机器学习- 吴恩达Andrew Ng Week10 知识总结 Large scale machine learning
Posted 架构师易筋
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了机器学习- 吴恩达Andrew Ng Week10 知识总结 Large scale machine learning相关的知识,希望对你有一定的参考价值。
Coursera课程地址
因为Coursera的课程还有考试和论坛,后续的笔记是基于Coursera
https://www.coursera.org/learn/machine-learning/home/welcome
Large scale machine learning 大数据集机器学习
1. 大数据集学习 Learning with large datasets
当我们的算法在 m 很小时具有高方差时,我们主要受益于非常大的数据集。回想一下,如果我们的算法有高偏差,更多的数据将没有任何好处。
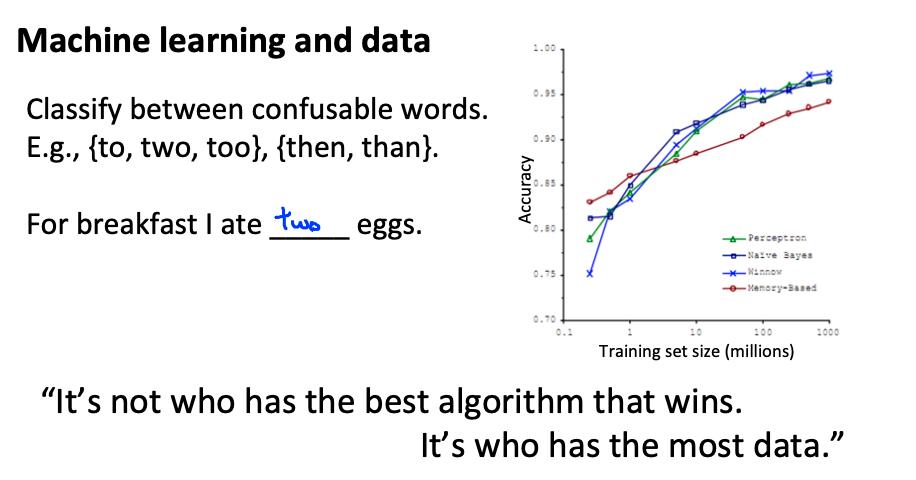
数据集通常可以达到 m = 100,000,000 这样的大小。在这种情况下,我们的梯度下降步骤必须对所有一亿个示例进行求和。我们会尽量避免这种情况——这样做的方法如下所述。
大数据集对过拟合的优化才有用。
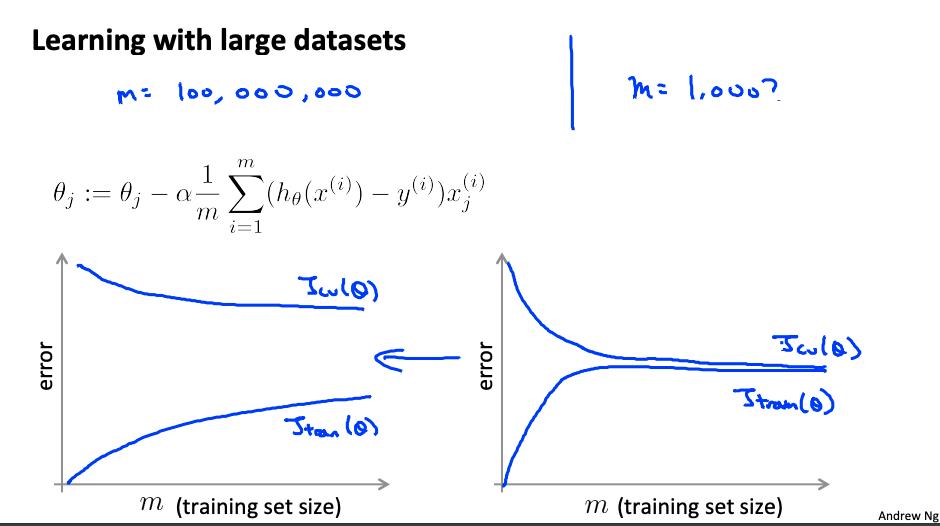
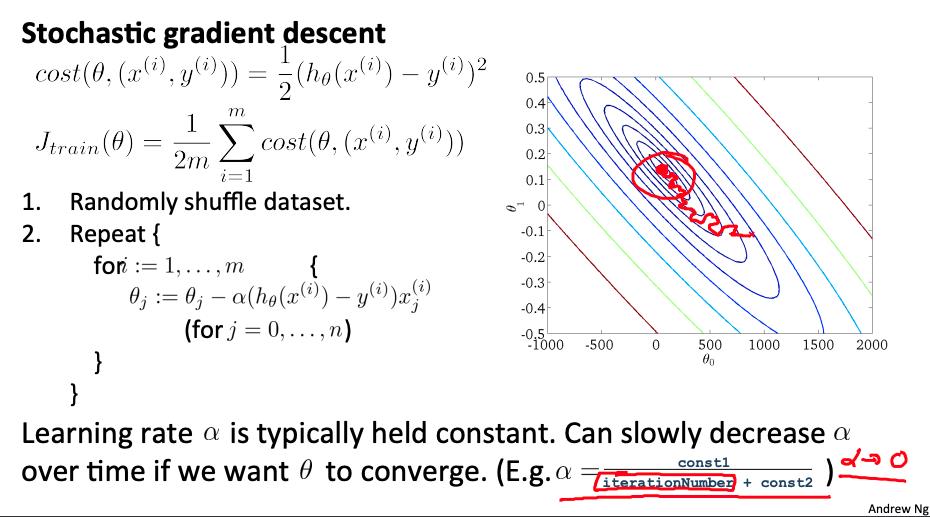
2. 随机梯度下降 Stochastic gradient descent
回顾一下 线性回归的梯度下降算法
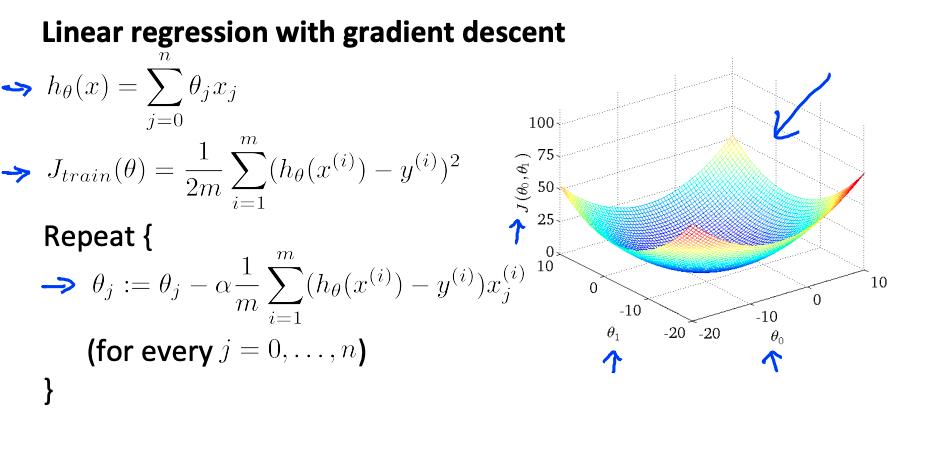
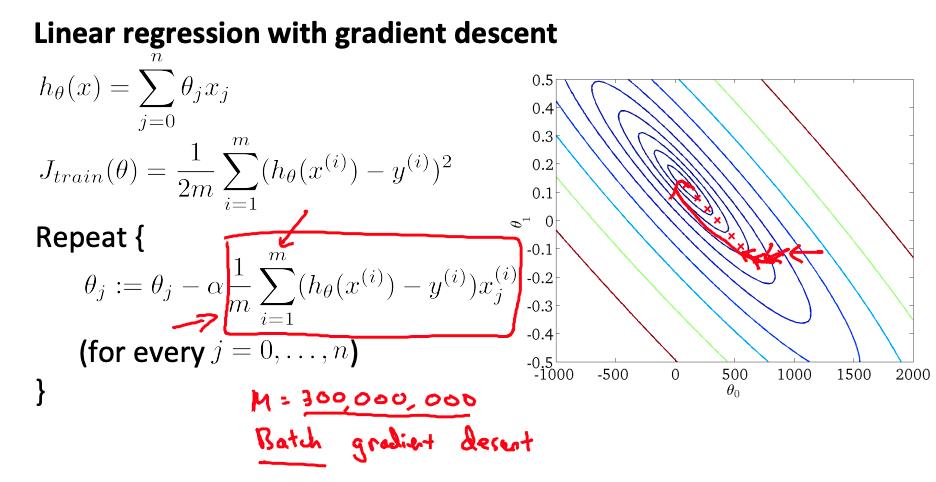
随机梯度下降是经典(或批量)梯度下降的替代方案,并且对大型数据集更有效且可扩展。
