源码解析 | 万字长文详解 Flink 中的 CopyOnWriteStateTable
Posted Flink 中文社区
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了源码解析 | 万字长文详解 Flink 中的 CopyOnWriteStateTable相关的知识,希望对你有一定的参考价值。
声明:笔者的源码分析都是基于 flink-1.9.0 release 分支,其实阅读源码不用非常在意版本的问题,各版本的主要流程基本都是类似的。如果熟悉了某个版本的源码,之后新版本有变化,我们重点看一下变化之处即可。
-
1、hash 结构为了保证读写数据的高性能,都需要有扩容策略,CopyOnWriteStateMap 的扩容策略是一个渐进式 rehash 的策略,即:不是一下子将数据全迁移的新的 hash 表,而是慢慢去迁移数据到新的 hash 表中。 -
2、Checkpoint 时 CopyOnWriteStateMap 支持异步快照,即:Checkpoint 时可以在做快照的同时,仍然对 CopyOnWriteStateMap 中数据进行修改。问题来了:数据修改了,怎么保证快照数据的准确性呢?
1.StateTable 简介
-
CopyOnWriteStateTable 属于 Flink 自己定制化的数据结构,Checkpoint 时支持异步 Snapshot。 -
NestedMapsStateTable 直接嵌套 Java 的两层 HashMap 来存储数据,Checkpoint 时需要同步快照。
2.CopyOnWriteStateTable
-
CopyOnWriteStateMap 的扩容策略是渐进式 rehash,而不是一下子扩容完 -
为了支持异步的 Snapshot,需要将 Snapshot 时 StateMap 的快照保存下来,具体的保存策略怎么实现的? -
为了支持 CopyOnWrite 功能,所以在修改数据时,要进行一系列 copy 的操作,不能修改原始数据,否则会影响 Snapshot。 -
Snapshot 异步快照流程及 Snapshot 完成时,如何 release 掉旧版本数据?
3.CopyOnWriteStateMap 的渐进式 rehash 策略
3.1 扩容简述
3.2 选择 Table 的策略
// 选择当前元素到底使用 primaryTable 还是 incrementalRehashTableprivate StateMapEntry<K, N, S>[] selectActiveTable(int hashCode) {// 计算 hashCode 应该被分到 primaryTable 的哪个桶中int curIndex = hashCode & (primaryTable.length - 1);// 大于等于 rehashIndex 的桶还未迁移,应该去 primaryTable 中去查找。// 小于 rehashIndex 的桶已经迁移完成,应该去 incrementalRehashTable 中去查找。return curIndex >= rehashIndex ? primaryTable : incrementalRehashTable;}
3.3 迁移过程
-
检测是否处于 rehash 中,如果正在 rehash 就会调用 incrementalRehash 迁移一波数据 -
计算 key 和 namespace 对应的 hashCode
private void incrementalRehash() {StateMapEntry<K, N, S>[] oldMap = primaryTable;StateMapEntry<K, N, S>[] newMap = incrementalRehashTable;int oldCapacity = oldMap.length;int newMask = newMap.length - 1;int requiredVersion = highestRequiredSnapshotVersion;int rhIdx = rehashIndex;// 记录本次迁移了几个元素int transferred = 0;// 每次至少迁移 MIN_TRANSFERRED_PER_INCREMENTAL_REHASH 个元素到新桶、// MIN_TRANSFERRED_PER_INCREMENTAL_REHASH 默认为 4while (transferred < MIN_TRANSFERRED_PER_INCREMENTAL_REHASH) {// 遍历 oldMap 的第 rhIdx 个桶StateMapEntry<K, N, S> e = oldMap[rhIdx];// 每次 e 都指向 