正面PK Spark | 几大特性垫定Flink1.12流计算领域真正大规模生产可用
Posted 大数据真好玩
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了正面PK Spark | 几大特性垫定Flink1.12流计算领域真正大规模生产可用相关的知识,希望对你有一定的参考价值。
回复”资源“获取更多惊喜
在小编的记忆里,Flink 自从出现在大众视野中,一直在高速迭代。Flink1.10版本之前因为重大功能的缺失(主要是和Hive的兼容性),笔者一直都不推荐直接应用在大规模的生产实践中,可以做小范围内业务尝试。Flink 1.10版本可以被认为是一个承上启下的革命性版本。
随着 Flink 1.12版本的更新,Flink更新的一系列重大特性和对稳定性方面的考量,小编个人认为才真正拥有了和Spark这么成熟的框架正面交锋的资格。Flink1.12版本有哪些更新可以在官网查询到,不再赘述。
我们从这些特性中找出最重要的几个讲解,希望对大家有帮助。
第一个,基于Kubernetes的高可用方案
Flink 1.12 版本后,Flink 终于出现了生产级别的 Kubernetes(下面简称K8s)高可用方案。有的同学可能会问,为什么不用Yarn,要用K8s做集群管理?
这个要从K8s的发展过程和相比于Yarn的优势谈起。
Kubernetes 项目源自 Google 内部 Borg 项目,基于 Borg 多年来的优秀实践和其超前的设计理念,并凭借众多豪门、大厂的背书,时至今日,Kubernetes 已经成长为容器管理领域的事实标准。在大数据及相关领域,包括 Spark,Hive,Airflow,Kafka 等众多知名产品正在迁往 Kubernetes,Apache Flink 也是其中一员。
Yarn的发展过程不需要赘述,从Hadoop时代开始,Yarn就是最被广泛使用的资源管理框架存在。
那么,K8s相比于Yarn有哪些特点呢?小编个人认为主要是以下几个方面:
1. K8s作为容器管理的事实标准,在资源和网络隔离,安全,多租户天然优势
2. 能够和云原生的监控体系无缝融合,例如Prometheus
3. Yarn缺少load balance、离在线混合部署这些特性,在资源利用率上稍弱
但是并不是说Yarn就不够好,K8s也存在很多缺陷,例如较高的运维成本、复杂的权限管理等。
Flink 1.12版本的更新代表:Flink 可以利用 Kubernetes 提供的内置功能来实现 JobManager 的 failover,而不用依赖 ZooKeeper。该方案与 ZooKeeper 方案基于相同的接口,并使用 Kubernetes 的 ConfigMap对象来处理从 JobManager 的故障中恢复所需的所有元数据。
我们从官网上可以找到Flink集成K8s的原理图:
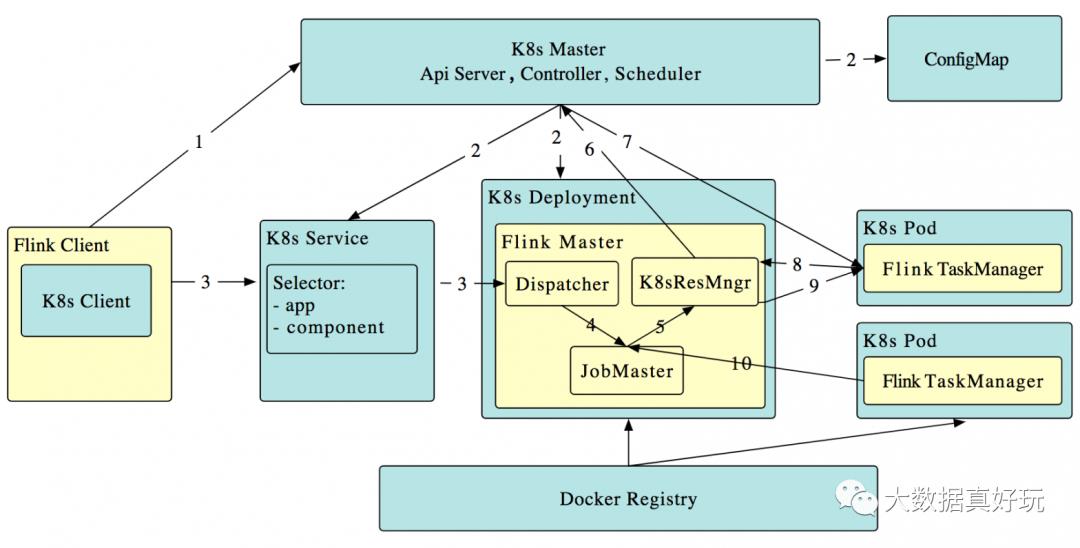 图来源于ververica.cn
图来源于ververica.cn
工作原理如下:
Flink 客户端首先连接 Kubernetes API Server,提交 Flink 集群的资源描述文件,包括 configmap,job manager service,job manager deployment 和 Owner Reference。
Kubernetes Master 就会根据这些资源描述文件去创建对应的 Kubernetes 实体。以我们最关心的 job manager deployment 为例,Kubernetes 集群中的某个节点收到请求后,Kubelet 进程会从中央仓库下载 Flink 镜像,准备和挂载 volume,然后执行启动命令。在 flink master 的 pod 启动后,Dispacher 和 KubernetesResourceManager 也都启动了。前面两步完成后,整个 Flink session cluster 就启动好了,可以接受提交任务请求了。
用户可以通过 flink 命令行即 flink client 往这个 session cluster 提交任务。此时 job graph 会在 flink client 端生成,然后和用户 jar 包一起通过 RestClinet 上传。
一旦 job 提交成功,JobSubmitHandler 收到请求就会提交 job 给 Dispatcher。接着就会生成一个 job master。
JobMaster 向 KubernetesResourceManager 请求 slots。