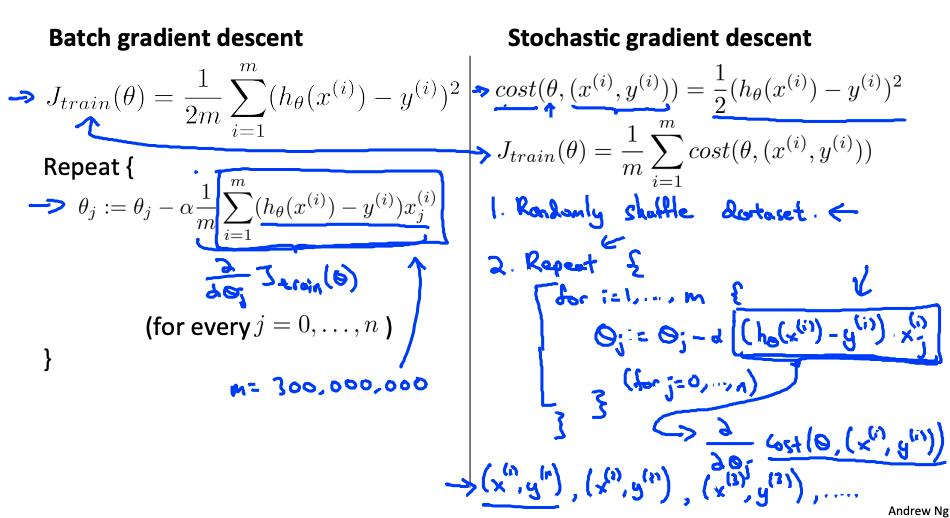
随机梯度下降以不同但相似的方式写出:
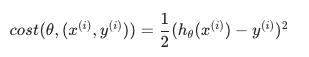
上述成本函数的唯一区别是消除了内部的 m, 改用 常数 1/2 .
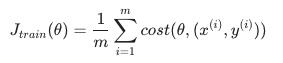
J(train)在只是应用于我们所有训练示例的成本的平均值。
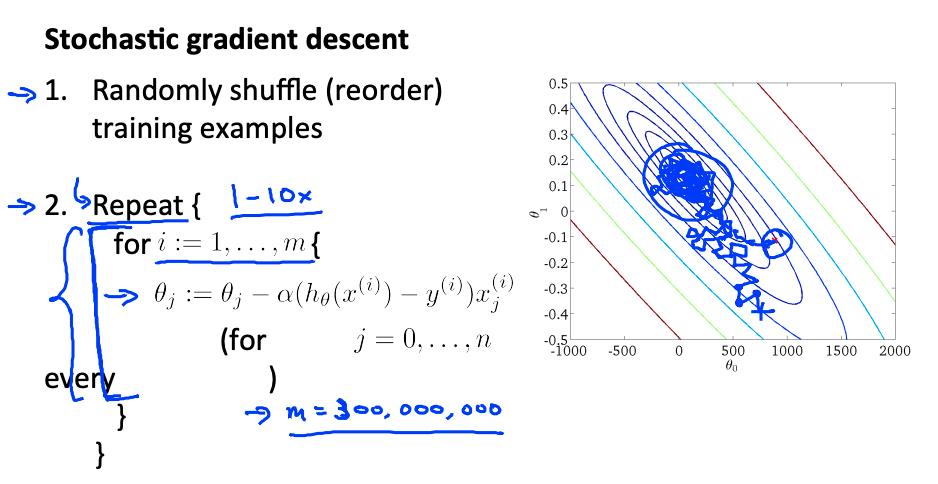
算法如下
- 随机“洗牌”数据集
- For i = 1 … m
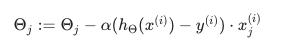
该算法一次只会尝试拟合一个训练示例。这样我们就可以在梯度下降中取得进展,而不必先扫描所有 m 个训练样本。随机梯度下降不太可能在全局最小值处收敛,而是随机地在它周围徘徊,但通常会产生足够接近的结果。随机梯度下降通常需要 1-10 次遍历您的数据集才能接近全局最小值。