e.next,e 不为空,表示当前桶中还有元素未遍历,需要继续遍历// 每次迁移必须保证,整个桶被迁移完,不能是某个桶迁移到一半while (e != null) {// 遇到版本比 highestRequiredSnapshotVersion 小的元素,则 copy 一份if (e.entryVersion < requiredVersion) {e = new StateMapEntry<>(e, stateMapVersion);}// 保存下一个要迁移的节点节点到 nStateMapEntry<K, N, S> n = e.next;// 迁移当前元素 e 到新的 table 中,插入到链表头部int pos = e.hash & newMask;e.next = newMap[pos];newMap[pos] = e;// e 指向下一个要迁移的节点e = n;// 迁移元素数 +1++transferred;}oldMap[rhIdx] = null;// rhIdx 之前的桶已经迁移完,rhIdx == oldCapacity 就表示迁移完成了// 做一些初始化操作if (++rhIdx == oldCapacity) {XXXreturn;}}// primaryTableSize 中减去 transferred,增加 transferredprimaryTableSize -= transferred;incrementalRehashTableSize += transferred;rehashIndex = rhIdx;}
4.StateMap 的 Snapshot 策略
4.1 浅拷贝原理分析
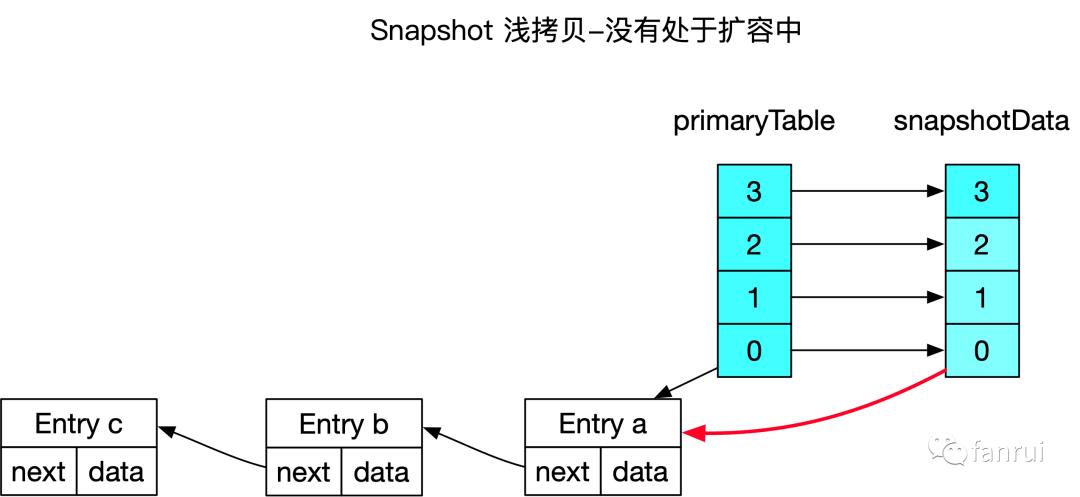
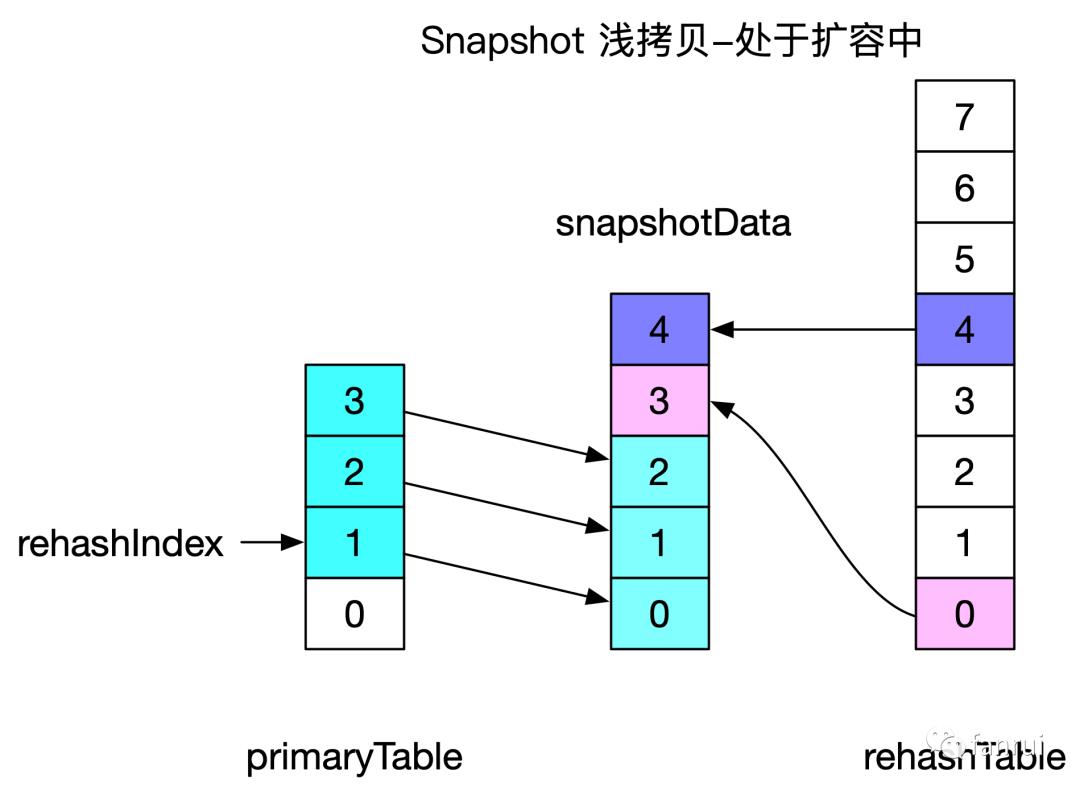
上图中也是省略了 Entry,Entry 引用的浅拷贝与之前没有扩容的情况类似。
4.2 浅拷贝源码详解
List<CopyOnWriteStateMapSnapshot<K, N, S>> getStateMapSnapshotList() {List<CopyOnWriteStateMapSnapshot<K, N, S>> snapshotList =new ArrayList<>(keyGroupedStateMaps.length);// 调用所有 CopyOnWriteStateMap 的 stateSnapshot 方法// 生成 CopyOnWriteStateMapSnapshot 保存到 list 中for (int i = 0; i < keyGroupedStateMaps.length; i++) {CopyOnWriteStateMap<K, N, S> stateMap =(CopyOnWriteStateMap<K, N, S>) keyGroupedStateMaps[i];snapshotList.add(stateMap.stateSnapshot());}return snapshotList;}
public CopyOnWriteStateMapSnapshot<K, N, S> stateSnapshot() {return new CopyOnWriteStateMapSnapshot<>(this);}CopyOnWriteStateMapSnapshot(CopyOnWriteStateMap<K, N, S> owningStateMap) {super(owningStateMap);// 对 StateMap 的数据进行浅拷贝,生成 snapshotDatathis.snapshotData = owningStateMap.snapshotMapArrays();// 记录当前的 StateMap 版本到 snapshotVersion 中this.snapshotVersion = owningStateMap.getStateMapVersion();this.numberOfEntriesInSnapshotData = owningStateMap.size();}