Kubernetes 集群分配一个新的 Pod 后,在上面启动 TaskManager。
TaskManager 启动后注册到 SlotManager。
SlotManager 向 TaskManager 请求 slots。
TaskManager 提供 slots 给 JobMaster。然后任务就会被分配到这个 slots 上运行。
那么基于 Flink on K8s的高可用的几种模式大家可以参考这里:
https://blog.csdn.net/yunxiao6/article/details/108705244
整体的架构如下:
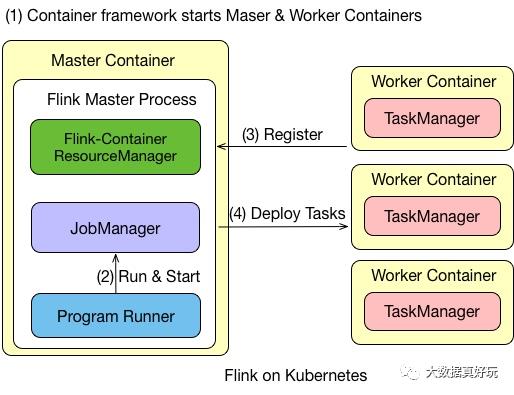
Flink on Kubernetes 的架构如图所示,Flink 任务在 Kubernetes 上运行的步骤有:
首先往 Kubernetes 集群提交了资源描述文件后,会启动 Master 和 Worker 的 container。
Master Container 中会启动 Flink Master Process,包含 Flink-Container ResourceManager、JobManager 和 Program Runner。
Worker Container 会启动 TaskManager,并向负责资源管理的 ResourceManager 进行注册,注册完成之后,由 JobManager 将具体的任务分给 Container,再由 Container 去执行。
需要说明的是,在 Flink 里的 Master 和 Worker 都是一个镜像,只是脚本的命令不一样,通过参数来选择启动 master 还是启动 Worker。
Flink on Kubernetes–JobManager
JobManager 的执行过程分为两步:
首先,JobManager 通过 Deployment 进行描述,保证 1 个副本的 Container 运行 JobManager,可以定义一个标签,例如 flink-jobmanager。
其次,还需要定义一个 JobManager Service,通过 service name 和 port 暴露 JobManager 服务,通过标签选择对应的 pods。
Flink on Kubernetes–TaskManager
TaskManager 也是通过 Deployment 来进行描述,保证 n 个副本的 Container 运行 TaskManager,同时也需要定义一个标签,例如 flink-taskmanager。
对于 JobManager 和 TaskManager 运行过程中需要的一些配置文件,如:flink-conf.yaml、hdfs-site.xml、core-site.xml,可以通过将它们定义为 ConfigMap 来实现配置的传递和读取。
整个交互的流程比较简单,用户往 Kubernetes 集群提交定义好的资源描述文件即可,例如 deployment、configmap、service 等描述。后续的事情就交给 Kubernetes 集群自动完成。Kubernetes 集群会按照定义好的描述来启动 pod,运行用户程序。各个组件的具体工作如下:
Service: 通过标签(label selector)找到 job manager 的 pod 暴露服务。
Deployment:保证 n 个副本的 container 运行 JM/TM,应用升级策略。
ConfigMap:在每个 pod 上通过挂载 /etc/flink 目录,包含 flink-conf.yaml 内容。
Flink on Kubernetes参考案例
首先,修改flink-conf.yaml:
high-availability: org.apache.flink.kubernetes.highavailability.KubernetesHaServicesFactory
high-availability.storageDir: s3:///flink/recovery
kubernetes.cluster-id: cluster1337
以上3个配置,表明我们希望Flink运行在K8s上。
官网推荐我们使用native Kubernetes deployments模式进行部署。以session-cluster模式为例,参考官网的案例:
We generally recommend new users to deploy Flink on Kubernetes using native Kubernetes deployments.
