[引擎开发] 渲染架构与高级图形编程
Posted ZJU_fish1996
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了[引擎开发] 渲染架构与高级图形编程相关的知识,希望对你有一定的参考价值。
| [本文大纲] 概念引入 图形API设计 OpenGL DirectX GPU驱动架构 Compute Shader Indirect draw 移动端管线架构 Subpass 光照渲染路径 多线程架构 线程竞争 独立渲染/图形API线程 多线程渲染提交 ue4高级图形编程 ue4中的RHI设计 ue4中的多线程架构 ue4中的RDG架构 ue4中的Indirect draw ue4中计算着色器应用 ue4中的移动端渲染 |
(注:本文内容参考了大量公开的技术分享)
概念引入
图形API提供了GPU硬件的访问接口,因此我们可以通过直接通过调用图形API来进行图形引擎开发。但图形引擎通常会在图形API的基础上做一些封装,要么是对常用方法的简单封装,要么是一套较为完整的封装体系。之所以需要引入渲染框架,往往是出于以下原因考虑:
(1) 提高复用性
在图形编程中,我们会有一些比较常用的操作,比如创建屏幕大小的2D纹理,更新顶点等缓冲区的数据等,底层API接口的调用较为繁琐,因此可以对这些常用操作做一些简单封装。
更进一步的,对于图形编程而言,进行效果开发时,我们往往更关注shader编写时渲染数据的输入和输出,而不希望考虑背后数据拷贝和同步、显存分配等细节。为了将这两者更好地解耦,隐藏底层的实现细节,我们需要封装一套简单易用、性能较好的渲染框架,能够以较少的代码量/甚至图形化的形式完成逻辑的开发。
(2)通用调用
为了确保图形引擎能够适配多端,需要支持多套图形API,比如Windows端的DirectX,移动端的OpenGLES, Metal和Vulkan等,为每套API单独维护一套代码是比较繁琐的,因此我们往往考虑在API层进行封装,以便可以用同一套渲染逻辑开发多端的效果。
(3)应用高级策略
为了加快渲染数据的准备,从而提高渲染效率,我们通常会使用一些高级策略,比如多线程渲染、GPU驱动等。
图形API设计
由于渲染架构或多或少都会借鉴一些图形API的设计思想,可能是API的一些名称的沿用,或者是设计的扩展与封装。在对图形API没有基础认知的情况下,可能会难以理解有些架构设计的依据。
OpenGL
种类
OpenGL在多平台上均有对应的实现,包含Desktop OpenGL,以及适用于移动端的OpenGL ES,适用于网页端的Web GL。
OpenGL本身只是一套标准,每个硬件厂商都有自己的实现,比如在移动平台设备上就包含Mali, PowerVR, Adreno等,针对不同的实现,会有不同的适配情况。
ogl
固定渲染管线的代表。管线执行是固定的,无法进行GPU编程,只能通过CPU请求的方式修改GPU的渲染状态,比如修改相机、投影矩阵,请求绘制几何体等。
es3
最重要的变化就是支持了compute shader。
新的扩展:
曲面细分支持
command list支持:NV_command_list
设计
OpenGL是基于状态机的设计。具体表现为,每个状态的请求都使用独立的API,对于同一属性,设置的状态会一直生效,直到下一次状态设置。
我们调用的函数可以划分以下几种类型的:
① 创建/删除对象
如glGenTextures,glGenBuffers,glTextureData,glCreateShader等;
② 设置当前缓冲区
如glActiveTexture,glBindTexture,glBindBuffer等;
③ 设置缓冲区状态
如glEnableXXX,glVertexAttribPointer等;
④ 渲染提交
如glDrawArrays, glDrawElements, glDispatch等;
无论是哪个具体的模块,OpenGL的API设计都基本遵循类似的流程:
初始化数据时,创建-绑定-设置,渲染时,绑定-设置-提交。
OpenGL的语法非常简单直白,相比起Dx, Vulkan这样更偏向工程的设计,非常适合跨平台的应用或者图形算法的快速验证。
DirectX
dx11
dx11中,参数往往通过上下文结构体传递。
工作提交
它包含两种类型的context,一种是即时上下文,这意味着我们的指令会被立刻提交到图形层;另一种是延迟上下文,此时指令将被缓存,在合适的时候才添加到即时上下文并提交到图形层。

资源管理
在资源管理上,dx11将资源简单划分为如下几个类型:
(1)Default。仅GPU读写。
(2)Dynamic。CPU可频繁读写的。
(3)Staging。CPU可读取GPU显存拷贝。
显存由dx11内部分配和管理。
dx12
dx12的几个核心的设计:

GPU驱动架构
Compute Shader
计算着色器没有传统光栅化管线的流程,它的出现主要是为了解决GPU的通用计算问题。我们可以利用计算着色器,使用GPU完成并行计算。计算的结果存储在显存中,可以直接在渲染管线中使用。
通过计算着色器,我们可以完成GPU加速的物理模拟计算,如GPU粒子模拟,布料模拟等;也可以让原本由CPU负责的渲染数据准备工作转移到GPU上,即使用GPU驱动的渲染架构。
基本概念
计算着色器可以实现并行计算,它的基本概念包括输入输出(纹理或缓冲区),并行度(工作组和工作组群),并行任务的同步(共享内存和内存屏障);它们的具体含义如下:
工作组:内部包含了用户定义的工作线程数量,在3D空间中排列,包含三个维度,可以并行执行;
共享内存:工作组内共享的内存,可读写,一般在16k-32k;
工作组群:计算着色器可以创建多个工作组,称为工作组群,并行情况取决于硬件设备支持的并行工作单元;
结果:输出到可写的纹理/缓冲区或结构缓冲区,且任意位置可写;
工作组同步
工作组同步就是让所有工作线程运行到同一个位置,然后再继续执行。
比如在共享内存写入的时候,如果下一个计算的输入依赖于上一个计算的写入,为了保证其它线程的写入已经完成,需要使用工作组同步的功能。
GroupMemoryBarrierWithGroupSync();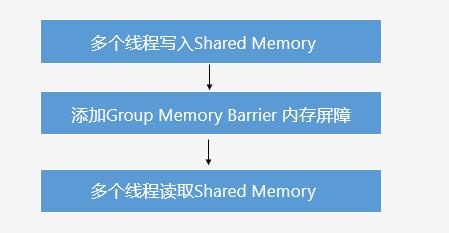
输入参数
GroupThreadID
GroupID
DispatchThreadID
GroupIndex
计算着色器有哪些好处?
