a wheel, for the nature of man is fundamentally unchanging." }
{ "index" : { "_index" : "got", "_id" : "18" } }
{ "quote" : "Knowledge is a weapon, Jon. Arm yourself well before you ride forth to battle." }
{ "index" : { "_index" : "got", "_id" : "19" } }
{ "quote" : "I prefer my history dead. Dead history is writ in ink, the living sort in blood." }
{ "index" : { "_index" : "got", "_id" : "20" } }
{ "quote" : "In the game of thrones, even the humblest pieces can have wills of their own. Sometimes they refuse to make the moves you’ve planned for them. Mark that well, Alayne. It’s a lesson that Cersei Lannister still has yet to learn." }
{ "index" : { "_index" : "got", "_id" : "21" } }
{ "quote" : "Every man should lose a battle in his youth, so he does not lose a war when he is old." }
{ "index" : { "_index" : "got", "_id" : "22" } }
{ "quote" : "A reader lives a thousand lives before he dies. The man who never reads lives only one." }
{ "index" : { "_index" : "got", "_id" : "23" } }
{ "quote" : "The fisherman drowned, but his daughter got Stark to the Sisters before the boat went down. They say he left her with a bag of silver and a bastard in her belly. Jon Snow, she named him, after Arryn." }
{ "index" : { "_index" : "got", "_id" : "24" } }
{ "quote" : "You could make a poultice out of mud to cool a fever. You could plant seeds in mud and grow a crop to feed your children. Mud would nourish you, where fire would only consume you, but fools and children and young girls would choose fire every time." }
{ "index" : { "_index" : "got", "_id" : "25" } }
{ "quote" : "Men live their lives trapped in an eternal present, between the mists of memory and the sea of shadow that is all we know of the days to come." }
{ "index" : { "_index" : "got", "_id" : "26" } }
{ "quote" : "No. Hear me, Daenerys Targaryen. The glass candles are burning. Soon comes the pale mare, and after her the others. Kraken and dark flame, lion and griffin, the sun’s son and the mummer’s dragon. Trust none of them. Remember the Undying. Beware the perfumed seneschal." }
4.3 实施检索
GET got/_search
{
"query": {
"match": {
"quote": "live"
}
}
}
返回结果(仅列举评分、Quote 字段)如下:
| Score | Quote |
|---|---|
| 3.3297362 | A reader lives a thousand lives before he dies. The man who never reads lives only one. |
| 2.847715 | Men live their lives trapped in an eternal present, between the mists of memory and the sea of shadow that is all we know of the days to come. |
| 2.313831 | I prefer my history dead. Dead history is writ in ink, the living sort in blood. |
|---|
这时候会面临我们的终极疑惑——这些评分咋来的?咋计算的呢?
别急,我们一步步拆解。
5、评分拆解
加上 "explain":true 一探究竟。
GET got/_search
{
"query": {
"match": {
"quote": "you"
}
},
"explain": true
}
拿第一个返回文档也就是评分为:3.3297362 的结果数据为例,自顶向下的方法有利于理解计算。
如下拆解结果所示,分数 3.3297362 是分词单元 live 的 boost * IDF * TF 三者的乘积,简记为:
总评分 = 2.2 * 2.043074 * 0.74080354 = 3.3297362。
explain 执行后的结果,核心部分如下所示:
{
"_shard" : "[got][0]",
"_node" : "m9VCQfPDRqqMuupU_Xz5Eg",
"_index" : "got",
"_type" : "_doc",
"_id" : "22",
"_score" : 3.3297362,
"_source" : {
"quote" : "A reader lives a thousand lives before he dies. The man who never reads lives only one."
},
"_explanation" : {
"value" : 3.3297362,
"description" : "weight(quote:live in 21) [PerFieldSimilarity], result of:",
"details" : [
{
"value" : 3.3297362,
"description" : "score(freq=3.0), computed as boost * idf * tf from:",