# Configuration and service definition
$ kubectl create -f flink-configuration-configmap.yaml
$ kubectl create -f jobmanager-service.yaml
# Create the deployments for the cluster
$ kubectl create -f jobmanager-session-deployment.yaml
$ kubectl create -f taskmanager-session-deployment.yaml
首先启动 Session Cluster,执行上述四个启动命令就可以将 Flink 的 jobmanager-service、jobmanager-deployment、taskmanager-deployment 启动起来。启动完成之后用户可以通过接口进行访问,然后通过端口进行提交任务。
官网给出的建议配置如下图所示:
jobmanager-session-deployment.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: flink-jobmanager
spec:
replicas: 1
selector:
matchLabels:
app: flink
component: jobmanager
template:
metadata:
labels:
app: flink
component: jobmanager
spec:
containers:
- name: jobmanager
image: flink:1.12.0-scala_2.11
args: ["jobmanager"]
ports:
- containerPort: 6123
name: rpc
- containerPort: 6124
name: blob-server
- containerPort: 8081
name: webui
livenessProbe:
tcpSocket:
port: 6123
initialDelaySeconds: 30
periodSeconds: 60
volumeMounts:
- name: flink-config-volume
mountPath: /opt/flink/conf
securityContext:
runAsUser: 9999 # refers to user _flink_ from official flink image, change if necessary
volumes:
- name: flink-config-volume
configMap:
name: flink-config
items:
- key: flink-conf.yaml
path: flink-conf.yaml
- key: log4j-console.properties
path: log4j-console.properties
taskmanager-session-deployment.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: flink-taskmanager
spec:
replicas: 2
selector:
matchLabels:
app: flink
component: taskmanager
template:
metadata:
labels:
app: flink
component: taskmanager
spec:
containers:
- name: taskmanager
image: flink:1.12.0-scala_2.11
args: ["taskmanager"]
ports:
- containerPort: 6122
name: rpc
- containerPort: 6125
name: query-state
livenessProbe:
tcpSocket:
port: 6122
initialDelaySeconds: 30
periodSeconds: 60
volumeMounts:
- name: flink-config-volume
mountPath: /opt/flink/conf/
securityContext:
runAsUser: 9999 # refers to user _flink_ from official flink image, change if necessary
volumes:
- name: flink-config-volume
configMap:
name: flink-config
items:
- key: flink-conf.yaml
path: flink-conf.yaml
- key: log4j-console.properties
path: log4j-console.properties
若想销毁集群,直接用 kubectl delete 即可,整个资源就可以销毁。
$ kubectl delete -f jobmanager-service.yaml
$ kubectl delete -f flink-configuration-configmap.yaml
$ kubectl delete -f taskmanager-session-deployment.yaml
$ kubectl delete -f jobmanager-session-deployment.yaml
我们运行一个demo案例如下:
$ ./bin/flink run -m localhost:8081
$ ./examples/streaming/TopSpeedWindowing.jar
打开 http://localhost:8081 即可看到结果。
第二个,DataStream API 支持批执行模式
我们都知道Flink在1.12之前是支持DataStream和DataSet两种API来分别处理无限流和有限流。然而这非常奇怪不是吗?因为在Flink的设计理念中,有限流被认为是时间维度上有限的【无限流】。
Flink1.12在设计中将DataStream API进行了改造,支持批模式。这代表了什么?Flink真正的走向了批流一体,虽然我们在生产实践中还是以DataSet处理批模式,但是在不久的将来会变得不一样。
Flink 1.12 提供了一个配置来告诉集群使用什么模式执行任务:execution.runtime-mode。
STREAMING
BATCH
AUTOMATIC
然后我们就可以使用一下命令进行任务提交:
$ bin/flink run -Dexecution.runtime-mode=BATCH examples/streaming/WordCount.jar
当然你也可以在代码中这么写:
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setRuntimeMode(RuntimeExecutionMode.BATCH);
虽然,目前这个使用模式看起来比较愚蠢。但是这也代表着,无论是从设计理念还是生产实践上,Flink正式超越Spark在流计算上的设计,成为当之无愧的NO1。
当然我们在使用DataStream执行Batch或者Streaming模式时,背后是不一样的,主要体现在以下几个方面:
Streaming模式下,每一条数据的到来都会立即触发计算并产生结果,但是Batch模式会划分Stage,然后一个接一个执行。
Streaming模式下,使用StateBackend存储状态,但是Batch模式下会被忽略。
WaterMark在Batch模式下几乎不需要,但是Streaming模式下的WaterMark是个强需求。
失败策略不一样。Streaming模式会基于Checkpoint进行重试,但是Batch模式下一般整个任务都会重启。
reduce、sum函数在Batch模式下只输出最终结果。并且Batch模式完全不支持Checkpoint、Broadcast State、Iterations。
上部分就讲解到这里了。
以上是关于正面PK Spark | 几大特性垫定Flink1.12流计算领域真正大规模生产可用的主要内容,如果未能解决你的问题,请参考以下文章