① 支持任意位置的写入
相比起PS只能写入当前位置的像素,CS可以写入任意位置的像素。
② 显示地控制同步
通过调用GroupMemoryBarrierWithGroupSync进行主动的线程同步。传统着色器的同步往往是由于并行被打断被动进行同步。
③ 可使用共享内存
使用共享内存有如下优点:
(1)默认情况下我们会使用RT来缓存一些中间计算结果,这会导致计算需要在多个pass完成,并且会导致RT的切换。共享内存可以缓存一些中间的计算结果,支持在一个pass内完成计算,避免RT切换带来的带宽消耗。
(2)缓存贴图的采样来避免重复采样。比如图像空间算法Bloom,Blur,需要采样周围的像素,如果使用PS来计算,同一个像素会被多次采样,而使用CS可以把贴图采样的结果缓存到共享内存中,确保工作组内每个像素只会被采样一次。
(3)缓存复杂的计算结果
④ 原子操作
不同工作线程同时写入同一地址时,原子操作是非常必要的。
⑤ 与传统管线并行
ios设备上完全并行,Mali设备上可以和Vertex Shader顺序执行,和Pixel Shader并行。可以减少输入输出的依赖,提高并行性。
计算着色器有哪些不足?
① 不支持FrameBuffer的压缩
② 不具备纹理读取缓存的硬件优化
在ps中,采样当前uv对应的纹理会更快,因为会预先缓存;
③ 纹理输出格式较少
Indirect Draw
一般情况下,在渲染调用中,我们比较常用的方式是使用CPU来提交渲染指令,准备渲染数据。
具体来说,当我们调用Draw接口的时候,我们就已经在CPU中明确了绘制对象和对应数据。而对于间接绘制而言,我们指定的并不是具体的数据,而是一个缓冲区,这个缓冲区将由GPU进行填充,一般情况下会使用计算着色器来实现GPU的数据填充。
完成了缓存区的填充后,数据将直接传递给顶点着色器进行处理。
Indirect draw的优点
这种做法的好处是,如果由CPU来准备数据,一方面会消耗CPU准备的时间,另一方面需要进行CPU和GPU的大量交互。CPU的处理任务多,时间较长,如果CPU的处理速度较慢,将会成为渲染流水线的瓶颈,降低绘制效率。如果使用GPU进行调度,就可以避免频繁的数据拷贝,并能够并行处理任务,从而加快数据准备的速度,避免其成为渲染流水线的瓶颈,提升绘制效率。
OpenGL的Indirect Draw
直接绘制的情况下,OpenGL提供的非索引版本接口如下:
void glDrawArrays(GLenum mode, GLint first, GLsizei count);glDrawArrays在调用时并没有指定对应的渲染数据,而只是指明了调用的模式和绘制的起始位置、数量等。调用者应该确保当前OpenGL上下文已经绑定相关的缓冲区数据/Shader Program/输入输出。绘制指令将根据当前上下文中的数据进行提交。
而对于非直接绘制而言,OpenGL提供的接口如下:
void glDrawArraysIndirect(GLenum mode, const void *indirect);此时我们不需要显式传输渲染数据,而只需指定indirect buffer。
indirect参数对应着GL_DRAW_INDIRECT_BUFFER的偏移位置。Indirect Buffer对应着这样的结构体:
typedef struct {
GLuint count;
GLuint instanceCount;
GLuint first;
GLuint baseInstance;
} DrawArraysIndirectCommand;这意味着我们只需要在GPU填充这样的结构体数据即可,可以使用计算着色器来完成这一点。
对于索引渲染也有类似的接口。
总体而言,大致的调用逻辑如下:
(1)并使用计算着色器或其它方法完成非直接绘制缓冲区数据的填充;
(2)绑定对应的非直接绘制缓冲区;
(3)调用非直接绘制的接口,指定基元类型以及偏移位置(一般情况不偏移为0);
DirectX的Indirect Draw
void DrawIndexedInstancedIndirect(
ID3D11Buffer *pBufferForArgs,
UINT AlignedByteOffsetForArgs
);在dx11中,我们指定对应的缓冲区,以及缓冲区偏移值。
缓冲区结构需要设置D3D11_RESOURCE_MISC_DRAWINDIRECT_ARGS的标志。
Indirect Draw的应用
(1)基于GPU的剔除
类似基于Hi-Z的遮挡剔除算法是在GPU中实现的,如果物体在CPU中进行收集,那么就涉及到请求GPU执行遮挡剔除,并阻塞等待剔除结果的流程。但在Indirect draw流程中,就无需回读,直接可以将参数传递。
(2)程序顶点
我们可能会涉及到程序生成的网格数据,比如海水,草地,它们属于程序化资源,较少依赖美术资源,因此非常适合使用indirect draw。我们可以直接在计算着色器中生成网格数据以及相关顶点动画。
例子:https://github.com/SaschaWillems/Vulkan/tree/master/examples/indirectdraw
移动端管线架构
我们会在这一章讨论和移动端特性相关的渲染架构设计思想。
之所以要单独讨论移动端,而没有单独讨论PC端,是由移动端的特殊硬件决定的。移动端为了降低带宽消耗,减少手机发烫的情况,在架构设计上相对复杂,也做了不少妥协。针对这种特殊的情况,我们在编写图形管线的时候也应该做一些针对性的优化。而在PC端上就没有类似的问题,我们可以尽可能的使用一些高级特性,包括多核架构来提升渲染性能。
Subpass
subpass是针对移动端TBR/TDBR架构提供的一个渲染优化方案。Vulkan,Metal,OpenGL等图形API对此提供了良好的支持。
在TBR/TDBR架构中,渲染结果不再直接写入framebuffer,而是将把整块framebuffer空间拆成多个Tile,渲染结果会写入Tile上访问速度更快的on-chip memory,在当前帧绘制完成后,再把数据从Tile写入到framebuffer。通过这种方法优化了带宽消耗。
把结果从Tile写入framebuffer的过程称为Resolve,将framebuffer的内容载入Tile称为Restore。
因此,控制什么时候进行on-chip memory和framebuffer的Resolve/Restore能够较好地控制性能。在有些情况下,比如后处理阶段,我们可能需要多个pass来完成后处理操作,并且最终写入的都是同一个渲染目标。此时,我们就可以将后处理的中间结果存储到on-chip memory,等到后处理所有pass完成后,再将数据写入到framebuffer。
