Flink-分布式的冯诺伊曼机器
Posted OSC开源社区
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Flink-分布式的冯诺伊曼机器相关的知识,希望对你有一定的参考价值。
最近,笔者有幸受邀参加了由OSCHINA举办的《高手问答》活动。在第250期项目中,笔者有关实时流计算技术的一些问题与读者进行了互动。在一问一答的过程中,笔者发现大家对“流”这种计算模式还是非常感兴趣的。因此,笔者想再将这些问题的核心知识点做些归纳总结。
时至今日,当我们谈论起流计算技术时,已经不可避免地会讨论Flink了。Flink在其官网上,开宗明义地对Flink的定义是“构建在流数据上的有状态计算”。
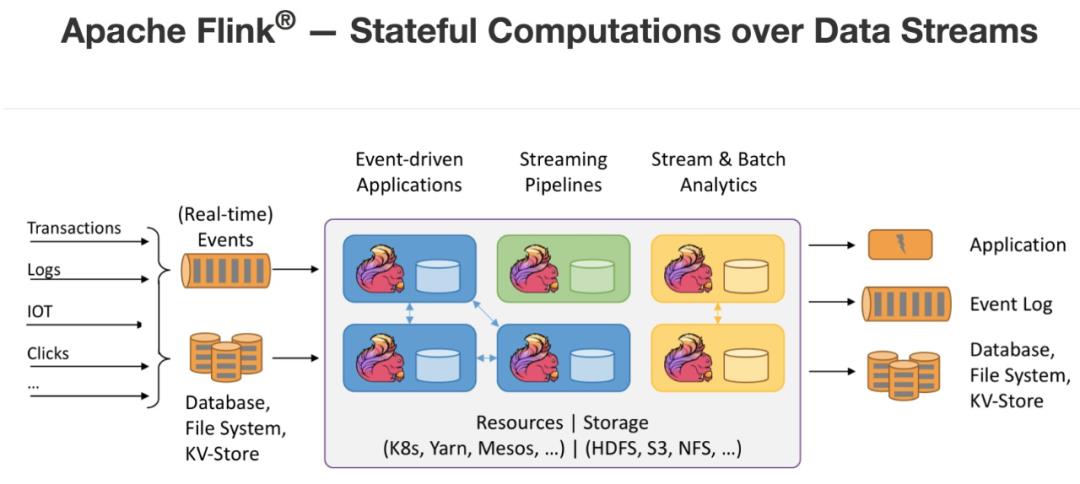
所以,Flink的核心概念有两点:一是流数据,二是有状态计算。正是这两点,让笔者将Flink推崇为真正理解“流”这种计算模式的第一框架。
究其本质,是对数据在“时间”维度的管理。而什么又是“有状态计算”?再究其本质,是对数据在“空间”维度的管理。一个“时间”,一个“空间”,足以让Flink框架解决“流”计算过程中的所有问题。
“流”这种计算模式的复杂性,在“时间”维度表现为三个方面:
1)事件窗口。“流”是无穷无尽的,我们处理它的一种方式有两种,一种来一个事件就处理一个,另一种则是将“流”按照“窗口”进行“分而治之”处理。前一种方式试用于一些简单的场景,比如filter、map、foreach之类。
但是后一种“窗口”的实现,则有诸多的复杂性,它需要对流数据进行缓冲处理,并且窗口的定义多种多样,比如按时间翻滚、滑动、按事件关联等。
2)时间乱序。由于网络传输和并发处理的原因,在流计算系统接收到事件时,非常有可能事件已经在时间上乱序了。比如时间戳为1532329665005的事件,比时间戳为1532329665001的事件先到达流计算系统。
怎样处理这种事件在时间上乱序的问题呢?通常的做法就是将收到的事件先保存起来,等过一段时间后乱序的事件到达时,再将其和保存的事件按时间排序,这样就恢复了事件的时间顺序。
3)流的关联。操作也会涉及流数据状态的管理。在关系型数据库中,关联操作是一种非常普遍的行为。现在这个概念也越来越多地被延伸到流计算上来。常见的关联操作有join和union。
特别是在实现join操作时,需要先将参与join操作的各个流的相应窗口内的数据缓存在流计算系统内,然后以这些窗口内的数据为基础,做类似于关系型数据库中表与表之间的join计算,得到join计算的结果,之后再将这些结果以流的方式输出。
很显然,流的关联操作也是需要临时保存部分流数据的。
而“流”在“空间”维度表现出的复杂性则主要表现在,高“势”变量的状态存储。势(Cardinality)是集合论中用来描述一个集合所含元素数量的概念。比如集合S={A, B, C}有3个元素,那么它的势就是3。集合包含的元素数量越多,其势越大。
当我们进行聚合分析的变量具有一个较低的势时,那么一切都尚且安好。但实际的情况是,我们在“流”计算中分析的变量往往具有比原本预想高得多的势。比如统计用户每天的登入次数,那么光全中国就有十四亿人口!再比如需要统计每个IP访问网站的次数,那全球有四十多亿IP。
再加上,有时候我们需要聚合的是一些复合变量,比如统计“过去一周同一用户在同一IP C段申请贷款次数”,这种情况如果严格按照理论值计算(也就是笛卡尔积),那将是天文数字。
所以,至少我们不能指望将这些状态都存放在本地内存里。所以我们需要对这些状态进行分布式地存储。
那Flink针对于流计算中的这两种复杂性,分别做了怎样的设计呢?
