(十七)AtomicInteger原子类的介绍和使用
Posted HaC是个程序员
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了(十七)AtomicInteger原子类的介绍和使用相关的知识,希望对你有一定的参考价值。
多线程系列目录:
(十一)sleep(1)、sleep(0)和sleep(1000)的区别
(十二)yield、notify、notifyAll、sleep、join、wait的区别
在第十四章(十四)volatile的用法,为什么不能确保原子性提到 AtomicInteger 可以保证原子性。
但是我并没有展开讲它的详细用法,因为内容多,所以这一章节就来学习一下原子操作类——AtomicInteger
AtomicInteger是对int类型的一个封装,提供原子性的访问和更新操作,其原子性操作的实现是基于CAS(compare-and -swap)技术。
《深入理解Java虚拟机第二版.周志明》说到这个CAS:

CAS在本专栏 第 十六章ReentrantLock 介绍过,也可以回顾一下。
1、AtomicInteger 有什么用?
老生常谈,在 synchronized 这个章节中,我们举过几个例子,也详细解释了为什么多个线程对 i 自增,最后没办法得到准确的值的原因,我们下面再来看看这个例子.
main方法一共新建了10个线程,每个线程都调用1000次 increase() 方法,让 i 自增 ,注意要用Run模式启动噢~
/**
* @author HaC
* @webSite https://rain.baimuxym.cn
* @date 2021/4/28
* @Description
*/
public class AtomicIntegerTest extends Thread {
public static int count = 0;
public static void increase() {
count++;
}
@Override
public void run() {
for (int j = 0; j < 1000; j++) {
increase();
}
}
public static void main(String[] args) {
Thread[] threads = new Thread[10];
for (int i = 0; i < threads.length; i++) {
threads[i] = new AtomicIntegerTest();
}
for (int i = 0; i < threads.length; i++) {
threads[i].start();
}
//这段代码解释见下
while (Thread.activeCount() > 2) {
Thread.yield();
}
//剩下一个守护线程+主线程,表示子线程执行完毕
System.out.println(count);
}
}
debug模式启动是
Thread.activeCount() > 1;run模式启动是
Thread.activeCount() > 2,idea run模式下有个后台线程。反正这里表示的就是线程都执行完了,只剩下一个线程了就打印,否则主线程让步(yield)给子线程继续执行
以上结果输出是9371, 理想情况是输出 10000 ,但是结果不尽人意,每次输出的结果基本都不一样,都是一个小于10000的数字。
对于Java中的运算操作,例如自增或自减,若没有进行额外的同步操作,在多线程环境下就是线程不安全的。count++解析为count=count+1,明显,这个操作不具备原子性。
简单的说就是 count=count+1 执行的时候,每次都要去读到count的值(右边这个),然后再加一,然后在修改count的值(左边),但就是恰恰这个修改的时间,这10个线程执行顺序是CPU控制的,会出现 Thread1 修改count变成了 10, Thread2 也拿到了count修改也变成了 10, 这样就会导致 数据的不一致性。
用了AtomicInteger类后会变成什么样子?