基于这一思路,图形API提供了subpass相关的接口,使得我们能够将一些有关联的pass合并。即使图形API层没有较为直接的接口,我们也可以在应用层通过一些渲染框架的封装来实现类似的思想。
Vulkan中的subpass
subpass这一名字源自于Vulkan图形API,Vulkan对该功能做了比较完善的封装。因此,我们先对Vulkan中subpass的设计做简单介绍。
Vulkan本身有RenderPass和subpass的概念,subpass的一些定义由VkSubpassDescription结构描述:
VkAttachmentReference colorReference = { 1, VK_IMAGE_LAYOUT_COLOR_ATTACHMENT_OPTIMAL };
// 1 : Index ..OPTIMAL : attachment type
VkAttachmentReference depthReference = { 2, VK_IMAGE_LAYOUT_DEPTH_ATTACHMENT_OPTIMAL };
// 2 : Index ..OPTIMAL : attachment type
VkAttachmentReference inputReference = { 3, VK_IMAGE_LAYOUT_SHADER_READ_ONLY_OPTIMAL };
// 3 : Index ..OPTIMAL : input type
subpassDescriptions[0].pipelineBindPoint = VK_PIPELINE_BIND_POINT_GRAPHICS;
subpassDescriptions[0].colorAttachmentCount = 1;
subpassDescriptions[0].pColorAttachments = &colorReference; // Output
subpassDescriptions[0].pDepthStencilAttachment = &depthReference; // Output
subpassDescriptions[0].InputAttachmentCount = 1;
subpassDescriptions[0].pInputAttachment = &inputReference; // Input上述代码描述了将一个颜色/深度缓冲区绑定到subpass[0]上,使得subpass内可以写入颜色和深度,并绑定了一个缓冲区的数据作为输入。
OpenGL中的subpass
OpenGL没有直接提供subpass的封装,但是它支持了多个和读写相关的扩展,能够让我们做一些上层的封装:
(1)Framebuffer Fetch:可在Shader中以较低带宽采样MRT,是直接采样的硬件优化版本;
(2)Depth/Stencil Resolve : 可在Shader中获取深度/模板缓冲区;
(3)Pixel Local Storage:可在Shader中读写on-chip memory;
对于subpass而言,我们主要使用Pixel Local Storage扩展。可以在shader中控制数据在on-chip memory读写,从而实现subpass的思想。
需要通过如下宏开启扩展:
#extension GL_EXT_shader_pixel_local_storage : enable我们可以通过扩展指定的格式来自定义在on-chip memory上读写的结构:
__pixel_localEXT FragLocalData
{
layout(r11f_g11_b10f) vec3 Normal;
layout(r11_g11f_b10f) vec3 Color;
} Storage;图形API对subpass的支持
① 所有Vulkan平台都支持subpass
② 所有IOS平台都支持frame_buffer_fetch
③ 只有部分OpenGL(android平台)支持frame_buffer_fetch
(1)Pixel Local Storage : Mail GPU & ImgTech PowerVR GPU支持,Adreno GPU不支持;
(2)FrameBuffer Fetch : Adreno GPU支持,Mali GPU不完全支持。
光照渲染路径
在渲染场景中,我们往往有多种光照和材质,计算不同光照对不同材质的影响是图形编程中非常核心的一个环节。在什么时候,以怎样的形式渲染光照也是渲染架构需要考虑的。
一般来说,我们会根据项目的实际需求,所处的平台特性进行光照渲染路径(Shading Path)的选择。
在移动平台上,在早期阶段,由于手机的带宽有限,往往会选用前向渲染的技术方案,forward+在forward的基础上对光照计算进行剔除。延迟光照通常用于pc或主机平台,但目前也已经开始出现基于移动端优化的延迟光照。
接下来将会对每种渲染路径做一个简单的介绍。
前向光照
前向光照是一个相对简单的渲染路径,在绘制物体的同时直接进行光照的计算,它的优点如下:
(1)实现比较简单
(2)能够实现任意多的着色模型数量
(3)输入参数的数量限制较小
(4)没有额外的带宽和显存占用
(5)能够应用硬件反走样
缺点如下:
(1)无法获取足够多的信息,难以应用一些高级效果(如贴花)
(2)多光照情况下计算量较大,为m(光照数量)* n(物体数量)次,overdraw比较严重
(3)为了处理不同光照类型,shader代码中需要包含不同光照类型的组合,导致shader代码占用内存过大
Forward+
前向光照计算在处理有大量光照的场景时性能会快速地达到瓶颈。针对这一问题,我们对forward算法进行了改进,称为forward+。
场景中主光源的数量是有限的,一般会用到大量光源的情况主要是局部灯光。局部灯光的特点是,只会对场景中的部分物体产生光照影响。因此,我们没有必要对所有物体都计算光照,只需要对受到光照影响的物体进行计算即可。
但是,着色器无法知晓每个对象具体受到哪些光照影响,这就需要我们预先准备这些数据。
为了实现这一点,forward+在forward的基础上在着色阶段前新增了light-culling阶段。我们可以在CPU中实现基于对象的光照记录,但是这种方法并行度较低;也可以在GPU中实现光照记录,一般会使用计算着色器实现对应功能。