3. 小批量梯度下降
小批量梯度下降有时甚至比随机梯度下降更快。不是像批量梯度下降那样使用所有 m 个样本,也不是像随机梯度下降那样只使用 1 个样本,我们将使用一些中间数量的样本 b。

b 的典型值范围为 2-100 左右。
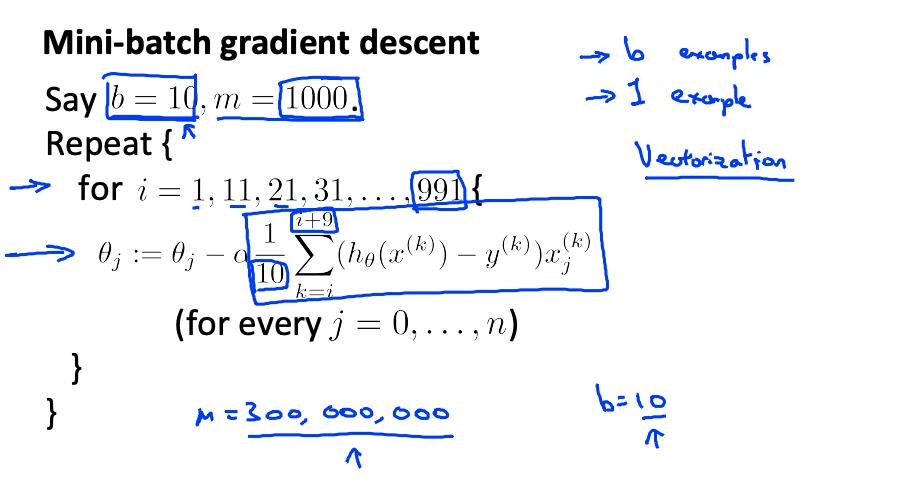
例如,对于 b=10 和 m=1000:
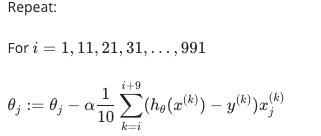
我们只是一次总结十多个例子。一次计算多个示例的优点是我们可以在 b 个示例上使用矢量化实现。
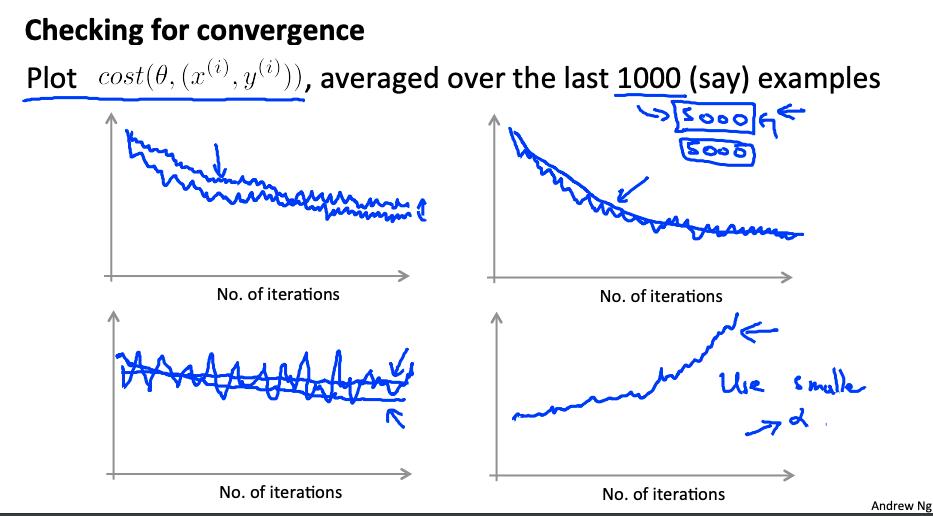
4. 随机梯度下降收敛 Stochastic gradient descent convergence
我们如何选择随机梯度下降的学习率 α?另外,我们如何调试随机梯度下降以确保它尽可能接近全局最优?