public class CopyOnWriteStateMap<K, N, S> extends StateMap<K, N, S> {// 当前 StateMap 的 versionprivate int stateMapVersion;// 所有 正在进行中的 snapshot 的 versionprivate final TreeSet<Integer> snapshotVersions;// 正在进行中的那些 snapshot 的最大版本号private int highestRequiredSnapshotVersion;StateMapEntry<K, N, S>[] snapshotMapArrays() {// 1、stateMapVersion 版本 + 1,赋值给 highestRequiredSnapshotVersion,// 并加入snapshotVersionssynchronized (snapshotVersions) {++stateMapVersion;highestRequiredSnapshotVersion = stateMapVersion;snapshotVersions.add(highestRequiredSnapshotVersion);}// 2、 将现在 primary 和 Increment 的元素浅拷贝一份到 copy 中// copy 策略:copy 数组长度为 primary 中剩余的桶数 + Increment 中有数据的桶数// primary 中剩余的数据放在 copy 数组的前面,Increment 中低位数据随后,// Increment 中高位数据放到 copy 数组的最后StateMapEntry<K, N, S>[] table = primaryTable;final int totalMapIndexSize = rehashIndex + table.length;final int copiedArraySize = Math.max(totalMapIndexSize, size());final StateMapEntry<K, N, S>[] copy = new StateMapEntry[copiedArraySize];if (isRehashing()) {final int localRehashIndex = rehashIndex;final int localCopyLength = table.length - localRehashIndex;// for the primary table, take every index >= rhIdx.System.arraycopy(table, localRehashIndex, copy, 0, localCopyLength);table = incrementalRehashTable;System.arraycopy(table, 0, copy, localCopyLength, localRehashIndex);System.arraycopy(table, table.length >>> 1, copy,localCopyLength + localRehashIndex, localRehashIndex);} else {System.arraycopy(table, 0, copy, 0, table.length);}return copy;}}
-
stateMapVersion:表示当前 StateMap 的版本,每次 Snapshot 时版本号加一 -
snapshotVersions:存放所有正在进行中的 snapshot 的版本号(因为可能存在多个同时进行的 Snapshot) -
highestRequiredSnapshotVersion:表示正在进行中的那些 snapshot 的最大版本号,如果当前没有正在进行中的 Snapshot,那么赋值为 0
注:copy 数组的长度与上述原理分析不完全一致,原理分析时应该是 copiedArraySize = totalMapIndexSize;实际上 copiedArraySize = Math.max(totalMapIndexSize, size())。
源码注释写到:理论上 totalMapIndexSize 就够了,这里考虑 size 主要是为了兼容 StateMap 的 TransformedSnapshotIterator 功能。
5.CopyOnWrite 实现原理
5.1 CopyOnWrite 原理简述
5.2 CopyOnWrite 原理详解
■ 5.2.1 修改链表头部节点的场景
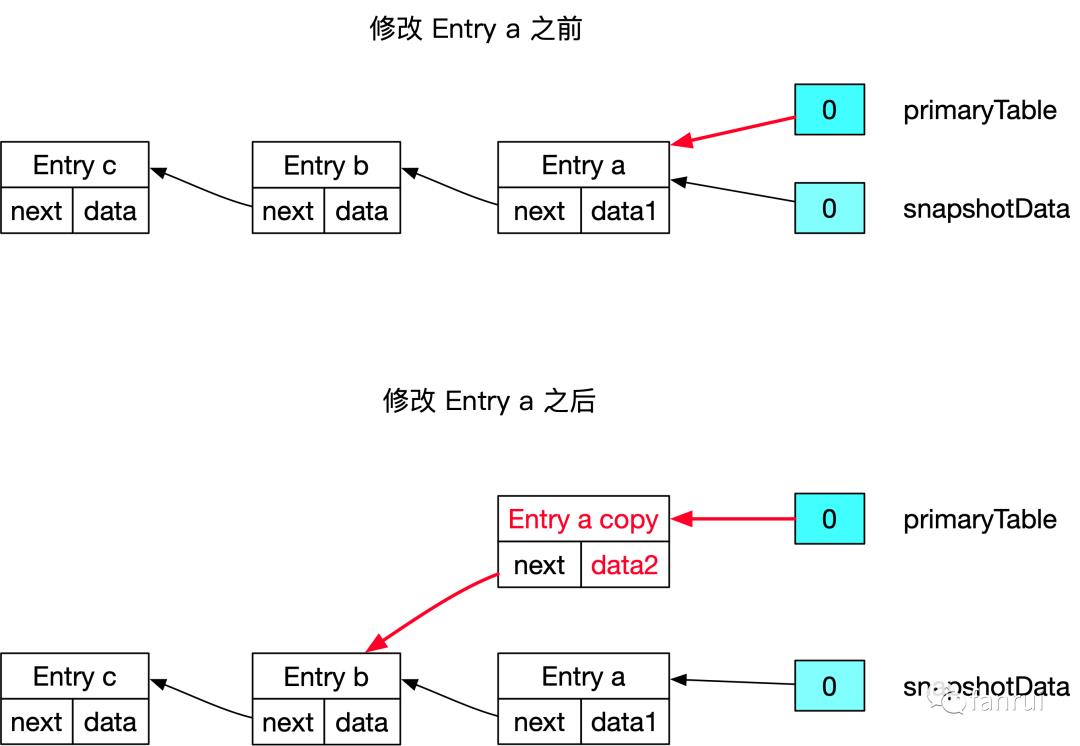
-
深拷贝一个 Entry a 对象为 Entry a copy -
将 Entry a copy 放到 primaryTable 的链表中,且 next 指向 Entry b -
应用层修改 Entry a copy 的 data,将 data1 修改为设定的 data2
■ 5.2.2 修改链表中间节点的场景
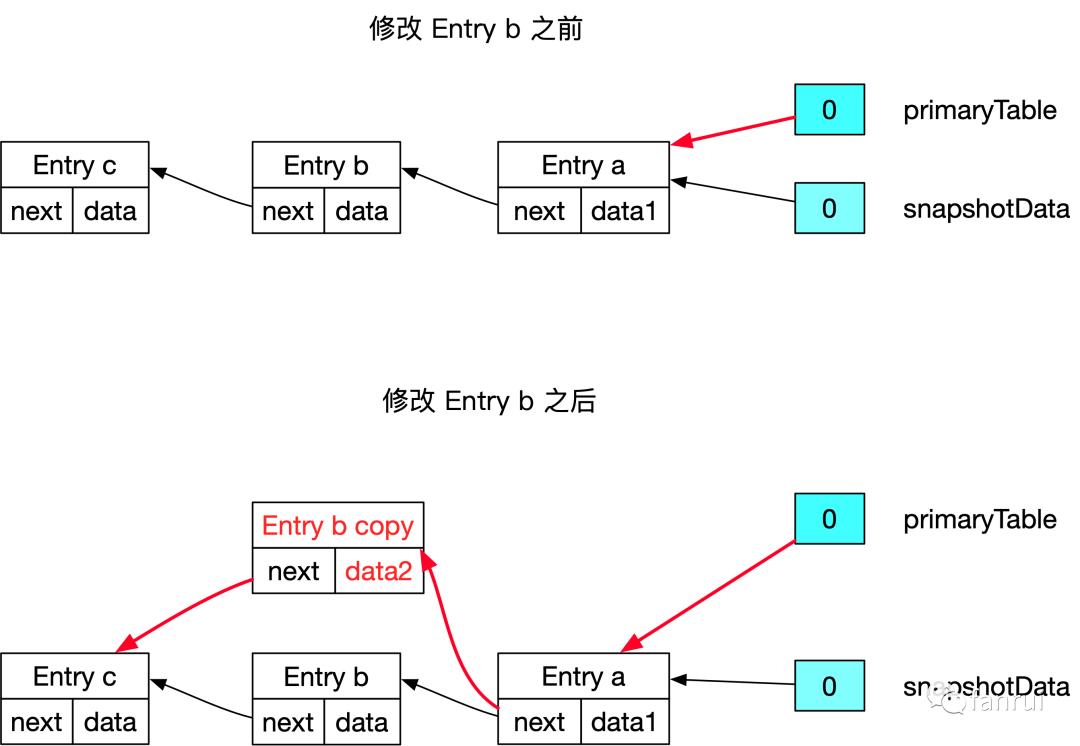
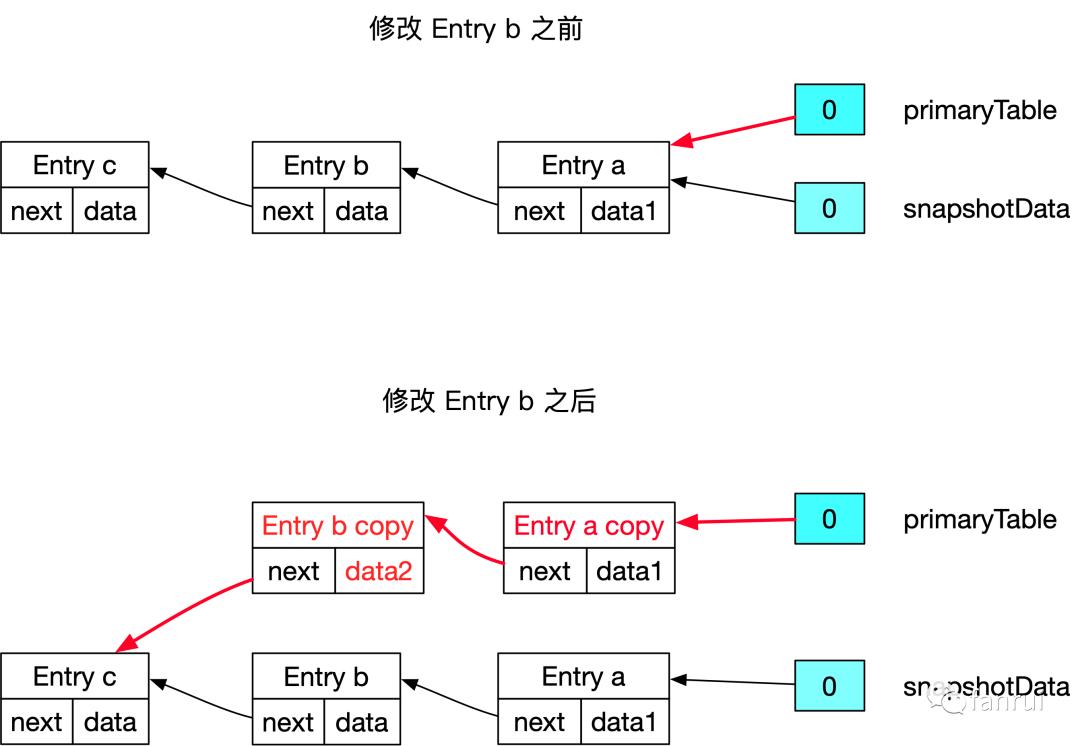
-
深拷贝一个 Entry b 对象为 Entry b copy -