由上可见,forward+能够更好地处理多光照的情况,减少不必要的计算,但是也会带来一些管理开销,实现也相对复杂一些。因此我们应该根据场景的实际光照情况选择合适的光照渲染路径。
延迟光照
通俗来说,延迟光照会在后处理阶段进行光照计算。
延迟光照主要分为两个阶段:
第一个阶段,我们渲染所有物体,并将渲染的数据写入到多张渲染目标,称为GBuffer,这些数据包括基本颜色、法线、深度、材质属性等;
第二个阶段,我们根据GBuffer中的信息,进行屏幕空间的光照计算,得到最终渲染的结果。
它的优点如下:
(1)多光照情况下,以较低的复杂度绘制。它的复杂度和物体数量无关,对于m个光源,屏幕空间每个像素只需计算m次。overdraw带来的消耗更低。
(2)记录了GBuffer信息,对一些高级的屏幕空间算法的实现更友好
(3)将材质和光照计算的过程分离,减少所需的shader数量
缺点如下:
(1)用到多张渲染目标,带来严重的带宽消耗和显存占用
(2)材质信息需要记录在GBuffer中,限制了材质的多样性
(3)无法应用硬件反走样,需要自己实现相关AA算法
(4)对透明物体没有较好的处理办法
Tile-Based延迟光照
我们知道移动端无法很好地应用延迟光照主要就是因为带宽问题。随着图形API的发展,近几年也出现了针对移动端优化的延迟渲染,也就是基于前文提到的subpass技术实现的延迟光照。
此时,光照绘制分为两个步骤:
① 物体写入GBuffer,GBuffer存储于on chip memory。
② 利用GBuffer进行光照计算,将最终颜色写入framebuffer。
在此过程中,实际上GBuffer只作为中间过程量存在,因此也就在保留延迟渲染减少overdraw的优点的情况下,避免了GBuffer写入带来的带宽消耗。但同时,也失去了传统延迟光照的一些优点,比如后处理阶段无法利用GBuffer信息作为输入,因为此时GBuffer是memoryless的。
混合管线
在实际的项目中,不同的渲染路径没有绝对的区分,整个管线可能是混合的,比如我们会遇到如下情况:
① 在延迟管线中,大部分光照是后处理完成的,但是仍然有一些简单光照计算可能放到前向阶段就完成了,直接写入到SceneColor中;
② 在延迟管线中,会单独处理透明物体,让其依然按照forward管线进行绘制;
在很多情况下,我们会发现,有些渲染算法本身可能并不复杂,有时候真正的难点在于如何使用一套渲染框架描述尽可能多的着色模型,并且保证性能和易用性。因此,在处理渲染管线时,也会为了更好地适配更多效果做或多或少的妥协,加上各种各样的特殊处理。我们也就会吸取不同渲染路径的优点来实现最终的渲染架构。
多线程架构
线程竞争
在多线程编程中,我们经常会有多线程访问数据的需求,当同一时间有多个线程都想要访问同一个数据时,就会出现线程的竞争。为了解决这一问题,我们主要从两个角度考虑,第一个是针对特定场景从架构上避免线程竞争的发生;另一个是如果无法避免线程竞争应该采用的解决方案。
我们将在这一章节做一些简单的介绍,并在后续多线程编程中进行更为详细的介绍。
(1) 加锁 / 线程安全的容器
这是解决线程之间竞争最通用的一种方法,适用于大部分场景。
当其中一个线程访问数据时,对其上锁,在此期间,其它线程将阻塞等待锁的释放,并行被打断。线程之间的竞争现象越严重,对性能的影响越大。
(2)同步点的设置
我们可以通过设置同步点来确保逻辑的先后执行顺序。较为常见的应用是,当进行多线程数据写入后,应该设置同步点,保证所有数据都已经完成写入。接下来的步骤再访问这些写入的数据才是安全的。
(3)唯一的访问所有权
还有一种比较常见的方案是,只能允许一个线程对数据进行直接访问,如果其它线程也希望访问这一数据,需要请求有权限的线程,具体表现为将添加/修改/删除封装为命令,添加到命令队列中。这意味着这些操作是录制的,是异步请求/延迟发生的。
在图形编程中,我们通常会仅让渲染线程拥有对渲染数据的访问权限。
(4)拷贝数据 / 双队列
对于每帧的渲染数据这种无状态的上下文数据(Context),它的数据传递关系比较简单,通常是在主线程将一些原生数据传递给渲染线程处理。这里可能出现线程竞争的地方是,如果主线程和渲染线程共用同一份数据,当渲染线程处理前一帧数据时,主线程对其访问就会发生竞争。
针对这种情况,我们往往使用双队列(渲染线程和主线程操作自己的队列)或者数据拷贝(每个线程维护自己特定的数据结构)的方式,从根源上避免竞争的问题发生。
(5)环形队列
环形队列通常应用于任务提交,如逻辑线程提交任务,渲染线程执行任务。可仅使用栅栏防止两者同时访问一个数据,避免了对每个数据的读写都要进行加锁操作。
独立渲染线程和图形API线程
独立的渲染线程是指执行准备渲染数据、提交渲染指令过程的线程。这一过程相比起逻辑线程,通常执行时间较长。使用独立的线程可以提高并行度,减少GPU的等待。
此外,为了减轻渲染线程的压力,也会考虑将提交渲染指令这一过程从渲染线程中分离出来,放入单独的图形API线程中。该线程根据渲染线程准备的数据,调用图形API。图形API线程与渲染线程的交互类似于渲染线程和逻辑线程的交互,因此后文将以逻辑线程和渲染线程的交互为例进行介绍。
为什么渲染线程能够提升渲染效率
传统的单线程架构中,我们会在一帧内完成逻辑更新以及渲染绘制。这意味着,当我们在执行逻辑更新时,GPU将进入等待状态。当GPU有机会处于空闲状态时,说明我们没有完全榨干GPU的性能,这带来了资源的浪费。
而将任务并行化后,渲染线程将一直处于活跃状态,此时GPU等待的概率降低,渲染效率得到提升。
另一方面,对于多核CPU硬件,当我们在执行逻辑更新时,有些CPU可能也处于空闲状态,此时并行地执行渲染任务,也能提升CPU的利用率。
概括来说,就是让CPU和GPU时刻都处于高速运转的状态。
逻辑线程和渲染线程
逻辑线程和渲染线程并不是完全独立的,它们存在一定的依赖关系:
(1)渲染线程需要接收来自逻辑线程的指令和数据并执行
(2)逻辑线程有时需要阻塞等待渲染线程的完成
数据访问
在数据访问上,参考线程竞争章节,一般会遵循唯一的访问所有权,并维护拷贝数据或双队列结构。
(1) 双队列结构
其中,双队列结构意味着当逻辑线程往队列A写入的时候,渲染线程读取队列B的内容,等逻辑线程完成了队列A的写入后,交换两个队列。也就是渲染线程读取队列A的内容,而逻辑线程写入队列B。
这样的数据结构可以确保两个线程不会同时访问同一队列,但是,这也意味着两者必须有严格的先后执行顺序。
(2) 拷贝数据
逻辑线程的数据提交到渲染线程时,渲染线程会维护一份独立的数据拷贝。在牺牲一部分空间的情况下,避免数据的竞争。并且该方法对先后执行顺序没有过多限制。