一种策略是绘制应用于每 1000 个左右训练示例的假设的平均成本。我们可以在梯度下降迭代过程中计算并节省这些成本。

用较小的学习速率,这是可能的,你可能会得到与随机梯度下降一个稍微好一点的解决方案。这是因为随机梯度下降会在全局最小值附近振荡和跳跃,并且会以较小的学习率进行较小的随机跳跃。
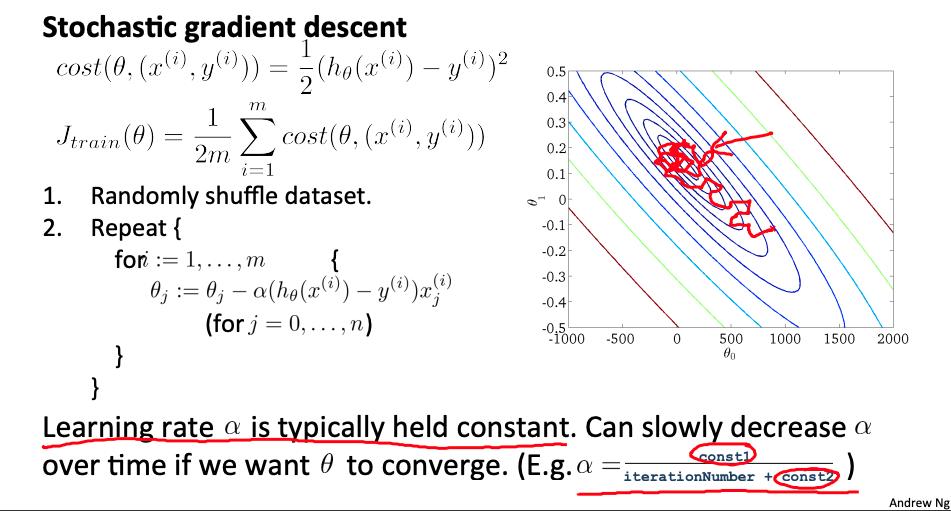
如果您增加平均的示例数量以绘制算法的性能,则绘图线将变得更平滑。
对于平均值的示例数量非常少,这条线会过于嘈杂,并且很难找到趋势。
尝试在全局最小值处实际收敛的一种策略是随着时间慢慢减小 α。例如
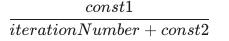
然而,这并不经常这样做,因为人们不想摆弄更多的参数。
5. 在线学习 Online learning
随着用户连续不断地访问网站,我们可以运行一个无限循环来获取 (x,y),在那里我们收集一些用户对 x 中的特征的操作来预测一些行为 y。

您可以在收集每个 (x,y) 对时更新 θ。通过这种方式,您可以适应新的用户群,因为您会不断更新 theta。

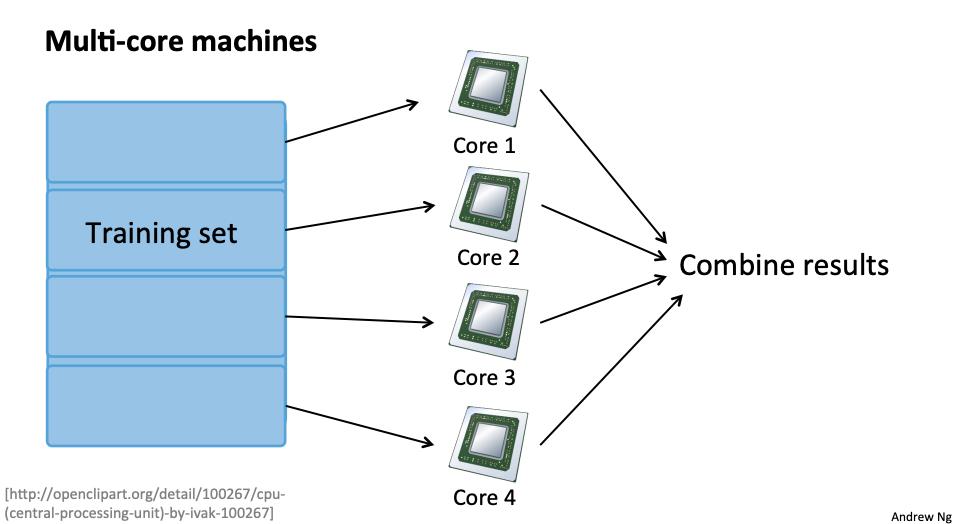
6. Map Reduce和数据并行 data parallelism
我们可以划分批量梯度下降并将数据子集的成本函数分派给许多不同的机器,以便我们可以并行训练我们的算法。
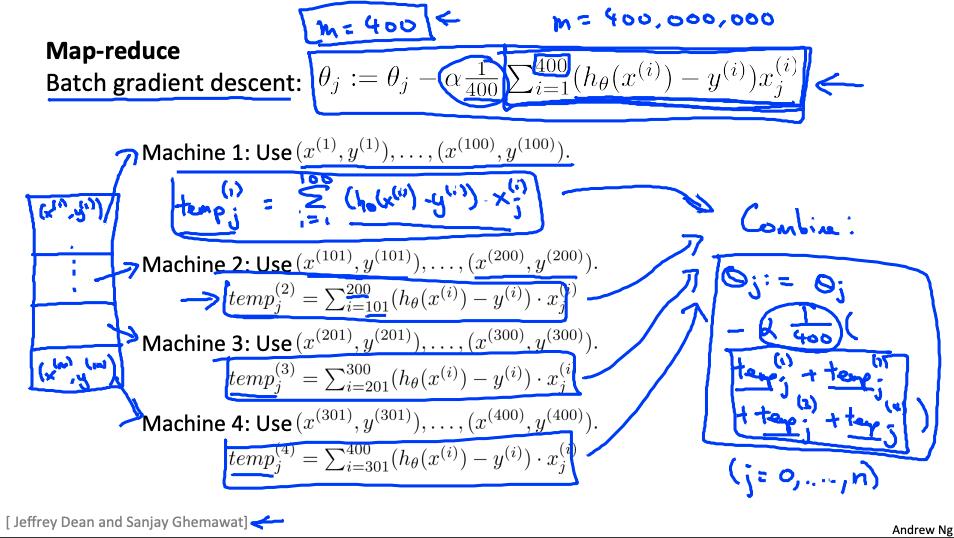