将 Entry b copy 串在 primaryTable 的链表中,且 next 指向 Entry c -
应用层修改 Entry b copy 的 data,将 data 修改为设定的 data2
-
深拷贝 Entry a 和 b 对象为 Entry a copy 和 b copy -
将 Entry a copy 和 b copy 串在 primaryTable 的链表中,且 Entry b 的 next 指向 Entry c -
应用层修改 Entry b copy 的 data,将 data 修改为设定的 data2
■ 5.2.3 插入新数据的场景
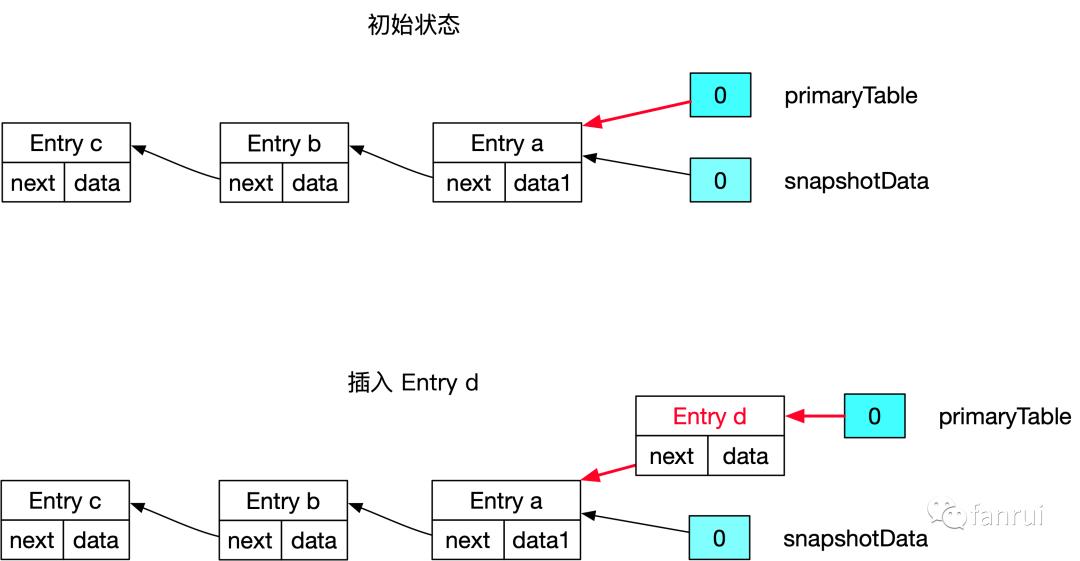
注:这里必须是插入新数据的场景,对于 Map 类型,插入旧数据对应的可能是修改操作
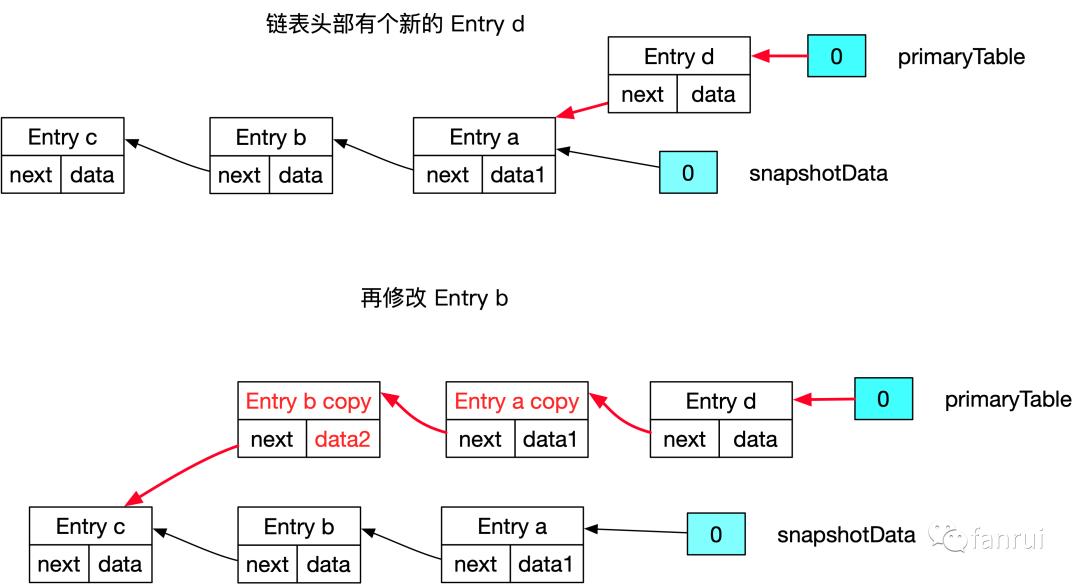
■ 5.2.4 链表头部有新节点再修改链表中间节点的场景
-
深拷贝 Entry a 和 b 对象为 Entry a copy 和 b copy -
将 Entry a copy 和 b copy 串在 Entry d 的链表中,且 Entry b 的 next 指向 Entry c -
应用层修改 Entry b copy 的 data,将 data 修改为设定的 data2
■ 5.2.5 get 链表中间节点的场景
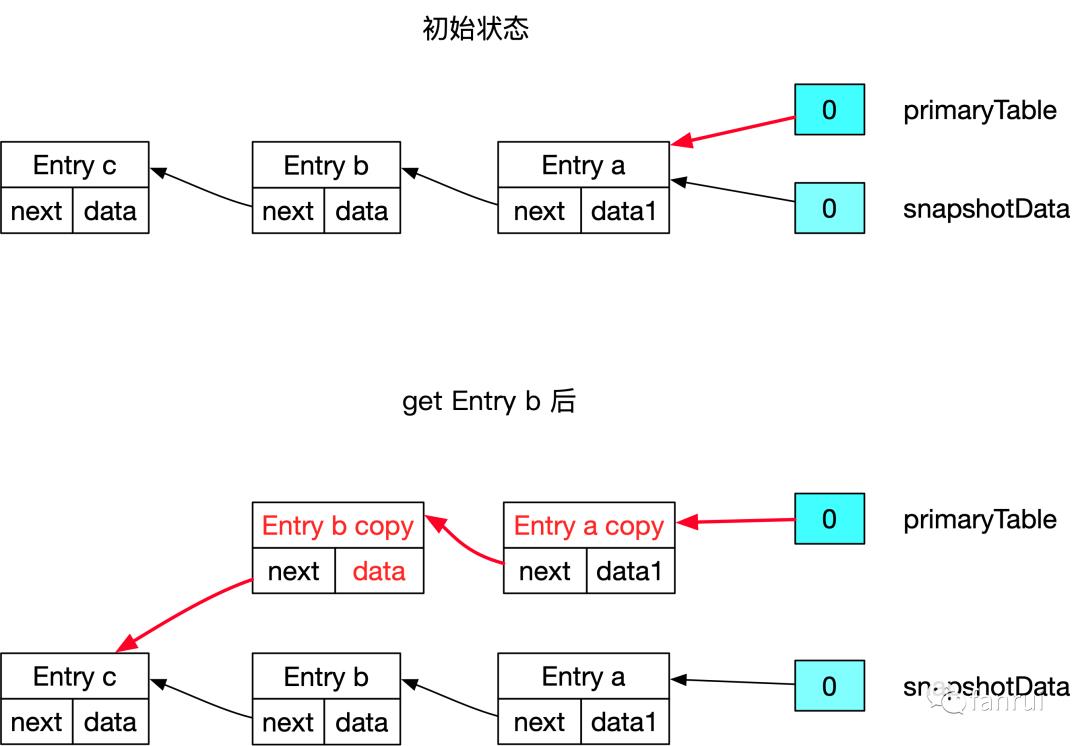
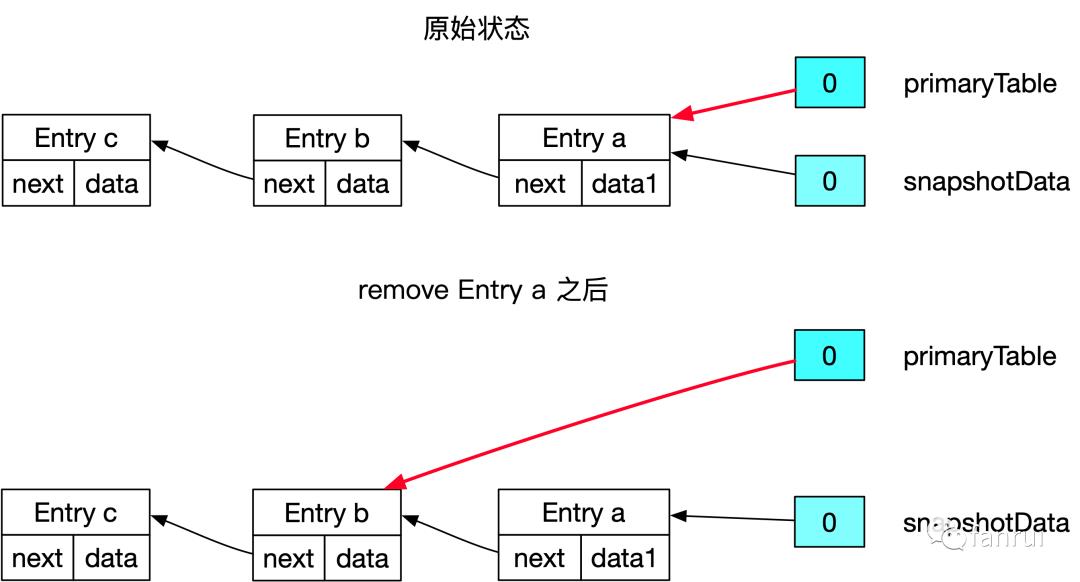
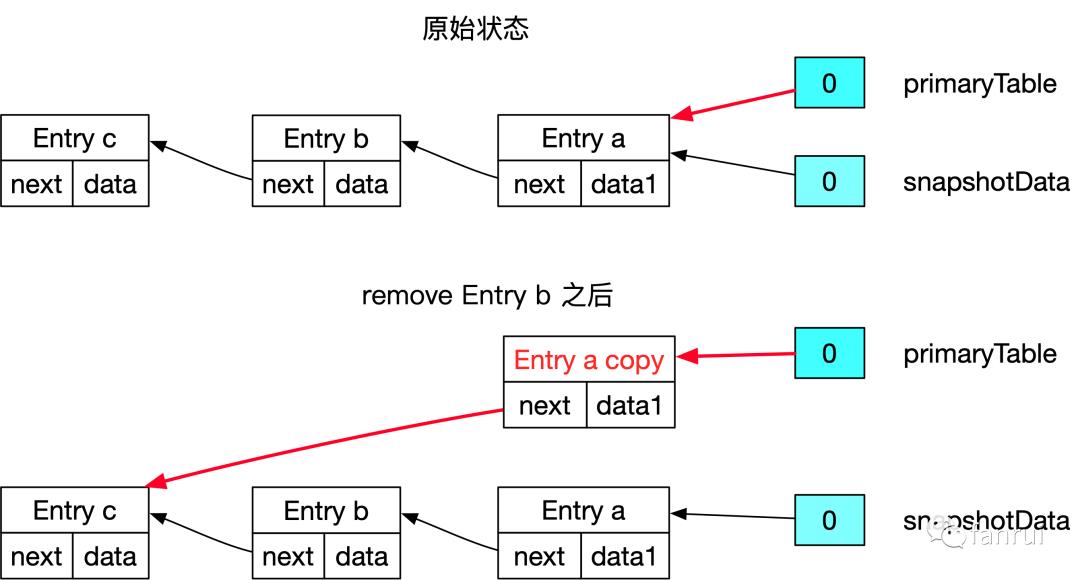
■ 5.2.6 remove 数据的场景
■ 5.2.7 COW 原理小结
-
插入新的 Entry 使用头插法插入到链表中 -
假设要修改 Entry b,那么要将 Entry b 以及链表中 Entry b 之前的 Entry 必须全部 copy 一份(新插入的数据不需要拷贝),Entry b 之后的 Entry 可以共享 -
访问 Entry b 的场景与修改 Entry b 的场景类似 -
假如修改或访问的数据是 copy 后的数据,那么实际上不需要再 copy 了,因为 copy 后的数据已经保证是 primaryTable 独占的数据,不与 Snapshot 共享 -
remove 数据的场景,分为两种 case: -
如果 remove 的 Entry 是链表头节点,将桶直接指向头结点的 next 节点即可。 -
如果 remove 的 Entry 不是链表头节点,需要将目标 Entry 之前的所有 Entry 拷贝一份,且目标 Entry 前一个节点的副本直接指向目标 Entry 的下一个节点。当然如果前继节点已经是新版本了,则不需要拷贝,直接修改前继 Entry 的 next 指针即可。
5.3 CopyOnWriteStateMap 各种操作源码详解
■ 5.3.1 CopyOnWriteStateMap 介绍
public class CopyOnWriteStateMap<K, N, S> extends StateMap<K, N, S> {// 默认容量 128,即:hash 表中桶的个数默认 128public static final int DEFAULT_CAPACITY = 128;// hash 扩容迁移数据时,每次最少要迁移 4 条数据private static final int MIN_TRANSFERRED_PER_INCREMENTAL_REHASH = 4;// State 的序列化器protected final TypeSerializer<S> stateSerializer;// 空表:提前创建好private static final StateMapEntry<?, ?, ?>[] EMPTY_TABLE =new StateMapEntry[MINIMUM_CAPACITY >>> 1];// 当前 StateMap 的 version,每次创建一个 Snapshot 时,StateMap 的版本号加一private int stateMapVersion;// 所有 正在进行中的 snapshot 的 version// 每次创建出一个 Snapshot 时,都需要将 Snapshot 的 version 保存到该 Set 中private final TreeSet<Integer> snapshotVersions;// 正在进行中的那些 snapshot 的最大版本号// 这里保存的就是 TreeSet<Integer> snapshotVersions 中最大的版本号private int highestRequiredSnapshotVersion;// 主表:用于存储数据的 tableprivate StateMapEntry<K, N, S>[] primaryTable;// 扩容时的新表,扩容期间数组长度为 primaryTable 的 2 倍。