针对流数据“时间”维度方面的管理,Flink 的 DataStream 与提供了窗口管理相关的 API,包括 Window 和 WindowAll。其中 Window 是针对KeyedStream,而 WindowAll 是针对非 KeyedStream。
在窗口之,则提供了一系列窗口聚合计算的方法,比如 Reduce、Fold、Sum、Min、Max 和 Apply 等。另外,DataStream提 供了一系列有关流与流之间计算的操作,比如Union、Join、CoGroup 和 Connect 等。
而在“空间”维度方面,Flink 提供了非常有特色的 KeyedStream。所谓KeyedStream 是指将流按照指定的键值,在逻辑上分成多个独立的流。这些逻辑流在计算时,状态彼此独立、互不影响,但是在物理上这些独立的流可能是合并在同一条物理的数据流中。
因此在KeyedStream具体实现时,Flink会在处理每个消息前,将当前运行时上下文切换到key值所指定流的上下文。就像线程栈的切换那样,这样优雅地避免了不同逻辑流在运算时的相互干扰。
并且,Flink为KeyedStream提供了Keyed State状态管理方案,当我们需要在逻辑流中记录一些状态信息时,就可以使用Keyed State。比如“统计不同IP上出现的不同设备数”,可以用将流按照IP分成KeyedStream,这样来自不同IP的设备事件,会分发到不同IP独有的逻辑流中。
然后在逻辑流处理过程中,使用KeyedState来记录不同设备数。如此一来,可以非常方便地实现“统计不同IP上出现的不同设备数”的功能。
所以说,Flink真的是针对“流”这种计算模式提供了各方面贴心的开箱即用功能,而且是用起来真香的那种。
但这样就完了吗?《易经》有言“形而上者谓之道,形而下者谓之器”。笔者认为,上面谈到的这些知识,还只能说是针对Flink这个具体的“器”。
而更重要的问题应该是,Flink这种分布式、有状态、流式计算的模式,会成为未来“大数据”技术的主要架构模式。
此话怎讲?我们看下现代计算机架构的开山鼻祖,冯诺伊曼先生对计算机结构的定义:
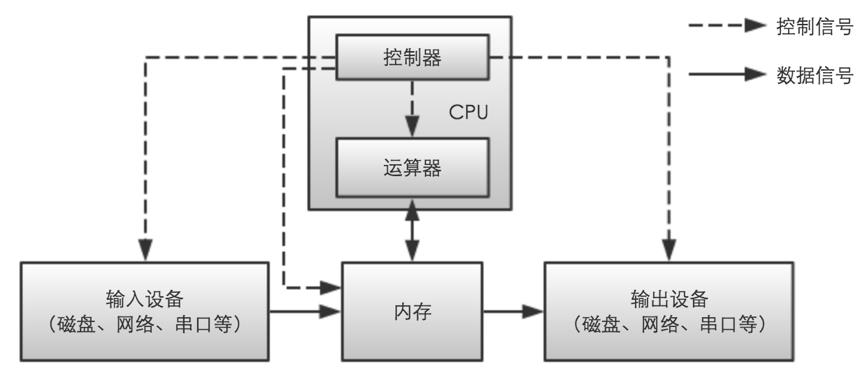
在冯诺依曼结构的计算机系统中,计算最核心的三个组成是CPU、内存和IO。
如果我们将Flink与冯诺伊曼架构进行对比,会发现Flink的计算模式非常像是把单JVM进程内的流计算过程扩展到了分布式集群。
如果我们不强调“流”这种计算模式,那么完全可以将Flink理解为一个分布式的JVM,各个任务分配的线程相当于是CPU,而State则相当于是内存。
由于Flink的State可以是用磁盘存储,而机器可以水平扩展,所以理论上Flink这个分布式JVM的“CPU”和“内存”都是“无限”的。如果按照分布式JVM理解Flink框架,可以大大扩展我们对Flink的使用场景,而不仅仅将其视为一个专门用于处理流数据的工具而已。
现在有一个趋势,是使用Flink和Pravega来做大数据处理。个人觉得,这种模式在未来将成为主流的大数据处理模式,Flink充当CPU和内存的角色,Pravega充当存储。数据以“流”的方式被计算,并且以“流”的方式被存储。
正如Unix哲学“万物皆文件”一样,未来的计算世界里,将会是“万物皆流”!
作者简介:周爽,本硕毕业于华中科技大学,先后在华为2012实验室高斯部门和上海行邑信息科技有限公司工作。开发过实时分析型内存数据库RTANA、华为公有云RDS服务、移动反欺诈MoFA等产品。目前但任公司技术部架构师一职。著有《实时流计算系统设计与实现》一书。
点击“阅读原文”,可查看高手问答第 250 期 —— 是时候掌握真正的实时流计算技术了,在线观摩老师与读者的互动。
以上是关于Flink-分布式的冯诺伊曼机器的主要内容,如果未能解决你的问题,请参考以下文章
读《冯诺伊曼传》
读《冯诺伊曼传》
读《冯诺伊曼传》
请问冯·诺依曼结构和哈佛结构有啥异同?谢谢!
硬核操作系统讲解
硬核操作系统讲解----计算机架构部分