需要注意的情况是指针的拷贝。我们应该尽可能避免指针的浅拷贝,而是直接缓存对应的数据,或者为指针添加引用计数。除非我们能够确保逻辑线程不会直接对指针做修改或销毁的操作,或者确保正确的先后执行顺序。
渲染线程资源访问权
在渲染线程架构里,数据的传输绝大部分都是单向的,也就是只应该从逻辑线程传往渲染线程。当一个数据提交到渲染线程,我们就认为它应该归渲染线程管理,如果想要访问或者修改渲染数据,应该请求渲染线程执行这一操作。
数据的生命周期
在渲染提交过程中,存在两部分数据:
(1)跨帧存储的数据。主要是场景对象数据,包括几何体、灯光等。
(2)每帧的上下文数据。比如当前相机、投影矩阵,渲染状态等。这类数据要么是每帧计算得到的,要么是每次提交指令时重新构造的非缓存状态。
在设计渲染线程的时候,应该合理管理并区分这两种不同生命周期的数据类型。
逻辑线程和渲染线程同步
逻辑线程向渲染线程通过添加指令的方式进行数据和逻辑的交互,命令队列通常由环形队列进行维护。
我们往往用类来封装每个命令,并且将类的结构以字节码(Buffer)的形式进行管道数据传输。
请求分为不需要返回值/同步和需要返回值/同步两种情况。对于前者,通常适用于添加灯光/几何体等简单的请求指令;对于后者,我们可能需要返回值,比如,我们在逻辑层请求渲染线程对当前画面进行拍摄,并能在逻辑线程读取这张快照。
返回值的读取分为同步和异步两种。同步意味着我们将堵塞等待,异步意味着我们将设置一个同步点,当渲染线程完成当前命令后,发起异步回调。
多线程渲染提交
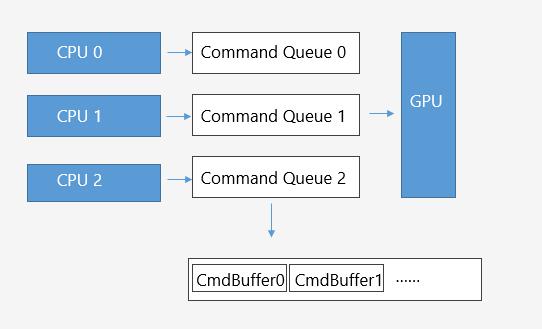
多线程渲染提交是指渲染指令的异步提交,这需要图形API和硬件的支持。
这意味着我们可以异步地通过图形API渲染指令提交到不同的命令队列。
多线程渲染提交能够很好地减轻CPU到GPU传输数据的压力,提升drawcall效率。
如图所示,独立的渲染线程意味着Command Queue的提交在渲染线程上完成,而多线程渲染意味着可以有多个CommandQueue同时运行。
ue4高级图形编程
ue4中的RHI设计
RHI,即Render Hardware Interface,它基于不同的图形API以及硬件,封装了统一的渲染逻辑,隐藏了图形API的底层实现逻辑。ue4的渲染接口封装风格语法更接近现代语法的DirectX,渲染指令将通过RHICommandList设置。
统一封装
对于调用者而言,只需执行RHI层提供的统一图形接口,函数内部将通过GDynamicRHI指针索引到对应的图形API实例。对于相同的代码,GDynamicRHI在不同平台下将会实例化为不同的对象,比如,在pc机上将调用directX,在移动设备上则会调用metal/OpenGL等。
以纹理创建为例,DynamicRHI就包含了如下多种实现:
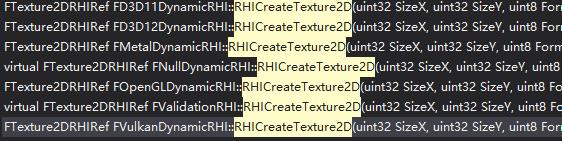
RHI的封装从封装粒度来区分,包含两种不同的类型:一种是对图形API的直接转发,另一种是对图形API的简单二次封装。
ue4中的多线程渲染
数据的线程安全
(1)几何体独立的线程数据
对于每个对象的几何体数据,在不同线程有各自的数据结构,分别是MeshComponent,Scene Proxy和Vertex Factory:
① UPrimitiveComponent对应游戏线程私有的几何体数据;
② FPrimitiveSceneProxy/FPrimitiveSceneInfo对应渲染线程中的几何体数据,它用于准备渲染数据时,组装几何体数据,以便生成对应的渲染指令;
其中,Proxy用于数据从游戏线程到渲染线程的交互,而SceneInfo是渲染线程私有的。
③ FVertexFactory对应于RHI层的网格数据,FMatertial对应于RHI层的着色器数据
之所以要封装多个结构,并在不同结构之间拷贝数据,是出于线程安全考虑。为了避免资源竞争,ue4采取的办法就是在不同线程进行数据交互时,记录独立的数据拷贝。
(2)独立线程数据结构间数据的传递
初始化:
在游戏线程中,我们通过调用FScene::AddPrimtives(RendererScene.cpp),创建FPrimitiveSceneProxy,再基于SceneProxy创建对应的SceneInfo。
在渲染线程中,将SceneInfo加入到对应的Primitives数组中。
修改:
游戏线程修改了PrimitiveComponent属性后,需要调用MarkRenderStateDirty来通知渲染线程更新数据。
渲染线程检测到RenderState状态发生变化后,会先销毁原有RenderState并请求创建新的RenderState。
(3)线程竞争
虽然ue4已经提供了线程独立的数据结构,但是如果在Proxy中传递指针或引用,依然存在风险。
比如我们将一个UObject传递给Proxy结构,此时如果在渲染线程中访问这个数据,就可能会有线程竞争的问题,因为这个数据可能已经被游戏线程回收了。
为了避免这个情况,我们可以:
① 尽量存储对应的数据而不是使用指针的直接复制;
比如我们想要在渲染线程访问AActor的一个值属性,可以直接在Proxy中镜像这个属性,而不是缓存AActor指针。
② 尽可能从设计上避免在游戏线程和渲染线程访问同一份数据;
一些渲染线程特有的函数使用_RenderThread的后缀,这些函数操作渲染线程私有的数据。
③ 确保渲染线程引用数据的时候,数据不会被删除;
比如在UPrimitiveComponent准备销毁自身的时候,可以添加一个DetachFence,等到渲染线程完成后,gc再去真正销毁数据。
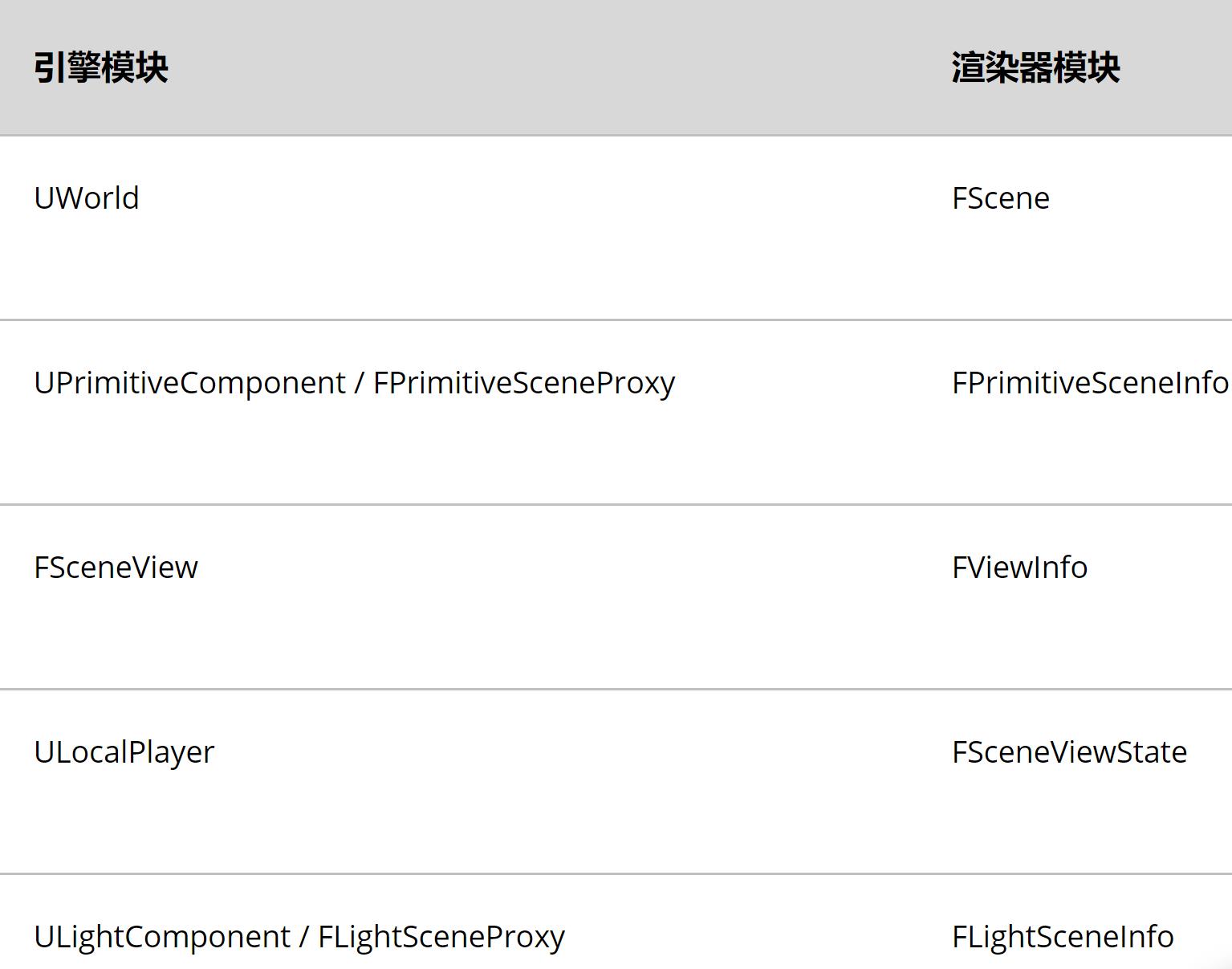
(4)其余独立的线程数据
除了几何体有独立的线程数据外,大多数常见的结构也有各自对应的结构。一般而言,游戏线程数据结构以U开头,渲染线程数据结构以F开头。
比如,UWorld对应于FScene,FSceneView对应于FViewInfo。
(5)显存数据管理
如上所提,ue4维护了以F开头的显存数据。这些数据是仅渲染线程可访问的。如果游戏线程希望访问渲染数据,需要使用间接的方式,即通过命令队列来完成。
举例而言,如果我们希望释放纹理资源,应该通知渲染线程来完成这一操作。这个操作不是立即执行的,而是会加入到渲染队列,按序执行。
void UTexture::ReleaseResource()
{
if (Resource)
{
// ...