// 非扩容期间为 空表private StateMapEntry<K, N, S>[] incrementalRehashTable;// primaryTable 中元素个数private int primaryTableSize;// incrementalRehashTable 中元素个数private int incrementalRehashTableSize;// primary table 中增量 rehash 要迁移的下一个 index// 即:primaryTable 中 rehashIndex 之前的数据全部搬移完成private int rehashIndex;// 扩容阈值,与 HashMap 类似,当元素个数大于 threshold 时,就会开始扩容。// 默认 threshold 为 StateMap 容量 * 0.75private int threshold;// 用于记录元素修改的次数,遍历迭代过程中,发现 modCount 修改了,则抛异常private int modCount;}
■ 5.3.2 StateMapEntry
static class Node<K,V> implements Map.Entry<K,V> {// 当前 key 对应的 hash 值final int hash;final K key;V value;// next 指向当前桶中下一个 NodeNode<K,V> next;}
-
根据 key 计算 hash 值,定位到具体的桶 -
遍历当前桶的一个个 Entry,先比较 hash 值是否相同,在比较 key 是否相同(使用 equals 判断 key 是否相同) -
如果 hash 值和 key 的 equals 方法都能匹配,表示找到了对应的 Entry,返回 Entry 中的 value 即可
protected static class StateMapEntry<K, N, S> implements StateEntry<K, N, S> {final K key;final N namespace;S state;final int hash;StateMapEntry<K, N, S> next;// new entry 时的版本号int entryVersion;// state (数据)更新时的 版本号int stateVersion;}
-
namespace:namespace 是 Flink 中的概念,用于区分不同的 Window,在 StateMapEntry 中 key 和 namespace 组合起来作为共同的主键,state 作为 value -
entryVersion:表示创建 entry 时的版本号 -
stateVersion:表示当前 StateMapEntry 中 state (数据)更新时的版本号
■ 5.3.3 插入新数据源码流程
public void put(K key, N namespace, S value) {// putEntry 用于找到对应的 Entry,// 包括了修改数据或插入新数据的场景final StateMapEntry<K, N, S> e = putEntry(key, namespace);// 将 value set 到 Entry 中e.state = value;// state 更新了,所以要更新 stateVersione.stateVersion = stateMapVersion;}
private StateMapEntry<K, N, S> putEntry(K key, N namespace) {// 计算当前对应的 hash 值,选择 primaryTable 或 incrementalRehashTablefinal int hash = computeHashForOperationAndDoIncrementalRehash(key, namespace);final StateMapEntry<K, N, S>[] tab = selectActiveTable(hash);int index = hash & (tab.length - 1);// 遍历当前桶中链表的一个个 Entryfor (StateMapEntry<K, N, S> e = tab[index]; e != null; e = e.next) {// 如果根据 key 和 namespace 找到了对应的 Entry,则认为是修改数据// 普通的 HashMap 结构有一个 Key ,而这里 