我们试一下用AtomicInteger 来修饰一下这个count变量。
/**
* @author HaC
* @webSite https://rain.baimuxym.cn
* @date 2021/4/28
* @Description
*/
public class AtomicIntegerTest extends Thread {
// public static int count = 0;
// 使用AtomicInteger类来初始化一个int值
public static AtomicInteger count = new AtomicInteger(0);
public static void increase() {
// count++;
// 自增
count.getAndIncrement();
}
@Override
public void run() {
for (int j = 0; j < 1000; j++) {
increase();
}
}
public static void main(String[] args) {
Thread[] threads = new Thread[10];
for (int i = 0; i < threads.length; i++) {
threads[i] = new AtomicIntegerTest();
}
for (int i = 0; i < threads.length; i++) {
threads[i].start();
}
while (Thread.activeCount() > 2) {
Thread.yield();
}
//剩下一个守护线程+主线程,表示子线程执行完毕
System.out.println(count);
}
}
结果就是每次输出都是 10000,这是因为AtomicInteger.incrementAndGet()方法保证了原子性。
在increase 方法上加个synchronized也是可以的,我们前面的章节讲到,只不过性能大大降低了。
在并发环境下,某个线程对共享变量先进行操作,如果没有其他线程争用共享数据那操作就成功;如果存在数据的争用冲突,那就才去补偿措施,比如不断的重试机制,直到成功为止,因为这种乐观的并发策略不需要把线程挂起,也就把这种同步操作称为非阻塞同步(操作和冲突检测具备原子性)。
原子类一览图参考如下:
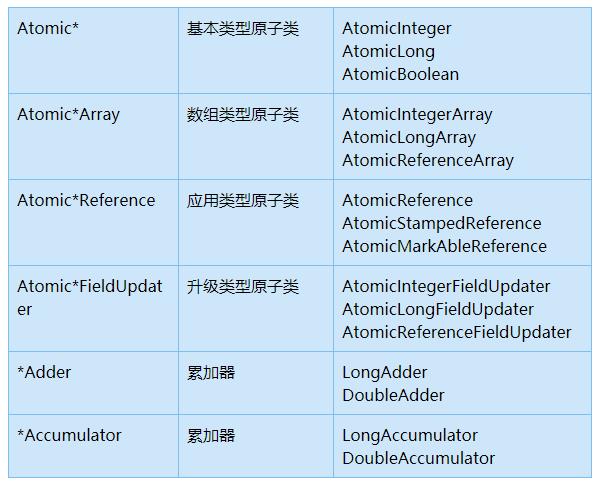
上面例子用到的是AtomicInteger,还有其他场景的数据要求也可以使用合适的原子类。
高并发情况下,LongAdder(累加器)比AtomicInteger、AtomicLong原子操作效率更高,LongAdder累加器是java8新加入的,参考以下压测代码:
/**
* @description 压测AtomicLong的原子操作性能
**/
public class AtomicLongTest implements Runnable {
private static AtomicLong atomicLong = new AtomicLong(0);
@Override
public void run() {
for (int i = 0; i < 10000; i++) {
atomicLong.incrementAndGet();
}
}
public static void main(String[] args) {
ExecutorService es = Executors.newFixedThreadPool(30);
long start = System.currentTimeMillis();
for (int i = 0; i < 10000; i++) {
es.submit(new AtomicLongTest());
}
es.shutdown();
//保证任务全部执行完
while (!es.isTerminated()) { }
long end = System.currentTimeMillis();
System.out.println("AtomicLong add 耗时=" + (end - start));
System.out.println("AtomicLong add result=" + atomicLong.get());
}
}
/**
* @description 压测LongAdder的原子操作性能
**/
public class LongAdderTest implements Runnable {
private static LongAdder longAdder = new LongAdder();
@Override
public void run() {
for (int i = 0; i < 10000; i++) {
longAdder.increment();
}
}
public static void main(String[] args) {
ExecutorService es = Executors.newFixedThreadPool(30);
long start = System.currentTimeMillis();
for (int i = 0; i < 10000; i++) {
es.submit(new LongAdderTest());
}
es.shutdown();
//保证任务全部执行完
while (!es.isTerminated()) {
}
long end = System.currentTimeMillis();
System.out.println("LongAdder add 耗时=" + (end - start));
System.out.println("LongAdder add result=" + longAdder.sum());
}
}
在高度并发竞争情形下,AtomicLong每次进行add都需要flush和refresh(这一块涉及到java内存模型中的工作内存和主内存的,所有变量操作只能在工作内存中进行,然后写回主内存,其它线程再次读取新值),
每次add()都需要同步,在高并发时会有比较多冲突,比较耗时导致效率低;而LongAdder中每个线程会维护自己的一个计数器,在最后执行LongAdder.sum()方法时候才需要同步,把所有计数器全部加起来,不需要flush和refresh操作。
参考:
- love1024.blog.csdn.net/article/details/80623884
以上是关于(十七)AtomicInteger原子类的介绍和使用的主要内容,如果未能解决你的问题,请参考以下文章
JUC并发编程 -- 原子整数(AtomicInteger)& 原子引用 (介绍 & ABA问题 & AtomicStampedReference & AtomicMa