分布式存储系统CephCeph块设备
Posted 辛辛之火可以开源
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了分布式存储系统CephCeph块设备相关的知识,希望对你有一定的参考价值。
| 这部分Ceph块设备的内容主要学习Ceph块设备的基本或主要概念,下一部分内容会接着学习Ceph块设备的常用命令 |
A block is a sequence of bytes (often 512). Block-based storage interfaces are a mature and common way to store data on media including HDDs, SSDs, CDs, floppy disks, and even tape.
Ceph block devices are thin-provisioned, resizable, and store data striped over multiple OSDs. Ceph block devices leverage RADOS capabilities including snapshotting, replication and strong consistency. Ceph block storage clients communicate with Ceph clusters through kernel modules or the librbd library.
Note
Kernel modules can use Linux page caching. For librbd-based applications, Ceph supports RBD Caching.
Ceph’s block devices deliver high performance with vast scalability to kernel modules, or to KVMs such as QEMU, and cloud-based computing systems like OpenStack and CloudStack that rely on libvirt and QEMU to integrate with Ceph block devices.You can use the same cluster to operate the Ceph RADOS Gateway, the Ceph File System, and Ceph block devices simultaneously.
rbd is a utility for manipulating rados block device (RBD) images, used by the Linux rbd driver and the rbd storage driver for QEMU/KVM. RBD images are simple block devices that are striped over objects and stored in a RADOS object store. The size of the objects the imageis striped over must be a power of two.
STRIPING(条带)
RBD images are striped over many objects, which are then stored by the Ceph distributed object store (RADOS). As a result, read and write requests for the image are distributed across many nodes in the cluster, generally preventing any single node from becoming a bottleneck when individual images get large or busy.
POOLS
Pools are logical partitions for storing objects.
When you first deploy a cluster without creating a pool, Ceph uses the default pools for storing data. A pool provides you with:
· Resilience: You can set how many OSD are allowed to fail without losing data. For replicated pools, it is the desired number of copies/replicas of an object. A typical configuration stores an object and one additional copy (i.e., size = 2), but you can determine the number of copies/replicas.
· Placement Groups: You can set the number of placement groups for the pool. A typical configuration uses approximately 100 placement groups per OSD to provide optimal balancing without using up too many computing resources. When setting up multiple pools, be careful to ensure you set a reasonable number of placement groups for both the pool and the cluster as a whole.
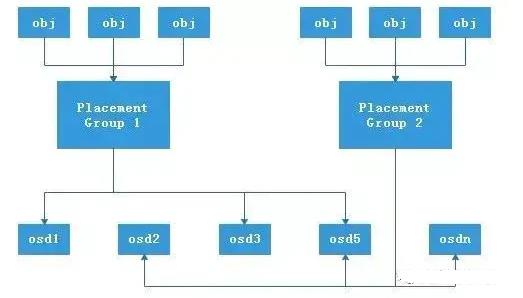
对于数据(对象),最终会写入到实际的物料磁盘OSD中,而PG起到了逻辑归组的作用,类似于数据库中表空间的概念,它的结构图如下:
PGP (Placement Group for Placement)
再来看看PGP的描述:
PGP is Placement Group for Placement purpose, which should be kept equal to the total number of placement groups(pg_num). For a Ceph pool, if you increase the number of placement groups, that is, pg_num, you should also increase pgp_num to the same integer value as pg_num so that the cluster can start rebalancing. The undercover rebalancing mechanism can be understood in the following way.The pg_num value defines the number of placement groups, which are mapped to OSDs. When pg_num is increased for any pool, every PG of this pool splits into half, but they all remain mapped to their parent OSD. Until this time, Ceph does not start rebalancing. Now, when you increase the pgp_num value for the same pool, PGs start to migrate from the parent to some other OSD, and cluster rebalancing starts. In this way, PGP plays an important role in cluster rebalancing.
pg和pgp的关系:
pg是用来存放object的,pgp相当于是pg存放osd的一种排列组合,举个例子,比如有3个osd,osd.1、osd.2和osd.3,副本数是2,如果pgp的数目为1,那么pg存放的osd组合就只有一种,可能是[osd.1,osd.2],那么所有的pg主从副本分别存放到osd.1和osd.2,如果pgp设为2,那么其osd组合可以两种,可能是[osd.1,osd.2]和[osd.1,osd.3],是不是很像我们高中数学学过的排列组合,pgp就是代表这个意思。一般来说应该将pg和pgp的数量设置为相等。
· CRUSH(Controlled Replication Under Scalable Hashing) Rules: When you store data in a pool, placement of the object and its replicas (or chunks for erasure coded pools) in your cluster is governed by CRUSH rules. You can create a custom CRUSH rule for your pool if the default rule is not appropriate for your use case.