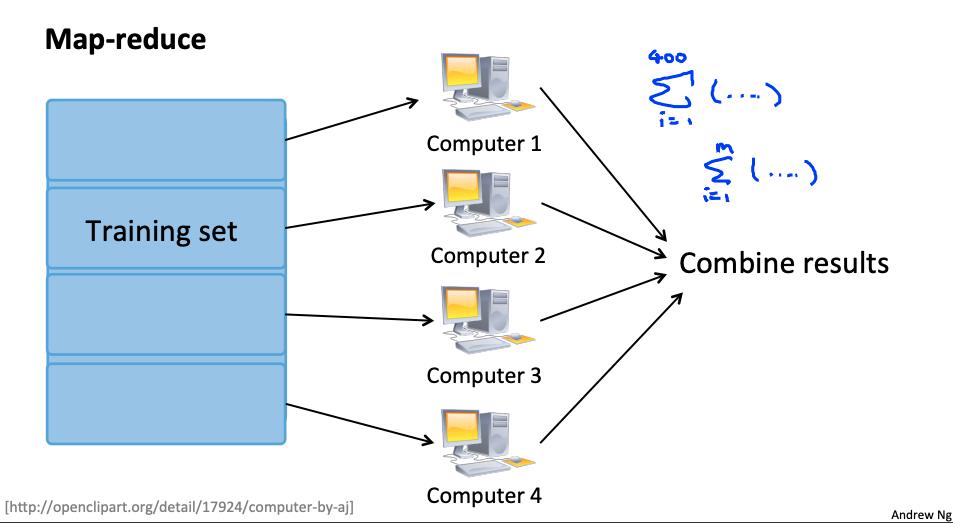
您可以将训练集拆分为与您拥有的机器数量相对应的 z 个子集。在每台机器上计算
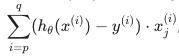
我们已经分割了从 p 开始到 q 结束的数据。
MapReduce 将获取所有这些已调度(或“映射”)的作业并通过计算来“减少”它们:
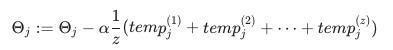
对所有 j = 0 ,…,n.
这只是简单地从所有机器中获取计算成本,计算它们的平均值,乘以学习率,然后更新 theta。
如果您的学习算法可以表示为训练集上函数的计算总和,则它是 MapReduceable 。线性回归和逻辑回归很容易并行化。

对于神经网络,您可以在许多机器上计算数据子集的前向传播和反向传播。这些机器可以将它们的衍生产品报告回将它们组合起来的“主”服务器。
参考
https://www.coursera.org/learn/machine-learning/resources/srQ23
https://www.coursera.org/learn/machine-learning/supplement/itpOu/lecture-slides
以上是关于机器学习- 吴恩达Andrew Ng Week10 知识总结 Large scale machine learning的主要内容,如果未能解决你的问题,请参考以下文章