"details" : [
{
"value" : 2.2,
"description" : "boost",
"details" : [ ]
},
{
"value" : 2.043074,
"description" : "idf, computed as log(1 + (N - n + 0.5) / (n + 0.5)) from:",
},
{
"value" : 0.7408035,
"description" : "tf, computed as freq / (freq + k1 * (1 - b + b * dl / avgdl)) from:",
}
]
}
]
}
}
5.1 词频 TF 拆解
执行 explain 后,词频 TF 拆解计算如下,
{
"value":0.7408035,
"description":"tf, computed as freq / (freq + k1 * (1 - b + b * dl / avgdl)) from:",
"details":[
{
"value":"3.0",
"description":"freq, occurrences of term within document",
"details":[
]
},
{
"value":1.2,
"description":"k1, term saturation parameter",
"details":[
]
},
{
"value":0.75,
"description":"b, length normalization parameter",
"details":[
]
},
{
"value":"14.0",
"description":"dl, length of field",
"details":[
]
},
{
"value":16.807692,
"description":"avgdl, average length of field",
"details":[
]
}
]
}
词频计算涉及参数如下:
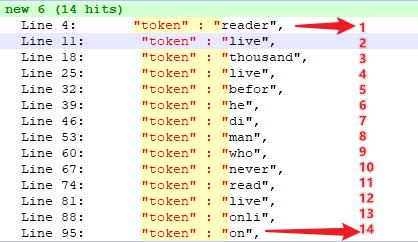
freq = 分词单元 live 在文档中出现的次数为 3 次,如下图所示:

k1:1.2,缺省值。
b:0.75 缺省值。
dl:该文档的分词后分词单元的个数(number of tokens),为 14。
可以借助——analyze API 验证:
POST got/_analyze
{
"text": "A reader lives a thousand lives before he dies. The man who never reads lives only one",
"analyzer": "english"
}
分词后的 token 为:
avgdl:等于所有文档的分词单元的总数 / 文档个数) ,计算结果为:16.807692。
如何计算的呢?这里有同学会有疑惑,解读如下:
avgdl 计算步骤 1:所有文档的分词单元的总数。
如下所示:共 437个。文档数为 26 个。
为了方面查看,我把 26 个文档的全部 document 内容集合到一个文档里面,求得的分词后的结果值为 437 。
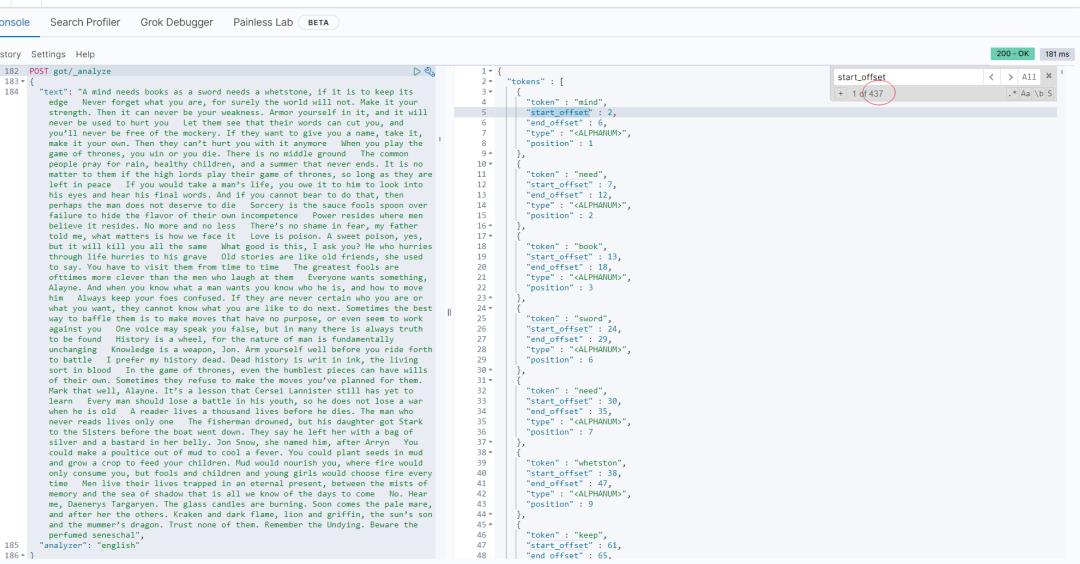
avgdl 计算步骤 2:avgdl = 437 / 26 = 16.807692。
最终 TF 词频 求解结果为:0.740803524(该手算值精度和最终 Elasticsearch 返回结果精度值不完全一致,属于精度问题,不影响理解全局),其求解步骤如下:
TF = freq / (freq + k1 * (1 - b + b * dl / avgdl))
= 3 / (3 + 1.2 *( 1 - 0.75 + 0.75 * 14 / 16.807692))
= 3 / (3 + 1.2 *0.87471397)
= 3/(3+1.049656764)
= 3/4.049656764
= 0.740803524
5.2 逆文档频率 IDF 拆解
执行 explain 后,逆文档频率 IDF 拆解如下:
{
"value":2.043074,
"description":"idf, computed as log(1 + (N - n + 0.5) / (n + 0.5)) from:",
"details":[
{
"value":3,
"description":"n, number of documents containing term",
"details":[
]
},
{
"value":26,
"description":"N, total number of documents with field",
"details":[
]
}
]
}
N:待检索文档数,本示例为 26。
n:包含分词单元 live 的文档数目,本示例为 3。
最终 IDF 求解结果为:2.043074,其计算公式如下:
IDF = log(1 + (N - n + 0.5) / (n + 0.5))
= log( 1 + ( 26 - 3 + 0.5) / ( 3 + 0.5))
= log( 1 + 23.5/3.5)
= log( 1 + 6.714285)
= log(7.714285)
= 2.043074
如上计算对数, 底数为 e。
5.3 总评分拆解
总评分
= boost * TF * IDF
= 2.2 * 0.74080354 * 2.043074 = 3.3297362
boost 为什么等于 2.2 ?
如果我们不指定 boost,boost 就是使用缺省值,缺省值是 2.2。
boost 参见:
https://www.elastic.co/guide/en/elasticsearch/reference/current/search-explain.html
https://www.infoq.com/articles/similarity-scoring-elasticsearch/
6、小结
一步步拆解,才能知道 BM25 模型的评分‘奥秘’所在,原来难懂的数学计算公式,也变得清晰明朗!
有了拆解,再来看其他的检索评分问题自然会“毫不费力"。
本文由英文博客:https://blog.mimacom.com/bm25-got/ 翻译而来,较原来博客内容,增加了计算的细节和个人解读,确保每一个计算细节小学生都能看懂。
欢迎就评分问题留言交流细节。
参考
https://blog.mimacom.com/bm25-got/
https://ruby-china.org/topics/31934
https://www.elastic.co/guide/en/elasticsearch/reference/current/similarity.html
https://lucene.apache.org/core/4_0_0/core/org/apache/lucene/search/similarities/BM25Similarity.html
https://www.elastic.co/guide/en/elasticsearch/reference/current/index-modules-similarity.html
https://nlp.stanford.edu/IR-book/html/htmledition/okapi-bm25-a-non-binary-model-1.html
推荐

更短时间更快习得更多干货!
中国50%+Elastic认证工程师出自于此!
以上是关于干货 | 一步步拆解 Elasticsearch BM25 模型评分细节的主要内容,如果未能解决你的问题,请参考以下文章