CPU静默数据错误:存储系统数据不丢不错的设计思考
Posted 阿里云云栖号
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了CPU静默数据错误:存储系统数据不丢不错的设计思考相关的知识,希望对你有一定的参考价值。
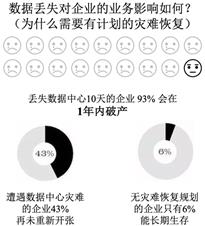
简介: 对于数据存储系统来说,保障数据不丢不错是底线,也是数据存储系统最难的部分。据统计,丢失数据中心10天的企业,93%会在1年内破产。那么如果想要做到数据不丢不错,我们可以采取怎样的措施呢?

作者 | 冲禔
来源 | 阿里技术公众号
一、背景
对于数据存储系统来说,保障数据不丢不错是底线,也是数据存储系统最难的部分。试想,如果您的银行存款记录为 1 万,因为数据存储系统异常导致该记录丢失、或者数据错误导致位翻转从 1 万变为 0,其影响是致命的。根据统计,丢失数据中心10天的企业,93% 会在1年内破产。
业界的 Data integrity 和Data Corruption 术语就是描述此类问题,它们除了阐述数据错误外,还描述了在数据存储、传输等过程中存在的问题。为了保证理解一致,先明确数据不丢和数据不错的定义:
- 数据不丢,是指相关内容不丢失。例如,100 MB 的文件其部分、全部丢失;或者,文件的元数据有部分、全部丢失,典型如文件创建时间字段丢失。
- 数据不错,是指内容存在,但是发生了错误。例如,100MB 的文件全部都存在,但其部分、全部数据出错,和原始数据不一样(例如 1 万错误的存储为 0);或者,文件的元数据出现部分或全部出错。对于存储系统来说,数据用 0 或 1 表示,因此数据错误的表现就是位翻转,就是数据从 0 变为 1,或者从 1 变为 0。
同时,Data Consistency(数据一致性)也是相关术语,但它具有更严格的要求,数据丢失或错误会导致数据一致性问题;但是在数据不丢也不错时,也不一定保证数据一致性,因为在业务逻辑设计中并没有满足一致性要求,例如数据库事务ACID的一致性要求,通常是逻辑上的数据正确性。本文重点讨论数据的不丢不错故障原因,以及数据存储系统如何防控设计,不对数据库事务深入讨论。
1 常见的磁盘、内存、网络数据翻转(Bit Flip)
对于计算机系统来说,不管是计算还是存储,不管是电子部件还是机械部件,都是采用 0 和 1 的二进制系统,都存在数据翻转的问题,所以数据不错的关键是防护位翻转。
-
盘的位翻转。不管是 HDD 还是 SSD,都包含存储介质和数据读取两部分,位翻转可能出现在介质层面,也可能出现在数据读取层面。
- 为了检测介质层面的位翻转,通常会增加额外的空间存放校验位。例如,HDD 在块大小512 字节基础上扩展为520 字节,增加了8字节(Data Integrity Field)内容,该内容中用了 2 字节(Guard) 字段存放基于该块 512 字节内容的 CRC16 值。
- 为了检测数据读取的位翻转检测,在外部线缆接口访问层采用了 CRC 来校验,同时内部的读写部件则采用了 ECC 来检查。为此,盘的S.M.A.R.T.信息还提供了 UltraDMA CRC Error Count、Soft ECC Correction、Hardware ECC Recovered 字段来统计错误数。
- 内存位翻转。内存作为电子设备,容易受到干扰,例如信号串扰、宇宙射线等,从而出现位翻转,为此引入了 ECC(Error Correction Code)内存。
- 网络位翻转。网卡作为传输设备,传输过程中因为线缆、接口、内部器件等问题,也可能出现位翻转的情况,所以网络传输中,通常会增加校验位(Checksum)来检查翻转。
以上是典型的数据翻转场景,特别是盘和内存通常是在访问时发现错误;而实际上在未发现时数据其实已经出错,因此业界也叫“静默数据错误(SDE,Silent Data Error)”。
2 隐蔽的 CPU SDE
除了存储硬件有数据翻转的数据静默错误外,作为计算核心部件的 CPU 其实也有类似的问题。因为 CPU 内部也有寄存器、缓存、传输总线等电子器件,尽管也加入了检测机制,但也有出错的概率。从 CPU 的错误分类来看,典型有如下三种:
- 硬件可检测错误。通过 CPU 内部的硬件设计,在某些情况下可以自动发现错误并校正错误,此时几乎对系统没有影响。
- 用户能观测错误。在某些情况下硬件能检测错误但是无法校正,并且这些错误要对用户可见,典型如宕机崩溃。
- 静默数据错误。此类错误既没有被硬件检测到,也没有被通知给操作系统,但是数据就是被 CPU 写到了内存,从而无法知道它是错误的。
CPU 的静默数据错误是致命的,因为对程序的体验就是让 CPU 计算返回了结果并进行存储和处理,但是数据实际已经出错、业务也不知道,而且没有任何告警。团队经过数据校验功能和 CPU SDE 错误检查工具,发现了几起 SDE 错误,并且业界谷歌和脸书都发表了文章描述该问题,可以说当前的业界难题。
二、CPU SDE故障发现过程
1 发现问题
近期团队开发的两个核心模块在某集群的指定服务器上都发现校验数据异常,由于同时在两个核心模块发现,在排除软件模块问题后,把根因排查方向转向硬件。
2 分析定位
通过对内存中的已知数据(/dev/shm/data) 让 CPU 反复计算校验 md5,然后和该数据的 正确 md5 值比较,看 CPU 是否计算返回了错误数据。
$pwd
/dev/shm
$ cat t.py
import os
import sys
import hashlib
data = open("./data").read()
hl = hashlib.md5()
hl.update(data)
digest = hl.hexdigest()
print "digest is %s" % digest
if digest != "a75bca176bb398909c8a25b9cd4f61ea":
print "error detected"
sys.exit(-1)经过在故障机器上测试,确实发现 CPU 计算 md5 的返回值中,会偶发返回错误 md5 值的情况,而且此时操作系统没有发生任何异常,问题定位是和 CPU 相关。
3 厂家确认
通过和 CPU 厂家沟通,确认该 CPU 的某个 core 发生硬件故障,导致此异常,并讨论了如下解决方案。
- 短期解决方案。厂家提供工具在线快速监测类似故障,团队完成该检测工具(主要是针对典型的 CPU 指令集)的测试,并在业务上验证通过后,快速上线。
- 长期解决方案。厂家提供工具在线监测所有类型的静默数据错误故障,并详细讨论根因和优化措施。
三、存储系统数据不丢不错设计思考
1 数据不丢不错体系思考
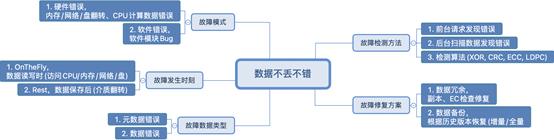
为了更好的控制数据存储系统在数据不丢不错方面的风险,进行了如上图所示的多维度思考。
故障模式
从故障来源角度看,故障模式分为硬件错误和软件错误。

故障发生时刻
故障发生的时刻,有如下两种情况:
- On The Fly。表示数据错误发生在读写时,例如 CPU 计算、内存访问、网络传输、磁盘读取过程中。
- Rest。表示数据保存到介质后,因为部件老化、环境影响、宇宙射线等因素,导致位翻转。
故障数据类型
从故障数据类型角度看,受影响的数据可能是元数据、也可能是数据;绝大部分系统都包含元数据和数据,包括底层的硬盘都有存放配置的元数据,因此它们都有可能发生错误。

故障检测方法
数据错误 100% 会发生,没有任何侥幸,故障的检测方法将极为重要,能够快速检测到数据错误,将能争取更多的机会修复数据。

为了检测故障,业界提供了如下的典型校验码算法或纠错码算法:
- XOR 算法。按照二进制的异或 (XOR) 计算校验值,能够检测单 Bit 翻转错误。
- CRC(Cyclic redundancy check)算法。通常由 n 个数据位,通过数学的多项式计算得到 k 个校验位,实现错误检测和纠错。它被广泛应用于数据的传输校验、以及硬盘的存储校验中。
- LDPC(Low Density Parity Check Code)算法。它通过校验矩阵定义的一类线性码,为使译码可行,在码长较长时需要校验矩阵满足“稀疏性”,即校验矩阵中 1的 、密度比较低,也就是要求校验矩阵中 1 的个数远小于 0 的个数,并且码长越长,密度就要越低。在 SSD 存储中,LDPC 也被规模应用。
