Flink 消息聚合处理方案
Posted Flink 中文社区
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Flink 消息聚合处理方案相关的知识,希望对你有一定的参考价值。
微博机器学习平台使用 Flink 实时处理用户行为日志和生成标签,并且在生成标签后写入存储系统。为了降低存储系统的 IO 负载,有批量写入的需求,同时对数据延迟也需要进行一定的控制,因此需要一种有效的消息聚合处理方案。
在本篇文章中我们将详细介绍 Flink 中对消息进行聚合处理的方案,描述不同方案中可能遇到的问题和解决方法,并进行对比。
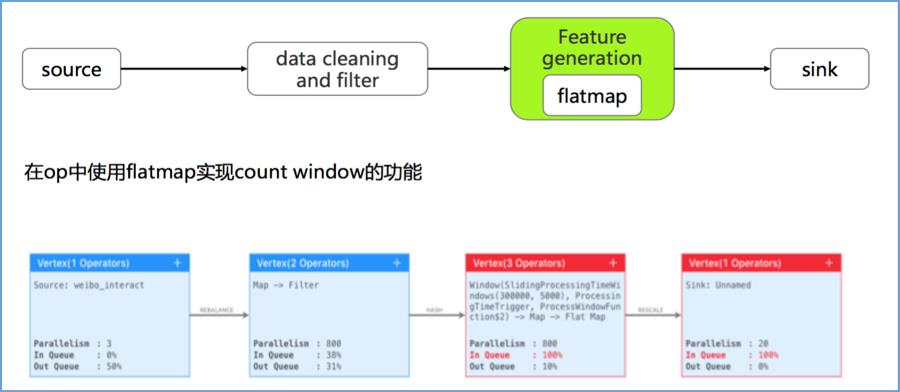
这是我们能够想到最直观的解决方案,即在自定义的 flatMap 方法中对消息进行聚合,伪代码如下:
-
-
flatMap 可以和上游算子 chain 到一起,减少网络传输开销。
-
使用 operator state 完成 checkpoint,支持正常和改并发恢复。
与此同时,由于使用 operator state,因此所有数据都保存在 JVM 堆上,当数据量较大时有 GC/OOM 风险。
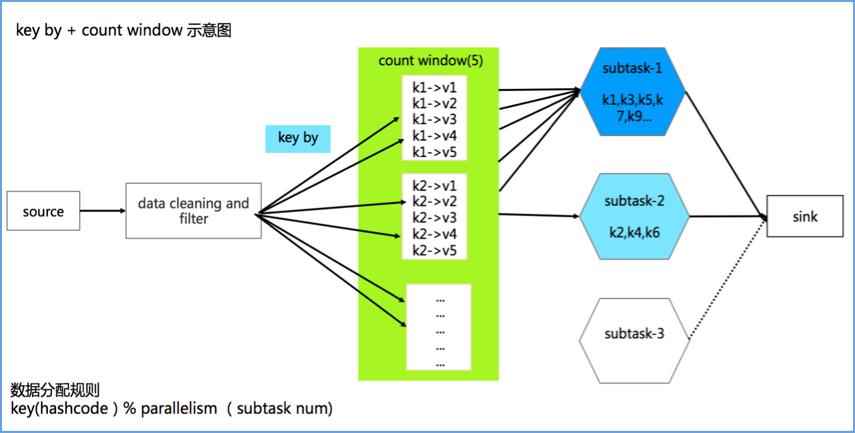
对于大规模 state 数据,Flink 推荐使用 RocksDB backend,并且只支持在 KeyedStream 上使用。与此同时,KeyedStream 支持通过 Count Window 来实现消息聚合,因此 Count Window 成为第二个可选方案。