key 和 namespace 的组合当做 keyif (e.hash == hash && key.equals(e.key) && namespace.equals(e.namespace)) {// 修改数据逻辑(暂时忽略)if (e.entryVersion < highestRequiredSnapshotVersion) {e = handleChainedEntryCopyOnWrite(tab, index, e);}// 修改数据,直接返回对应的 Entryreturn e;}}// 代码走到这里,说明原始的链表中没找到对应 Entry,即:插入新数据的逻辑++modCount;if (size() > threshold) {doubleCapacity();}// 链中没有找到 key 和 namespace 的数据return addNewStateMapEntry(tab, key, namespace, hash);}
这里注意,普通的 HashMap 结构有一个 Key 一个 value。而这里 key 和 namespace 的组合当做 Map 的 key,value 仍然是原来的 value。
■ 5.3.4 修改数据源码流程
// 如果根据 key 和 namespace 找到了对应的 Entry,则认为是修改数据// 普通的 HashMap 结构有一个 Key ,而这里 key 和 namespace 的组合当做 keyif (e.hash == hash && key.equals(e.key) && namespace.equals(e.namespace)) {// entryVersion 表示 entry 创建时的版本号// highestRequiredSnapshotVersion 表示 正在进行中的那些 snapshot 的最大版本号// entryVersion 小于 highestRequiredSnapshotVersion,说明 Entry 的版本小于当前某些 Snapshot 的版本号,// 即:当前 Entry 是旧版本的数据,当前 Entry 被其他 snapshot 持有。// 为了保证 Snapshot 的数据正确性,这里必须为 e 创建新的副本,且 e 之前的某些元素也需要 copy 副本// handleChainedEntryCopyOnWrite 方法将会进行相应的 copy 操作,并返回 e 的新副本// 然后将返回 handleChainedEntryCopyOnWrite 方法返回的 e 的副本返回给上层,进行数据的修改操作。if (e.entryVersion < highestRequiredSnapshotVersion) {e = handleChainedEntryCopyOnWrite(tab, index, e);}// 反之,entryVersion >= highestRequiredSnapshotVersion// 说明当前 Entry 创建时的版本比所有 Snapshot 的版本高// 即:当前 Entry 是新版本的数据,不被任何 Snapshot 持有// 注:Snapshot 不可能引用高版本的数据// 此时,e 是新的 Entry,不存在共享问题,所以直接修改当前 Entry 即可,所以返回当前 ereturn e;}
-
entryVersion 小于 highestRequiredSnapshotVersion,说明 Entry 创建时的版本小于当前某些 Snapshot 的版本号,即:当前 Entry 是旧版本的数据,当前 Entry 被其他 Snapshot 持有。为了保证 Snapshot 的数据正确性,这里必须为 e 创建新的副本,且 e 之前的某些元素也需要 copy 副本,handleChainedEntryCopyOnWrite 方法将会进行相应的 copy 操作,并返回 e 的新副本。最后将 e 的副本返回给上层,进行数据的修改操作。 -
反之,entryVersion >= highestRequiredSnapshotVersion,说明当前 Entry 创建时的版本比所有 Snapshot 的版本高。Snapshot 不可能引用高版本的数据,所以当前 Entry 是新版本的数据不被任何 Snapshot 持有。此时 e 是新的 Entry,不存在共享问题,所以直接修改当前 Entry 即可,所以返回当前 e。