除了上述的基本检测算法外,还有和各层业务逻辑相关的检测算法,它要按照业务的数据结构和算法逻辑进行正确性检测。
故障修复方案
典型的数据错误故障修复方案有如下两类:
- 数据冗余修复。例如基于编码冗余进行修复,以及副本、纠错码的数据修复。
- 数据备份修复。保存基于时间点的数据,典型如增量备份、全量备份,当检测到数据错误时,可以基于时间点恢复数据,只是它不是最新数据。
2 硬件数据错误和修复典型场景
内存数据错误
- 数据错误模式。发生单比特错误,出现位翻转。
- 故障发生时刻。通常是在读写内存时发生,典型如内存读、写、拷贝等。
- 故障数据类型。该错误比特影响的相关数据,可能是业务元数据,或者业务数据。
- 故障检测方法。采用 ECC内存,采用类似汉明码技术的数据位+校验位来检测。
- 故障修复方案。典型情况下,ECC 能够自动修复单比特错误,应用无感知;也能够检测多比特错误,但是无法修复,此时操作系统层面会反馈内存的 MCE 错误。
网卡数据错误
- 数据错误模式。网卡内的部件异常、网口网线松动,出现数据错误。
- 故障发生时刻。通过网络传输数据时刻,典型如网络收发包。
- 故障数据类型。该错误比特影响的相关数据,可能是业务元数据,或者业务数据。
- 故障检测方法。在各层网络协议包中增加校验,通过校验来检测错误。
- 故障修复方案。通常在网络协议中,对于错误的网络包采取丢弃、重传的方式处理。
盘数据错误
- 数据错误模式。除了盘接口传输采用 CRC 校验外,盘存储介质会出现位翻转的错误。
- 故障发生时刻。存储在介质上的数据会出现静默数据错误,只是在读取时才会发现。
- 故障数据类型。该错误比特影响的相关数据,可能是业务元数据,或者业务数据。
- 故障检测方法。在介质存储数据时,例如 512 字节 Sector 保存数据时,保存额外的 CRC 校验数据和LBA(Logical block addressing)信息,从而可以检查数据是否出错、或者 LBA 是否写偏(典型发生在 Firmware 错误)。通过后台的数据扫描,发现该错误。
- 故障修复方案。通过业务软件层做多块盘间的冗余,例如保存数据副本、纠删码,从而可以通过正确的冗余数据来进行修复。
CPU 数据错误
- 数据错误模式。难度最大的是 CPU 静态数据错误,例如计算 CRC 返回错误值,但操作系统并未上报异常。
- 故障发生时刻。使用 CPU 进行数据计算时。
- 故障数据类型。该错误比特影响的相关数据,可能是业务元数据,或者业务数据。
- 故障检测方法。单机系统内不同 CPU Core 重复处理对比检测、分布式系统不同机器的 CPU 重复处理对比检测,做到端到端检测(End to End Detect,E2E Detect),如下图所示。
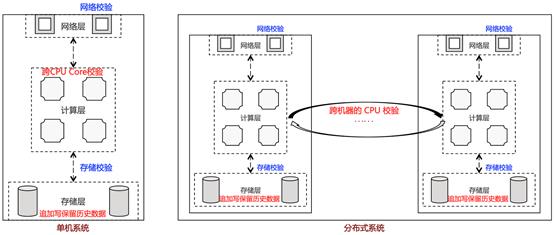
- 故障修复方案。上层业务要做好原始数据的备份,在检测到异常后进行恢复,例如机器按照追加写方式保存原始数据,在后期计算处理出错后可以恢复;而且可以设计回收站机制,即使软件层面删除了数据,也会保留一定周期,从而在软件逻辑出 Bug 后也有修复的机会。
3 软件数据错误和修复典型场景
软件 Bug 导致数据错误影响分析
软件 Bug 影响很严重,特别是在分布式系统之上开发软件,在该业务层如果没有数据备份,就只有一份数据,一旦出现软件Bug 删除数据,将是灾难式的影响。业务层软件通常分为数据和元数据,两者的受影响程度有差异,通常元数据的数据错误影响更大。

软件 Bug 的数据错误检测
业务软件的数据基于保存时间,有如下两种类型:
- 增量数据。业务新写入、更改、删除的数据,通常由业务软件的前台逻辑处理。
- 存量数据。业务前期存储的数据,由于业务软件有数据迁移、空间整理等需要改变数据,设计后台逻辑来处理。
因此,需要针对性的做错误检测,包含如下的检测纬度:
- 增量数据处理检测。在业务软件前台逻辑中保存数据更新日志,检测逻辑通过检查更新日志,来校验前台逻辑是否存在 Bug。
- 存量数据处理检测。在业务软件后台逻辑中保存数据变更日志,检测逻辑通过检查变更日志,来校验后台逻辑是否存在 Bug。