注释:
Ceph作为关注度比较高的统一分布式存储系统,其有别于其他分布式系统就在于它采用Crush(Controlled Replication Under Scalable Hashing)算法使得数据的存储位置都是计算出来的而不是去查询专门的元数据服务器得来的。另外,Crush算法还有效缓解了普通hash算法在处理存储设备增删时带来的数据迁移问题。接下面要回答三个问题:什么是CRUSH?它能做什么?它是怎么工作的?
1. 什么是CRUSH?
随着大规模分布式系统的出现,系统必须能够平均的分布数据和负载,最大化系统的利用率,并且能够处理系统的扩展和系统故障。一般的分布式系统都会采用一个或者多个中心服务用来控制数据的分布,这种机制使得每次IO操作都会先去一个地方查询数据在集群中的元数据信息。当集群的规模变大或者系统的workload比较大时,这些中心服务器必然会成为性能上的瓶颈。Ceph摒弃了这种做法,而是通过引入CRUSH算法,将数据分布的查询操作变成了计算操作,并且是在client端完成。
CRUSH是受控复制的分布式hash算法,是ceph里面用于控制数据分布的一种方法,能够高效稳定的将数据分布在普通的结构化的集群中。它是一种伪随机的算法,在相同的环境下,相似的输入得到的结果之间没有相关性,相同的输入得到的结果是确定的。它只需要一个集群的描述地图和一些规则就可以根据一个整型的输入得到存放数据的一个设备列表。Client在有IO操作的时候,可能会执行CRUSH算法。
2. CRUSH能干什么?
如上面介绍的,它主要是ceph用来控制数据分布的。通过下图,我们看一下它在整个IO流程中处于什么位置。
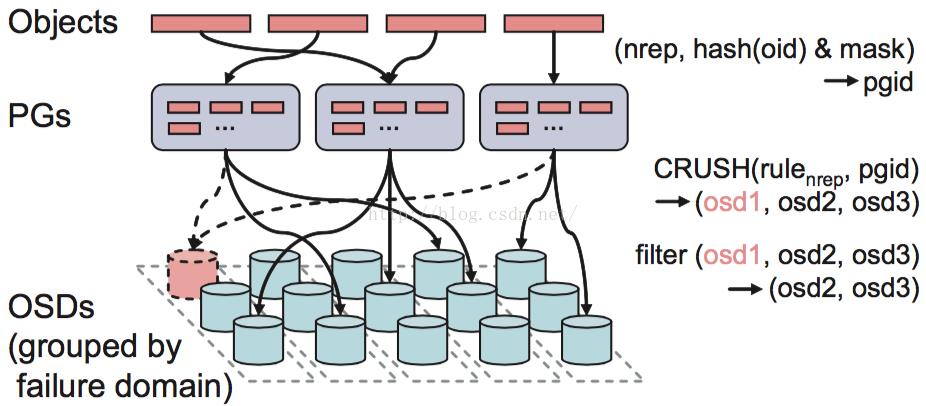
Ceph的后端是一个对象存储(RADOS),所以所有的数据都会按照一个特定的size(ceph系统默认是4M)被切分成若干个对象,也就是上面的Objects。每一个Object都有一个Objectid(oid),Objectid的命名规则是数据所在image的block_name_prefix再跟上一个编号,这个编号是顺序递增的。通过(poolid, hash(oid) & mask),每个object都可以得到它对应的pgid。有了这个pgid之后,Client就会执行CRUSH算法得到一个OSD列表(OSD1,OSD2,OSD3)。然后对它们进行筛选,根据副本数找出符合要求的OSD,比如OSD不能是failed、overloaded的。知道数据要存在哪些OSD上之后,Client会向列表中的第一个OSD(primary osd)发起IO请求。然后这个OSD按照读写请求分别做相应的处理。
所以一句话说明CRUSH的作用就是,根据pgid得到一个OSD列表。
3. CRUSH是如何工作的?
CRUSH是基于一张描述当前集群资源状态的map(Crush map)按照一定的规则(rules)得到这个OSD列表的。Ceph将系统的所有硬件资源描述成一个树状结构,然后再基于这个结构按照一定的容错规则生成一个逻辑上的树形结构作为Crush map。数的叶子节点是OSD。
4. 归置组是如何使用的?