ENQUEUE_RENDER_COMMAND(DeleteResource)([ToDelete = Resource](FRHICommandListImmediate& RHICmdList)
{
ToDelete->ReleaseResource();
delete ToDelete;
});
Resource = nullptr;
}
}渲染线程
ue4包含了主线程,渲染线程以及(可选的)RHI线程。
主线程通过抽象的命令队列向渲染线程添加命令,渲染线程通过图形API的命令队列向图形管线添加命令。
由于渲染线程较为耗时,它往往大幅落后于游戏线程,为了减少两者的差距,游戏线程在Tick结束后会阻塞等待,直到渲染线程仅落后于游戏线程一两帧左右。
线程通讯
我们通过如下宏从主线程向渲染线程添加命令:
ENQUEUE_RENDER_COMMAND(CommandName)(LambdaFunction);较早的ue4版本中,添加命令的宏还有_ONEPARAM, _TWOPARAM的后缀,目前已经借助匿名函数实现了无需指定参数数量的通用形式。需要注意的是,匿名函数的传参应该为值传递。
可以看出相当于调用了EnqueueUniqueRenderCommand函数,并传入lambda函数作为函数参数:
#define ENQUEUE_RENDER_COMMAND(Type) \\
struct Type##Name \\
{ \\
static const char* CStr() { return #Type; } \\
static const TCHAR* TStr() { return TEXT(#Type); } \\
}; \\
EnqueueUniqueRenderCommand<Type##Name>在实际调用中,如果支持独立的渲染线程,则会根据传入的CommandName生成一个继承自FRenderCommand的渲染指令类,并基于这个类请求TaskGraph构造一个任务。
template<typename TSTR, typename LAMBDA>
FORCEINLINE_DEBUGGABLE void EnqueueUniqueRenderCommand(LAMBDA&& Lambda)
{
QUICK_SCOPE_CYCLE_COUNTER(STAT_EnqueueUniqueRenderCommand);
typedef TEnqueueUniqueRenderCommandType<TSTR, LAMBDA> EURCType;
if (IsInRenderingThread())
{
// ...
}
else
{
if (ShouldExecuteOnRenderThread())
{
CheckNotBlockedOnRenderThread();
TGraphTask<EURCType>::CreateTask().ConstructAndDispatchWhenReady(Forward<LAMBDA>(Lambda));
}
else
{
// ...
}
}
}线程同步
当我们希望同步游戏线程和渲染线程时,可以在游戏线程中新建一个fence,即 FRenderCommandFence::BeginFence,此时,相当于往命令队列里添加了一个任务;然后调用FRenderCommandFence::Wait进行阻塞,相当于等待刚刚加入的任务被触发;或者调用IsFenceComplete或GetNumPendingFences去查询当前任务是否已经完成。如果新加入的空任务被触发,意味着同步完成了。
此外,也可以调用FlushRenderingCommands阻塞游戏线程,使得渲染线程完全赶上游戏线程。
并行提交
ue4支持并行地提交渲染指令。
常用的资源屏障设置,设置Shader参数,创建缓冲区或缓冲区等都属于渲染指令。
并行提交包含了两个模块,一个是CPU端支持任务的并行提交,这可以通过ue4的TaskGraph系统完成,根据预设的每个任务处理最少指令数和线程数进行任务分配;
另一部分是GPU端需要支持任务的并行处理,这需要图形API的支持。比如dx11的延迟提交,dx12的多个command list。
当我们调用CommandList的函数RenderFunction时,内部通常会根据当前是否支持并行渲染,来选择立即执行渲染指令,或是添加渲染指令到渲染队列中。
void RenderFunction()
{
if (Bypass())
{
GetContext().FunctionName();
}
else
{
ALLOC_COMMAND(PassClassName)();
}
}通过ALLOC_COMMAND宏,我们从内存管理器申请了新的指令空间,并将指令添加到CommandLink链表结构中。
添加到队列中的指令,将在FRHICommandListExecutor::ExecuteList调用后执行。

并行提交包含异步提交和非异步提交。
对于异步提交而言,将创建一个“分发任务”的任务,该任务将作为调度者,异步创建RHI相关的异步任务;而对于非异步提交而言,则会立刻创建RHI相关的异步任务。
线程同步
和游戏线程调用FlushRenderingCommands一样,如果希望RHI完全追上渲染线程的速度,也可以调用ImmediateFlush函数进行同步。
根据同步的情况不同,分为几个等级的同步策略:
① 仅等待WaitOutstandingTasks队列里的任务完成;
② 强制执行命令队列里的命令;
③ 强制执行命令队列里的命令,并等待异步分发任务完成;
④ 强制执行命令队列里的命令,并等待异步分发任务和RHI任务完成。
⑤ 强制执行命令队列里的命令,并等待异步分发任务完成和RHI任务完成,且刷新资源和PSO状态。
可以看出,从③到以上才开始涉及到线程间的同步,而这样的同步在渲染逻辑中并不会过多的出现。更多会被使用到的是第②级的强制执行命令,这使得渲染端可以主动地控制指令执行的时间点,因此它会在整个主渲染流程中被反复调用。
其中强制执行命令分为两个情况,一个是RHI位于独立线程,一个是无独立线程。
对于独立的RHI线程,我们需要执行如下几个步骤:
(1)清空已经完成的任务事件;
其中RHIThreadTask和PrevRHIThreadTask记录普通的分发任务,RenderThreadSublistDispatchTask记录异步分发任务的任务
(2)缓存获取当前的任务队列,并创建新的任务队列用于下次使用;
(3)如果支持异步提交,那么我们创建异步提交的任务,并且需要标记每个分发任务与事件的对应关系,使得同步时能够知道应该等待哪个事件来确保执行完成;否则,直接添加RHI的任务,并记录上一个RHI任务;
(4)如果需要强制刷新队列,则应该分别等待SublistDispatchTask和所有RHIThreadTask;
而对于非独立的RHI线程,我们直接等待所有任务完成后,清空任务队列。
ue4中的Indirect draw
Indirect draw更适用于一些程序化资源,比如地形、水体、植被等。ue4中也有少量的indirectdraw的实例,可以作为参考。
绘制时调用的核心API为RHI层的DrawPrimitiveIndirect/DrawIndexedIndirect。
一个使用的实例就是应用于水面上的Tiled Screen Space Reflection。
首先使用一个计算着色器,将屏幕划分为多个tile,并判断每个tile中是否包含水体(通过shadingmodel),接下来利用输出的多个tile信息,通过indirect draw,只对包含水体的tile进行屏幕空间反射的计算,最后再将反射/天光/IBL等和水体效果结合。