- 全量数据检测。针对存储介质的静默数据损坏,即使没有软件修改数据,也可能发生数据错误,所以需要设计全量数据扫描逻辑,主动发现错误。
对于数据错误检测设计,需要考虑如下的关键点:
- 错误检测模块要解耦。该模块应该是独立模块,单独设计,和前台、后台的数据处理逻辑不相关,从而错误检测模块才能准确的检测出 Bug。
- 数据处理逻辑记录日志的完备性。处理逻辑包括前台逻辑、后台逻辑,它们都需要保证 日志完整(漏记数据变化的记录),日志正确(日志记录包含校验,例如 CRC),避免日志丢失(掉电、异常时,日志不会丢)。
- 提高检测效率。数据错误检测的目的,除了找出 Bug 外,最重要是支撑数据恢复,提升检测效率可以更好的帮助数据恢复。检测效率主要度量单位时间内检测文件数(元数据检测)、单位时间内检测数据量(数据检测),例如每天检测多少文件数、多少文件量。
- 元数据检测优先级高于数据检测。基于元数据重要性,检测时要优先、快速检查元数据,从而可以更好的控制数据错误的影响。
- 合理利用数据冗余层的校验。例如存储的全量数据检测,可以充分利用分布式存储在数据冗余层(副本、纠删码)的后台扫描(Scrub),当检测到了某块盘的数据错误、可在此层通过冗余对比正确性并修复。
软件 Bug 的数据修复
数据错误检测到软件 Bug,并且发生了实际的数据错误,就必须要进行数据修复,要考虑如下的关键点:
- 数据冗余预埋。业务软件设计时,要考虑数据层冗余,构建在冗余存储之上。典型如分布式存储的多副本、纠删码技术,保证数据块在静态数据后(特别是存储介质的硬件、Firmware 数据错误),能够在该层做数据修复。
- 数据备份。业务软件尽管构建在数据冗余层上,但是业务层看到的单个文件,如果软件 Bug 误删除该文件仍然会导致数据丢失。所以,业务软件层要做好数据备份设计,例如 CheckPoint、多版本、快照、备份等。
- 数据备份保留周期。备份的数据长期保留有成本问题,因此需要合理设置保留周期,保证备份和成本的平衡。
- 数据备份时间一致性。业务软件可能在多层都会备份数据,因此各层要提供备份接口能力,由业务层统一设置备份时间。
- 数据恢复效率。数据恢复工具要能够尽快恢复数据,比每天恢复文件数、每天恢复数据量。
- 错误检测和备份恢复的统一设计。假设“数据备份保留周期”为 Tb,“错误检测时间”为 Td,“数据恢复时间”为 Tr,则需要保证 Tb > Td + Tr。
四、小结
数据不丢不错需要体系化的设计,要能够有效的防护硬件数据错误、抵御软件 Bug,从而要从数据冗余、备份,错误数据检测,数据恢复等维度全面构建,如下图所示。
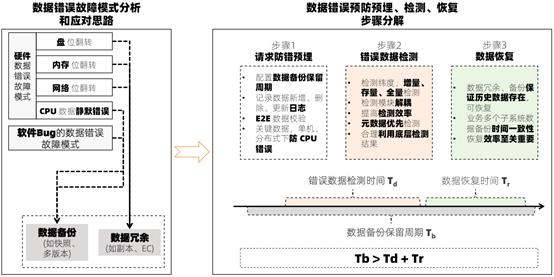
业务作为数据存储系统,基于上述思路做了如下的工作:
- 分布式数据冗余配置。在分布式层配置副本或纠删码,从而在某份数据出错后,可用正确数据校正。
- 业务层采用追加写支持多版本,实现数据备份。将备份的历史数据保存到回收站中,待需要恢复时使用。
- 端到端的 CRC 校验。拉通业务各层,在单机、分布式的计算环节、网络环节、写入盘环节进行校验,对于重要元数据要重点校验。
- 记录前台、后台的数据更新日志。业务将各类数据变化的请求信息,正确记录到日志,并将日志持久化保存。
- 增量、存量、全量数据检测机制。针对增量数据,结合日志实现典型如 1 天内扫描检测完成;对于存量数据,结合日志实现典型如 3 天内扫描检测完成;对于全量数据,基于参数配置实现典型如 60 天内扫描检测。
- 数据恢复机制和组织。业务成立专门的数据恢复团队,针对每个版本演练数据恢复准确性;并通过批量处理机制,提高恢复效率。
尽管业务做了上述不丢不错的预防机制,但在 CPU 静态数据错误方面还有很大的提升空间。理论上要做到数据不丢不错,只能是概率上无限接近于 100%。要达到该目的,除了技术上不断优化外,还需要在责任心和管理上下苦功夫,要始终保持对数据的敬畏之心。
原文链接
本文为阿里云原创内容,未经允许不得转载。
以上是关于CPU静默数据错误:存储系统数据不丢不错的设计思考的主要内容,如果未能解决你的问题,请参考以下文章