存储池内的归置组( PG )把对象汇聚在一起,因为跟踪每一归置组个对象的位置及其元数据需要大量计算——即一个拥有数百万对象的系统,不可能在对象这一级追踪位置。
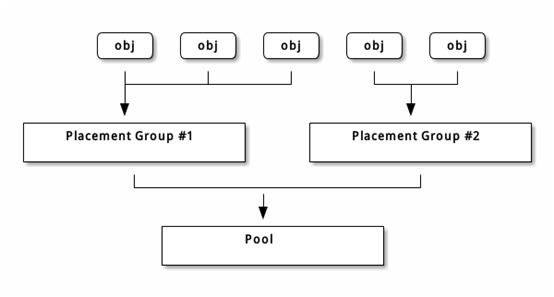
Ceph 客户端会计算某一对象应该位于哪个归置组里,它是这样实现的,先给对象 ID 做哈希操作,然后再根据指定存储池里的 PG 数量、存储池 ID 做一个运算。详情见 PG 映射到 OSD 。
The object’s contents within a placement group are stored in a set of OSDs. For instance, in a replicated pool of size two, each placement group will store objects on two OSDs, as shown below.
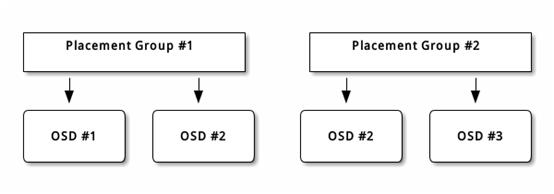
Should OSD #2 fail, another will be assigned to Placement Group #1 and will be filled with copies of all objects in OSD #1. If the pool size is changed from two to three, an additional OSD will be assigned to the placement group and will receive copies of all objects in the placement group.
Placement groups do not own the OSD, they share it with other placement groups from the same pool or even other pools. If OSD #2 fails, the Placement Group #2 will also have to restore copies of objects, using OSD #3.
When the number of placement groups increases, the new placement groups will be assigned OSDs. The result of the CRUSH function will also change and some objects from the former placement groups will be copied over to the new Placement Groups and removed from the old ones.
上面这张图很好地介绍了Ceph的架构和数据IO路径,并且也很好地诠释Ceph的设计哲理:
一切皆对象
一切均被crush
一切皆对象
众所周知,Ceph提供了一个统一存储平台,即结合了块存储(RBD)、对象存储(RGW)、文件存储(CephFS)与一体的分布式存储“航母”,而这艘航母的核心是RADOS。
而RADOS这一层就是一个对象存储系统,所有进入Ceph中的数据最终都是由RADOS负责存储进OSD中。这一层提供了librados接口,供RBD、RGW、CephFS这些上层的调用,通过socket来达到与RADOS层交互,所有上层对象最终会被封装成一个个rados对象。
一切皆被crush
一个文件被封装成一个个rados对象后,如何均匀地分发到各个OSD节点上呢?这个时候就需要用到ceph的核心算法:crush。
在介绍crush算法之前,还需要介绍两个概念:
1). Pool: Ceph对PG做的逻辑上的划分。每类存储都有其对应的默认存储池,比如RBD的默认存储池为rbd, RGW的对应存储池为default.rgw.buckets.data, CephFS的对应存储池为cephfs。也就是说,不同的RADOS上层来的数据,最终会落到不同的Pool中,由此来更好的管理数据。
2). PG(placement group): 是一些对象逻辑上的合集,也是Pool最基本组成单位,是实现冗余策略,数据迁移、灾难恢复等功能的基础。可以向上接受、处理客户端请求,转化为能被Object Store理解的事务,是一个对象落到OSD上的最后逻辑载体。
因此可以看到,一个文件从客户端写入,到最终落盘,以对象存储为例,会经历以下过程:
rgw object -> rados object -> pool -> pg -> osd
而一个rgw对象被映射成一个rados对象,一个rados对象被映射到PG,一个PG映射到一个OSD中,都需要借助哈希算法,这三次哈希转变,也就是crush算法的核心。
说了那么多,下面给出一些通俗解释:
RGW: 提供对象存储服务的组件
RBD:提供块存储服务的组件
MDS:提供文件存储服务的组件
OSD: Ceph管理硬盘的组件
MON(Monitor): 管理Ceph集群状态、各个组件的组件
5. 预定义PG_NUM
用此命令创建存储池时:ceph osd pool create {pool-name} pg_num
确定 pg_num 取值是强制性的,因为不能自动计算。下面是几个常用的值:
少于 5 个OSD 时可把 pg_num 设置为128
OSD数量在5到10个时,可把 pg_num 设置为512
OSD数量在10到 50个时,可把 pg_num 设置为4096
OSD数量大于50时,你得理解权衡方法、以及如何自己计算 pg_num 取值
自己计算 pg_num 取值时可借助 pgcalc 工具
随着 OSD 数量的增加,正确的 pg_num 取值变得更加重要,因为它显著地影响着集群的行为、以及出错时的数据持久性(即灾难性事件导致数据丢失的概率)。
· Snapshots: When you create snapshots with ceph osd pool mksnap, you effectively take a snapshot of a particular pool.
以上是关于分布式存储系统CephCeph块设备的主要内容,如果未能解决你的问题,请参考以下文章