概括而言,indirect draw的实现主要包含两步,一步是使用cs生成水体的TileBuffer,另一步是利用TileBuffer进行indirect draw的SSR。使用indirect draw主要的好处在于可以仅在一个drawcall期间完成多个Tile的处理,而无需逐Tile进行drawcall。
ue4中的RDG架构
RDG,也就是渲染依赖性图表(Rendering Dependency Graph),这是一个基于图表的调度系统,是ue4提供的一套渲染框架解决方案。
它开放和传统渲染框架类似的接口,比如创建纹理、缓冲区等。但和传统渲染框架即时执行不同,RDG是延迟的,它会在收集完当前帧的所有指令后,再根据已有信息进行合理的调度和执行。
例如,RDG会考虑到如下细节:合理调度计算密集型和带宽密集型的渲染指令,合理的资源屏障设置和同步策略,合理的内存和生命周期管理等。
RDG的原理简介
我们在图形编程,尤其是在有多个pass阶段的情况下,会遇到比较复杂的引用关系,比如我们需要在一些pass中写入某些数据,并在另一些pass中读入这些数据,形成资源读写依赖关系;又比如两个pass可能都只需要同一个只读数据的输入,形成非依赖但引用资源的关系。这就需要我们仔细地考虑pass顺序的先后,资源引用带来的屏障设置,避免同一资源引用时每个pass都反复解析等等。
RDG框架的诞生就是为了自动处理这些繁琐的操作,让图形编程者从复杂的依赖引用关系中解放出来,更好地关注于图形算法本身的实现细节。
RDG使用例子
RDG架构模拟了即时调用模式的接口设计,两次Execute调用间不会保留任何状态,每次调用都将重建整个图形依赖关系。
对于使用者而言,只需定义RDG实例,设置相关数据并执行。举例来说,对于绘制深度的Pass而言:
if (bShouldRenderCustomDepth)
{
FRDGBuilder GraphBuilder(RHICmdList); // 1.定义RDG
RenderCustomDepthPass(GraphBuilder); // 2.设置相关数据
GraphBuilder.Execute(); // 3.执行
}对于深度绘制这一pass,设置相关数据包含了这些操作:
① 请求分配当前pass的参数:
FCustomDepthPassParameters* PassParameters = GraphBuilder.AllocParameters<FCustomDepthPassParameters>();② 绑定pass的参数:
PassParameters->RenderTargets[0] = FRenderTargetBinding(CustomDepthTextures.MobileCustomDepth, DepthLoadAction);
PassParameters->RenderTargets[1] = FRenderTargetBinding(CustomDepthTextures.MobileCustomStencil, StencilLoadAction);
PassParameters->RenderTargets.DepthStencil = FDepthStencilBinding(
CustomDepthTextures.CustomDepth,
DepthLoadAction,
StencilLoadAction,
FExclusiveDepthStencil::DepthWrite_StencilWrite);③ 请求分配场景纹理:
PassParameters->MobileSceneTextures = CreateMobileSceneTextureUniformBuffer(GraphBuilder, EMobileSceneTextureSetupMode::None);④ 添加pass。可以发现具体的渲染调用封装在lambda函数中,这意味着当前设置只是进行了操作的记录,而调用将在Execute函数执行后才被真正执行。
GraphBuilder.AddPass(
RDG_EVENT_NAME("CustomDepth"),
PassParameters,
ERDGPassFlags::Raster,
[this, &View](FRHICommandListImmediate& RHICmdList)
{
//...
});以上几个步骤基本概述了如何使用RDG框架去定义一个渲染pass。
RDG接口设计
总而言之,RDG框架提供了如下接口:
① 创建新纹理 / UAV / SRV / Buffer
使用RDG创建的数据仅在RDGBuilder生存期内有效,因此这些数据只用于创建一些临时数据。
由于RDG创建的纹理并不会立即分配,因此不能使用原有的纹理类型。
FRDGTexture* Texture = GraphBuilder.CreateTexture(TextureDesc, TEXT("NAME")); // 创建纹理
FRDGTextureUAV* TextureUAV = GraphBuilder.CreateUAV(TextureUAVDesc); // 从纹理创建UAV
FRDGTextureSRV* TextureSRV = GraphBuilder.CreateSRV(TextureSRVDesc); // 从纹理创建SRV
FRDGBuffer* DrawIndiretParametersBuffer = GraphBuilder.CreateBuffer(IndirectArgBufferDesc, TEXT("DOFIndirectDrawParameters")); // 创建Buffer
PassParameter->OutScatterDrawIndirectParameters = GraphBuilder.CreateUAV(DrawIndirectParametersBuffer); // 从Buffer创建UAV
② 定义,分配和设置pass参数
定义pass参数可以使RDG资源和pass产生关联,如果仅分配pass参数而不进行关联,那么pass参数将是无效的。
它和着色器参数结构的定义放到一起,仅在名字上有一定差别,多了一个RDG的标识:
BEGIN_SHADER_PARAMETER_STRUCT(FParameters, )
// SHADER_PARAMETER_TEXTURE(Texture2D, MyTexture) // 原有的纹理声明方式
SHADER_PARAMETER_RDG_TEXTURE(Texture2D, MyTexture) // RDG纹理生命方式
SHADER_PARAMETER_RDG_TEXTURE_UAV(RWTexture2D<float4>, MyOutputUAV) // 像素着色器绑定UAV
SHADER_PARAMETER_RDG_BUFFER(StructuredBuffer<float4>, ScatterDrawList) // 使用SRV从Buffer读取数据
RENDER_TARGET_BINDING_SLOT() // 提供渲染目标和深度模板的输入
END_SHADER_PARAMETER_STRUCT()通过相关的shader宏,我们可以获取pass关联的RDG资源,并对pass进行相关的资源注册。RDG能够基于使用情况来推断资源的生命周期,并了解到pass是如何使用该资源(作为输入或输出),从而进行资源屏障的自动设置。
③ 添加Pass
和上述演示的深度绘制pass类似,主要分为以下三步:
// 1.分配参数
FMyShaderCS::FParameters* PassParameters = GraphBuilder.AllocParameters<FMyShaderCS::FParameters>();
// 2.设置参数
Parameters->SceneColor = SceneColor;
// ...