private StateMapEntry<K, N, S> handleChainedEntryCopyOnWrite(StateMapEntry<K, N, S>[] tab,int mapIdx,StateMapEntry<K, N, S> untilEntry) {// current 指向当前桶的头结点StateMapEntry<K, N, S> current = tab[mapIdx];StateMapEntry<K, N, S> copy;// 判断头结点创建时的版本是否低于 highestRequiredSnapshotVersion// 如果低于,则 current 节点被 Snapshot 引用,所以需要 new 一个新的 Entryif (current.entryVersion < highestRequiredSnapshotVersion) {copy = new StateMapEntry<>(current, stateMapVersion);tab[mapIdx] = copy;} else {copy = current;}// 依次遍历当前桶的元素,直到遍历到 untilEntry 节点,也就是我们要修改的 Entry 节点while (current != untilEntry) {current = current.next;// current 版本小于 highestRequiredSnapshotVersion,则需要拷贝,// 否则不用拷贝if (current.entryVersion < highestRequiredSnapshotVersion) {// entryVersion 表示创建 Entry 时的 version,// 所以新创建的 Entry 对应的 entryVersion 要更新为当前 StateMap 的 versioncopy.next = new StateMapEntry<>(current, stateMapVersion);copy = copy.next;} else {copy = current;}}return copy;}
-
如果低于则 current 节点被 Snapshot 引用,所以需要 new 一个新的 Entry,也就是所谓的拷贝一个副本。 -
否则不用拷贝。
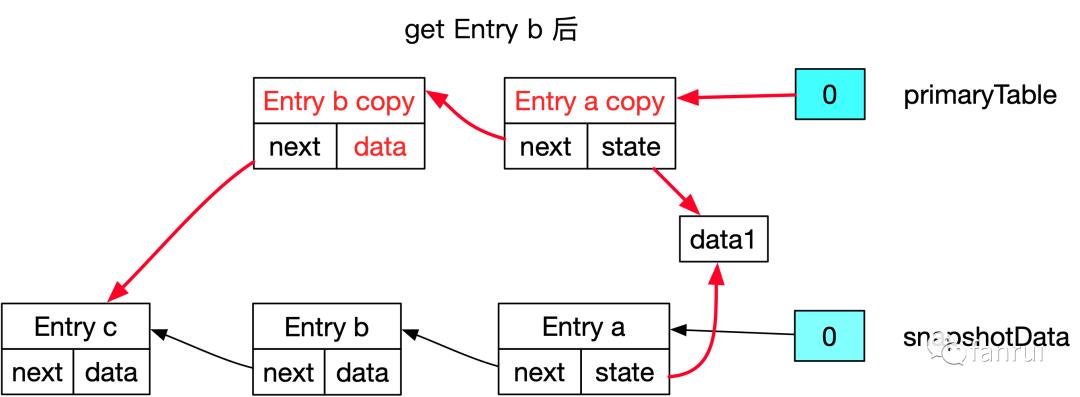
■ 5.3.5 访问数据源码流程
if ((e.hash == hash && key.equals(eKey) && namespace.equals(eNamespace))) {// 一旦 get 当前数据,为了防止应用层修改数据内部的属性值,// 所以必须保证这是一个最新的 Entry,并更新其 stateVersion// 首先检查当前的 State,也就是 value 值是否是旧版本数据,// 如果 value 是旧版本,则必须深拷贝一个 value// 否则 value 是新版本,直接返回给应用层if (e.stateVersion < requiredVersion) {// 此时还有两种情况,// 1、如果当前 Entry 是旧版本的,则 Entry 也需要拷贝一份,// 按照之前分析过的 handleChainedEntryCopyOnWrite 策略拷贝即可// 2、当前 Entry 是新版本数据,则不需要拷贝,直接修改其 State 即可if (e.entryVersion < requiredVersion) {e = handleChainedEntryCopyOnWrite(tab, hash & (tab.length - 1), e);}// 更新其 stateVersione.stateVersion = stateMapVersion;// 通过序列化器,深拷贝一个数据e.state = getStateSerializer().copy(e.state);}return e.state;}
-
如果 value 是旧版本,则必须深拷贝一个 value -
否则 value 是新版本,直接返回给应用层
-
1、如果当前 Entry 是旧版本的,则 Entry 也需要拷贝一份,按照之前分析过的 handleChainedEntryCopyOnWrite 策略拷贝即可 -
2、当前 Entry 是新版本数据,则不需要拷贝,直接修改其 State 即可
■ 5.3.6 remove 数据源码流程