由于需要使用 KeyedStream,我们面临的第一个问题就是如何生成 key。一个比较自然的想法是直接使用随机数,伪代码示例如下:
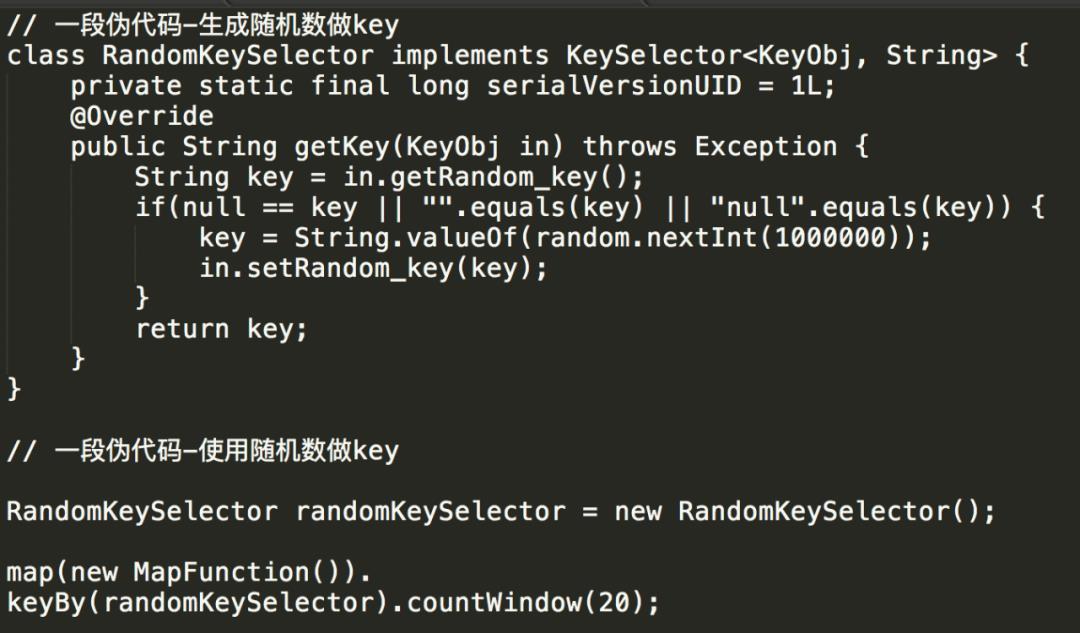
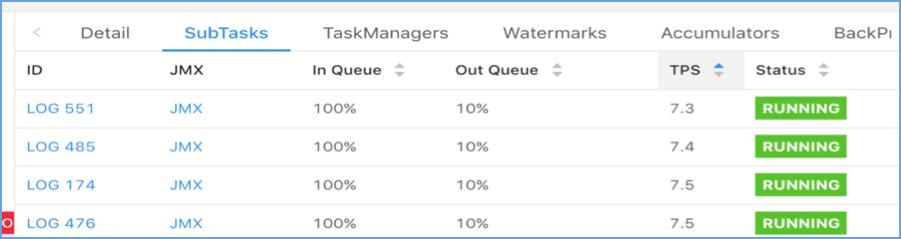
然而实际上线测试时出现了数据倾斜,不同并发间会出现负载不均,部分 task 接收不到数据从而 TPS 为 0:
在我们的场景下,除了有批量写入降低 IO 的需求,对数据延迟也需要控制,当 key set 太大时,每个 key 累积指定数据条数的时间将增加,会导致数据写入的延迟增大,因此我们需要控制 key set 的大小。经过分析,当 key set 较小时,Flink 默认的数据分发策略在并发间分布不均,从而导致了上述数据倾斜的问题。下面我们从源码级别对此进行说明。
首先,
Flink 为了保证从 state 中恢复数据时产生最小的 IO,引入了 key group 的概念。Key group 数目等于最大并发数(max parallelism),取值范围是 128-32768。当做数据分发的时候,key 会按照规则被分发到 key group 里面,相关代码如下所示:
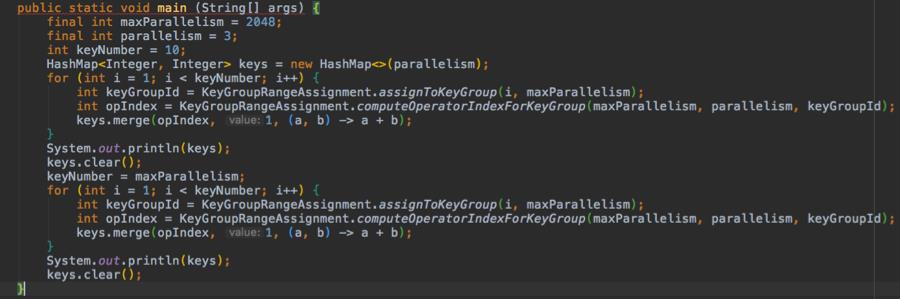
keyGroup->KeyGroupRangeAssignment.assignToKeyGroup(key,maxParallelism);
然后
,key group 会按照规则被分发到每个 task 上,代码示例如下:
Task->String.valueOf(KeyGroupRangeAssignment.computeOperatorIndexForKeyGroup(maxParallelism, parallelism, keyGroup));
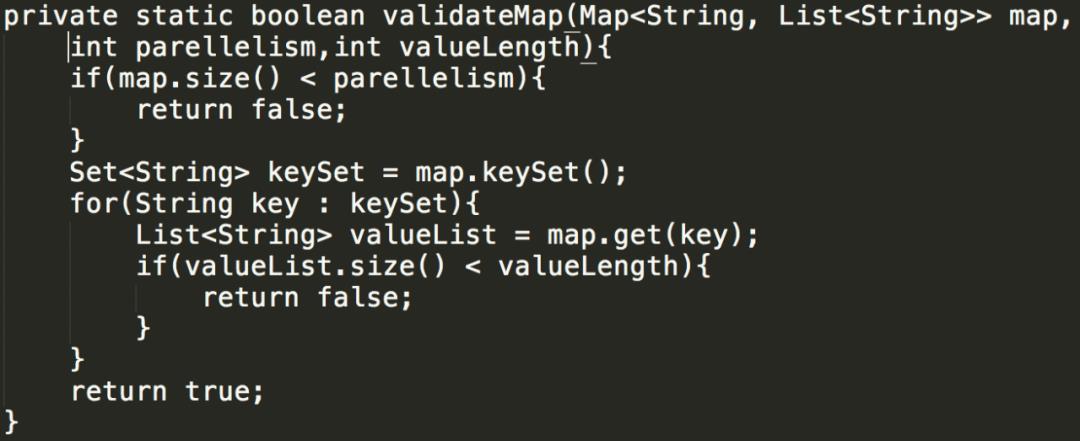
通过 debug 可以发现,当 key 的数量较小时,该分发策略会导致 key 在 task 之间分配不均匀,测试代码如下:
{0=4, 1=4, 2=1}
{0=651, 1=686, 2=710}
可以看到,当只有 10 个 key 时,并发间分布很不均匀;但当 key 的数量增加到 2048 时,就相对均匀了。
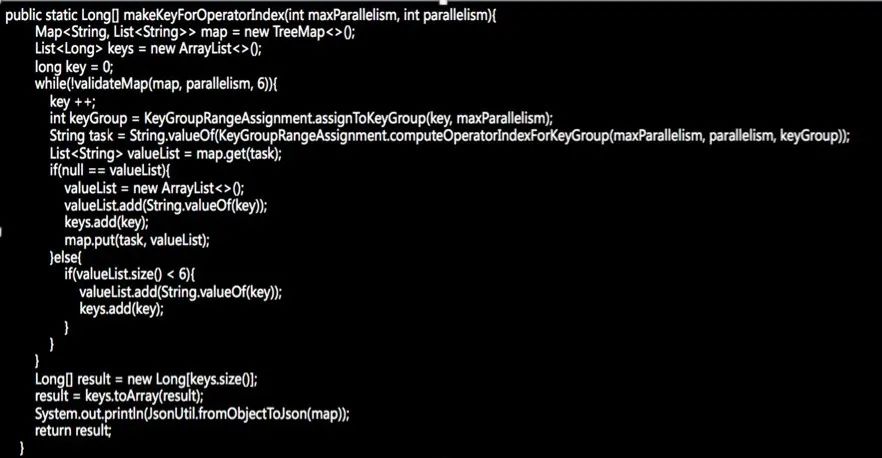
在了解了 key 的分发策略之后,我们可以相应的调整 key 的生成规则,来达到指定并发度和 key set 大小前提下的数据均匀,如下述代码所示:
我们利用 maxParallelism 和 parallelism 生成 key,并将其存储到一个大小为 parallelism 的 map 里,以 taskid 作为 map key ,每个 task 对应的 key list 作为 value,来保证每个 taskid 对应的 list 都存储了相同数量的 key。
最后
,再将 map 打平,存储到一个数组里。在使用的时候,我们可以从该数组里随机取数来作为key,
就能达到平均分配的目的了。

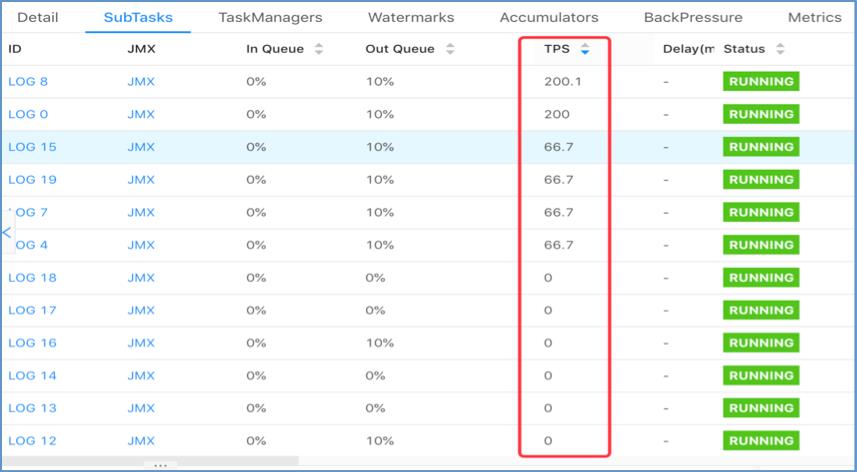
该方案的执行效果如下:
可以看到数据倾斜的问题得以解决,每个任务的负载都比较均匀。但需要注意的是由于引入了 key by,因此会有数据 shuffle,对比 flatmap 方案会有额外的网络开销。另外由于生成 key 的规则和实际并发度有关,因此该方案不支持改并发恢复,或者说如果修改并发,那么在 restore 的时候会发生数据错乱的问题,这一点需要尤为注意。
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
数据都在 state 中(rockdb/jvm heap)
|
|
在数据量不大且内存充足的情况下,建议使用 flatmap 方案;在数据量较大且可以保证不修改并发的情况下,建议使用 count window 方案并使用 RocksDB 进行 state数据存储;在数据量较大且需要修改并发的情况下,当前给出的两种方案都无法解决,需要寻求新的解决方案。
曹富强、张颖,微博机器学习研发中心-系统工程师。现负责微博机器学习平台数据计算模块,主要涉及实时计算 Flink、Storm、Spark Streaming,离线计算 Hive、Spark 等。目前专注于 Flink 在微博机器学习场景的应用。
普惠全球开发者,这一次,格外与众不同!首个 Apache 顶级项目在线会议 Flink Forward 全球直播中文精华版来啦,聚焦 Alibaba、Google、AWS、Uber、Netflix、新浪微博等海内外一线厂商,经典 Flink 应用场景,最新功能、未来规划一览无余。点击下方图片可了解更多大会详情:
你也「
在看
」吗?
以上是关于Flink 消息聚合处理方案的主要内容,如果未能解决你的问题,请参考以下文章