// 3.添加pass
GraphBuidler.AddPass(
RDG_EVENT_NAME("MyShader %dx%d", View.ViewRect.Width(), View.ViewRect.Height()),
PassParameters,
ERenderGraphpassFlags::Compute,
[PassParameters, ComputeShader, GroupCount] (FRHICommandList& RHICmdList)
{
// ...
});添加pass时,参数包含一个可用于调试分析的事件名(发行版本将去除),pass相关的参数,pass类型标记,以及对应的绘制Lambda函数。
在lambda函数调用期间,可以认为RDG资源是已分配且可安全访问的。由于lambda函数将延迟执行,为了避免引用失效,需要显式单独捕获参数。
④ 绑定深度渲染目标/颜色渲染目标
对于一些渲染目标而言,它的创建独立于RDG系统外。RDG支持对外部渲染目标进行绑定,同时我们可以指定外部渲染目标的加载(是否清空)/存储的特性。
PassParameters->RenderTargets[0] = FRenderTargetBinding(
Outputs.SceneColor,
ERenderTargetLoadAction::ENoAction,
ERenderTargetStoreAction::EStore); // 绑定颜色渲染目标
PassParameters->RenderTargets.DepthStencil = FDepthStencilBinding(
SceneBlackboard.SceneDepthBuffer,
ERenderTargetLoadAction::ENoAction, ERenderTargetStoreAction::ENoAction,
ERenderTargetLoadAction::ELoad, ERenderTargetStoreAction::EStore,
FExclusiveDepthStencil::DepthRead_StencilWrite); // 绑定深度渲染目标另外一些渲染对象可能是由ue4中的渲染对象池,即IPooledRenderTarget接口分配的,RDG如果需要引用到这些资源,可以调用相关的注册接口建立外部引用关系:
TRefCountPtr<IPooledRenderTarget> RawSceneColorPtr = ...
FRDGTexture* SceneColor = GraphBuilder.RegisterExternalTexture(RawSceneColorPtr, TEXT("SceneColor"));⑤ 屏幕空间的pass
有许多图形算法是基于屏幕空间,比如SSS,SSR,TAA等,它们之间纹理输入输出上存在一些共性。为了使得这一类算法的调用更加简单,ue4提供了针对屏幕空间算法的封装。
class FScreenPassTextureViewport
{
// ...
FIntRect Rect; // 视口矩阵,定义了位于[0, extent]的子矩形
FIntPoint Extent = FIntPoint::ZeroValue; // 矩形宽度
}对于屏幕空间的算法而言,它的输入输出纹理和屏幕分辨率是关联的,因此应该提供相关类来简化输入输出纹理的操作;此外,输入和输出视口不一定是完全一致的,举例来说,有时我们需要写入降分辨率(1/2屏幕分辨率或1/4屏幕分辨率)的纹理。
ue4定义了一个针对屏幕空间pass的着色器参数结构FScreenPassTextureViewportParameters,我们可以在着色器参数结构中直接引用这一结构:
BEGIN_SHADER_PARAMETER_STRUCT(FParameters, )
SHADER_PARAEMETER_STRUCT(FScreenPassTextureViewportParameters, Velocity)
END_SHADER_PARAMETER_STRUCT()接下来,调用GetScreenPassTextureViewportParameters,将其添加到pass参数:
FVelocityFlattenCS::FParameters* PassParameters = GraphBuilder.AllocParamaters<FVelocityFlattenCS::FParameters>();
PassParameters->Velocity = GetSreenPassTextureViewportParameters(VelocityViewport);在shader中,只需要一个宏(定义于ScreenPass.ush)就可以引入当前纹理:
// 定义纹理视口参数
SCREEN_PASS_TEXTURE_VIEWPORT(Velocity)上面描述的大部分细节,都封装在绘制屏幕空间pass的API中,在我们不需要比较细致的控制时,可以直接调用这一函数:
template<typename TPixelShaderType>
inline void AddDrawScreenPass(
FRDGBuilder& GraphBuilder,
FRDGEventName&& PassName,
const FScreenPassViewInfo& ScreenPassView,
const FScreenPassTextureViewport& OutputViewport,
const FScreenPassTextureViewport& InputViewport,
TPixelShaderType* PixelShader,
typename TPixelShaderType::FParameters* PixelShaderParameters) { }此外,框架提供了简单的类型转换,可以将uv坐标从一个视口空间映射到另一个视口空间。
FScreenPassTextureViewportTransform GetScreenPassTextureViewportTransform(
const FScreenPassTextureViewportParameters& Source,
const FScreenPassTextureViewportParameters& Destination);在shader中,通过scale和bias进行计算:
SCREEN_PASS_TEXTURE_VIEWPORT_TRANSFORM(ScreenColorToVelocity)
float2 VelocityUV = ScreenColorUV * SceneColorToVelocity_Scale + SceneolorToVelocity_Bias;实现细节

了解了RDG的基本使用后,我们可以关注一下RDG系统做了哪些事情。整个系统主要分为两个模块,一个是RDG对资源的二次封装,另一个是RDG的调度系统。如上图所示,当我们收集完成所有的pass信息后,在最终的执行阶段,RDG系统依次完成了编译、创建显存资源和资源屏障以及执行渲染逻辑的过程。
RDG资源结构

ue4中实际的显存资源主要是通过RHI接口创建的。而对于RDG系统而言,为了更好地管理资源,它单独封装了RDG的资源,比如FRDGTexture, FRDGBuffer等。
RDG资源内部包含了RHI显存资源,也包含了RDG相关的一些资源属性。当我们调用RDG的创建资源接口时,只填充了它的资源属性,在实际调用执行时,才会去填充RHI显存资源相关的内容。
就资源属性而言,一部分属性是资源本身的属性,比如大小、类型等;另一部分是为了计算生命周期、引用关系而记录的属性。
pass引用资源
以上是关于[引擎开发] 渲染架构与高级图形编程的主要内容,如果未能解决你的问题,请参考以下文章