private StateMapEntry<K, N, S> removeEntry(K key, N namespace) {final int hash = computeHashForOperationAndDoIncrementalRehash(key, namespace);final StateMapEntry<K, N, S>[] tab = selectActiveTable(hash);int index = hash & (tab.length - 1);for (StateMapEntry<K, N, S> e = tab[index], prev = null;e != null; prev = e, e = e.next) {if (e.hash == hash && key.equals(e.key) && namespace.equals(e.namespace)) {// 如果要删除的 Entry 不存在前继节点,说明要删除的 Entry 是头结点,// 直接将桶直接指向头结点的 next 节点即可。if (prev == null) {tab[index] = e.next;} else {// 如果 remove 的 Entry 不是链表头节点,需要将目标 Entry 之前的所有 Entry 拷贝一份,// 且目标 Entry 前一个节点的副本直接指向目标 Entry 的下一个节点。// 当然如果前继节点已经是新版本了,则不需要拷贝,直接修改前继 Entry 的 next 指针即可。// copy-on-write check for entryif (prev.entryVersion < highestRequiredSnapshotVersion) {prev = handleChainedEntryCopyOnWrite(tab, index, prev);}prev.next = e.next;}// 修改一些计数器++modCount;if (tab == primaryTable) {--primaryTableSize;} else {--incrementalRehashTableSize;}return e;}}return null;}
-
如果 remove 的 Entry 是链表头节点,将桶直接指向头结点的 next 节点即可。 -
如果 remove 的 Entry 不是链表头节点,需要将目标 Entry 之前的所有 Entry 拷贝一份,且目标 Entry 前一个节点的副本直接指向目标 Entry 的下一个节点。当然如果前继节点已经是新版本了,则不需要拷贝,直接修改前继 Entry 的 next 指针即可。
6.Snapshot 流程及完成后的 release 操作
public void writeStateInKeyGroup(@Nonnull DataOutputView dov, int keyGroupId) {// 获取 KeyGroupId 对应的 CopyOnWriteStateMapSnapshotStateMapSnapshot<K, N, S, ? extends StateMap<K, N, S>> stateMapSnapshot =getStateMapSnapshotForKeyGroup(keyGroupId);// 将 stateMapSnapshot 中的 State 数据进行序列化输出stateMapSnapshot.writeState(localKeySerializer, localNamespaceSerializer,localStateSerializer, dov, stateSnapshotTransformer);// stateMapSnapshot 对应的数据已经遍历完了,所以可以释放该快照stateMapSnapshot.release();}
void releaseSnapshot(int snapshotVersion) {synchronized (snapshotVersions) {// 将 相应的 snapshotVersion 从 snapshotVersions 中 removesnapshotVersions.remove(snapshotVersion);// 将 snapshotVersions 的最大值更新到 highestRequiredSnapshotVersion,// 如果snapshotVersions 为空,则 highestRequiredSnapshotVersion 更新为 0highestRequiredSnapshotVersion = snapshotVersions.isEmpty() ?0 : snapshotVersions.last();}}
7.总结
本文涉及的 github 仓库,都在 feature/source-code-read-1-9-0 分支,之后也会持续更新:
https://github.com/1996fanrui/flink/tree/feature/source-code-read-1-9-0注释
 福利来了
福利来了
Apache Flink 极客挑战赛
以上是关于源码解析 | 万字长文详解 Flink 中的 CopyOnWriteStateTable的主要内容,如果未能解决你的问题,请参考以下文章
万字长文|Hashtable源码深度解析以及与HashMap的区别
五万字长文详解SpringBoot 操作 ElasticSearch